文末有福利!
引言
本文主要介绍大模型(LLMs)如何助力汽车自动驾驶,简单来说,作者首先带大家了解大模型的工作模式,然后介绍了自动驾驶大模型的3大应用场景,最后指出自动驾驶大模型将会是未来的发展趋势,只要坚持,国内新能源造车新势力还是很有机会的。本文没有深入讲解算法架构,而是化繁为简,能够让您很快的对自动驾驶大模型有个较为全面的理解。
除此之外,作者也整理了自动驾驶大模型相关的论文,回复:自动驾驶****LLM 可自行获取。
背景介绍
青霉素发现之前,科学家们的研究方向是在无菌实验室中不断的试错,旨在希望通过传统的医学方法来解决复杂的问题。然而,一个偶然的事件却改变了事件的发展,苏格兰医生弗莱明忘记关闭培养皿,导致培养皿被霉菌污染。这时,弗莱明注意到了一些奇怪的事情:所有靠近水分的细菌都死了,而其他细菌则幸存下来。
其中的水分到底是由什么构成的呢?带着这个一文,弗莱明发现霉菌的主要成分青霉素是一种强大的细菌杀手,从此人类发现青霉素的作用,从而产生了我们今天使用的抗生素。反过来想,如果一个医生按照传统的医学方法在无菌实验室里进行研究,青霉素的发现或许还要晚上很多年,甚至有可能也发现不了。
那么,汽车的自动驾驶是否也有可能出现类似的事情呢?前几年的汽车自动驾驶大多都是基于所谓的“模块化”构建,其主要包括感知模块、定位模块、规划模块、控制模块等,这里的控制模块会根据其他模块的信息来实现汽车的转向、变道等功能。如下图所示:
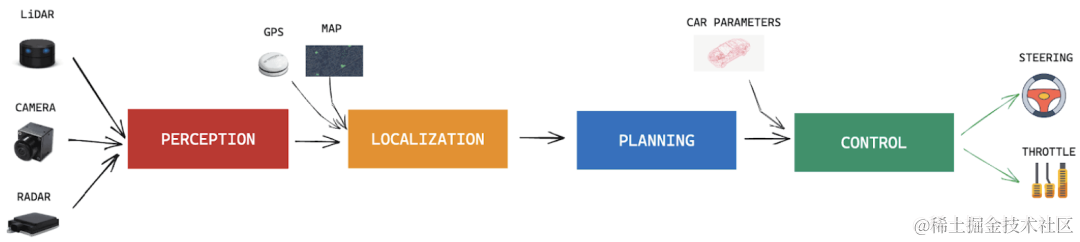
随着模型框架的发展,研究人员提出了端到端学习,核心思想是用预测转向和加速度的单个神经网络替换每个模块,这同样会引入黑盒问题,尽管如此仍然无法解决自动驾驶问题。那么近两年快速发展的大语言模型能否成为实现自动驾驶的答案呢?为此,本文将探讨大模型如何助力汽车自动驾驶。
LLM概述
简单来说,大模型主要包含Token化、Transformer、文本生成三大概念。其中:
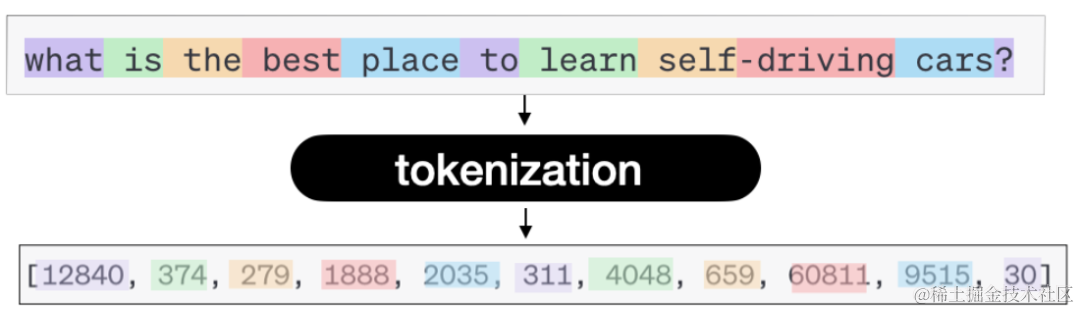
「Token化」:给大模型输入一个文本,返回也是一个文本。但实际上是需要将输入文本转换成Token。那么什么是Token呢?简单来说一个Token可对应一个单词、一个字符、一个短句等。神经网络的输入始终是数字,因此您需要将文本转换为数字;这就是Token化。如下图所示:
「Transformer」:将输入文本转换成一个个的Token之后,就要将其输入到神经网络中,目前大部分的模型的基础网络架构都是Transformer,如下图所示。下图展示的是Encode-Decode架构的模型,不过现在大多数大模型都是Decode架构,例如GPT、LIaMA、ChatGLM等。不管怎样,它们都共享核心 Transformer 模块:多头注意力、层归一化、加法和串联、块、交叉注意力等…
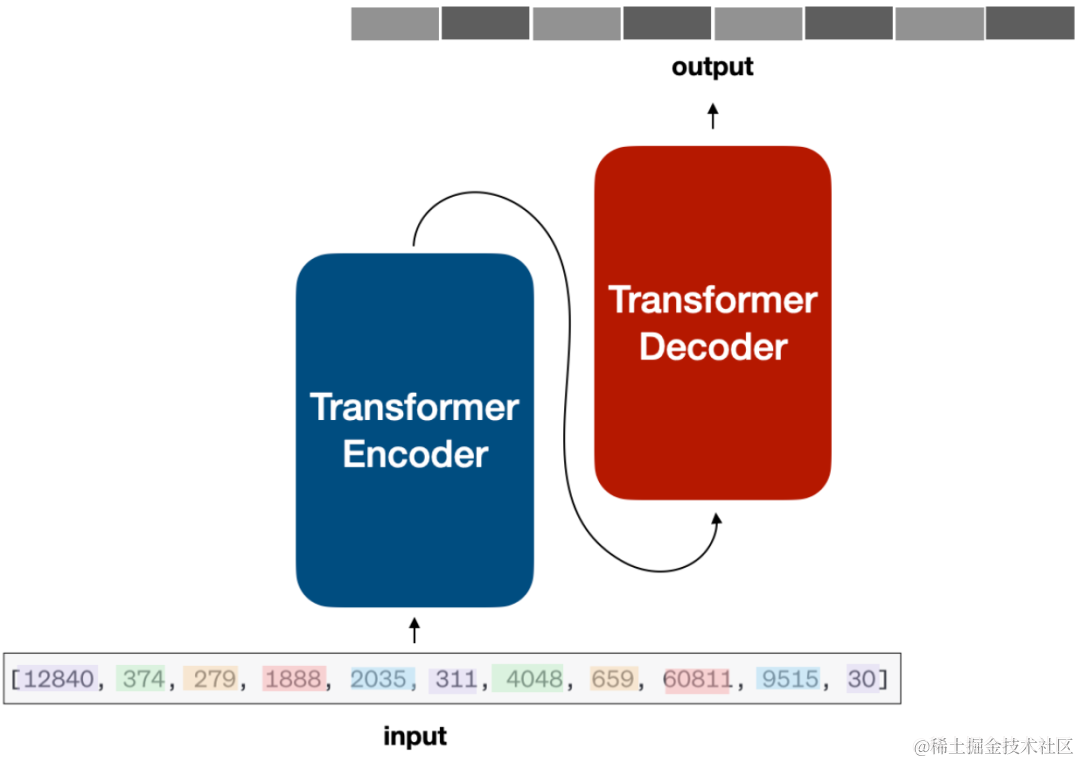

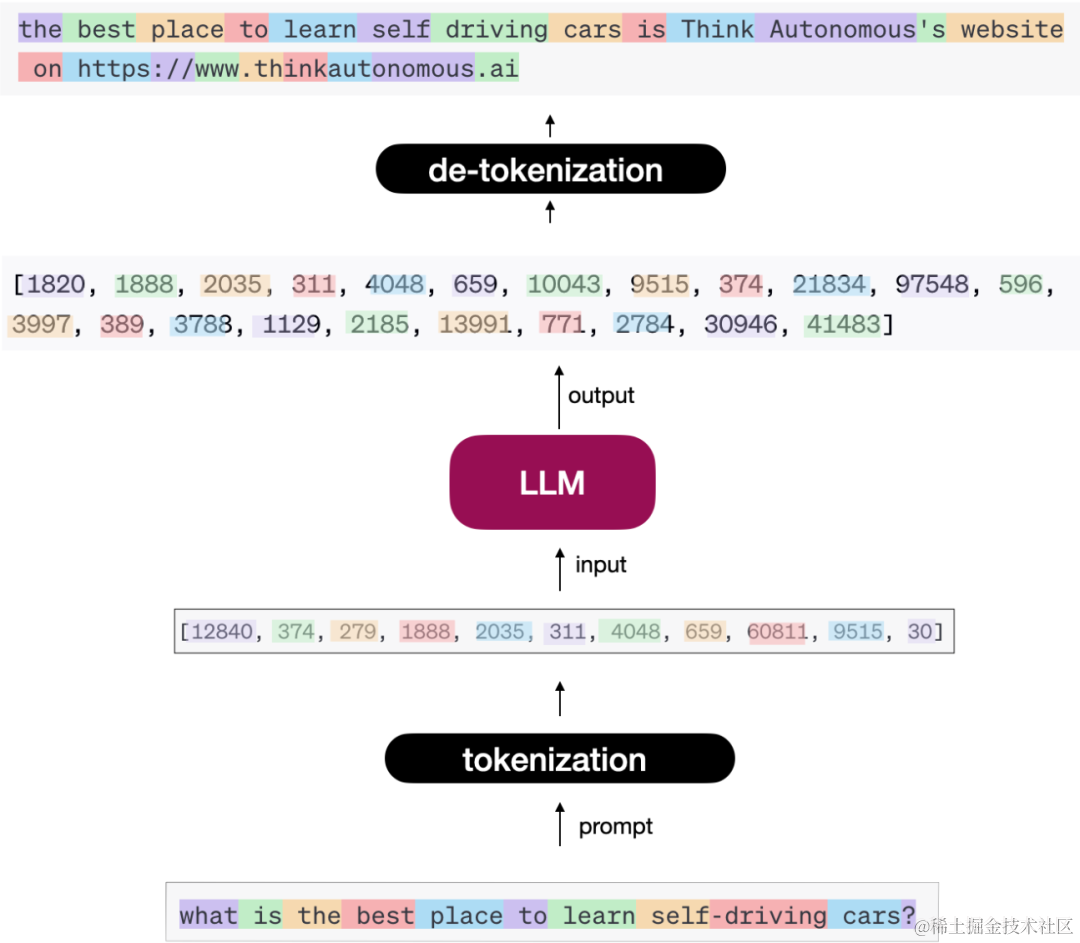
「文本生成」 当上述Token进入Transformer网络中,文本是如何一个一个的生成的呢?如上图,编码器主要是学习输入文本特征并理解上下文,解码器主要是试图生成一个一个的单词,当然在一个一个单词生成的过程中主要依赖概率来进行判断输出。如下图所示:
LLM赋能自动驾驶
基于上面对LLM基本原理的介绍,那么它该如何应用到自动驾驶中呢?上面是将文本数据输入到模型架构中,在此场景下,这里将图像、传感数据(激光雷达点云、3D图像点云等)、算法数据(车道线、障碍物等)等转换成Token作为模型输入,模型架构基本上无需进行变动。输出则是基于我们想要汽车驾驶操作,例如当传感器检测到前面有车,左侧后方无车辆,可以左侧进行变道操作。
以上变道只不过是LLMs任务中的一种,除此之外LLM还能解决哪些自动驾驶任务呢?结合目前国内新能源汽车最新发展趋势,主要涉及这几个方面:
「环境感知」:在此情况下,输入通常是一系列的图像,例如最新的特斯拉取消的激光雷达采用全视觉感知,输出通常是一组对象,例如显示屏中模拟的车道、行人、障碍物等。就大模型而言,其主要有3个核心任务:检测、预测和跟踪。如下图所示,将车辆行驶图像输入到ChatGPT中,可以要求其描述发生的状况:

不单单是ChatGPT,其他的模型同样可以做到,例如 HiLM-D 、MTD-GPT ,有的模型(例如PromptTrack)甚至可以为目标分配唯一的ID标识。
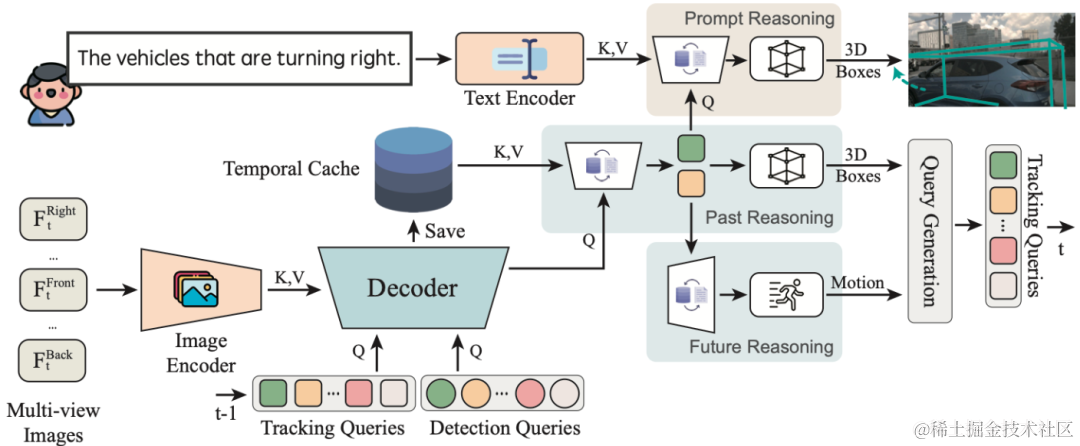
在上图PromptTrack模型中,多个传感器图像会被发送到Encoder-Decoder网络中,通过该网络可以预测对象注释(如3D边界框和注意图),然后结合LLM提示“找到正在右转的车辆”,接着下一个块会找到 3D 边界框定位,并使用二分图匹配算法分配 ID。
「决策规划」 如果大模型在图像中发现了目标,那么它会告诉你面对该种情况该如何操作。这就是任务规划,即根据当前感知来规划从A到B的路径,当前在这块做的较好模型为Talk2BEV。除此之外,为了方便驾驶人更好的理解周围的环境,模型会结合多个视图生成鸟瞰视图。

如上图所示,这并不是纯粹基于“提示”,因为核心目标检测模型仍然是鸟瞰感知,但是LLM被用来“增强”输出,通过建议一些区域,查看特定的地方,并预测路径。
其他模型(例如 DriveGPT)经过训练,将 Perception 的输出发送到 Chat-GPT 并对其进行微调,以直接输出驾驶轨迹。如下图所示:
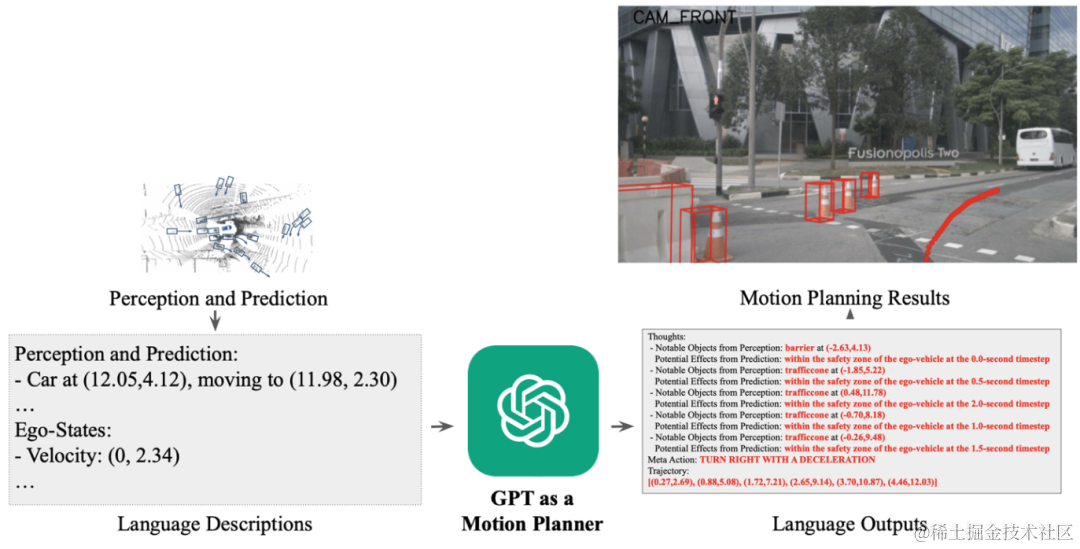
总结一下,结合上面我们对大模型的理解,这里的大模型(LLMs)输入是Token化的图像或者是感知算法的输出,然后将现有模型(BEV 感知、二分匹配……)与语言提示融合在一起,让大模型来寻找正在移动的车辆,最后,根据不同场景任务,根据输入数据对大模型进行细致的微调即可。
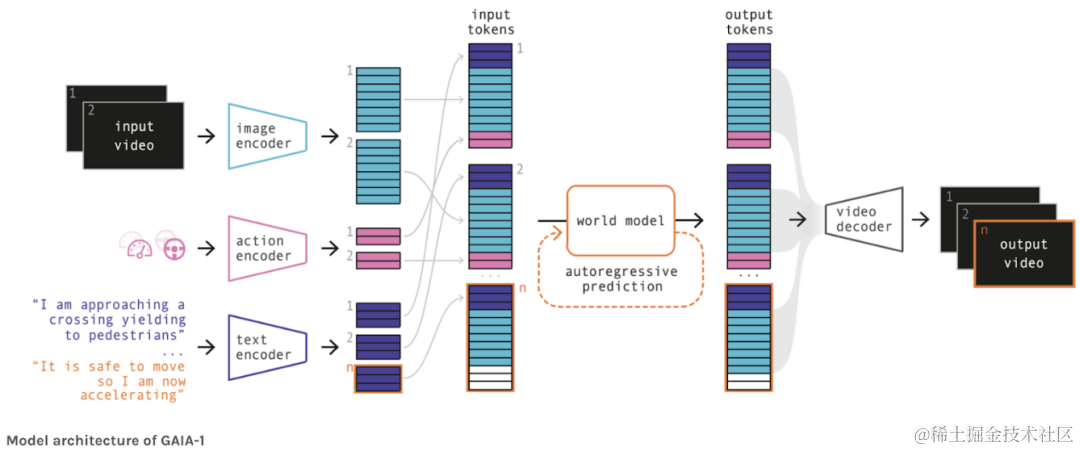
「图像生成」 您听说过 Wayve 的 GAIA-1 模型吗?该架构将图像、动作和文本提示作为输入,然后使用世界模型(对世界及其交互的理解)来生成视频,其模型架构如下所示:
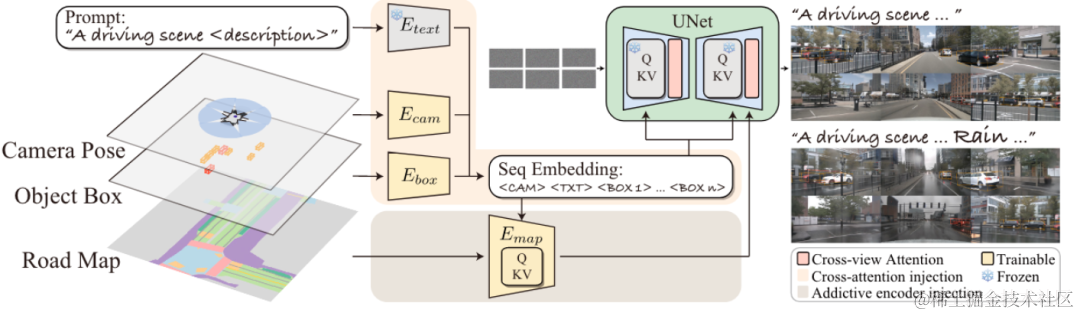
类似地,您可以看到 MagicDrive,它将 Perception 的输出作为输入并使用它来生成场景:
还有一些模型能够根据当前的图像,生成未来可能的场景,例如:Driving Into the Future 、Driving Diffusion。根据这类模型,可以生成很多的汽车应用场景数据,进而可以训练出更好的模型,形成模型都迭代优化闭环。
自动驾驶LLM可信吗?
我们都知道,大模型当面对自己不了解的现实知识时,有很大概率会出现模型幻觉。那么将其应用到自动驾驶方面是否同样会出现类似的情况,答案是肯定的。
不过现在对自动驾驶LLM下定论也为时过早!因为,ChatGPT出现才不到一年半的时间,现在的大模型已经可以实现视频生成(例如Sora)、音乐生成(例如:Stable Audio 2.0、Prompt-Singer等),且效果惊人,未来的自动驾驶大模型也将会乘风破浪,成为自动驾驶的主流核心技术。紧跟技术迭代更新,只要坚持,国内新能源造车新势力还是很有机会的。








)



)




:i.MX linux开发之开发板)


