软件监控简史,从 00 年代开始。发生了什么变化?为什么事情变得如此神秘?
终端设备上日益重要的用户体验通过边缘计算和分布式计算不断得到改善。然而,服务质量的测量仍然使用基于服务器的原语进行。
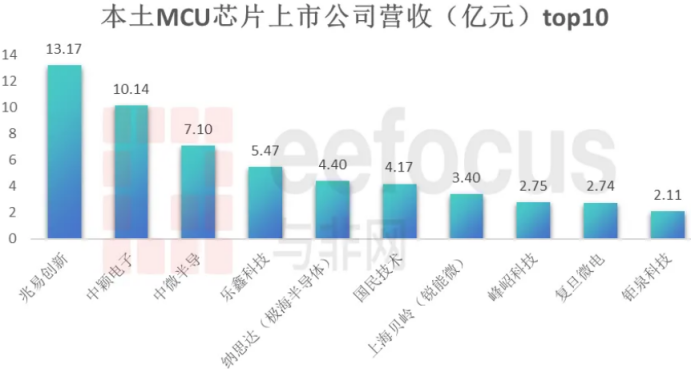
我们的 2000 年软件监控是这样的:
用户通过浏览器访问网络。互联网速度缓慢且不稳定,因此糟糕的体验不会导致客户流失。这个时间段,各种基建发展的不完善,大家主力对象都是PC,上网时间比较短,场景也比较少,慢是预期之内,所以一切发展都是正常的。
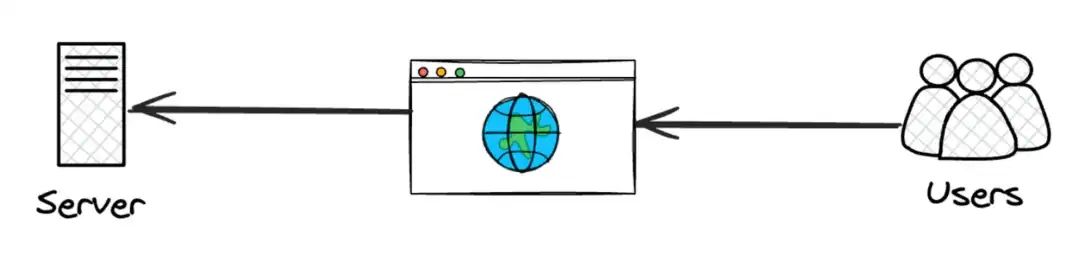
到了 2000 年代后期,手机问世了。这改变了一切,而且改变得很快。
用户注意力的持续时间缩短到“电梯间”和“咖啡间”、“上班之余”、“睡觉前一分钟”。用户上网开始变得非常方便,这意味着用户要求更多。注意力持续时间缩短。应用程序从web端转向娱乐互联网,开始满足人类多巴胺需求。延迟令人无法接受。同时延迟高的站点也时刻面临被淘汰的风险。
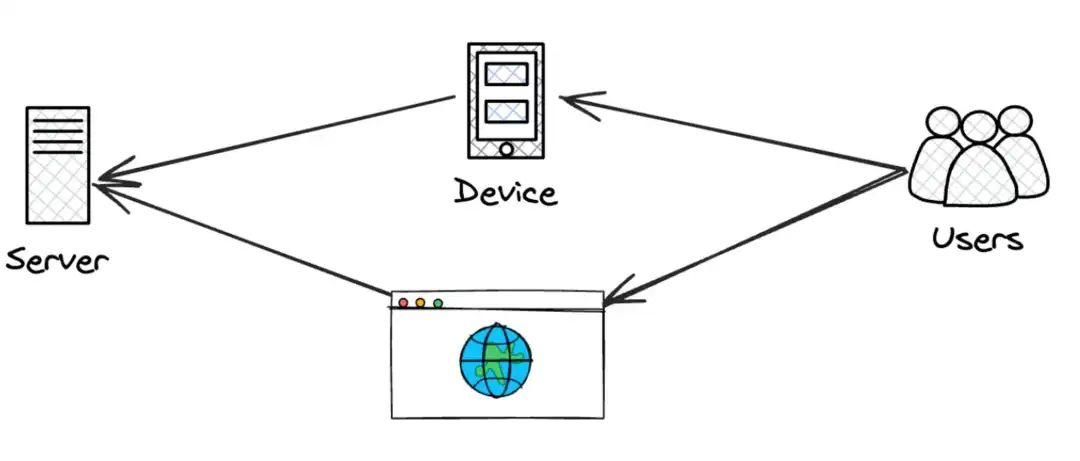
企业开始认真对待分布式系统,想尽办法提升用户体验,缩短用户访问时延。
最先利用这一点的服务是媒体服务,各种视频软件铺面而来,其目的是快速接触客户,以便更快地进行消费用户。
其中内容分发网络(CDN)和边缘媒体得到广泛采用。用户现在可以快速上传和下载文件。
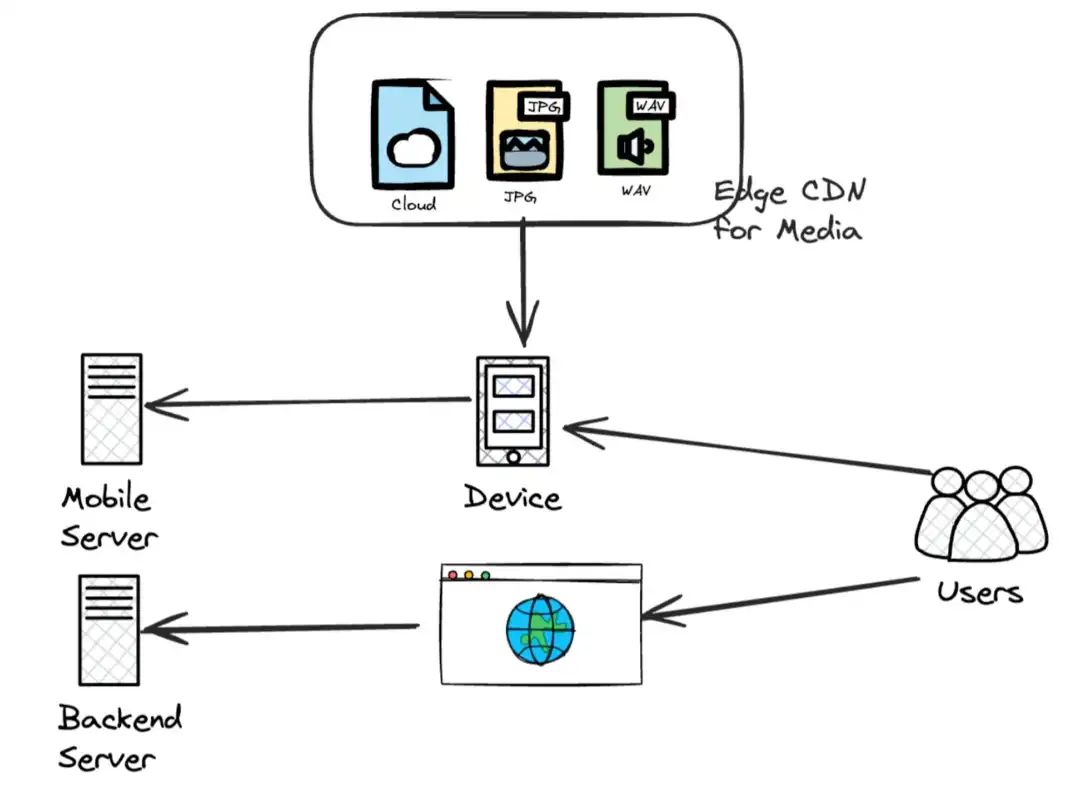
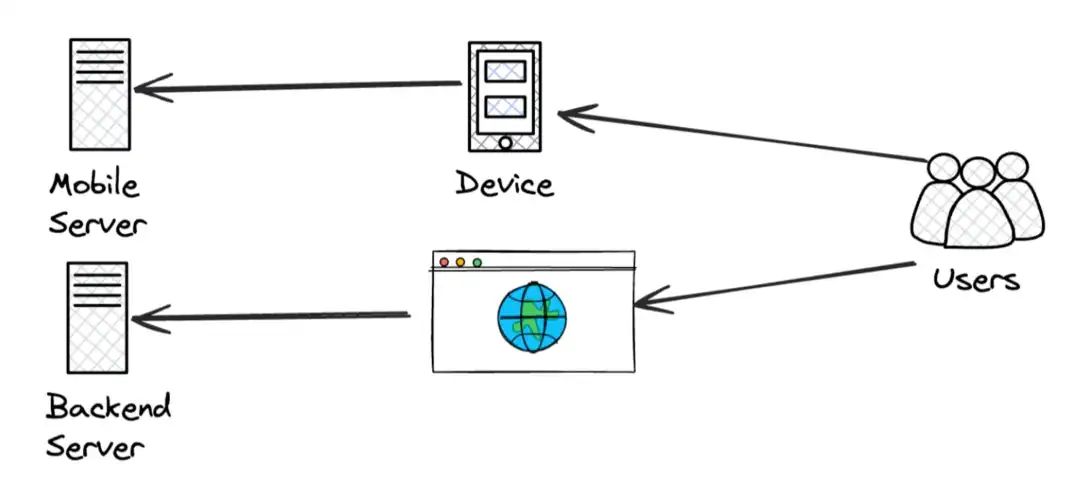
社交媒体、直播和其他 over-the-top (OTT) 平台广受欢迎。更快的性能提高了用户体验。注意到系统复杂程度的快速变化了吗?看看下面的图片 👇
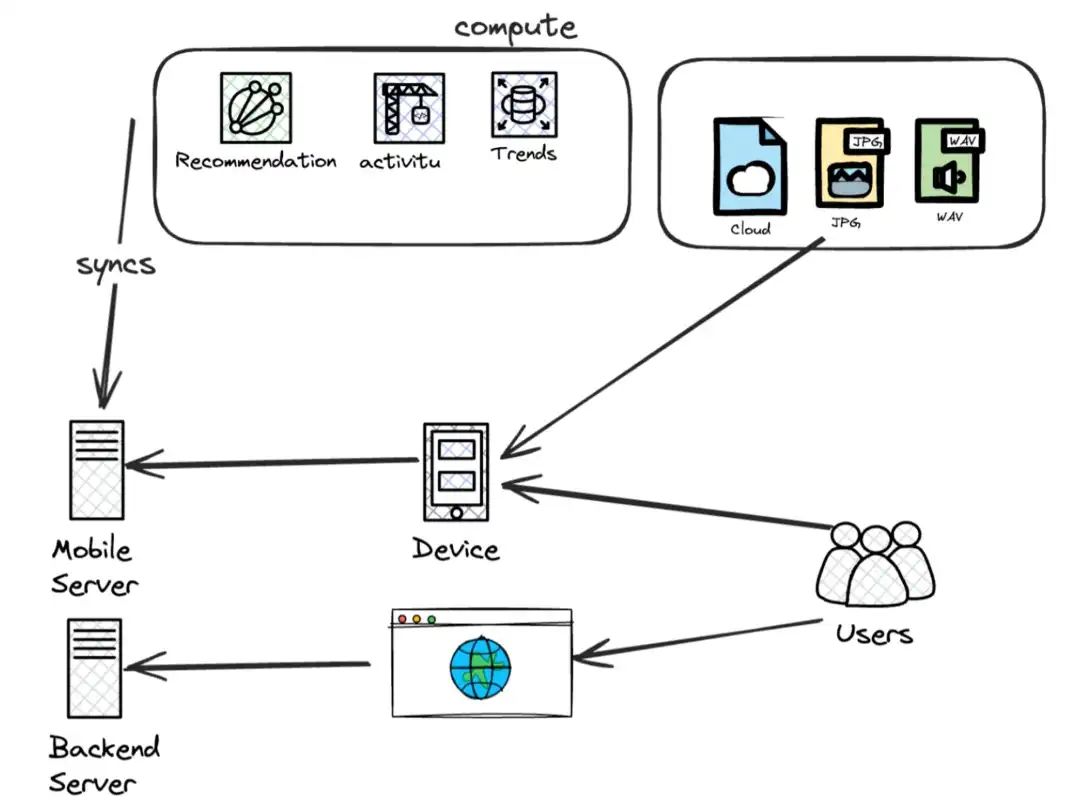
随着计算机用户的迅速增长,2B软件和互联网迎来了爆发式增长,软件研发人员开始研究用户体验和使用习惯。例如:他们做什么的?他们使用系统的频率,以及他们与服务器的距离。
现在,工程师必须监控两件事:客户体验(时延)和服务器健康状况(资源占用)。
这种转变发生得太快,以至于很多工程师根本无法理解各种监控软件和各种监控指标。还有一些软件工程师心安理得认为,为什么要加一些监控指标?又要多维护一些监控软件,增加企业成本,有这个必要吗?当软件出现故障用人盯着不行吗?有什么问题吗?
然而一些早期吃到用户红利的互联网企业,早已把监控当成他们服务器端的基础设施,他们通过这些基础设施察觉用户的一举一动,所以当互联网普及速度超过人们想象时,互联网企业基本呈压倒之势占领了2B软件。小型软件公司逐渐消亡之势,大型互联网公司则越来越强。
不过监控主要由服务器端的基础设施处理。当请求到达服务器时,它们可能已经丢失了客户特定的请求信息,或者需要降低存储信息的成本。因此,我们对基础设施的健康状况有很好的覆盖,但与应用程序和产品行为的关联性很小。
这是无法接受的。只解决这些服务器健康带来的收益并不是那么大。
产品无法在缺乏透明度的情况下运行,因此它们会根据来自终端设备的事件创建自己产品层面的监控指标。
这个时候就带来了公司高层为代表的产品人员和技术工程人员之间的矛盾,监控本身就是针对一些时延指标和服务器健康,为什么要加入业务指标?
突然之间,每个团队都有自己的系统健康状况监控和理解。一片混乱!!
这种意见和观点分散的问题在于,工程团队很少能达成“提高客户体验”共识。他们有办法知道 99% 的请求都有效,但他们无法推断出 99% 的用户是否满意。
例如:虽然产品可以判断出 1% 的用户放弃了直播,但他们无法知道这是否是因为这 1% 的用户在直播中遇到了延迟。
目前可用的工具需要花费大量精力和心血才能回答上述问题。解决这些问题的激励只能锁定额外的 1% 收益。
这就是 9 的意义,从 99 → 99.9% 所需的成本和努力与从 90 → 99% 所需的成本和努力是相同的。
虽然只有一小部分客户体验是通过后端提供的,但整个遥测数据和生命周期都存在于服务器端。基于此,近年来,日志、指标、监控呈蓬勃发展,这包括基本链路追踪工具和 OpenTelemetry 规范。
为了利用可观察性来解答有关最终用户体验的问题,我们需要技术来分析不同细分市场的数据,例如地区、群体和个人用户。然而,目前的工具无法处理这种级别的基数。现有的技术无法提供经济有效的方法来分析不同细分市场的趋势,例如比较去年与今年的“黑色星期五”的销售额。
借助提高成本效益的工具,让监控更贴近客户,它将始终保持凝聚力和联系性。好的,那么我们如何解决这个问题?您认为应该改变什么?
推荐
A Big Picture of Kubernetes
Kubernetes入门培训(内含PPT)
原创不易,随手关注或者”在看“,诚挚感谢!












![记录:[android] SSLHandshakeException: Handshake failed 问题;已解决!](https://img-blog.csdnimg.cn/direct/4ee18a00d0c44ff0adc12da5617b2a17.webp)