0. 序章
0.1 文本说明
所有应用程序操作的名称和编程说明都以黄色背景书写,问题以蓝色背景书写,以方便他们在文本中识别。 在整个课程中,请逐步遵循所有说明,并确保获得预期结果,然后再继续下一部分或问题。
通过在Ubuntu中运行RapidMiner工作环境开启软件,如下所示:
a..初始化RapidMiner应用程序类型:
SETUP RAPIDMINER9c.要在同一终端窗口中运行RapidMiner,请输入指令:
RapidMinerGUI如果要求,请接受许可证条款,但不要要求更新当前版本。
0.2 内容简介
这文介绍了关于决策树的相关内容。决策树是一种著名的分类算法,它通过迭代地将数据分割成子集,使用简单的条件构建决策路径。主要算法由连接的决策节点组成,这些节点生成所谓的分支,这些分支将决策树的根与任何叶子节点连接起来。叶子节点对应于被分配到定义类别中的数据集记录。本课程重点研究基于决策树的监督分类。其主要目标是理解并测试应用于特定数据集的这种监督分类方法的一些配置。
决策树分类算法的工作原理是从一组数据开始,算法试图通过提出问题并根据数据的特征答案来分割数据,每次分割都旨在使得子集比之前更加纯净(即子集中的数据更可能属于同一个类别)。这一过程重复进行,直到满足某个停止条件,例如达到预定的深度或子集中的数据已足够纯净。最终,每个叶子节点代表一个类别,通过从根到叶子的路径,可以根据新数据的特征预测其类别。
本篇文章的目标是通过实践来深入理解决策树分类的工作原理及其不同配置如何影响分类性能。通过应用决策树算法于特定的数据集并调整其配置,将能够观察和分析不同设置对模型性能的影响,从而获得关于如何有效使用决策树进行数据分类的洞见。
0.3 文章背景
利用决策树算法来检验和评估在特定的二元分类问题上的性能。为了熟悉这个问题和数据集的描述,需要阅读以下的信息。所要求的是进行一项详细的个人资料分析,以确定潜在客户是否有资格获得住房贷款。个人资料的相关性根据个人条件和住房融资的区域类型(基本上是城市、半城市和农村)而有所不同。问题是,是否能够利用在线申请表提供的个人数据,自动化贷款资格审查过程。将使用一个数据集(稍后复制)进行测试,该数据集包含根据以下属性集合的贷款资格决策示例。
目标是探索如何使用决策树模型根据客户的个人信息自动判断其是否符合住房贷款的条件。这涉及到分析客户的多个属性,如收入水平、就业状态、教育背景、家庭状况以及所求贷款的地理位置(城市、半城市或农村)等因素,来决定他们是否有资格获得贷款。通过这种方式,银行或贷款机构可以更高效、更快速地处理贷款申请,同时也能减少因主观判断而导致的错误。这种自动化处理贷款资格的方法,不仅能提高处理速度和准确性,也有助于银行更好地管理和评估贷款风险。
0.4 背景分析
| Attribute name 属性名称 | Description说明 |
| Loan ID | ldentification number of the loan application.贷款申请的识别号码。 |
| Gender | “Male” or Female. Gender of the main applicant.男性 还是 女性。 主申请人的性别。 |
| Married | Yes” or “No”. Indicates if the main applicant is married.是 "或 "否"。表示主申请人是否已婚。 |
| Dependents | “0”,“1”“2”, or “3+” (three or plus). Number of persons that dependeconomically on the main applicant.“0"、"1"、"2 "或 "3+"(三人或三人以上)。在经济上依赖主申请人的人数"。 |
| Education | Graduate” or "Not Graduate” Indicates if the main applicant obtained or not a university degree. |
| Self Employed | "Yes” or “No”. Indicates if the main applicant is self-employed or not. |
| Income1 | Amount of the main applicant monthly income. |
| Income2 | Amount of the coapplicant monthly income. |
| Amount | Estimated loan amount (assumed to be actually multiplied by 1.000) |
| Term学期 | Necessary number of months to reimburse the loan.偿还贷款所需的月数 |
| Credit History | “1”(Yes) or “0”(No). Indicates if the main applicant has or not a positiverecord of repaying debts in the past. |
| Property Area | “Urban”, “Rural, or “Semiurban”. Type of area where housing to be financed is located. |
| Status | "y”(Yes) or "N”(No). Indicates if the loan application is eligible or not. |
问题1:这些属性的数据类型可能是什么?请在下表中每个属性名称的右边写出相应的类型。
RapidMiner是一款流行的数据科学平台,它支持多种数据类型,以便于处理各种数据分析任务。在RapidMiner中,数据类型主要用于定义属性(或列)的性质,这对于数据预处理、分析和建模至关重要。以下是RapidMiner中常见的数据类型:
Integer(整数): 用于表示没有小数部分的数值,例如年龄、人数等。
Real(实数): 用于表示有小数部分的数值,例如体重、温度等。
Date/Time(日期/时间):用于表示日期和时间信息。这种类型的数据可以表示为日期、时间或日期时间的组合,允许进行时间序列分析或时间相关的数据处理。
Polynomial(多项式):类似于名义型,但是它用于表示两个以上的值,这些值没有固定的顺序。多项式数据类型适用于多类别数据,其中类别之间没有明确的等级或顺序。
Binomial(二进制):一种特殊的名义型数据,仅包含两个类别(如是/否、真/假)。在某些情况下,二进制数据也可以表示为0和1。
| Attribute name | respective types |
| Loan ID | Polynomial |
| Gender | Binomial |
| Married | Binomial |
| Dependents | Polynomial |
| Education | Binomial |
| Self Employed | Binomial |
| Income1 | Integer |
| Income2 | Integer |
| Amount | Integer |
| Term | Integer |
| Credit History | Binomial |
| Property Area | Polynomial |
| Status | Binomial |
1. 开始教程
1.1 数据集的初步分析
在操作子窗口Operators中激活Read csv:DatAccess Files > Read > Read csv。将其拖放到处理Process 工作区中。在Read csv的 Parameters子窗口中,确认以下项目已被选中:use quotes, parse numbers, first row as names, read not matching values asmissing.。点击Import Configuration Wizard... 从你的目录中读取loan_data.csv文件。点击Next,改变文件编码格式 File Encoding为UTF-8,并在列分隔符Column Separator下拉菜单中选择逗号选项Comma “,” 。检查数据集。
在in the Import Data window.中,验证属性的 types and roles 类型和角色。根据列出的值,将属性定义为二项式或多项式binomial or polynominal,每当适用时。确保Dependents属性是多项式polynominal的(这避免了如果属性类型设置为整数,则将值3+视为缺失integer)。同时验证最后一个属性“Status”是带有角色标签的二项式binomial with label as role。然后点击Finish按钮。如果还没有完成,将 Read Csv操作符的输出 out 端口连接到处理 Process子窗口右侧的结果res 端口。

问题2:运行过程并检查结果Results视图中的ExampleSet (Read CSV)标签。类标签是如何与定义每条记录的属性区分开的?数据集由多少条记录组成,在多少条记录中存在缺失数据?
一共614条记录,存在丢失数据的134条,存在未丢失数据的480条,标签全部存在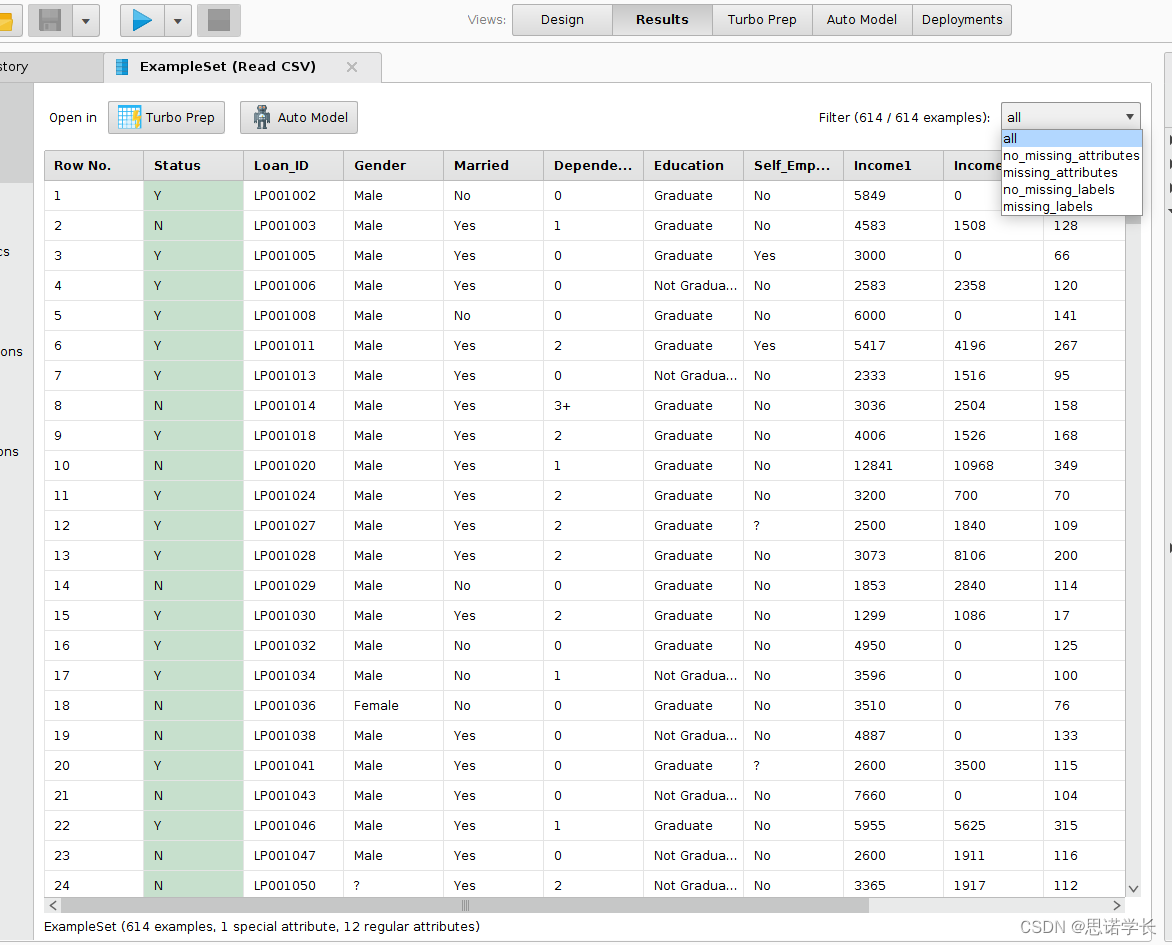
问题3:是否有任何缺失的贷款决定(即status状态值)?
没有缺失的标签记录
问题4:在所有数据缺失的记录中,哪些属性是完整的,哪些属性是不完整的?
完整的:status,Loan_ID,Education,Income1,Income2,Propertry_Area
不完整的:Gender,Married,Dependets,Self_Employed,Amount,Term,Credit_History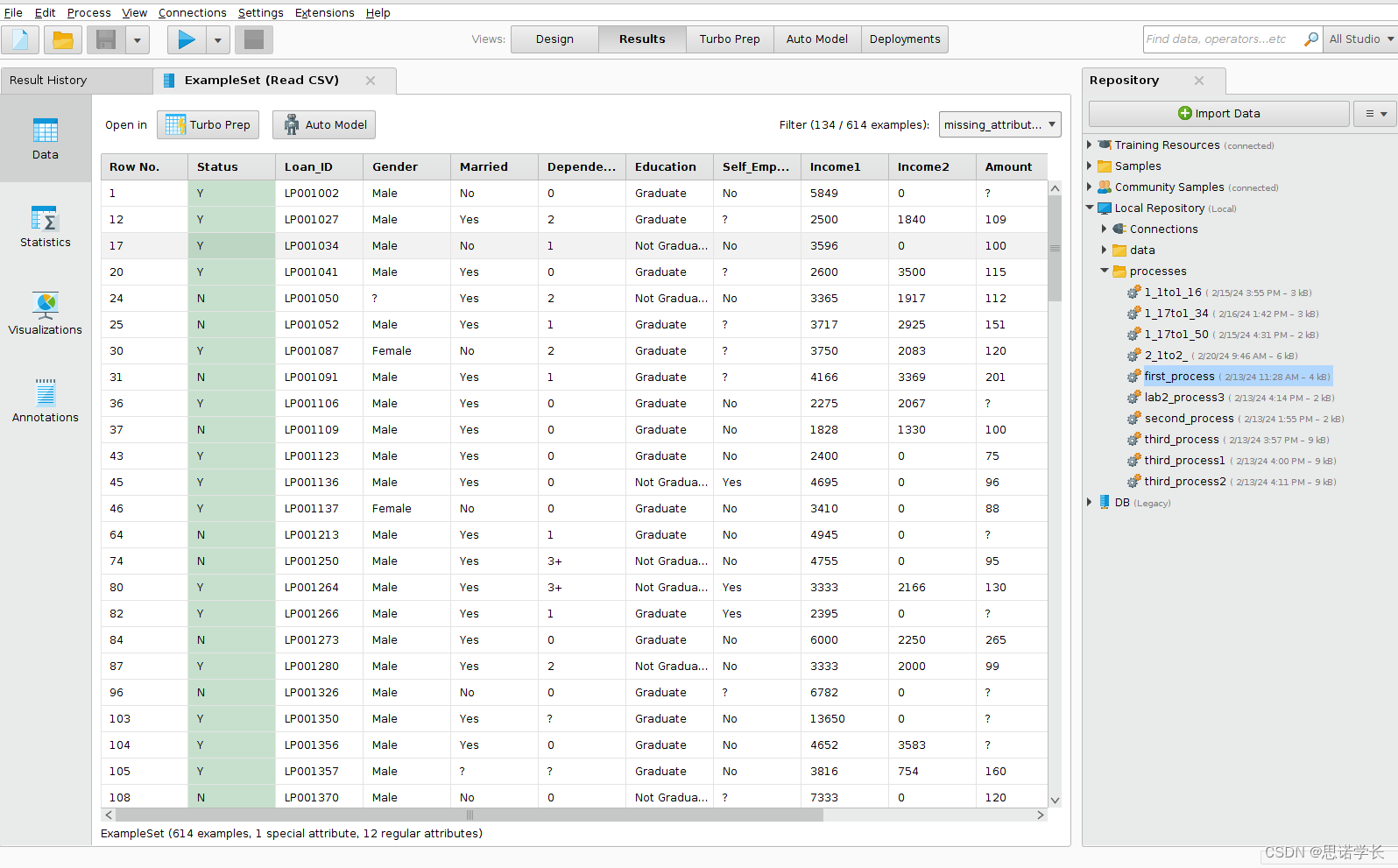
问题5: 数据集中每个类别有多少条记录,它们各自所占的百分比是多少?
Y:422
N:192
进行探索性数据分析以更好地理解数据集的一些初步观察。
问题6: 描述名义属性的主要趋势,并解释显示在两个属性名称上的警告标志。
Gender
Using this data column may potentially lead to biased models or decisions.
Please be careful and check if using this data is problematic.
This column was flagged since its name contains a suspicious term: gender
Do not rely on software alone to detect and mitigate bias. Learn more
at https://info.rapidminer.com/bias.
性别
使用此数据列可能会导致模型或决策出现偏差。
请注意并检查使用该数据是否有问题。
此列已被标记,因为其名称包含可疑术语:性别
不要仅仅依靠软件来检测和减少偏差。了解更多
请访问 https://info.rapidminer.com/bias。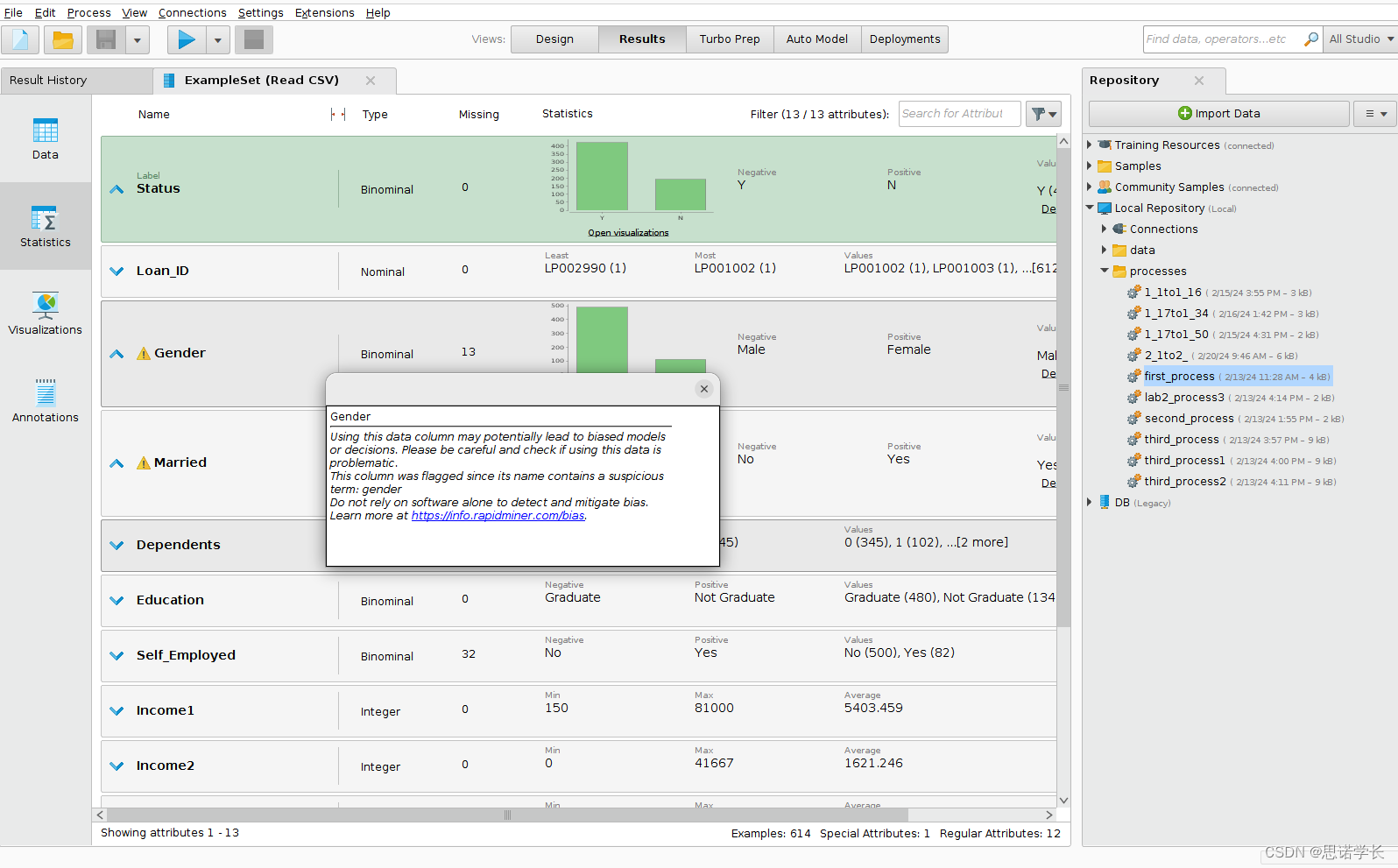
问题7: 非常高的第二收入是否会提高获得贷款批准的可能性?
无明显对应关系

问题8: 教育属性Education、贷款金额Amount和收入1Income1之间是否存在关系?
毕业且收入高的就有几率获得更高的贷款
问题9: 是否有任何荒谬或矛盾的记录?如果是这样,它们的模式是什么?
暂时未发现问题10: 使用Plot type中平行坐标图类型 Parallel Coordinates 提出更多描述数据集的观察。
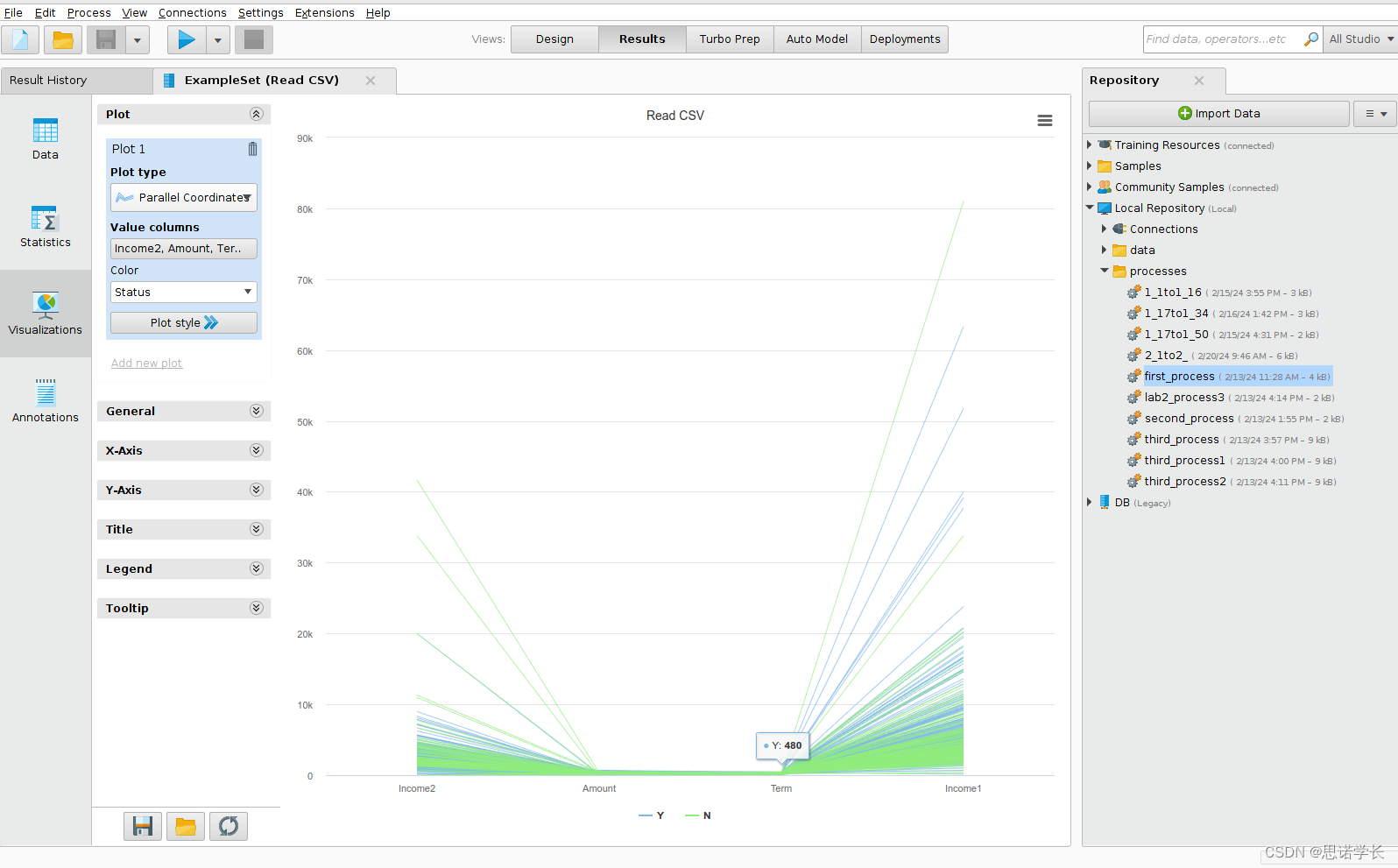
1.2 决策树Decision Tree
为了使用决策树设置一个分类原型,请按下图所示配置过程。选择必要的操作符如下:
在 Operators子窗口中查找 Split,然后选择Split Data这个operator:Blending → Examples → Sampling → Split Data
查找 Decision 并选择 决策树Decision Tree 运算符:Modeling → Predictive →Trees Decision Tree
查找Apply并选择Apply Model操作符Scoring → Confidences →Apply Model
查找 Performance ,选择 Performance (Binominal Classification) 操作符:Validation → Performance → Predictive → % Performance (Binominal Classification)

在Split Data操作符的Parameters参数子窗口中,将抽样类型sampling type保留为自动automatic,然后点击“分区”partitions label标签右侧的“编辑枚举Edit Enumeration”按钮。在“编辑参数列表:分区Edit Parameter List: partitions”窗口的ratio标签下添加两行,值分别为0.7和0.3(分别在不同行中,并按此顺序)。
问题11: 分割数据操作符的使用目的是什么,0.7和0.3的值分别是什么意思?
分割数据操作符通常用于将数据集分割成训练集和测试集,
这对于机器学习和数据科学项目中的模型训练和评估是非常重要的。
在这里,0.7和0.3的值分别表示数据集将被分割成70%的训练数据
和30%的测试数据。这样的分割比例有助于确保模型在足够大的数据
集上训练,同时留有足够的数据来测试模型的性能,以避免过拟合或
欠拟合。问题12: 两个分割数据操作符输出端口的内容是什么?
分割数据操作符的两个输出端口通常包含以下内容:一个端口输出训练数据集,
另一个端口输出测试数据集。具体来说,按照0.7和0.3的分割比例,如果原
始数据集包含全部的数据,那么第一个输出端口将包含70%的数据作为训练
集,第二个输出端口将包含剩余的30%数据作为测试集。
问题13: criterion参数的五个可能值的目的是什么?
Decision Tree(决策树)操作符的criterion参数指的是在
构造决策树时用于分割节点的准则。这些选项通常包括度量数据分割质量的
不同方法,如信息增益、增益比、基尼不纯度等。每个选项代表一种不同的
策略,用于评估分割的好坏,进而决定在构建树的过程中如何选择分割点。
不同的criterion可能会影响模型的性能和复杂度,因此选择最适合特定
数据集和问题的准则是很重要的。
问题14:描述Apply Model 操作符的两个输入inputs


问题15:Apply Model 操作符的两个输出outputs内容是什么?
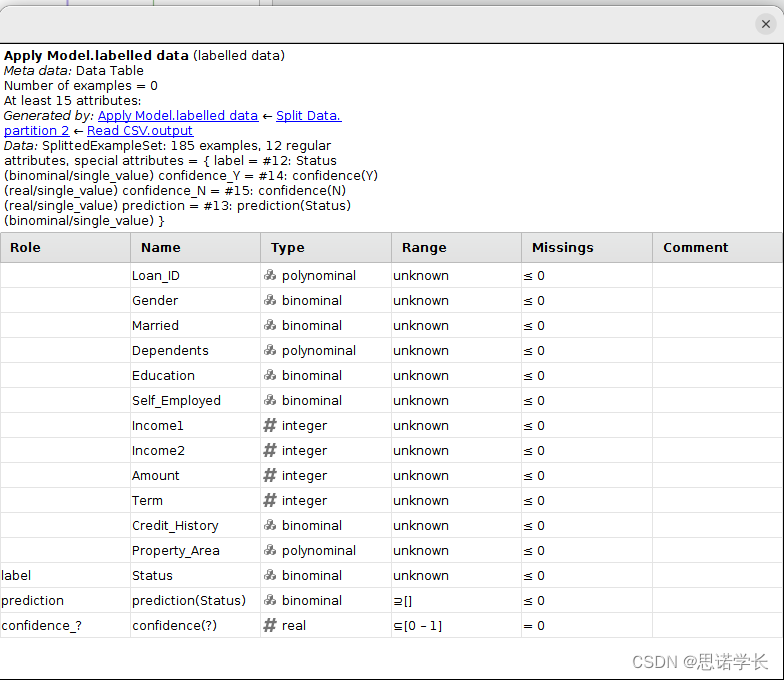
问题16 :保持Performance 操作符的默认参数parameters,此操作符的目的是什么?
按照以下方式配置Decision Tree操作符:准则使用增益比 criterion > gain ratio;maximal depth > 20; confidence > 0.25;minimal gain > 0.1;保留剪枝和预剪枝选项apply pruning与 apply prepruning 被勾选;最小叶节点大小大于2minimal leaf size > 2。运行配置的过程原型。在Results 结果视图中查看显示的Tree (Decision Tree) 标签页。将鼠标悬停在叶子上几秒钟将显示每个元素的补充信息。

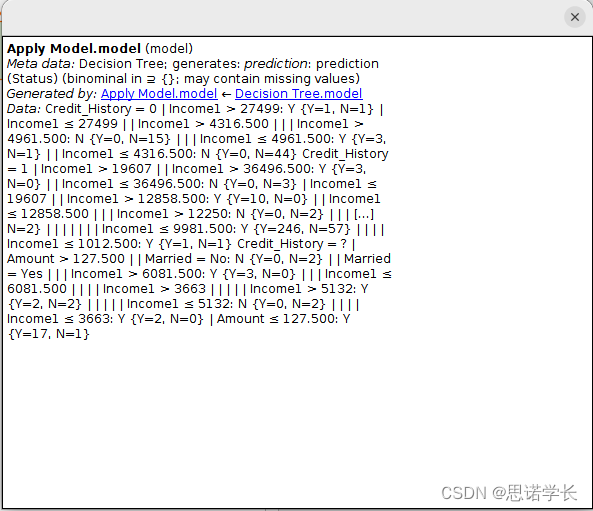
问题17:构成结果决策树的节点nodes和叶子 leafs有多少个?
7个节点,9个叶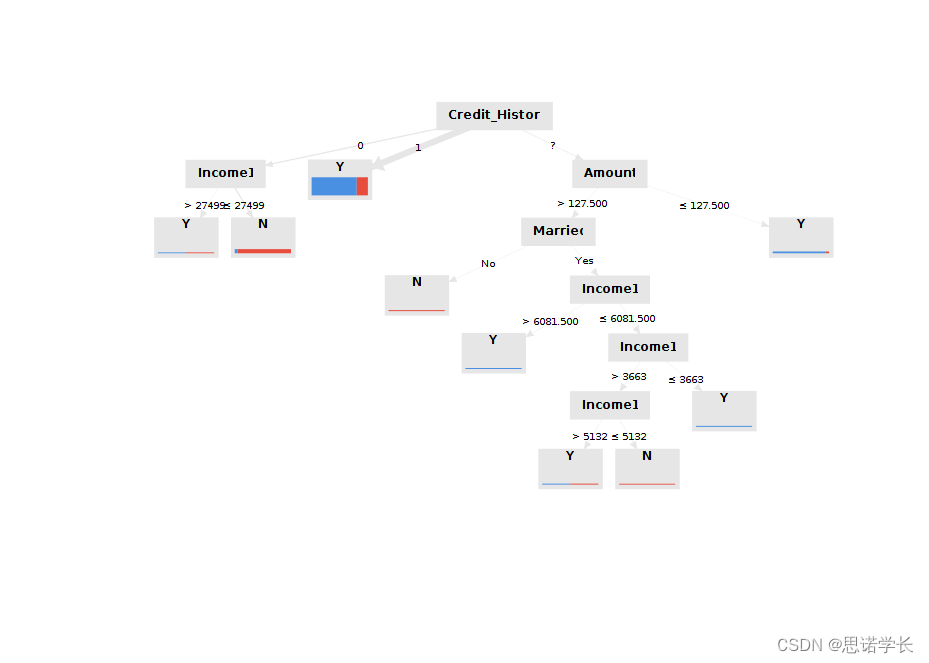
问题18:在树中可以识别出多少个“纯”叶子pure leaves (即只包含一个类的记录)?这些“纯”叶子识别出了哪个类?
5个纯净叶
问题19:在这个决策过程中最重要的属性是什么,为什么?
Income1,作为非叶节点出现次数最多问题20:决策树是否有未考虑的属性?如果有,是哪些?
除了Income1,Credit_Histor,Amount,Married其他都没有出现在决策树中问题21:解释 Tree (Decision Tree) 标签页的描述面板显示的内容。
描述了树的执行逻辑Tree
Credit_History = 0
| Income1 > 27499: Y {Y=1, N=1}
| Income1 ≤ 27499: N {Y=3, N=60}
Credit_History = 1: Y {Y=267, N=66}
Credit_History = ?
| Amount > 127.500
| | Married = No: N {Y=0, N=2}
| | Married = Yes
| | | Income1 > 6081.500: Y {Y=3, N=0}
| | | Income1 ≤ 6081.500
| | | | Income1 > 3663
| | | | | Income1 > 5132: Y {Y=2, N=2}
| | | | | Income1 ≤ 5132: N {Y=0, N=2}
| | | | Income1 ≤ 3663: Y {Y=2, N=0}
| Amount ≤ 127.500: Y {Y=17, N=1}

问题22: 在什么条件下获得树的最短决策路径,结果是什么?
在Credit_Histor为1的时候
问题23:你会信任这个决策吗?为什么?
不信任,因为未处理缺失值,而且参考的因素过于少查看结果 Results视图中的 % Performance 标签页的 % Performance Vector (Performance) tab 显示的准确率值 accuracy 。
问题24:准确率accuracy值表达了什么?
78.38%(121+24)/(121+34+6+24)=78.8%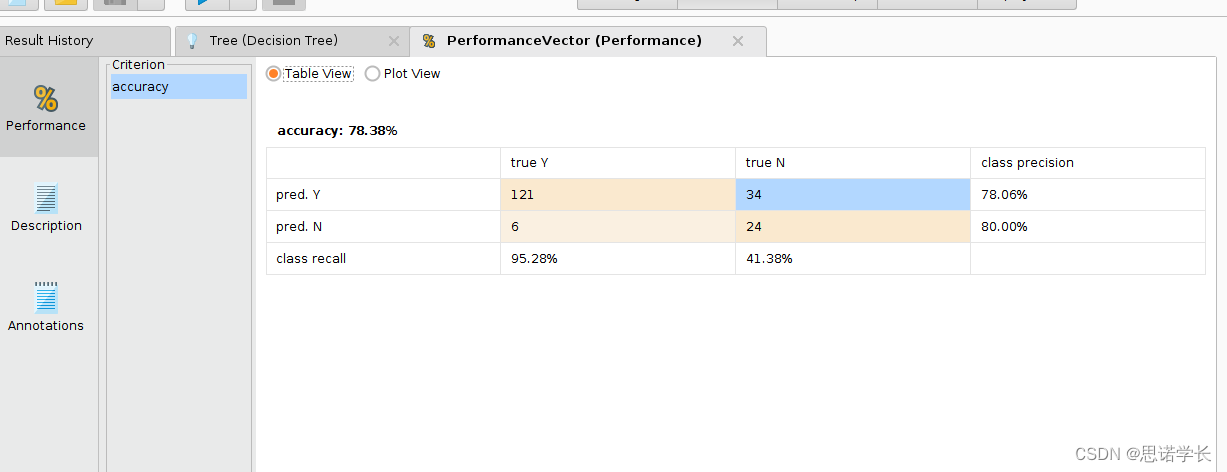
问题25:在所有相关记录中,哪个类别的正确检索记录的相对数量(召回率) (recall) 较低?
召回率(Recall):在所有相关记录中,正确检索到的记录的比例。用公式表示为:召回率 = (正确检索到的记录数)/(所有相关记录数)。如果某个类别的召回率较低,这意味着系统在检索这个类别的相关信息时遗漏了许多相关记录。这可能是因为模型对该类别的识别能力不足,或者该类别的记录较难以区分。
对于哪个类别的召回率低,这取决于具体的数据集和模型性能。如果一个类别的相关记录经常被忽略,那么该类别的召回率就低。这意味着对于这个类别,模型没有很好地捕捉到所有相关的记录,可能导致信息的遗漏。
41.38%
24/(34+24)
问题26:两个类别的所有检索记录中正确检索记录的相对数量(精确度) (precision)值是否有显著差异?这意味着什么?
精确率(Precision):在所有检索到的记录中,正确检索的记录的比例。用公式表示为:精确率 = (正确检索到的记录数)/(所有检索到的记录数)。如果两个类别的精确率值存在显著差异,这表明模型在识别这两个类别的准确性上存在差距。对于精确率较高的类别,意味着检索到的记录中,相关记录的比例较高,模型对这个类别的识别较为准确。相反,精确率较低的类别意味着模型在检索时产生了较多的不相关记录,准确性较低。
这个差异说明了模型对不同类别的识别能力不均衡。在实践中,可能需要通过模型调整、数据平衡或其他技术手段来改善特定类别的精确率,从而提高模型整体的性能。
综上所述,召回率低意味着许多相关记录被遗漏,影响了信息的完整性。精确率的显著差异意味着模型在不同类别的识别准确性上不均衡,可能需要针对性的改进措施。
)

)


(华中科技大学) 中国大学MOOC答案2024版100分完整版)













