💛前情提要💛
本文是传知代码平台中的相关前沿知识与技术的分享~
接下来我们即将进入一个全新的空间,对技术有一个全新的视角~
本文所涉及所有资源均在传知代码平台可获取
以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦!!!
以下内容干货满满,跟上步伐吧~
📌导航小助手📌
- 💡本章重点
- 🍞一. 概述
- 🍞二. 摘要
- 🍞三. 引言
- 🍞四. THOR
- 🍞五. THOR核心代码
- 🍞六.实验结果
- 🫓总结
💡本章重点
- 以思维链为线索推理隐含情感
🍞一. 概述
本文主要对 2023ACL 论文《Reasoning Implicit Sentiment with Chain-of-Thought Prompting》主要内容进行介绍。
🍞二. 摘要
虽然情绪分析任务中通常根据输入文本中的关键意见表达来确定给定目标的情绪极性,但在隐式情绪分析(ISA)中,意见线索通常是隐含或者模糊的。因此,检测隐含情绪需要常识和多跳推理能力来推断意见的潜在意图。在思想链(CoT)思想的启发,本文引入了一个三跳推理(THOR)CoT框架来模拟ISA的模拟人类推理的过程。THOR设计了一个三步提示原则,逐步诱导隐含的方面、观点,最后是情绪的极性。THOR+Flan-T5(11B)在监督微调下将数据集最优性能(SoTA)提高了6%以上。更引人注目的是,THOR+GPT3(175B)在零样本设置下将SoTA提高了50%以上。
🍞三. 引言

情感分析(SA)旨在基于输入文本检测对给定目标的情绪极性。SA可分为显性SA(ESA)和隐性SA(ISA),前者是当前的主流任务,他的情感表达会明确出现在文本中。
因此ISA更具挑战性,因为在ISA中,输入仅包含事实描述,没有直接给出明确的意见表达。例如,给定一个文本“Try the tandoori salmon!”,由于没有显著的提示词,几乎所有现有的情绪分类都预测“tandoori salmon”为中性极性。
人类很容易准确地确定情绪状态,因为我们总是掌握在文本后面隐含的真实意图或观点。因此,在没有真正理解情绪是如何被激发的情况下,传统的SA方法对ISA是无效的。
🍞四. THOR
近期大模型的崛起,让我们看到了机器对文本的理解有了新的高度。受到大模型中CoT的启发,文章提出了THOR( Three-hop Reasoning CoT framework),一个三段式的提问框架,能够通过循循善诱地方法,很好的让机器对隐形情感进行挖掘并预测,提升了ISA任务的性能。

如上图所示:
Traditional Prompting,表明传统的提示学习方法就是直接问模型,这句话中这个词的情感极性是什么。
Three-hop Reasoning with CoT Prompting,则是本文提出基于大模型思维链(CoT)的方法,提出的三段式提问框架。
- 首先询问句子在讲述方面词的什么方面;
- 其次,将回答整合后,将整合后的答案继续问方面词背后有什么隐含观点;
- 最后,再次整合前面的回答,最后问方面词的情感极性是什么。
通过THOR我们可以看到,使用CoT的方法循循善诱模型得到的答案为positive是正确的,而传统的提问时neutral是不正确的。
THOR框架具体设置如下:
假设我们要预测的句子为:“The new mobile phone can be just put in my pocket.”
其中要预测的方面词为“The new mobile phone”
不妨设句子为 X,设方面词为 t

以上述设置为例:
第一步,模型的输入为 Given the sentence “X”, which specific aspect of t is possibly mentioned?
假设模型得到的结果为"The specific aspect of the new mobile phone mentioned in the sentence is the size or portability",记为 A

第二步,模型的输入为Given the sentence “X”, A(第一问结果). Based on the common sense, what is the implicit opinion towards the mentioned aspect of the new mobile phone, and why?
假设模型输出为"Based on the mentioned aspect of size and portability, the sentence implies that the phone is small enough to fit in the speaker’s pocket. According to common sense, the implicit opinion of speaker towards the portability is good, because the speaker is able to easily carry the phone with them by placing it in their pocket, and find the phone to be convenient and easy to use." 这个答案不妨记作 O。

第三步,模型的输入为Given the sentence “X”, A(第一问结果), O(第二问的结果). Based on such opinion, what is the sentiment polarity towards the new mobile phone?
此时假设模型的输出为 “The sentiment polarity towards the new mobile phone based on the given sentence is positive. The speaker finds the phone to be convenient and easy to use, implying having a favorable view of the phone.”
此时我们可以看到,模型得到了我们需要的预测结果为 positive。

🍞五. THOR核心代码
def prompt_for_aspect_inferring(context, target):new_context = f'Given the sentence "{context}", 'prompt = new_context + f'which specific aspect of {target} is possibly mentioned?'return new_context, promptdef prompt_for_opinion_inferring(context, target, aspect_expr):new_context = context + ' The mentioned aspect is about ' + aspect_expr + '.'prompt = new_context + f' Based on the common sense, what is the implicit opinion towards the mentioned aspect of {target}, and why?'return new_context, promptdef prompt_for_polarity_inferring(context, target, opinion_expr):new_context = context + f' The opinion towards the mentioned aspect of {target} is ' + opinion_expr + '.'prompt = new_context + f' Based on such opinion, what is the sentiment polarity towards {target}?'return new_context, prompt
🍞六.实验结果
文章实验主要是基于Flan-T5大模型做的(因为这是为数不多开源且效果不错的大模型)
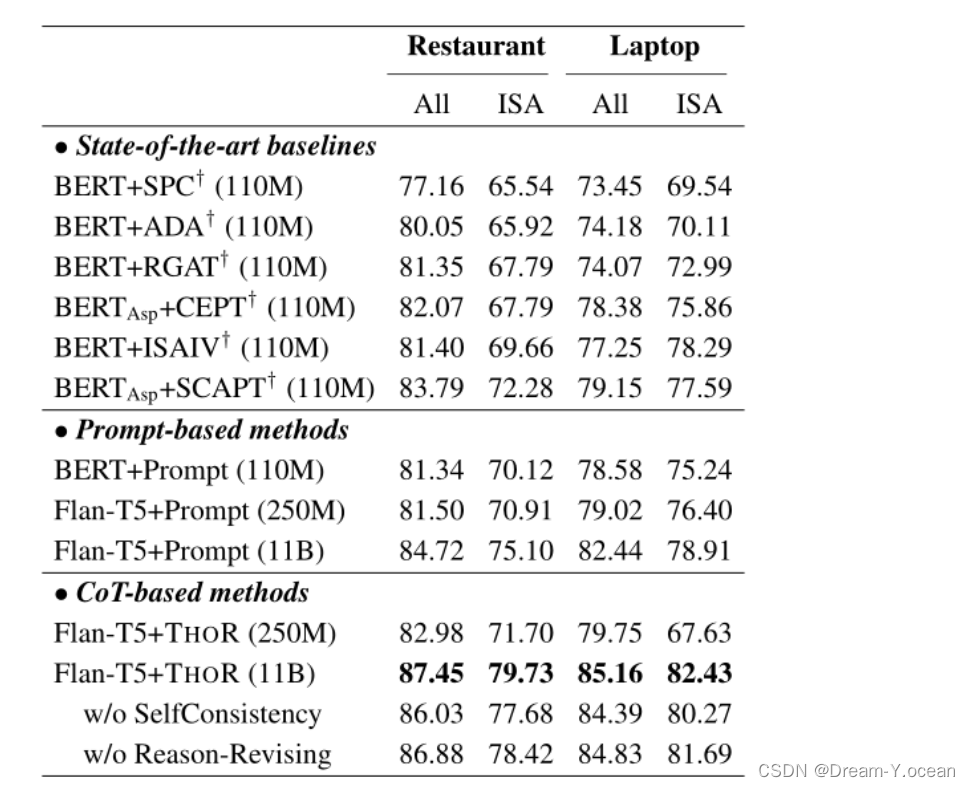
这个结果是使用数据集进行监督微调训练后的结果,监督微调大模型确实能够使得模型有更好的表现,但是随着现在预训练大模型越来越大,我们微调的成本也越来越大了。
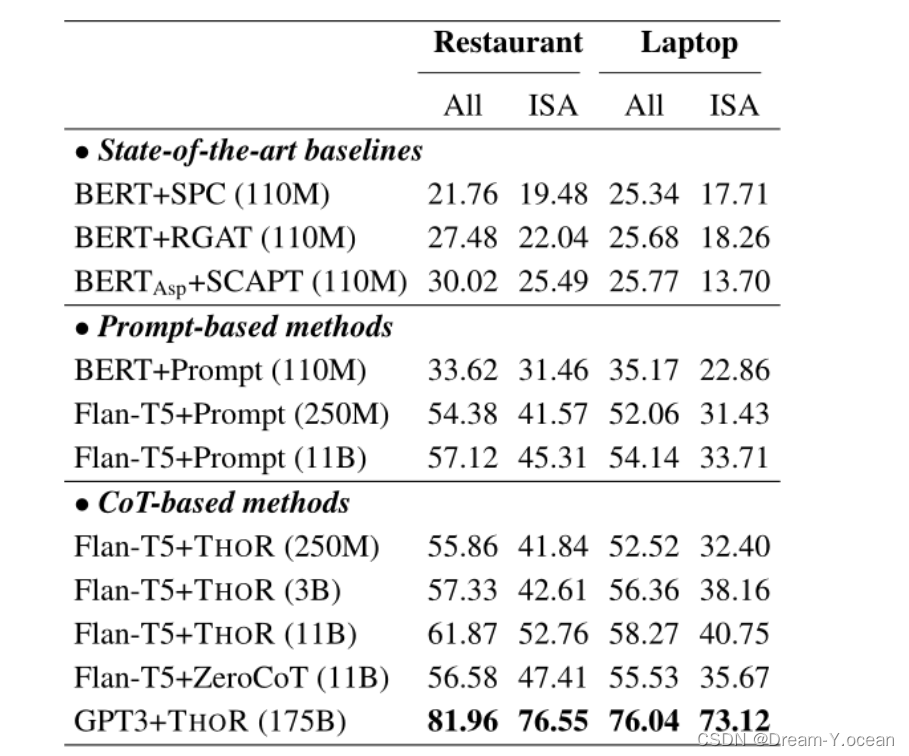
这个结果是使用zero-shot零样本得到的结果(不对大模型进行微调,直接通过THOR框架或者直接prompt询问结果,省去了微调大模型的时间和需要花费的资源,但是整体效果不如监督微调的结果)。
可以看得出使用THOR的方法比直接prompt效果好,并且当用GPT3作为大模型询问时,效果明显好很多,因为GPT3的参数量远大于Flan-T5而且也并不开源,使用起来可能需要花点钱。这说明目前大模型对自然语言的理解缺失已经有了质的飞跃了。
代码运行
- 首先创建虚拟环境
conda create -n thor python=3.8
- 按照自己电脑的cuda版本安装pytorch
nvidia-smi
然后去 pytorch 官网查看对应gpu版本的安装命令
# CUDA 10.2
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=10.2 -c pytorch# CUDA 11.3
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=11.3 -c pytorch -c conda-forge# CUDA 11.7
conda install pytorch==1.13.0 torchvision==0.14.0 torchaudio==0.13.0 pytorch-cuda=11.7 -c pytorch -c nvidia
- 最后安装一些必备的库
pip install -r requirements.txt
-
打开 main.py 后可以看到参数的设置,直接运行是进行laptop数据集+THOR框架+零样本进行评估
-
目前支持prompt和zero-shot两种,使用GPT3因为需要密钥,需要自己去获取。
if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('-c', '--cuda_index', default=0)parser.add_argument('--reasoning', default='thor', choices=['prompt', 'thor'],help='with one-step prompt or multi-step thor reasoning')parser.add_argument('-z', '--zero_shot', action='store_true', default=True,help='running under zero-shot mode or fine-tune mode')parser.add_argument('-d', '--data_name', default='laptops', choices=['restaurants', 'laptops'],help='semeval data name')parser.add_argument('-f', '--config', default='./config/config.yaml', help='config file')args = parser.parse_args()template = Template(args)template.forward()
🫓总结
综上,我们基本了解了“一项全新的技术啦” 🍭 ~~
恭喜你的内功又双叒叕得到了提高!!!
感谢你们的阅读😆
后续还会继续更新💓,欢迎持续关注📌哟~
💫如果有错误❌,欢迎指正呀💫
✨如果觉得收获满满,可以点点赞👍支持一下哟~✨
【传知科技 – 了解更多新知识】

(华中科技大学) 中国大学MOOC答案2024版100分完整版)














string模拟实现)
)

