⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️
🐴作者:秋无之地🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。
🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、留言💬、关注🤝,关注必回关
上一篇文章已经跟大家介绍过《数据集成:数据挖掘的准备工作之一》,相信大家对数据集成都有一个基本的认识。下面我讲一下:数据变换:数据挖掘的准备工作之一。
一、数据变换重要性
上一节中讲了数据集成,今天来说一下数据变换。
举个简单的例子:
如果一个人在百分制的考试中得了 95 分,你肯定会认为他学习成绩很好,如果得了 65 分,就会觉得他成绩不好。如果得了 80 分呢?你会觉得他成绩中等,因为在班级里这属于大部分人的情况。
为什么会有这样的认知呢?这是因为我们从小到大的考试成绩基本上都会满足正态分布的情况。什么是正态分布呢?正态分布也叫作常态分布,就是正常的状态下,呈现的分布情况。
比如你可能会问班里的考试成绩是怎样的?这里其实指的是大部分同学的成绩如何。以下图为例,在正态分布中,大部分人的成绩会集中在中间的区域,少部分人处于两头的位置。正态分布的另一个好处就是,如果你知道了自己的成绩,和整体的正态分布情况,就可以知道自己的成绩在全班中的位置。
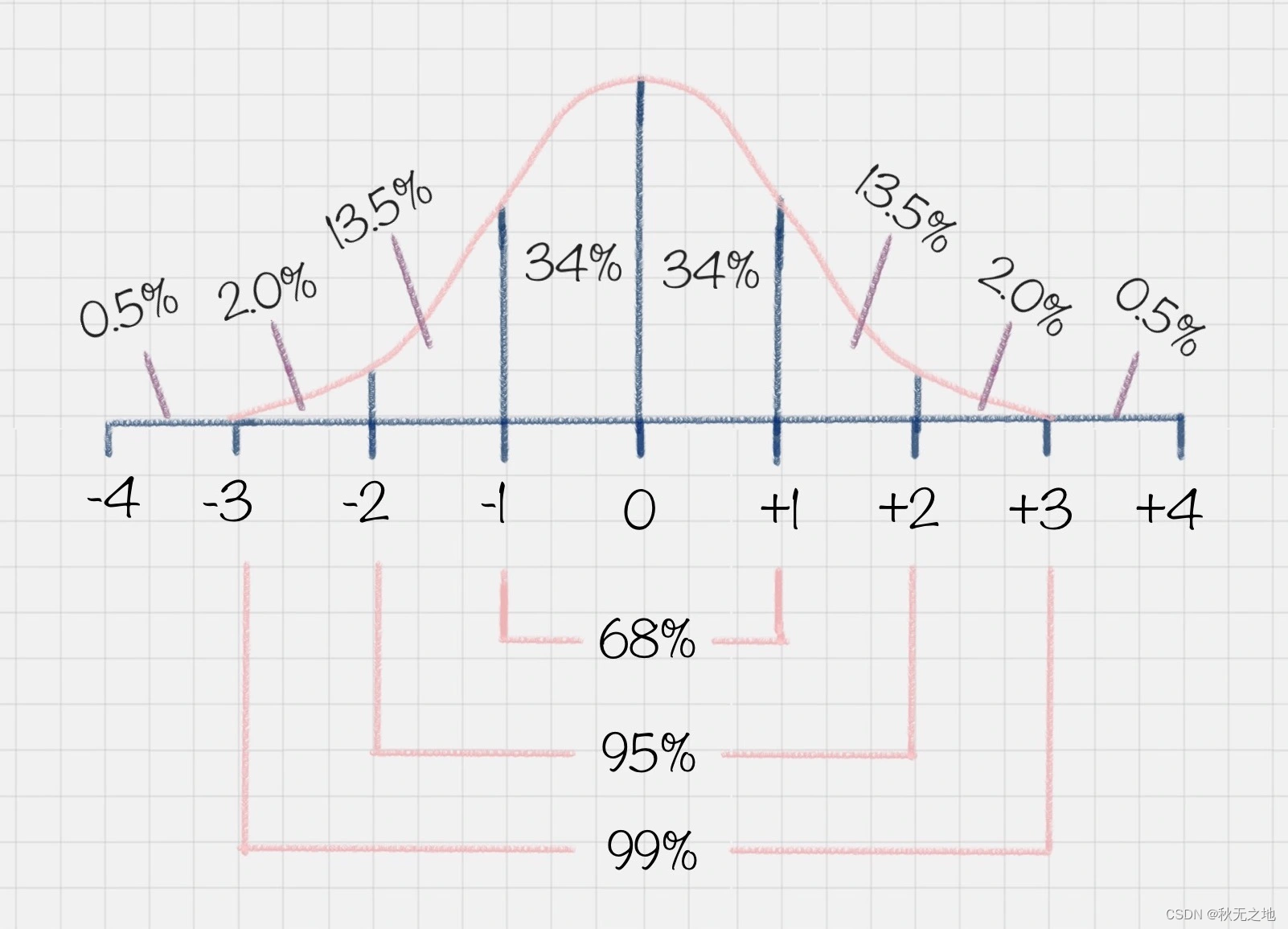
如果大部分人成绩都“不及格”,最后在大家激烈的讨论声中,老师会将考试成绩做规范化处理,从而让成绩满足正态分布的情况。因为只有这样,成绩才更具有比较性。所以正态分布的成绩,不仅可以让你了解全班整体的情况,还能了解每个人的成绩在全班中的位置。
上述的规范化处理就是数据分析中的数据转换。
二、数据变换是数据准备的重要环节
数据变换是数据准备的重要环节,它通过数据平滑、数据聚集、数据概化和规范化等方式将数据转换成适用于数据挖掘的形式。
我们再来举个例子,假设 A 考了 80 分,B 也考了 80 分,但前者是百分制,后者 500 分是满分,如果我们把从这两个渠道收集上来的数据进行集成、挖掘,就算使用效率再高的算法,结果也不是正确的。因为这两个渠道的分数代表的含义完全不同。
所以说,有时候数据变换比算法选择更重要,数据错了,算法再正确也是错的。你现在可以理解为什么 80% 的工作时间会花在前期的数据准备上了吧。
那么如何让不同渠道的数据统一到一个目标数据库里呢?这样就用到了数据变换。
在数据变换前,我们需要先对字段进行筛选,然后对数据进行探索和相关性分析,接着是选择算法模型(这里暂时不需要进行模型计算),然后针对算法模型对数据的需求进行数据变换,从而完成数据挖掘前的准备工作。

下面这些是常见的变换方法:
- 数据平滑:去除数据中的噪声,将连续数据离散化。这里可以采用分箱、聚类和回归的方式进行数据平滑,我会在后面给你讲解聚类和回归这两个算法;
- 数据聚集:对数据进行汇总,在 SQL 中有一些聚集函数可以供我们操作,比如 Max() 反馈某个字段的数值最大值,Sum() 返回某个字段的数值总和;
- 数据概化:将数据由较低的概念抽象成为较高的概念,减少数据复杂度,即用更高的概念替代更低的概念。比如说上海、杭州、深圳、北京可以概化为中国。
- 数据规范化:使属性数据按比例缩放,这样就将原来的数值映射到一个新的特定区域中。常用的方法有最小—最大规范化、Z—score 规范化、按小数定标规范化等,我会在后面给你讲到这些方法的使用;
- 属性构造:构造出新的属性并添加到属性集中。这里会用到特征工程的知识,因为通过属性与属性的连接构造新的属性,其实就是特征工程。比如说,数据表中统计每个人的英语、语文和数学成绩,你可以构造一个“总和”这个属性,来作为新属性。这样“总和”这个属性就可以用到后续的数据挖掘计算中。
在这些变换方法中,最简单易用的就是对数据进行规范化处理。下面我来给你讲下如何对数据进行规范化处理。
三、数据规范化的几种方法
1、Min-max 规范化
Min-max 规范化方法是将原始数据变换到[0,1]的空间中。
用公式表示就是:新数值 =(原数值 - 极小值)/(极大值 - 极小值)。
2、Z-Score 规范化
假设 A 与 B 的考试成绩都为 80 分,A 的考卷满分是 100 分(及格 60 分),B 的考卷满分是 500 分(及格 300 分)。虽然两个人都考了 80 分,但是 A 的 80 分与 B 的 80 分代表完全不同的含义。
那么如何用相同的标准来比较 A 与 B 的成绩呢?Z-Score 就是用来可以解决这一问题的。
我们定义:新数值 =(原数值 - 均值)/ 标准差。
假设 A 所在的班级平均分为 80,标准差为 10。B 所在的班级平均分为 400,标准差为 100。那么 A 的新数值 =(80-80)/10=0,B 的新数值 =(80-400)/100=-3.2。
那么在 Z-Score 标准下,A 的成绩会比 B 的成绩好。
我们能看到 Z-Score 的优点是算法简单,不受数据量级影响,结果易于比较。不足在于,它需要数据整体的平均值和方差,而且结果没有实际意义,只是用于比较。
3、小数定标规范化
小数定标规范化就是通过移动小数点的位置来进行规范化。小数点移动多少位取决于属性 A 的取值中的最大绝对值。
举个例子,比如属性 A 的取值范围是 -999 到 88,那么最大绝对值为 999,小数点就会移动 3 位,即新数值 = 原数值 /1000。那么 A 的取值范围就被规范化为 -0.999 到 0.088。
上面这三种是数值规范化中常用的几种方式。
四、Python 的 SciKit-Learn 库使用
SciKit-Learn 是 Python 的重要机器学习库,它帮我们封装了大量的机器学习算法,比如分类、聚类、回归、降维等。此外,它还包括了数据变换模块。
我现在来讲下如何使用 SciKit-Learn 进行数据规范化。
1. Min-max 规范化
我们可以让原始数据投射到指定的空间[min, max],在 SciKit-Learn 里有个函数 MinMaxScaler 是专门做这个的,它允许我们给定一个最大值与最小值,然后将原数据投射到[min, max]中。默认情况下[min,max]是[0,1],也就是把原始数据投放到[0,1]范围内。
我们来看下下面这个例子:
# coding:utf-8
from sklearn import preprocessing
import numpy as np
# 初始化数据,每一行表示一个样本,每一列表示一个特征
x = np.array([[ 0., -3., 1.],[ 3., 1., 2.],[ 0., 1., -1.]])
# 将数据进行[0,1]规范化
min_max_scaler = preprocessing.MinMaxScaler()
minmax_x = min_max_scaler.fit_transform(x)
print(minmax_x)运行结果:
[[0. 0. 0.66666667][1. 1. 1. ][0. 1. 0. ]]2、Z-Score 规范化
在 SciKit-Learn 库中使用 preprocessing.scale() 函数,可以直接将给定数据进行 Z-Score 规范化。
from sklearn import preprocessing
import numpy as np
# 初始化数据
x = np.array([[ 0., -3., 1.],[ 3., 1., 2.],[ 0., 1., -1.]])
# 将数据进行Z-Score规范化
scaled_x = preprocessing.scale(x)
print(scaled_x)运行结果:
[[-0.70710678 -1.41421356 0.26726124][ 1.41421356 0.70710678 1.06904497][-0.70710678 0.70710678 -1.33630621]]这个结果实际上就是将每行每列的值减去了平均值,再除以方差的结果。
我们看到 Z-Score 规范化将数据集进行了规范化,数值都符合均值为 0,方差为 1 的正态分布。
3、小数定标规范化
我们需要用 NumPy 库来计算小数点的位数。NumPy 库我们之前提到过。
这里我们看下运行代码:
# coding:utf-8
from sklearn import preprocessing
import numpy as np
# 初始化数据
x = np.array([[ 0., -3., 1.],[ 3., 1., 2.],[ 0., 1., -1.]])
# 小数定标规范化
j = np.ceil(np.log10(np.max(abs(x))))
scaled_x = x/(10**j)
print(scaled_x)运行结果:
[[ 0. -0.3 0.1][ 0.3 0.1 0.2][ 0. 0.1 -0.1]]四、总结
数据挖掘中数据变换比算法选择更重要。
在考试成绩中,我们都需要让数据满足一定的规律,达到规范性的要求,便于进行挖掘。这就是数据变换的作用。
如果不进行变换的话,要不就是维数过多,增加了计算的成本,要不就是数据过于集中,很难找到数据之间的特征。
在数据变换中,重点是如何将数值进行规范化,有三种常用的规范方法,分别是 Min-Max 规范化、Z-Score 规范化、小数定标规范化。其中 Z-Score 规范化可以直接将数据转化为正态分布的情况,当然不是所有自然界的数据都需要正态分布,我们也可以根据实际的情况进行设计,比如取对数 log,或者神经网络里采用的激励函数等。

在最后我给大家推荐了 Python 的 sklearn 库,它和 NumPy, Pandas 都是非常有名的 Python 库,在数据统计工作中起了很大的作用。SciKit-Learn 不仅可以用于数据变换,它还提供了分类、聚类、预测等数据挖掘算法的 API 封装。后面我会详细给你讲解这些算法,也会教你如何使用 SciKit-Learn 工具来完成数据挖掘算法的工作。
版权声明
本文章版权归作者所有,未经作者允许禁止任何转载、采集,作者保留一切追究的权利。


——wait/notify和park/unPark)



![计算机视觉与深度学习-卷积神经网络-卷积图像去噪边缘提取-图像去噪 [北邮鲁鹏]](http://pic.xiahunao.cn/计算机视觉与深度学习-卷积神经网络-卷积图像去噪边缘提取-图像去噪 [北邮鲁鹏])

![[python 刷题] 49 Group Anagrams](http://pic.xiahunao.cn/[python 刷题] 49 Group Anagrams)




)





)