文章目录
- 1、重试和死信主题
- 2、死信队列
- 3、代码演示
- 3.1、appication.yml
- 3.2、引入spring-kafka依赖
- 3.3、创建SpringBoot启动类
- 3.4、创建生产者发送消息
- 3.5、创建消费者消费消息
1、重试和死信主题
kafka默认支持重试和死信主题
重试主题:当消费者消费消息异常时,手动ack如果有异常继续向后消费,为了保证消息尽可能成功消费,可以将消费异常的消息扔到重试主题,再通过重试主题的消费者尝试消费死信主题:当一个消息消费多次仍然失败,可以将该消息存到死信主题。避免漏消息,以后可以人工介入手动解决消息消费失败的问题
2、死信队列
在Kafka中,DLT通常指的是 Dead Letter Topic(死信队列)。
Dead Letter Topic(DLT)的定义与功能:
- 背景:原生Kafka是不支持Retry Topic和DLT的,但Spring Kafka在客户端实现了这两个功能。
- 功能:当消息在Kafka中被消费时,如果消费逻辑抛出异常,并且重试策略(如默认重试10次后)仍无法成功处理该消息,Spring Kafka会将该消息发送到DLT中。
- 自定义处理:可以通过自定义
SeekToCurrentErrorHandler来控制消费失败后的处理逻辑,例如添加重试间隔、设置重试次数等。如果在重试后消息仍然消费失败,Spring Kafka会将该消息发送到DLT。
DLT的使用与意义:
- 错误处理:DLT为Kafka提供了一种机制来处理那些无法被成功消费的消息,从而避免了消息的丢失或阻塞。
- 监控与告警:通过对DLT的监控,可以及时发现并处理那些无法被成功消费的消息,从而保障Kafka系统的稳定性和可靠性。
- 二次处理:对于发送到DLT的消息,可以进行二次处理,如手动干预、修复数据等,以确保这些消息能够最终得到处理。
总之,在Kafka中,DLT是一个用于处理无法被成功消费的消息的特殊Topic,它提供了一种灵活且可靠的机制来保障Kafka系统的稳定性和可靠性。
3、代码演示
3.1、appication.yml
server:port: 8120
# v1
spring:Kafka:bootstrap-servers: 192.168.74.148:9095,192.168.74.148:9096,192.168.74.148:9097consumer:# read-committed读事务已提交的消息 解决脏读问题isolation-level: read-committed # 消费者的事务隔离级别:read-uncommitted会导致脏读,可以读取生产者事务还未提交的消息# 消费者是否自动ack :true自动ack 消费者获取到消息后kafka提交消费者偏移量# 调用ack方法时才会提交ack给kafka
# enable-auto-commit: false# 消费者提交ack时多长时间批量提交一次auto-commit-interval: 1000# 消费者第一次消费主题消息时从哪个位置开始# earliest:从最早的消息开始消费# latest:第一次从LEO位置开始消费# none:如果主题分区没有偏移量,则抛出异常auto-offset-reset: earliest #指定Offset消费:earliest | latest | nonekey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer# json反序列化器
# value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializerproperties:spring.json.trusted.packages: "*"listener:# 手动ack:manual手动ack时 如果有异常会尝试一直消费
# ack-mode: manual# 手动ack:消费有异常时停止ack-mode: manual_immediate3.2、引入spring-kafka依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.0.5</version><relativePath/> <!-- lookup parent from repository --></parent><!-- Generated by https://start.springboot.io --><!-- 优质的 spring/boot/data/security/cloud 框架中文文档尽在 => https://springdoc.cn --><groupId>com.atguigu</groupId><artifactId>spring-kafka-consumer</artifactId><version>0.0.1-SNAPSHOT</version><name>spring-kafka-consumer</name><description>spring-kafka-consumer</description><properties><java.version>17</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>3.3、创建SpringBoot启动类
package com.atguigu.spring.kafka.consumer;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;// Generated by https://start.springboot.io
// 优质的 spring/boot/data/security/cloud 框架中文文档尽在 => https://springdoc.cn
@SpringBootApplication
public class SpringKafkaConsumerApplication {public static void main(String[] args) {SpringApplication.run(SpringKafkaConsumerApplication.class, args);}}3.4、创建生产者发送消息
package com.atguigu.spring.kafka.consumer;
import jakarta.annotation.Resource;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.kafka.core.KafkaTemplate;
import java.time.LocalDateTime;
@SpringBootTest
public class KafkaProducerApplicationTests {@ResourceKafkaTemplate kafkaTemplate;@Testvoid sendRertyMsg(){kafkaTemplate.send("retry_topic",0,"","重试机制和死信队列"+"_"+ LocalDateTime.now());}
}
没有指定分区,默认会创建一个分区,即使此时有3个kafka实例,也只会用一个,因为只有一个分区


[[{"partition": 0,"offset": 0,"msg": "重试机制和死信队列_2024-06-07T15:49:37.398841600","timespan": 1717746578357,"date": "2024-06-07 07:49:38"}]
]
3.5、创建消费者消费消息
给一个消费者配重试主题的时候,死信主题消费者一般不写
package com.atguigu.spring.kafka.consumer.listener;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.annotation.RetryableTopic;
import org.springframework.kafka.annotation.TopicPartition;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.retry.annotation.Backoff;
@Component
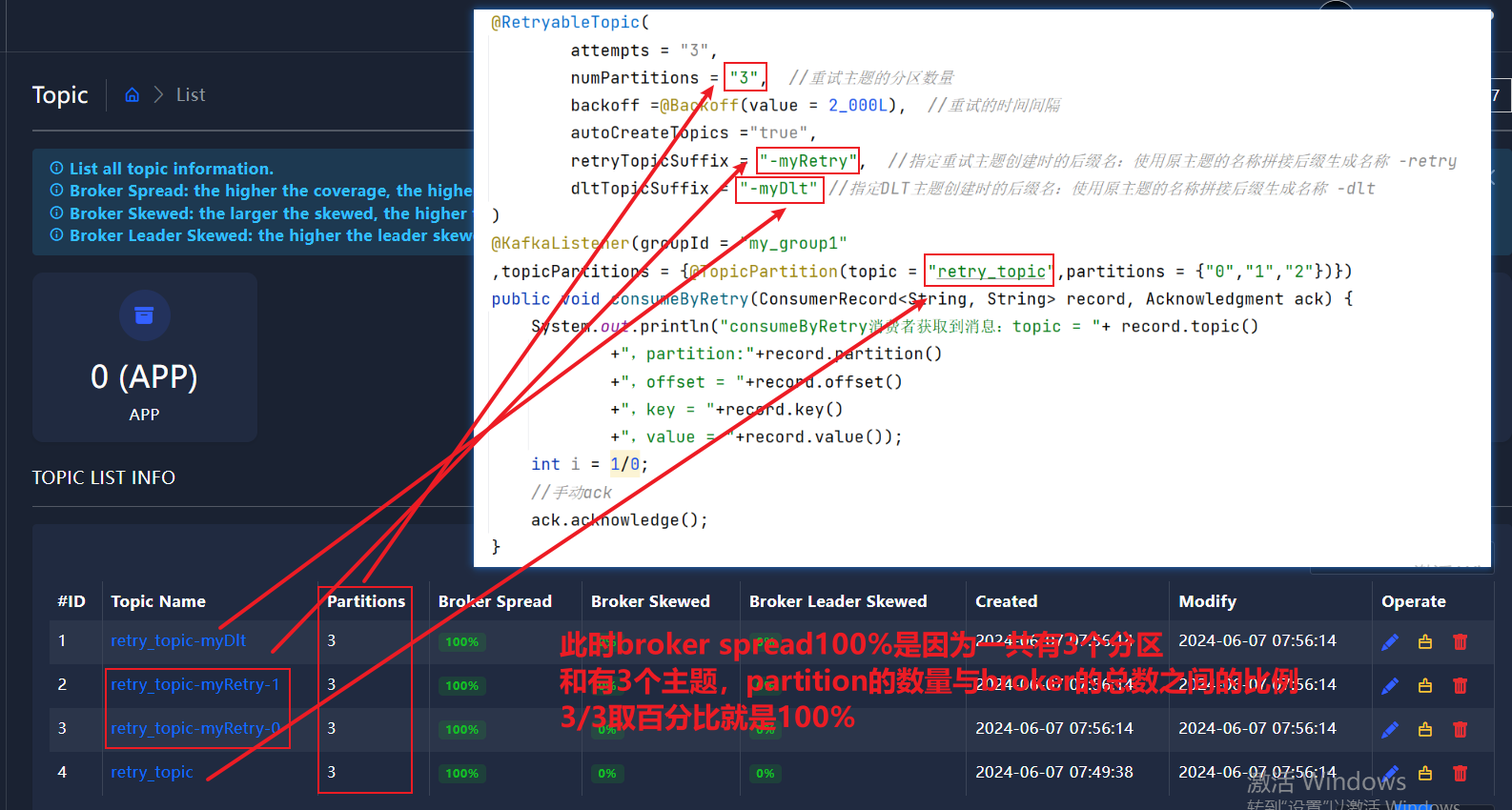
public class MyKafkaListenerAck {/*** 自动ack可能会导致漏消息* spring-kafka:* 自动ack 如果有异常,会死循环获取消息重新消费* 不能继续向后消费消息,会导致消息积压** 手动ack 配置了手动ack,且ack-mode为manual_immediate时,* 如果消息消费失败,会继续向后消费* @param record*///指定消费者消费异常使用重试+死信主题 必须结合手动ack使用@RetryableTopic(attempts = "3",numPartitions = "3", //重试主题的分区数量backoff =@Backoff(value = 2_000L), //重试的时间间隔autoCreateTopics ="true",retryTopicSuffix = "-myRetry", //指定重试主题创建时的后缀名:使用原主题的名称拼接后缀生成名称 -retrydltTopicSuffix = "-myDlt" //指定DLT主题创建时的后缀名:使用原主题的名称拼接后缀生成名称 -dlt)@KafkaListener(groupId = "my_group1",topicPartitions = {@TopicPartition(topic = "retry_topic",partitions = {"0","1","2"})})public void consumeByRetry(ConsumerRecord<String, String> record, Acknowledgment ack) {System.out.println("consumeByRetry消费者获取到消息:topic = "+ record.topic()+",partition:"+record.partition()+",offset = "+record.offset()+",key = "+record.key()+",value = "+record.value());int i = 1/0;//手动ackack.acknowledge();}/* //死信队列默认名称在原队列后拼接'-dlt'@KafkaListener(groupId = "my_group2",topicPartitions = {@TopicPartition(topic = "topic_dlt",partitions = {"0","1","2"})})public void consumeByDLT(ConsumerRecord<String, String> record, Acknowledgment ack) {System.out.println("consumeByDLT消费者获取到消息:topic = "+ record.topic()+",partition:"+record.partition()+",offset = "+record.offset()+",key = "+record.key()+",value = "+record.value());//手动ackack.acknowledge();}*/}
此时运行SpringKafkaConsumerApplication,控制台会报错,因为我们手动写了异常 int i=1/0

[[{"partition": 0,"offset": 0,"msg": "重试机制和死信队列_2024-06-07T15:49:37.398841600","timespan": 1717746979414,"date": "2024-06-07 07:56:19"}]
]
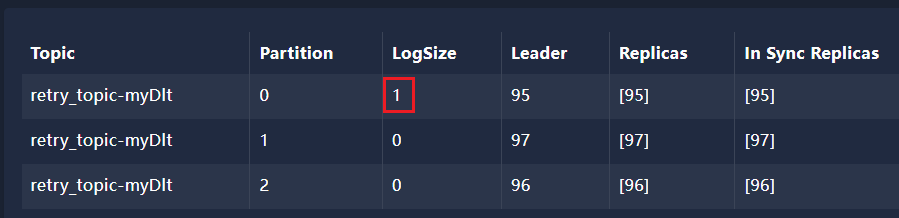
我们发现原本在重试主题中的消息,死信主题也有一份
之对归并排序的介绍与理解)


)
定时器)











:requests库的高级用法)


