本次案例分析用心脏病数据集来做随机森林模型预测
导入基本的数据分析包
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns读取数据
# 读取数据
data = pd.read_csv("A_train.csv") 
描述性统计分析


接下来对数据特征进行可视化
sns.set(style="whitegrid")# Plot the distribution of ages
plt.figure(figsize=(10, 6))
sns.histplot(data['age'], bins=20, kde=True, color='skyblue')
plt.title('Age Distribution')
plt.xlabel('Age (days)')
plt.ylabel('Frequency')
plt.show() 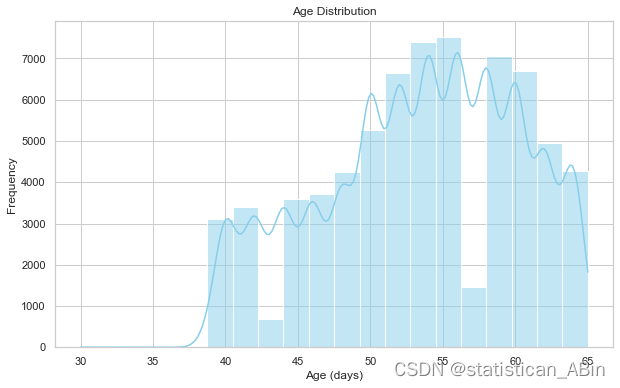
# 性别分布 - 饼图
gender_counts = data['gender'].value_counts()
plt.figure(figsize=(6, 6))
plt.pie(gender_counts, labels=['Female', 'Male'], autopct='%1.1f%%', colors=['#ff9999','#66b3ff'])
plt.title('Gender Distribution')
plt.show()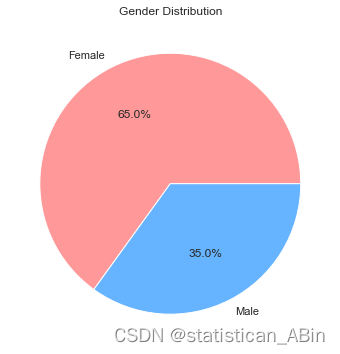
身高和体重分布
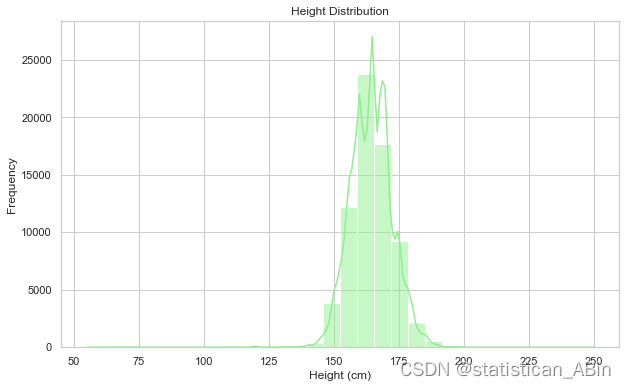
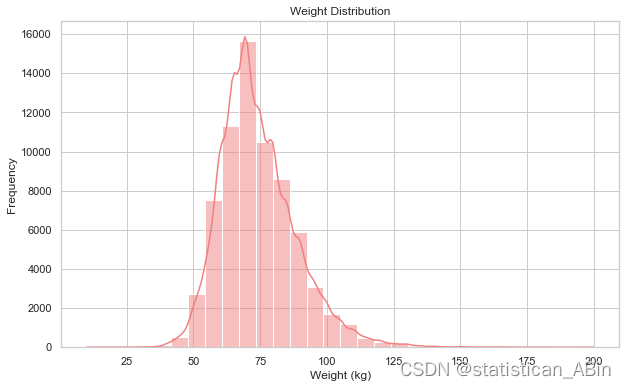
胆固醇和血糖水平
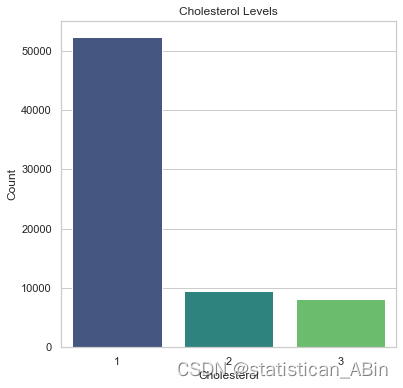
# 吸烟、饮酒和身体活动的比例

热力图
# 计算相关系数矩阵
correlation_matrix = data.corr()
# 设置绘图风格
sns.set(style="white")# 画布大小
plt.figure(figsize=(12, 10))# 绘制热力图
sns.heatmap(correlation_matrix, annot=True, fmt=".2f", cmap='coolwarm', linewidths=0.5, cbar_kws={"shrink": 0.8})
plt.title('Correlation Matrix Heatmap')
plt.show() # 分割数据
# 分割数据
X = data.drop(['id', 'cardio'], axis=1)
y = data['cardio']
模型建立
# 分割数据
X = data.drop(['id', 'cardio'], axis=1)
y = data['cardio']###生成混淆矩阵并可视化
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['KaiTi'] #中文
plt.rcParams['axes.unicode_minus'] = False #负号
conf_matrix = confusion_matrix(y_test, y_pred)plt.figure(figsize=(8, 6),dpi=200)
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', xticklabels=['0', '1'], yticklabels=['0', '1'])
plt.xlabel('预测标签')
plt.ylabel('实际标签')
plt.title('混淆矩阵')
plt.show() 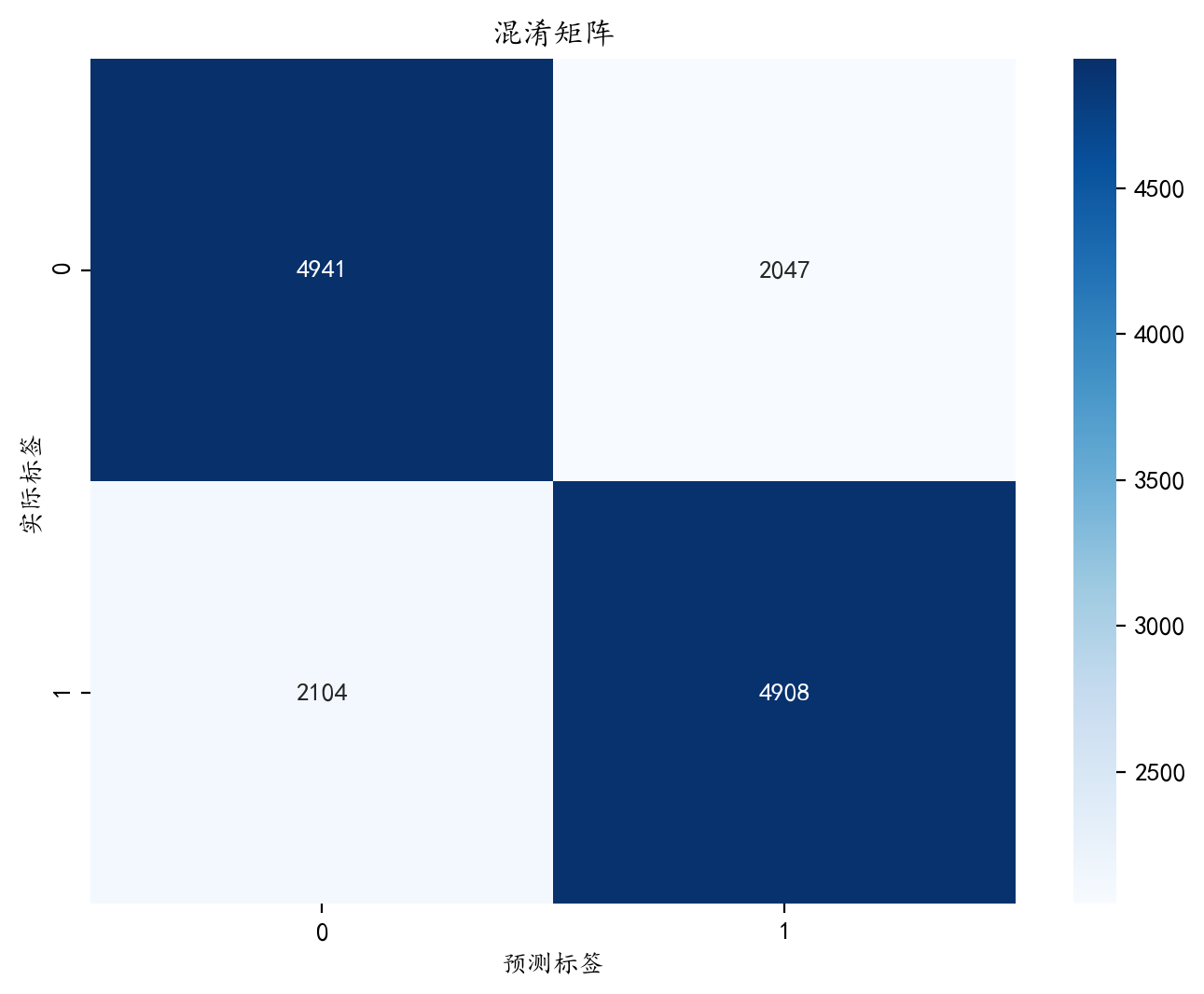
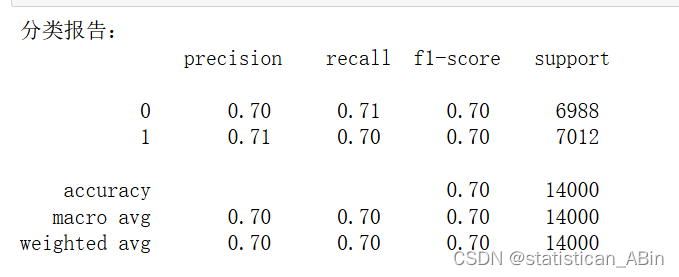
最后,可以使用特征重要性图来查看模型中各特征的重要性。

完整数据和代码
创作不易,希望大家多多点赞关注和收藏!谢谢!



)

)

:string类的模拟实现)
)


)





)

