背景:AI模型中不同的数据类型对硬件算力和内存的需求是不同的,为了提高模型在硬件平台的吞吐量,减少数据通信带宽需求,往往倾向于将高位宽数据运算转向较低位宽的数据运算。本文通过重新回顾计算机中整数和浮点数的定义,梳理AI模型出现的不同数据类型,进一步理解为什么会出现这些不同的数据类型。
整数的定义
在计算机中,整数类型的表示通常采用二进制补码形式。二进制补码是一种用来表示有符号整数的方法,它具有以下特点:
-
符号位:整数的最高位(最左边的位)通常用作符号位,0表示正数,1表示负数。
-
数值表示:
-
对于正数,其二进制补码与其二进制原码相同。
-
对于负数,其二进制补码是其二进制原码取反(除了符号位,每一位取反,0变为1,1变为0),然后再加1。
-
-
范围:对于n位比特位宽的整数类型,其表示范围为-2^(n-1)到2^(n-1) - 1,其中有一位用于表示符号位。
举例说明,对于一个8位二进制补码整数:
-
0110 1100 表示正数108。
-
1111 0011 表示负数-13。其二进制原码为1000 1101,取反得到 1111 0010,加1得到补码。
浮点数的定义
在计算机中,浮点数据类型的表示通常采用IEEE 754标准,该标准定义了两种精度的浮点数表示:单精度和双精度。
一个单精度浮点数通常由32位二进制组成,按照IEEE 754标准的定义,这32位被划分为三个部分:符号位、指数部分和尾数部分。
-
符号位:占用1位,表示数值的正负。
-
指数部分:占用8位,用于表示数值的阶码(数据范围)。
-
尾数部分:占用23位,用于表示数值的有效数字部分(小数精度)。
一个双精度浮点数通常由64位二进制组成,同样按照IEEE 754标准的定义,这64位被划分为三个部分:符号位、指数部分和尾数部分。同单精度不同的是,指数部分位宽是11位,尾数部分位宽是52位。单精度和双精度浮点数的取值范围和精度有所不同,双精度浮点数通常具有更高的精度和更大的取值范围。
IEEE 754标准中浮点数根据指数的值会分为规格化,非规格化和特殊值(零值、无穷大和NaN (Not a Number),它们的定义如下。规格化浮点数用于表示较大的数值,指数部分至少有一位为1,可以表示更大的数值范围和更高的精度。非规格化浮点数用于表示接近于零的数值,指数部分全为0,可以表示比规格化浮点数更接近于零的小数值。
-
规格化浮点数:指数部分至少有一位为1,且不能全为1。在规格化浮点数中,尾数部分的最高位总是1,并且在存储时通常省略了这个最高位,以节省存储空间。规格化浮点数的指数部分表示了数值的阶码,而尾数部分表示了数值的有效数字。例如,对于单精度浮点数,规格化浮点数的指数范围是1到254。
-
非规格化浮点数:指数部分全为0,尾数部分不全是0。在非规格化浮点数中,尾数部分的最高位不再强制为1,而是可以为0,这样可以表示非常接近于零的数值。非规格化浮点数可以用来增加浮点数的精度范围,但通常会失去一些精度。例如,在单精度浮点数中,当指数部分全为0时,尾数部分的最高位可以为0,这时表示的数值接近于零。
-
特殊值
-
零值:指数部分和尾数部分都为0,符号位可以为0或1,表示正零或负零,零值的真实值为0。
-
无穷大:指数部分全为1,尾数部分全为0,符号位分别为0和1。无穷大的真实值为正无穷大和负无穷大。
-
NaN: 指数部分全为1,尾数部分至少有一位为1,符号位可以是任意值。NaN表示浮点数的无效操作或不确定结果,NaN的真实值通常没有实际意义。
-
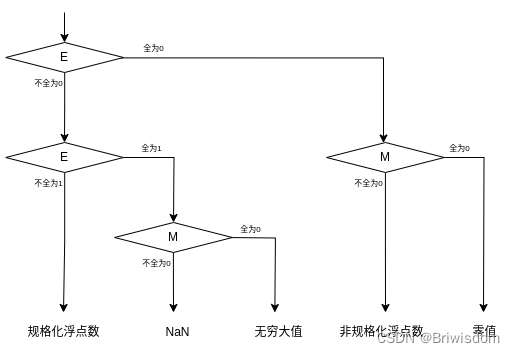
对于规格化和非规格化浮点数,其真实值的计算公式定义如下,其中S是符号位,取指0或1,表示浮点数的正负;E是指数部分,决定了数值的范围;M是尾数部分,决定了小数点的有效位数;E_bw表示指数的位宽;B表示指数的偏移量,B的取值取决于浮点数的指数位宽,比如E的位宽是8, B=2^7-1=127。
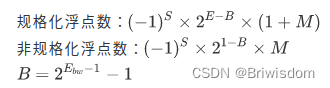
举例说明,对一个单精度浮点数的表示:
0 10000011 10100000000000000000000
-
符号位:0,S=0,表示正数,(-1)^0=1。
-
指数部分:10000011,E-B=130-127=3,表示指数为2^3=8。
-
尾数部分:10100000000000000000000,表示尾数为1.101,即1.625(二进制转换为十进制)。
所以,这个单精度浮点数表示的数值为1 * 8 * 1.625= 8.625。
AI模型中常用的数据类型
在AI模型中常用数据位宽有8bit, 16bit, 32bit,根据不同的应用场景和模型训练推理阶段需求,可以选择不同位宽的数据类型。下图是现有AI模型中出现过的数据类型位宽和定义,可以看到关于浮点数据类型在E和M位宽有很多种设计,比如对同样的16bit和8bit位宽的浮点数,出现了不同的E,M位宽设计,这些数据类型的出现也是AI领域在具体实践应用中,对软件和硬件设计不断优化的表现。
FP32: 单精度浮点数格式 ,FP32 是一种广泛使用的数据格式,其可以表示很大的实数范围,足够深度学习训练和推理中使用。
FP16: P16 是一种半精度浮点格式,因为神经网络具有很强的冗余性,降低数据位宽的计算对于模型性能来说影响不大,FP16和FP32混合精度训练模式被大量使用。
BF16: FP16 设计时并未考虑深度学习应用,其动态范围太窄。由 Google 开发的 16 位浮点格式称为“Brain Floating Point Format”,简称“bfloat16”,bfloat16 解决了FP16动态范围太窄的问题,提供与 FP32 相同的动态范围。其可以认为是直接将 FP32 的前 16 位截取获得的,在Transformer架构模型中有很好的表现。
FP8: FP8是INIDIA的H100 GPU产品中推出的一种8bit位宽浮点数据类型,有E4M3和E5M2两种设计,其中E5M2保持了FP15的数据范围,而E4M3则对数据精度有更好的支持。FP8数据类型可以在保持与FP16/BF16相似的模型精度下,节省模型的内存占用以及提升吞吐量。
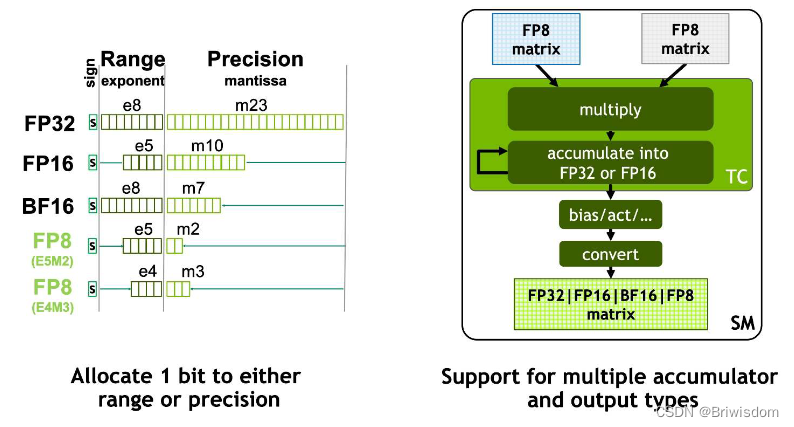
FP8数据类型
不同数据类型的演进过程
AI模型在业界长期依赖于FP32数据类型的训练,随后考虑到AI神经网络的冗余及对训练的精度没有特别敏感,逐渐出现了TF32和BF16数据类型,保证了和FP32相同的数据范围基础上,进行了不同程度的小数精度位数的降低,很好的解决了GPT模型计算过程中数据溢出的问题。后来面对AI模型不同训练阶段的精度需求,FP32和FP16等混合精度的模型训练方式也逐渐变得主流起来。
虽然为了实现模型推理加速,降低模型部署的内存空间,出现了模型量化为int8类型的研究方向,但是对仍在初期阶段的大语言模型(LLM)来说,探索更低的数据位宽以加速训练和降低推理成本仍然是一个很重要的研究课题。作为AI算力提供的领军公司NVIDIA在2022年发布的A100 GPU中推出了两种FP8数据类型的硬件支持,通过在诸多大模型并行化技术和工程手段的加持下,给LLM训练和推理带来了显著的性能提升和能效改善。
FP8的E4M3和E5M2介绍
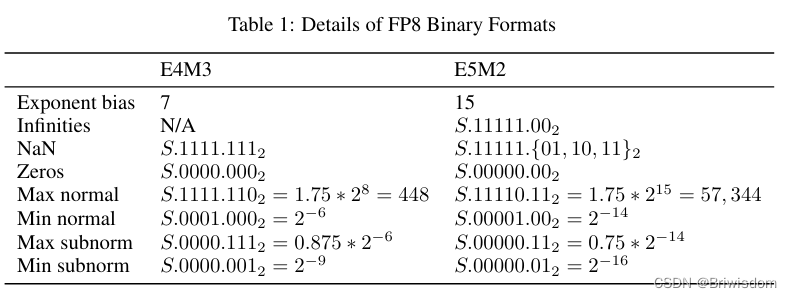
FP8 是一种 8 位浮点数表示法,FP8 的详细介绍可以参考链接。FP8 采取 E4M3 和 E5M2 两种表示方式,其中 E 代表指数位(Exponent),M 代表尾数位(Mantissa)。在表示范围内,E4M3 更精准,而 E5M2 有更宽的动态范围。 与传统的 FP16(16位浮点数)和 FP32(32 位浮点数)相比,它显著减少了存储,提高了计算吞吐。
FP32, FP16, BF16, FP8 E5M2的浮点数表示都遵循前面提到的IEEE754浮点数据标准,FP8的E4M3则不完全遵循IEEE754标准约定,主要不同在于当指数位全为1时候,去掉了无穷大类型的表示,约定仅当尾数全为1表示NaN,否则仍然来表示规格化数据的值,这样可以增加数据的表示范围。比如当二进制序列为0 1111 110时候,表示的值为1 * 2^8 * 1.75 =448。如果仍完全采用IEEE754标准,支持的最大的数据是240。下表展示了FP8两种类型的数据范围一些细节。
数据表示位数的降低带来了更大的吞吐和更高的计算性能,虽然精度有所降低,但是在 LLM 场景下,采用技术和工程手段,FP8 能够提供与更高精度类型相媲美的结果,同时带来显著的性能提升和能效改善。
- 性能提升:由于 FP8 的数据宽度更小,减少显存占用,降低通讯带宽要求,提高 GPU 内存读写的吞吐效率。并且在相同的硬件条件下,支持 FP8 的 Tensor Core 可以在相同时间内进行更多次的浮点运算,加快训练和推理的速度。
- 模型优化:FP8 的使用促使模型在训练和推理过程中进行量化,这有助于模型的优化和压缩,进一步降低部署成本。
与INT8 的数值表示相比较, FP8 在 LLM 的训练和推理更有优势。因为INT8在数值空间是均匀分布的,而 FP8 有更宽的动态范围, 更能精准捕获 LLM 中参数的数值分布,配合 NVIDIA Transformer Engine、NeMo 以及 Megatron Core 的训练平台和 TensorRT-LLM 推理优化方案,大幅提升了 LLM 的训练和推理的性能,降低了首 token 和整个生成响应的时延。
从FP32 到 FP8 的数据格式转换
当硬件支持了FP8数据类型的计算之后,作为软硬件协同发展的AI系统,软件上必须要考虑如何定义不同数据类型到FP8数据的转换过程。
AI模型中把浮点数量化为int8数据类型是一个常见的操作,目前已经有很多成熟的量化算法,但是这些量化算法对把高位宽的数据量化为低位宽的浮点数据类型是不适用的。
由于指数部分的存在,浮点量化与INT量化表现出了不一样的性质。INT的量化步长是均匀的,总是以一定的步长完成量化,这是一种均匀的量化。而浮点的量化则是非均匀的,随着数值增大,其步长也在逐渐变大。且E5M2的步长变化较E4M3而言更加明显。从另一个角度出发,量化的误差总是与步长正相关的,因此FP8浮点量化相比于INT8而言,对于小数来说会更加精确,但对于大数则更不精确。
目前,将FP32 向 FP8 的转换过程可以表示为先除以尺度因子得到中间结果 Unscaled FP32,再由中间结果完成 FP32 到 FP8 的格式转换。
- Unscaled FP32 = FP32 / scale
- FP8 = Convert(Unscaled FP32)
另外,在Convert函数的执行过程,具体需要处理以下三种特殊情况:
- 当 Unscaled FP32 数据已经超出 FP8 的表示范围,即 Unscaled FP32 的幅值大于 448,那么直接进行截断,此时为浮点上溢出。
- 当 Unscaled FP32 数据范围在 FP8 的表示范围内,且幅值大于 FP8 能够表达的最小值,此时需要移去多余的底数位,并对底数进行四舍五入。
- 当 Unscaled FP32 数据小于规范化 FP8 能够表达的最小值,此时浮点下溢出,此时我们除以非规范化的 FP8 最小值并取整。
小结
展望:随着全民谈AI,AI即未来的新一轮技术革命时代的到来,未来算力将会像如今的电力一样称为AI的基建设施。硬件芯片设计和软件栈需要紧密协作,进而推动创造出更多人人都消费的起的AI产品。
简单总结本文的重点:搞懂数据类型的定义,搞清楚为什么有这些数据类型就好啦。
参考:
https://zhuanlan.zhihu.com/p/574825662
NVIDIA H100 Tensor Core GPU Architecture Overview
FP8:前沿精度与性能的新篇章 - NVIDIA 技术博客
https://arxiv.org/pdf/2209.05433
 Object Pascal 学习笔记---第13章第3节 (内存管理技巧 ))





)









复现及问题记录)


