
【摘要】为大型语言模型 (LLM) 制作理想的提示是一项具有挑战性的任务,需要大量资源和专家的人力投入。现有的工作将提示教学和情境学习示例的优化视为不同的问题,导致提示性能不佳。本研究通过建立统一的上下文提示优化框架来解决这一限制,旨在实现提示指令和示例的联合优化。然而,在离散和高维自然语言空间中制定这种优化在收敛和计算效率方面带来了挑战。为了克服这些问题,我们提出了 PhaseEvo,这是一种高效的自动提示优化框架,它将法学硕士的生成能力与进化算法的全局搜索能力相结合。我们的框架采用多阶段设计,结合了基于 LLM 的创新变异算子,以提高搜索效率并加速收敛。我们对 35 项基准任务的方法进行了广泛的评估。结果表明,PhaseEvo 的性能大幅优于最先进的基线方法,同时保持良好的效率。
原文:PhaseEvo: Towards Unified In-Context Prompt Optimization for Large Language Models
地址:https://arxiv.org/abs/2402.11347
代码:未知
出版: 未知
机构:intui
1 研究问题
本文研究的核心问题是: 如何设计一个统一的in-context学习prompt优化框架,以实现prompt指令和示例的联合优化。
假设我们要优化一个仇恨言论检测任务的prompt。现有的方法要么只优化一个简短的零样本指令,比如"检测下面的文本是否包含仇恨言论",要么在固定的指令下优选一组few-shot示例。这往往得不到最优的效果。比如加入一些few-shot的正负面例子,再稍微修改一下指令的表述,可能会带来更好的提示效果。本文要解决的就是如何在指令和示例两个维度上同时搜索最优的prompt。
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
-
离散的自然语言空间具有极高的维度,优化搜索难度大。联合优化指令和示例需要在一个超大规模的离散空间中探索最优解,收敛速度慢,计算成本高。
-
全局探索容易陷入局部最优。现有的随机搜索方法虽然能全局探索,但也更容易陷入局部最优,难以持续优化。
-
纯粹的局部搜索优化幅度有限。一些基于梯度的局部搜索方法虽然能快速收敛,但往往只能在初始解附近小幅优化,难以跳出次优区域。
针对这些挑战,本文提出了一种兼顾"全局探索"和"局部优化"的"PhaseEvo"方法:
PhaseEvo巧妙地将进化算法中的"探索"和"利用"思想与LLMs的生成能力相结合。它设计了一个四阶段的迭代优化框架,在"全局探索"和"局部优化"之间反复切换:先用随机初始化种群全局探索解空间,再用反馈突变局部优化当前解,然后用进化算子重新探索新区域,最后再用语义突变加速收敛。这好比先撒一张大网到处探索,然后围绕探索到的好位置精细捕捞,接着再撒网到新水域,最后收缩网兜聚焦最佳区域。同时,PhaseEvo还根据算子的特性,设计了任务感知的相似度度量和自适应的阶段切换策略,大幅提升了搜索效率。
2 研究方法
论文提出了一种名为PhaseEvo的统一in-context学习prompt优化框架,以实现prompt指令和示例的联合优化。PhaseEvo的核心思想是将进化算法中的"探索"和"利用"思想与LLMs的生成能力相结合,通过"全局探索→局部优化→全局探索→局部优化"的四阶段迭代优化流程,在探索整个搜索空间和利用当前最优解之间求得平衡。
2.1 突变算子
PhaseEvo使用了5类LLM驱动的突变算子,每类算子在添加/删除示例、改进概率、收敛速度、是否支持多父代、计算成本等关键属性上各有特点。
-
Lamarckian算子: 给定一组输入输出对,利用LLM的few-shot学习能力反向生成对应的prompt。该算子能够引入全新的语义片段,为初始种群提供多样性。
-
Feedback算子: 利用LLM作为"考官"找出当前prompt的缺陷,并作为"梯度"反馈给另一个LLM"学生",后者据此生成改进后的prompt。该算子能同时修改指令和示例,改进概率高,收敛速度快,但容易陷入局部最优。
-
EDA算子: 从当前种群中选出一组语义相似但表述多样的parents,交由LLM生成它们的"遗传重组"。若按照适应度对parents排序,则称为EDA+I算子。该算子支持多父代,探索能力强,但改进概率和速度一般。
-
Crossover算子: 选择种群中适应度最高的两个个体作为parents,让LLM对它们执行"交叉重组"。若两个parents的相似度最低,则称为Crossover+D算子。其特点与EDA算子类似。
-
Semantic算子: 对当前prompt执行语义改写,生成表述不同但意思相近的新prompt。该算子探索能力较弱,但改进概率高,资源消耗低。
下表比较了不同算子的关键属性:
| 算子 | 能否增删示例 | 改进概率 | 收敛速度 | 多父代 | 计算成本 |
|---|---|---|---|---|---|
| 能 | - | - | 否 | 低 | |
| 能 | 高 | 快 | 否 | 中 | |
| 否 | 中 | 慢 | 能 | 高 | |
| 否 | 中 | 慢 | 能 | 高 | |
| 否 | 高 | 快 | 否 | 低 |
2.2 四阶段优化流程
PhaseEvo采用四阶段迭代优化流程,每个阶段的初始种群、突变算子、种群规模、迭代方式等如下:
-
阶段0(全局初始化):使用算子从任务数据或人工prompt中随机采样生成初始种群。该阶段探索空间最广,为后续阶段提供多样性的起点。
-
阶段1(局部反馈突变):对中的每个个体,迭代使用算子,让LLM"考官"反复找出其缺陷并让LLM"学生"迭代改进,直到无法再提升。所有改进后的个体形成新种群。该阶段在初始探索的基础上快速爬坡,为后续阶段提供局部最优解。
-
阶段2(全局进化突变):从中随机采样一组parents,用或算子生成它们的"遗传重组",加入种群形成。通过引入多样性的parents,该阶段能跳出阶段1的局部最优区域,在更大范围内探索。
-
阶段3(局部语义突变):对中的每个个体,使用算子生成其语义相近的变体,形成最终种群。该阶段在全局探索的基础上做局部微调,提升收敛速度。
算法1描述了PhaseEvo的总体流程:

不同阶段通过巧妙的组合,形成了"大范围撒网 → 精细捕捞 → 换址撒网 → 重点围捕"的高效探索利用策略。
2.3 关键设计改进
除了四阶段流程,PhaseEvo还在两个细节上进行了改进。
首先,它采用基于任务的相似度度量来评估不同个体的差异性。传统的做法通常基于prompt嵌入的余弦相似度,但这不能反映它们在下游任务上的性能差异。PhaseEvo为每个个体构造一个performance vector,记录其在验证集每个样本上的预测结果(例如[1,1,1,0,0]代表前三个样本预测正确,后两个预测错误),并用vector之间的汉明距离度量相似性。这种做法能更准确地评估个体之间的互补性,避免选择到冗余的parents。
其次,PhaseEvo为不同阶段设计了自适应的终止条件。原有的进化算法通常给每个阶段设置固定的迭代次数,但这忽略了不同算子的优化效率差异。PhaseEvo根据算子的特点,动态调整每个阶段的耐受度:
-
对于Feedback和Semantic等局部算子,若连续k(默认为1)次迭代都不再改进,则终止该阶段;
-
对于EDA和Crossover等全局算子,由于优化效率较低,即使连续若干次迭代都不再改进,也会给予更大的耐受度(如k=4)再做尝试。
这种自适应终止策略充分利用了高效算子的快速收敛能力,也给低效算子更多的探索机会,从而在优化效果和计算成本之间取得了良好的平衡。
2.4 算法复杂度分析
设为prompt语料库大小,为平均prompt长度,分别为全局和局部阶段的基因代数,则PhaseEvo的时间复杂度为,其中为涉及的下游任务数。与穷举搜索的指数级复杂度相比,PhaseEvo在大规模搜索空间上的伸缩性更好。
在空间复杂度上,PhaseEvo在整个优化过程中最多维护的内存消耗,远低于需要缓存所有中间结果的贪心搜索和beam search等方法。
实验结果表明,PhaseEvo在35个常见benchmark上平均只需12次迭代和4000次API调用(感觉有点昂贵啊!),就能达到超越现有最优方法20%的显著提升。这体现了PhaseEvo在计算效率和优化效果上的显著优势。
3 实验效果
为全面评估PhaseEvo的有效性,论文在35个常见benchmark上进行了大规模实验。这些数据集涵盖了Big Bench Hard(BBH)、NLP检测、指令理解等不同类型的任务。其中,BBH包含8个具有挑战性的推理数据集,每个数据集有50个训练样本、50个验证样本和125个测试样本。NLP检测任务包括Ethos、Liar和Sarcasm,分别取50/50/150个样本作为训练集/验证集/测试集。指令理解任务使用了24个多样化的数据集,每个任务从原有训练集中取50个样本作为验证集,保留原有测试集。所有任务的评估指标均基于测试集计算,包括准确率、F1值等。
3.1 对比方法
论文将PhaseEvo与6种最新的基于LLMs的prompt优化方法进行了比较,包括:
-
APE和APO:分别强调exploration和exploitation,前者采用迭代式的蒙特卡洛搜索,后者用错误示例作为梯度近似。
-
OPRO:作为一种meta-prompt方法,它利用LLMs对solution-score对和任务描述做进一步优化。
-
PromptBreeder和EvoPrompt:基于遗传算法,分别采用思维风格突变和差分进化作为搜索策略。
-
AELP:针对长prompt优化,它在句子级别做语义突变,搭配历史感知搜索。
所有实验中,这些方法使用相同数量的训练数据和API调用预算,以确保公平比较。
3.1.1 Big Bench Hard
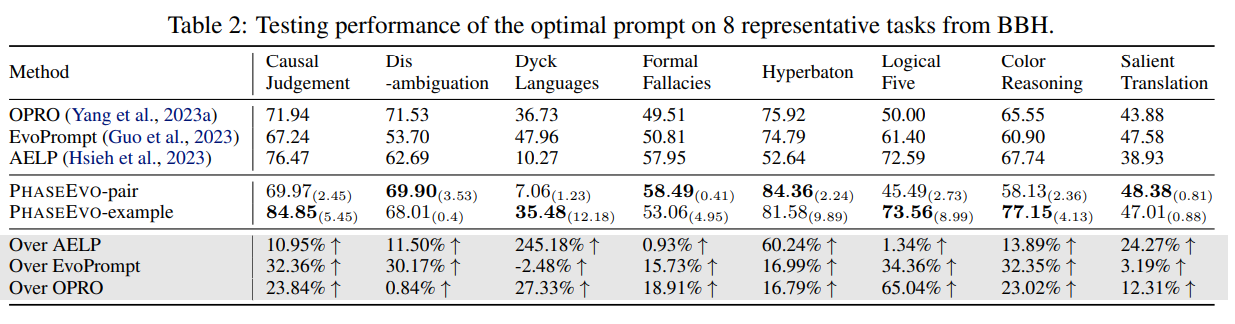
表2展示了haseEvo与最优基线在8个有代表性的BBH任务上的性能对比。可以看到,PhaseEvo在大部分任务上都取得了显著的提升,平均超过AELP 46.0%、EvoPrompt 20.3%和OPRO 23.5%。这体现了PhaseEvo在复杂推理任务上的优越性。不过,PhaseEvo在个别任务如Disambiguation QA上的表现略逊于部分基线,这可能是由于其对歧义消解的建模能力有限。
此外,论文还比较了不同初始化方式的影响。如表2所示,使用人工示例初始化(PhaseEvo-example)在Dyck Languages、Logical Five等任务上优于从原始数据采样初始化(PhaseEvo-pair),这得益于额外的先验知识引入。但在Causal Judgment等任务上,PhaseEvo-pair却表现更优,这可能是因为过于特定的人工示例限制了探索的广度。总的来说,这两种初始化方式在不同场景下各有优劣,论文建议根据任务的先验知识可获得性进行选择。
3.1.2 NLP检测任务

表3比较了PhaseEvo与APO在3个检测任务上的性能。可以看到,在Ethos和Sarcasm等简单任务上,PhaseEvo(GPT-3.5)与APO的性能相当;但在更复杂的Liar任务上,PhaseEvo的提升幅度高达19.6%,这得益于其在指令和示例两个方面的联合优化。当使用更强大的GPT-4作为base model时,PhaseEvo的性能进一步提升,但与GPT-3.5版本的差距并不显著。这表明PhaseEvo在充分利用GPT-3.5的同时,也具备了一定的鲁棒性。
3.1.3 指令理解任务
论文表17展示了PhaseEvo生成的prompt与人工few-shot示例在24个指令任务上的性能对比。APE和PromptBreeder的zero-shot和few-shot结果作为参考。可以看到,PhaseEvo在大部分任务上都显著超过了人工示例,且在17个任务上超过APE few-shot、18个任务上超过PromptBreeder。这验证了PhaseEvo在巨大的探索空间内寻找最优prompt的能力。
有趣的是,通过定性分析PhaseEvo生成的prompt,论文发现其可解释性和连贯性都明显优于人工设计的示例。在Rhymes任务中,PhaseEvo不仅给出了易于理解的任务定义,还提供了丰富的正面和负面示例,以及写作建议。相比之下,人工示例和其他方法的prompt则显得不够清晰和完整。这说明PhaseEvo不仅在优化prompt的性能,也在优化其语义和结构。
3.2 效率比较
除了有效性,论文还评估了PhaseEvo的计算效率。图5比较了不同方法在优化过程中的API调用次数和迭代次数。可以看到,PhaseEvo在35个任务上平均只需12次迭代和4000次API调用,就达到了超越现有方法的性能,而其他基于进化算法的方法如PromptBreeder则需要数十万次API调用。这得益于PhaseEvo对探索和利用的平衡,以及对不同阶段的适应性控制。此外,PhaseEvo的计算开销与APO等基于梯度的方法具有可比性,这进一步凸显了其在效率和效果间的良好权衡。
从理论上看,设为prompt语料库规模,为平均长度,分别为全局和局部阶段的代数,则PhaseEvo的时间复杂度为,空间复杂度为,均显著优于穷举搜索等暴力方法。这表明PhaseEvo能够支持在百万级语料上的实时优化。
3.3 消融实验
为验证PhaseEvo的一些关键设计,论文做了多组消融实验。
首先,相比随机选择算子的传统进化策略,PhaseEvo的phase进化方式在4个具有代表性的任务上都取得了更高的性能,尤其是在优化后期阶段。这说明exploration和exploitation的有序织交对于最终的收敛质量至关重要。
其次,论文比较了不同相似度度量对EDA/Crossover算子的影响。使用performance vector+汉明距离在所有任务上都优于余弦相似度,平均提升1.23%。这验证了任务感知的相似度度量在选择互补parents时的优越性。
最后,展示了优化过程中prompt长度的动态变化。可以看到,在不同任务上,最优prompt长度呈现不同的变化模式,这体现了PhaseEvo对搜索空间的灵活适应能力。值得一提的是,在部分任务中,最终的prompt长度反而低于初始值,这挑战了"prompt engineering必然导致冗长"的传统观念。
综上所述,大规模实验表明,PhaseEvo在优化few-shot prompts的性能和效率上都达到了新的高度,这得益于其在全局探索和局部利用间的动态平衡,以及对探索过程的精细把控。相信这一全新的优化范式能为后续的prompting研究提供重要的参考和补充。
4 总结后记
本论文针对联合优化prompt指令和示例的问题,提出了一种名为PhaseEvo的迭代优化框架。通过在"全局探索"和"局部利用"间的动态平衡,以及对不同阶段的适应性控制,PhaseEvo在35个benchmark任务上实现了显著超越现有方法的性能,且在计算效率上也达到了新的高度。实验结果表明,PhaseEvo生成的prompt在可解释性和连贯性上也优于人工设计,为自动prompt优化开辟了新的范式。
疑惑和想法:
-
PhaseEvo目前主要关注单任务prompt优化,如何扩展到多任务场景?是否可以引入任务间的知识迁移和few-shot泛化?
-
除了准确率等常见指标,如何评估优化后prompt的可解释性、稳健性和公平性?这些属性如何纳入优化目标?
-
PhaseEvo的搜索空间目前局限于离散token序列,是否可以引入连续嵌入表示,实现更细粒度的优化?
可借鉴的方法点:
-
"探索-利用"平衡的思想可以推广到其他需要在连续空间和离散空间混合搜索的优化问题,如神经架构搜索、强化学习等。
-
将LLM作为优化器参与问题求解的范式值得借鉴,可以利用LLM的先验知识指导优化过程,减少盲目搜索。
-
基于performance vector的个体表示方法可以应用到其他进化算法中,提高种群多样性和优化效率。
-
自适应阶段划分的思想可以用于控制其他迭代优化算法的收敛速度和资源分配,提高鲁棒性。



)
---Linux内核的组成)


)





)





