- 正则表达式扩展
- u修饰符(Unicode模式)
- y修饰符(Sticky或粘连模式)
- s修饰符(dotAll模式)
- Unicode属性转义
- 正则实例的flags属性
- 字符串方法与正则表达式的整合
- javascript的常用的正则表达式
- 验证数字
- 邮箱验证
- 手机号码验证
- 身份证号码验证
- URL验证
- javascript的正则表达式的匹配符有哪些?
- 点.:
- 脱字符^:
- 美元符号$:
- 方括号[]:
- **反斜杠**:
- 星号*:
- 加号+:
- 问号?:
- 花括号{}:
- 竖线|:
- 圆括号:
- 反斜杠后面跟特殊字符:
- 先行断言?=… 和 否定先行断言?!..:
- 后行断言?<=… 和 否定后行断言?<!..:
- i、g、m、u、y、s修饰符:
1. 正则表达式扩展
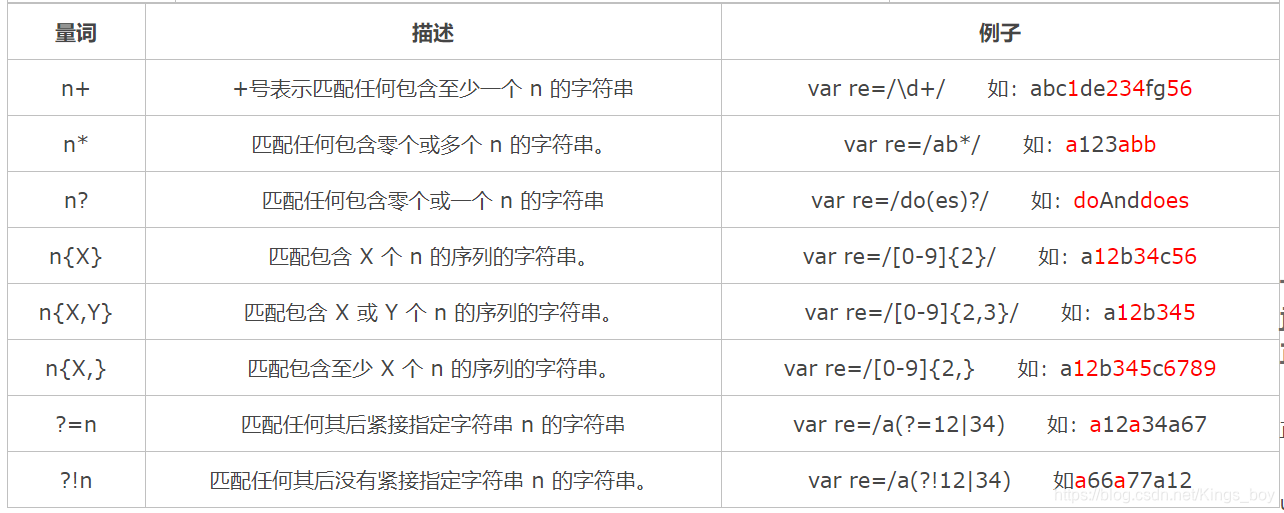
ES6对正则表达式进行了多方面的扩展,以下是一些关键的扩展点及其示例:
1.1. u修饰符(Unicode模式)
- 功能: 用于正确处理大于
\uFFFF的Unicode字符,即正确处理四个字节的UTF-16编码。启用此模式后,正则表达式能够识别并正确匹配Unicode字符,避免将多字节字符识别为多个字符。 - 示例:
const regex = /\u{1F600}/u; // 匹配笑脸表情符号 😄
console.log(regex.test('😄')); // 输出: true
1.2. y修饰符(Sticky或粘连模式)
- 功能: 类似于
g修饰符的全局匹配,但要求每次匹配必须从上一次匹配结束的位置开始。如果上次匹配结束在字符串末尾,则下次匹配尝试会失败。 - 示例:
const regex = /a/y;
const str = 'banana';
let match;
while ((match = regex.exec(str)) !== null) {console.log(match.index, match[0]);
}
// 输出: 1 a, 3 a, 5 a
// 注意,每次匹配都是从上一个'a'之后开始
1.3. s修饰符(dotAll模式)
- 功能: 使得
.可以匹配任意单个字符,包括换行符(\n)和回车符(\r),以往.不匹配换行符。 - 示例:
const regex = /.+/s;
console.log(regex.test('line1\nline2')); // 输出: true
// 此处 '.' 能够匹配包括换行在内的任意字符
1.4. Unicode属性转义
- 功能: 允许你根据Unicode字符的属性来匹配字符,如脚本类型、类别等。
- 示例:
const regexGreekSymbol = /\p{Script=Greek}/u;
console.log(regexGreekSymbol.test('π')); // 输出: true
// 匹配任何属于希腊语脚本的字符
1.5. 正则实例的flags属性
- 功能: 提供了一个读取正则表达式修饰符的方法。
- 示例:
const regex = /abc/ig;
console.log(regex.flags); // 输出: 'gi'
1.6. 字符串方法与正则表达式的整合
- 功能: ES6将原本字符串上的方法(如
match()、replace()、search()和split())调整为直接调用RegExp实例方法,增强了正则表达式与字符串操作的一致性和效率。
String.prototype.match 调用
RegExp.prototype[Symbol.match]
String.prototype.replace 调用
RegExp.prototype[Symbol.replace]
String.prototype.search 调用
RegExp.prototype[Symbol.search]
String.prototype.split 调用
RegExp.prototype[Symbol.split]
这些扩展增强了JavaScript正则表达式的功能,使其能更好地支持Unicode字符处理和提供了更灵活的匹配选项。
2. javascript的常用的正则表达式
JavaScript中常用的正则表达式广泛应用于文本验证、格式检查、数据提取等多种场景。下面列举几个典型的应用示例:
2.1. 验证数字
- 用途: 检查输入是否为纯数字。
- 正则表达式:
^\d+$ - 示例:
let numRegex = /^\d+$/;
console.log(numRegex.test("123")); // 输出: true
console.log(numRegex.test("123abc")); // 输出: false
2.2. 邮箱验证
- 用途: 验证电子邮件地址的格式是否正确。
- 正则表达式:
^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$ - 示例:
let emailRegex = /^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$/;
console.log(emailRegex.test("example@example.com")); // 输出: true
console.log(emailRegex.test("not-an-email")); // 输出: false
2.3. 手机号码验证
- 用途: 校验常见的中国大陆手机号格式。
- 正则表达式:
^1[3-9]\d{9}$ - 示例:
let phoneRegex = /^1[3-9]\d{9}$/;
console.log(phoneRegex.test("13812345678")); // 输出: true
console.log(phoneRegex.test("12801234567")); // 输出: false
2.4. 身份证号码验证
- 用途: 简单验证中国大陆身份证号码。
- 正则表达式:
^[1-9]\d{5}(18|19|20)\d{2}(0[1-9]|1[0-2])(0[1-9]|[12][0-9]|3[01])\d{3}[\dxX]$ - 示例:
let idCardRegex = /^[1-9]\d{5}(18|19|20)\d{2}(0[1-9]|1[0-2])(0[1-9]|[12][0-9]|3[01])\d{3}[\dxX]$/;
console.log(idCardRegex.test("123456199001011234")); // 输出: true
console.log(idCardRegex.test("123456190001011234")); // 输出: false
2.5. URL验证
- 用途: 检查字符串是否符合URL的格式。
- 正则表达式:
^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$ - 示例:
let urlRegex = /^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/;
console.log(urlRegex.test("https://www.example.com")); // 输出: true
console.log(urlRegex.test("not-a-url")); // 输出: false
正则表达式的复杂度可以根据验证需求的严格程度而有所不同。
3. javascript的正则表达式的匹配符有哪些?
JavaScript的正则表达式支持多种匹配符(也称作元字符或特殊字符),它们具有特殊的含义,用于构建复杂的匹配模式。以下是一些核心的匹配符及其简要说明:
3.1. 点(.):
匹配除换行符(\n)之外的任何单个字符。
3.2. 脱字符(^):
匹配字符串的开始位置,如果配合m修饰符(多行模式),也会匹配每一行的开始。
3.3. 美元符号($):
匹配字符串的结束位置,如果配合m修饰符,也会匹配每一行的结束。
3.4. 方括号([]):
定义一个字符集,匹配其中的任意一个字符。例如,[abc]匹配"a"、“b"或"c”。
3.5. 反斜杠(\):
用于转义特殊字符,使其作为普通字符处理,或用于插入特殊序列,如\d匹配任何数字。
3.6. 星号(*):
匹配前面的子表达式零次或多次。
3.7. 加号(+):
匹配前面的子表达式一次或多次。
3.8. 问号(?):
匹配前面的子表达式零次或一次,或在非贪婪模式下使重复尽可能少。
3.9. 花括号({}):
指定数量的重复次数。例如,a{3}匹配"aaa",a{2,4}匹配"aa"到"aaa"。
3.10. 竖线(|):
表示“或”,用于匹配两个或多个选择中的一个。例如,cat|dog匹配"cat"或"dog"。
3.11. 圆括号(()):
用于定义捕获组,可以提取匹配的内容,也可以用于应用量词或使用特殊构造如后向引用。
3.12. 反斜杠后面跟特殊字符:
如\d匹配任何十进制数字,\s匹配任何空白字符,\w匹配任何字母数字字符等。
3.13. 先行断言((?=...)) 和 否定先行断言((?!...)):
分别匹配后面跟有特定模式的位置,和后面不跟有特定模式的位置。
3.14. 后行断言((?<=...)) 和 否定后行断言((?<!...)):
分别匹配前面跟有特定模式的位置,和前面不跟有特定模式的位置。(注意:这些特性并非所有环境都支持,但在ES2018中被引入了JavaScript。)
3.15. i、g、m、u、y、s修饰符:
这些不是操作符,而是正则表达式标志,用于改变匹配行为,如忽略大小写(i)、全局匹配(g)、多行模式(m)、Unicode模式(u)、粘连模式(y)和dotAll模式(s)。
这些匹配符构成了构建复杂正则表达式的基础,通过组合使用,可以实现对文本的精确匹配和提取。