4月20日,在2024 OceanBase开发者大会上,云粒智慧的高级技术专家付大伟,分享了云粒智慧实时数仓的构建历程。他讲述了如何在传统数仓技术框架下的相关努力后,选择了OceanBase + Flink CDC架构的实时数仓演进历程。
业务背景及挑战
云粒智慧成立于2018年6月,主要面向政府和中小规模的企业,提供智慧城市和生态环保方面的智能化应用。联通云粒拥有三中台:数据中台、智能中台和应用中台,以及智能化应用产品,与政府合作为各地提供智慧城市建设服务,包括政务数据一体化、公共数据开放、一网统管、一网通办等业务。另外,在一些应急领域如水利和环保,也拥有智能化预警等方面的业务。
其中,数据中台主要提供数据采集、融合、治理、分析、计算的服务,是公司比较重要的产品。自公司成立初开始产品发育,到如今历经5个大版本迭代,现已在全国范围内落地上百个客户项目。下图是数据中台架构,可以看到其整体运行在K8S集群上,为了更好地动态扩缩容,计算和存储都使用OceanBase,同时使用Minio做非结构化文件的存储工作,使用Flink流计算引擎。在引擎上层,我们构建了一个引擎操作系统,用来适配在客户交付过程中面临的不同的大数据底座。
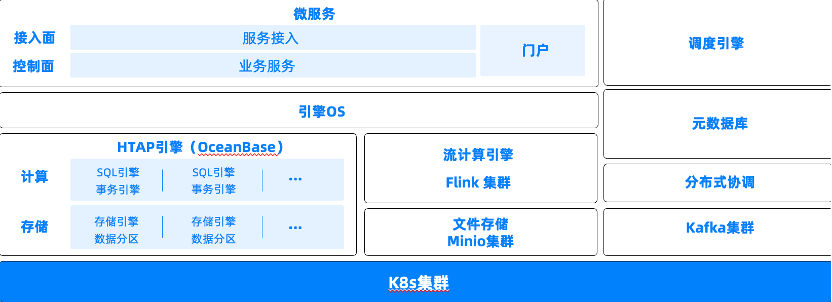
由于为各类政企交付项目,因此我们在交付过程中积累了三方面的业务特性。
- 多业务线,形态各异。政务领域业务跨度较大,多种数据源、不同频率的数据汇集,带来很多业务复杂性问题。
- 计算资源缺乏。各项目3-5台计算资源,难以运行大规模计算;服务器资源匮乏,大量数据计算往往耗时较长。
- 业务协同需求强。数据实时性较强,各单位追求业务协同效率,比如防汛减灾、水质污染等实时告警场景。
上述业务特点为技术实现带来了很大的挑战。技术中台作为大数据处理系统,引擎是它最核心的内容,在中台1.X到3.X版本迭代过程中,其实选用Hive和HDFS作为计算存储的引擎,但遇到诸多痛点,主要表现为以下四点。
- 资源利用率低:受限于YARN的调度策略,需要在项目中依据任务和资源情况逐个调优,任务量增加后仍需持续投入,难以一劳永逸。
- 数据时延:实时数据入仓带来了诸多小文件问题,虽然项目组在Flink的框架下做了诸多优化,仍然无法满足大屏监控、预警、数据消费等应急场景需求。
- 不够灵活:数据更新方式仅支持全表/分区级覆盖,应对远景冷区部分数据更新时,处理逻辑复杂且低效。
- 运维复杂:组件众多,配置、监控、伸缩、保活等都极大地增加了运维工作量。高可用场景下每个节点均需要多个进程,容器部署性能下降。
因此,在数据中台4.X版本时,我们希望引进新的引擎来解决上述问题。
实时数仓的架构演进
数据引擎作为一款基础软件,目前市面上百花齐放。我们在选型过程中主要关注五个方面:
- 它的开源协议是否足够宽松。
- 是否能够支持云原生的方式部署。
- 它需要支持集群。
- 它能够以私有化的方式部署到客户的现场。
- 这个产品以及它的生态是否有足够高的成熟度。
我们经过了较长时间的调研,认为OceanBase在三方面表现优异。
第一,它的架构设计比较简洁,主要是由OBServer和OBProxy组成,即便运维多套客户环境,也会节省很大的成本,增加一些便利;
第二,数据中台作为一个原生支持多租户的系统,我们使用OceanBase的多租户,整体方案上都会更加契合。
第三,OceanBase作为开源数据库(https://github.com/oceanbase/oceanbase),其社区和生态开放、成熟,尤其是针对我们常用的数据集成软件DataX和Flink,都有官方的一些插件。OceanBase非常契合我们的技术实现路线。
因此,我们也对OceanBase做了一些性能测试,包括我们部署3台8核32G的服务器集群,每次处理的数据量都达到1G以上来观测它的性能。我们观测到,OceanBase的性能指标最高可以达到Hive的24倍,在整个选型和应用过程中,我们发现OceanBase的学习成本也比较低的,熟悉MySQL就能上手,而且官方文档比较齐全。此外,当我们确定产品选型后,在后续的迁移工作中,我们花了一个多月的时间就完成了适配和迁移,比预期快很多。同事据运维人员反馈,利用OceanBase的日志能够解决大部分运维的问题。
至于数据同步工具的选型,Flink CDC的选型比较水到渠成,首先是契合度的问题,数据中台在最初版本中,我们已经使用Flink作为流计算的引擎,所以Flink CDC比较贴合我们的路线。其次,Flink CDC支持的方式非常多,包括全量、增量,以及先全量再增量的方式,这有利于提升交付效率。以往我们利用离线的开发,比如Hive的数仓来做增量同步时,需要开发人员设计一个比较大的图,去数仓捞出最新的时间戳,并且把它作为一个参数注入DataX的一些导入节点上,之后还需要数据去重、关联等治理操作才能够完成。
此外,Flink CDC运行在Flink分布式引擎上,在K8s上,我们根据客户实时数据量的大小可以自动扩缩容Flink。
自从选用OceanBase+Flink CDC架构后,架构变得非常简洁,我们用OceanBase代替了以前以Hive为主的MPP引擎、HiveServer2、YARN和HDFS。使用Flink CDC来完成关联数据库日志的同步,使用FlinkSQL做相应的实时加工处理。数据写入流程也更加便捷。
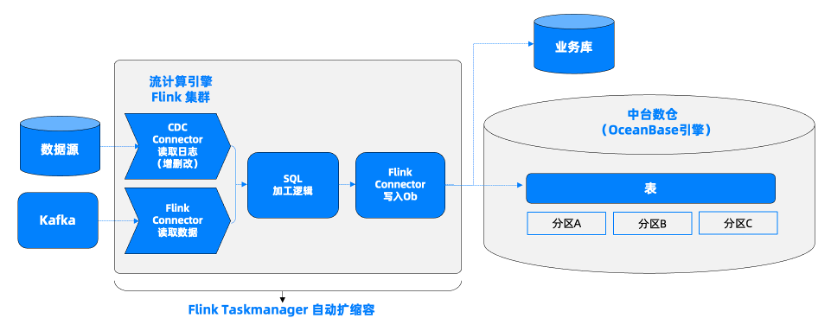
总而言之,优化后的平台架构,在以下方面呈现出较大优势,使我们能够依托 FlinkCDC 和 OceanBase,建设完全云原生的智能化数据中台。
第一, 云原生化。微服务、调度任务、大数据引擎全部基于K8S云原生技术,支持容器化部署和资源调度,实现弹性伸缩和快速升级。
第二, 数据开发。不同业务形态下简易配置,离线与实时数据开发均提供SQL 化(离线标准 SQL、实时 FlinkSQL)、配置化;拖拉拽式作业编排,百万级任务调度、开发效率提升。
第三, 运维管理。以往,大数据底座问题往往需要运维+开发花费1-2天时间进行排查和优化,OceanBase清晰的日志信息给运维带来极大便利,常见问题1小时内解决。
第四, 资源利用。流计算和 OceanBase 的广泛应用,使得单个项目服务器资源由原来的11台 缩减到 6台,在业务量和资源投入上可以更好的平衡。
第五, 学习成本。OceanBase对大数据新入行人员非常友好,学习成本极低。
下面我们以具体项目来说明OceanBase + FlinkCDC 架构的优势。
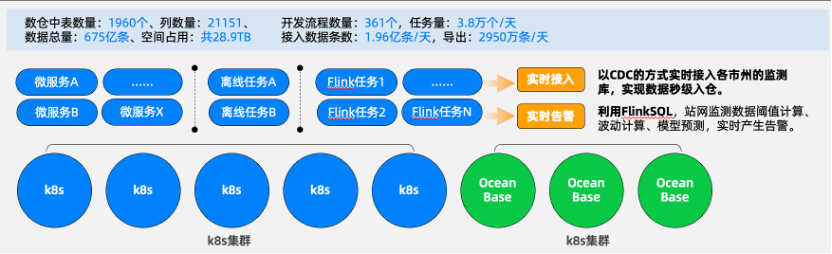
这是我们在贵州某项目上的应用,从客户的数据量、接入量可以看出,体量较大。客户需要接入物联网设备产生的数据,并且做实时预测、实时告警。它的数据表产过1900个,涉及的数据量有675亿条,而且每天接入的数据量都达到1.9亿左右。
在改造前,我们使用Hive引擎需要11台服务器,并且实时数据接入是采用离线批量的方式让它入仓,基本上会有5分钟左右的延迟,不能满足客户实时告警的需求。另外,更新逻辑比较复杂,我们需要额外运行很多任务以保证入仓数据是最新、最完整、和业务匹配的。
改造后,我们发现只需要8台服务器就能够支撑客户所有的业务,而且可以将延时控制在5秒左右,极大提升了数据告警效率。由于更新支持变得容易,大家的任务量也被极大缩减了。整体而言,服务器资源节省27%;实时效率提升100倍;业务复杂度降低10%。
未来规划
我们今年正在发力数据中台5.X版本的建设,进一步支持云原生化,包括结合OceanBase 4.3版本在云原生环境下做项目交付;通过FlinkCDC 支持更多数据源、Flink ML 探索应用,增强流计算;基于计算引擎的资源监控升级调度策略;让数据平台能够在有限的资源下运行更多的调度任务。



)







![[力扣题解]455. 分发饼干](http://pic.xiahunao.cn/[力扣题解]455. 分发饼干)





)
:什么是网关设备?(网络层面))
