MapReducer
目录
MapReducer
1.Hadoop是干嘛的
2.maven
3.MapReducer
1)分析数据 写sql
2)写程序
a.mapper程序
b.洗牌 分组排序
c.reducer程序
d.Test类
1.Hadoop是干嘛的
1)分布式存储 HDFS
2)处理大规模数据 MapReducer
2.maven
1)maven是用来下载jar包和加载依赖的
2)项目管理 打jar包 项目之前依赖
3)如何在maven中下载jar包
通过组id 工程名 和版本号就能确定一个工程 确定一个jar包

4)下载jar包 要给他一个下载的网址

3.MapReducer
1)分析数据 写sql
我们现在有一份订单数据
orderinfo
dt name money
2024-04-23,zhangsan,90
2024-04-23,lisi,50
2024-04-24,zhangsan,95
2024-04-24,lisi,55
现在 求商家每天的收入金额 假设我们现在使用sql语句求这个值
select sum(money),dt from orderinfo group by dt;
2)写程序
a.mapper程序

①用来接收每一行数据
②确定kv对 并输出kv对
k就是group后面的字段 v就是money

//KEYIN, VALUEIN, KEYOUT, VALUEOUT
//在Hadoop的输入输出中 不让我们用Java类型 使用Hadoop对应的类型
//long对应LongWritable String对应Text Float对应FloatWritable
public class OrderMapper extends Mapper<LongWritable, Text,Text, FloatWritable> {}Hadoop为什么不让使用Java类型?
map的输出kv或reduce的输出kv最后写到磁盘上,而用java类型写入磁盘(序列化)速度非常慢,也就是说,Java在作序列化的时候,速度非常慢,所以要用Hadoop类型,对Java的序列化做了改进。
package com.pracle.mr;import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;//KEYIN, VALUEIN, KEYOUT, VALUEOUT
//在Hadoop的输入输出中 不让我们用Java类型 使用Hadoop对应的类型
//long对应LongWritable String对应Text Float对应FloatWritable
public class OrderMapper extends Mapper<LongWritable, Text,Text, FloatWritable> {@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FloatWritable>.Context context) throws IOException, InterruptedException {String[] orders = value.toString().split(",");String okey=orders[0];String ovalue=orders[2];//context表示输出 输入输出都是Hadoop类型context.write(new Text(okey),new FloatWritable(Float.parseFloat(ovalue)));}
}
练习:求流量和 写一下Mapper程序
182133434,2020-12-12,9000
2123444343,2020-12-13,900
2323432424,2020-12-12,900
23234344,2020-12-13,900
package com.pracle.mr;import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class FlowMapper extends Mapper<LongWritable, Text,LongWritable, DoubleWritable> {@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, LongWritable, DoubleWritable>.Context context) throws IOException, InterruptedException {String[] flow = value.toString().split(",");String telephone=flow[0];String flo=flow[2];context.write(new LongWritable(Integer.parseInt(telephone)),new DoubleWritable(Double.parseDouble(flo)));}
}
Mapper<LongWritable, Text,Text, FloatWritable>
LongWritable:字符个数
Text:每一行数据
Text:SQL语句中group by后面的字段 key
FloatWritable:SQL语句中sum里面的字段 value
b.洗牌 分组排序
Mapper运行完以后 将数据交给shuffle shuffle根据key默认升序对数据进行分组排序

c.reducer程序
一组一组读取数据
reducer有四个参数
kin:shuffle中已经分好组的数据的key
vin:key对应的数据 可能会有多个 我们可以联想到list 数组
okey:就是kin
ovalue:sum(money)

package com.pracle.mr;import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
import java.util.Iterator;public class OrderReducer extends Reducer<Text, FloatWritable,Text,FloatWritable> {@Overrideprotected void reduce(Text key, Iterable<FloatWritable> values, Reducer<Text, FloatWritable, Text, FloatWritable>.Context context) throws IOException, InterruptedException {Iterator<FloatWritable> it = values.iterator();float sum=0;while (true){if(it.hasNext()){FloatWritable f = it.next();sum+=f.get();//类对象不能做+ - * /}else {break;}}
context.write(key,new FloatWritable(sum));}
}
d.Test类
Test类主要用来创建一个作业 完成对一份数据的处理
package com.pracle.mr;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;
//Test用于提交我们的Job作业
public class Test {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// System.setProperty("hadoop.home.dir","D:\\ALidownload\\hadoop-27");Configuration configuration=new Configuration();//获取Job的实例对象Job job = Job.getInstance(configuration);//设置驱动的类job.setJarByClass(Test.class);//设置Mapper的具体实现类job.setMapperClass(OrderMapper.class);//设置Map端输出的数据类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(FloatWritable.class);//设置Reducer的具体实现类job.setReducerClass(OrderReducer.class);//设置Reduce端输出的数据类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(FloatWritable.class);//设置输入输出路径FileInputFormat.setInputPaths(job,new Path("D:\\IDEA_workplace\\jtxy_hdfs\\data\\a.txt"));FileOutputFormat.setOutputPath(job,new Path("D:\\IDEA_workplace\\jtxy_hdfs\\output\\a_out.txt"));if(job.waitForCompletion(true)){System.out.println("程序运行成功!");}else{System.out.println("程序运行失败!");}}
}
在运行程序之前 我们先配置一下Hadoop的环境变量


环境变量配置完成以后 我们点击运行就可以了

点击查看结果

上面的程序我们也可以在Hadoop上面运行
我们修改以下内容

然后打包

将我们打包的jar放到HDFS上去
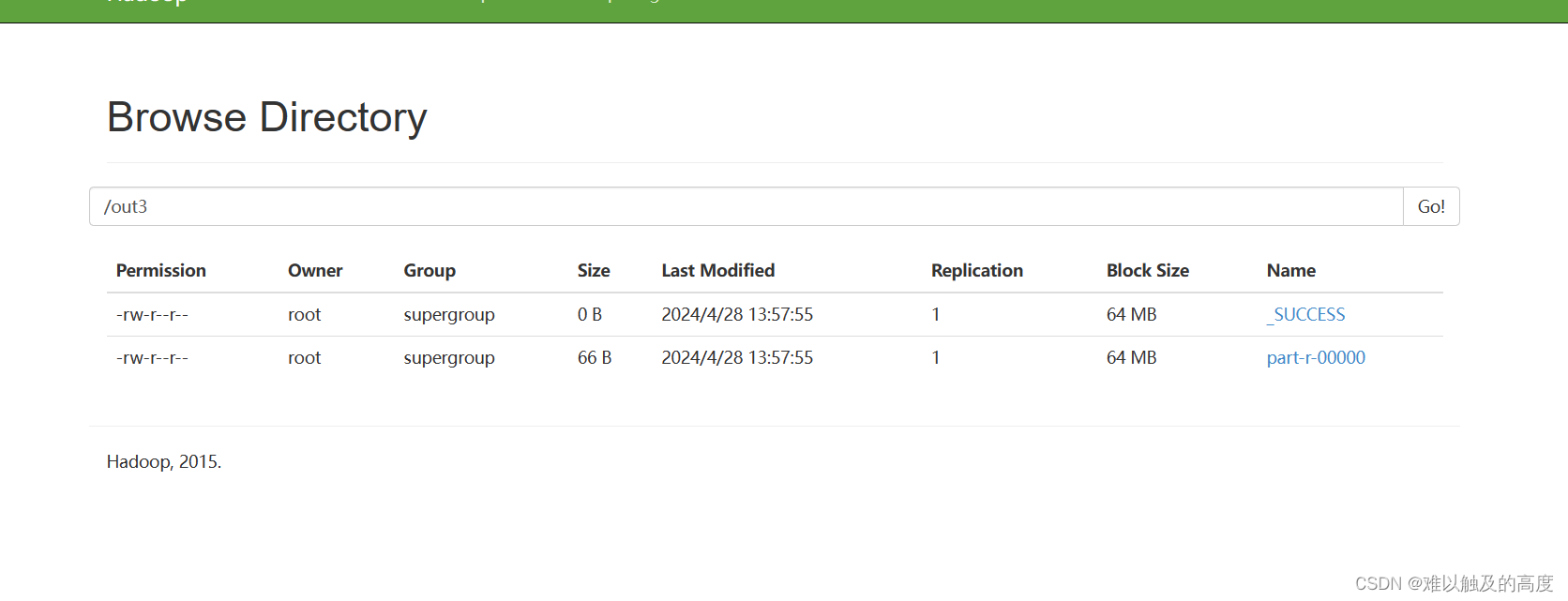
输入以下命令 证明MapReduce也可以在Hadoop上运行
hadoop fs -put a.txt /
hadoop jar jtxy_hdfs-1.0-SNAPSHOT-jar-with-dependencies.jar /a.txt /out3


多态)


)





)





Scikit-learn机器学习(一))


