VASA-1:语音生成AI视频
前言

最近,微软公司公布了一项图生视频的 VASA-1 框架,该 AI 框架只需使用一张真人肖像照片和一段个人语音音频,就能够生成精确逼真的相对应文本的视频,而且可以使表情和面部动作表现的十分自然。
VASA-1
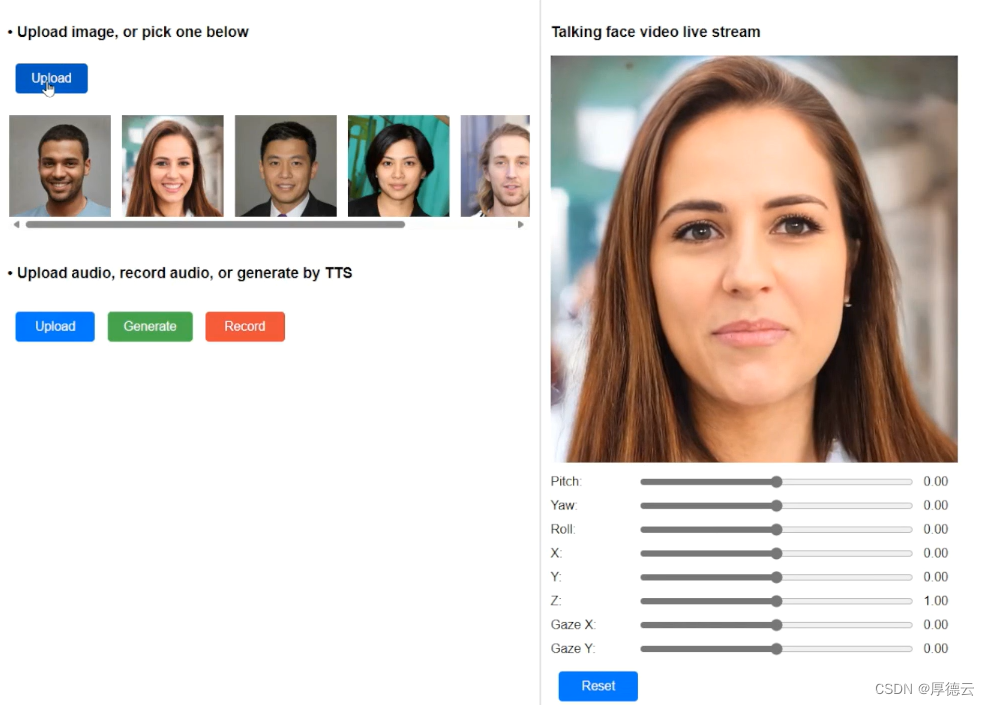
从官网给出的视频来看,VASA-1不仅可以在只上传一张静态图像和音频就可以生成高质量视频,还能够支持多国语言、独立控制嘴唇动作、眼睛、表情的变化和方向,同时也支持调整 参数来让画面。目前许多业内的相关软件都达不到VAS-1的效果。
目前VAS-1一键支持在离线模式下创作512×512分辨率的45fps的视频以及线流模式的40fps视频生成。并且前置延迟也只有170毫秒,这种处理速度也大大的增加了它的实用性。
总结

目前看来,VASA-1的推出标志着人工智能在语音生成视频领域的重大进展。VASA-1通过其先进的AI技术与强大的算力支持,使得用户能够仅用一张照片和一段音频,就能创造出细节丰富、表情自然的动态视频,这在以往是难以想象的。
总的来说,这不仅是AI视频生成技术的一个突破,也为整个数字媒体产业带来了新的可能性。而这样的壮举没有大量的算力支撑是很难成功的。
而这样的算力,你在厚德云官方就可以找到!如果你也对算力感兴趣或有需求,可以点击链接厚德云-专业 AI 算力云⎮GPU算力租赁首选厚德云进入厚德云官方看看!
厚德云是一款专业的AI算力云平台,为用户提供稳定、可靠、易用、省钱的GPU算力解决方案。海量GPU算力资源租用,就在厚德云。

)







--SpringCloud微服务工程公共部分提取)


)

)





