【五】序列化类serializer单表
【1】主要功能
- 快速序列化
- 将数据库模型类对象转换成响应数据,以便前端进行展示或使用。
- 这些响应数据通常是以Json(或者xml、yaml)的格式进行传输的。
- 反序列化之前数据校验
- 序列化器还可以对接收到的数据进行验证,确保数据的完整性和准确性。这有助于防止因数据错误或恶意输入导致的安全问题。
- 反序列化
- 序列化类也能将前端发送的请求数据(如json、xml、yaml格式的数据)转换成模型类对象,便于后端进行处理。
【2】序列化功能
(1)自定义序列化类
- 这是模型表的字段
from django.db import modelsclass Book(models.Model):book_name = models.CharField(max_length=64, verbose_name='书名')book_price = models.DecimalField(max_digits=6, decimal_places=2, verbose_name='价格')publish_name = models.CharField(max_length=64, verbose_name='出本社名字')
- 这是自定义的序列化类
- 这里的每个字段和序列化类的每个字段一一对应
from rest_framework import serializersclass BookSerializer(serializers.Serializer):book_name = serializers.CharField()book_price = serializers.IntegerField()publish_name = serializers.CharField()
(2)视图层中使用
-
使用语法
自定义序列化类(instance=模型表的数据, many=True)instance参数:可以传入模型表的queryset对象,也可以是单个querydict对象many参数:默认为False, 针对前面的instance对象- 如果传入的是多条数据即
queryset对象,那么就需要置为True - 如果传入的是单条数据即
querydict对象,那么就需要置为False
- 如果传入的是多条数据即
-
可以很明显的发现
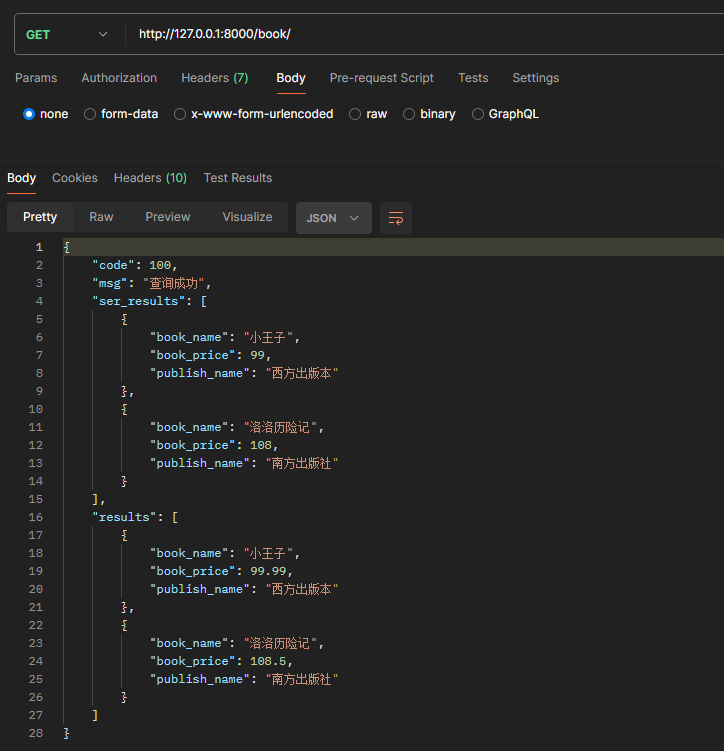
- 使用序列化内极其容易的将模型表的所有信息转换为列表传回了前端(因为是多条数据所以是个列表,如果是单条数据那么就是一个字典)
- 如果不适用序列化类,那么需要一次循环出所有的对象,然后一次根据模型表的字段进行赋值操作,这是极其繁琐的
class BookAPIView(APIView):def get(self, request, *args, **kwargs):book_queryset = Book.objects.all()# 使用序列化类book_ser = BookSerializer(instance=book_queryset, many=True)# 不适用序列化类results = []for info_obj in book_queryset:info_dict = dict()info_dict['book_name'] = info_obj.book_nameinfo_dict['book_price'] = info_obj.book_priceinfo_dict['publish_name'] = info_obj.publish_nameresults.append(info_dict)return Response({'code': 100, 'msg': '查询成功', 'ser_results': book_ser.data, 'results': results})
【3】校验数据
(0)语法
book_ser = BookSerializer(data=request.data)- data参数:传入需要校验的数据
- 因为用的是APIView,所以直接传入
request.data即可
book_ser.is_valid()- 调用
is_valid()方法会触发序列化器中的所有验证逻辑,包括字段级别的验证(局部钩子)和对象级别的验证(全局钩子)。 - 如果数据通过了所有验证,
is_valid()将返回True;否则,返回False。
- 调用
book_ser.data- 如果数据通过了验证(即
book_ser.is_valid()返回True),可以通过book_ser.data访问经过验证和转换的数据。
- 如果数据通过了验证(即
book_ser.errors- 如果数据验证失败,
book_ser.errors将包含一个字典,其中列出了所有验证失败的字段以及相应的错误信息。
- 如果数据验证失败,
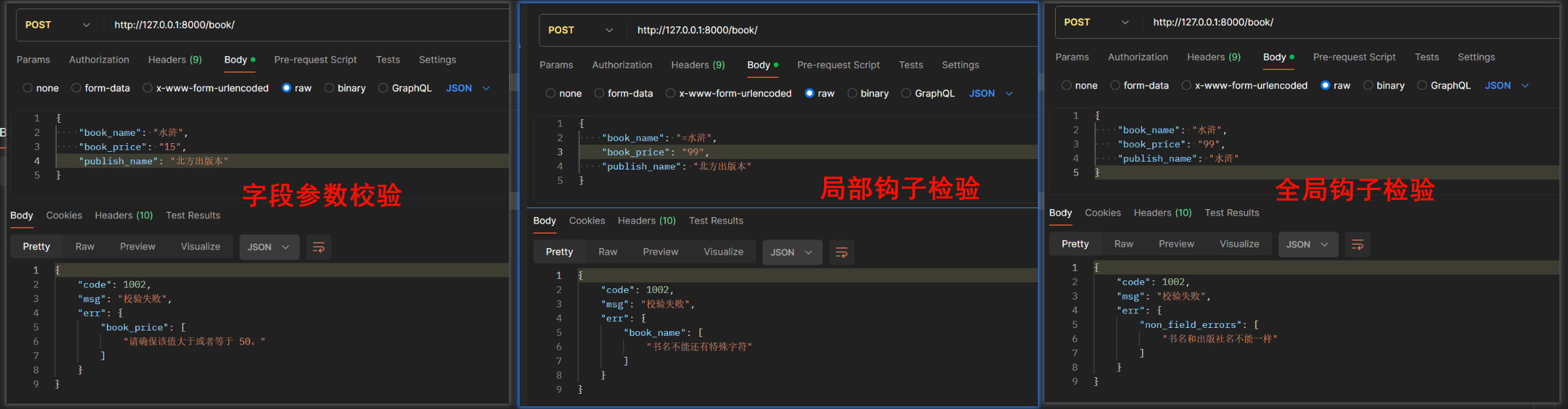
(1)字段参数校验
- 在自定义的序列化类中,每个字段是有一些参数的
- 这里添加一些参数进行校验
- 比如字符类型的长度检验,整型的最大、最小值检验等等
book_name = serializers.CharField(max_length=12, min_length=2)
book_price = serializers.IntegerField(max_value=500, min_value=50)
(2)钩子检验
-
钩子分为两种,一种是局部钩子,另一种是全局钩子
- 无论是哪种钩子函数,都需要将勾出来的数据返回回去
-
局部钩子:
- 是针对序列化器中单个字段的验证方法。
- 通常遵循
validate_<field_name>的命名模式,其中<field_name>是要验证的字段名。 - 当序列化器执行验证时,它会自动调用这些局部钩子方法。
-
全局钩子:
- 用于验证整个序列化器数据集的方法。
- 全局钩子通常覆盖序列化器中的
validate方法。 - 这个方法接收一个包含所有字段值的字典作为参数,并允许执行跨字段的验证逻辑。
# 序列化类
from rest_framework import serializers
from rest_framework.exceptions import ValidationErrorclass BookSerializer(serializers.Serializer):# 字段参数检验book_name = serializers.CharField(max_length=12, min_length=2)book_price = serializers.IntegerField(max_value=500, min_value=50)publish_name = serializers.CharField()# 局部钩子检验def validate_book_name(self, book_name):if any([i in book_name for i in ['*', '/', '=', '%', '@']]):raise ValidationError("书名不能还有特殊字符")return book_name# 全局钩子检验def validate(self, attrs):if attrs.get('book_name') == attrs.get('publish_name'):raise ValidationError('书名和出版社名不能一样')return attrs
# 视图层
class BookAPIView(APIView):def post(self, request, *args, **kwargs):book_ser = BookSerializer(data=request.data)if book_ser.is_valid():return Response({'code': 100, 'msg': '校验通过', 'data': book_ser.data})return Response({'code': 1002, 'msg': '校验失败', 'err': book_ser.errors})
- 结果
【4】反序列化保存
(1)语法
-
book_ser=BookSerializer(instance=obj,data=request.data)- instance参数:这个参数主要是在修改保存的时候才使用,传入的数据可以是对象,也可以是id等等
- data参数:这个还是传入的需要反序列化的内容
-
book_ser.save()- 用于将验证通过的数据保存为数据库中的记录
-
小拓展
- save中可以给额外参数
- 比如
.save(time=datetime.datetime.now()) - 这个需要模型表中有time的字段,结果就是将当前时间也保存在表中,不用经过数据校验
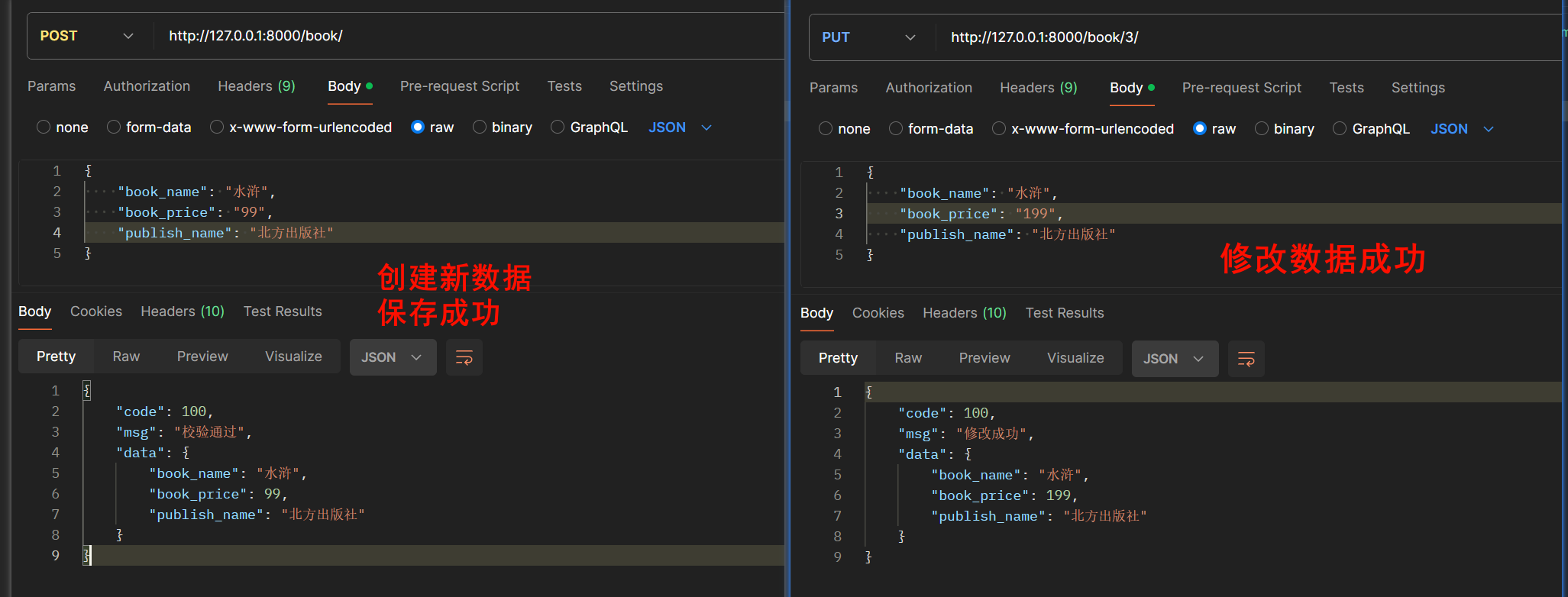
(2)两种保存方式
-
反序列化保存同样分为两个:
- 一个是创建新数据保存,一个是更新老的数据保存,这两个有很大的差别
- 无论是哪个都需要返回创建或修改后的数据
-
首先说创建新的数据
- 必须要重写create()方法,这个比较简单,直接通过模型创建即可
-
然后说修改保存
- 这里的视图层必须要传如一个要修改数据的相关信息,要不然是不知道修改谁的
- 可以传入pk,根据pk过滤以后使用update方法即可
- 可以传入obj,可以使用难度较高的反射,也可以一个字段一个字段的改
- 视图层
class BookAPIView(APIView):def put(self, request, *args, **kwargs):pk = kwargs.get('pk')book_obj = Book.objects.filter(pk=pk).first()book_ser = BookSerializer(instance=book_obj, data=request.data)if book_ser.is_valid():book_ser.save() # 需要重写update方法return Response({'code': 100, 'msg': '修改成功', 'data': book_ser.data})return Response({'code': 1002, 'msg': '修改失败', 'err': book_ser.errors})def post(self, request, *args, **kwargs):book_ser = BookSerializer(data=request.data)if book_ser.is_valid():book_ser.save() # 需要重写create放啊return Response({'code': 100, 'msg': '校验通过', 'data': book_ser.data})return Response({'code': 1002, 'msg': '校验失败', 'err': book_ser.errors})
- 序列化类
from rest_framework.exceptions import ValidationErrorclass BookSerializer(serializers.Serializer):# 字段参数检验book_name = serializers.CharField(max_length=12, min_length=2)book_price = serializers.IntegerField(max_value=500, min_value=50)publish_name = serializers.CharField()def create(self, validated_data):book = Book.objects.create(**validated_data)return bookdef update(self, instance, validated_data):for key, value in validated_data.items():setattr(instance, key, value) # 使用反射修改数据return instance

:路由与路由表基础)
(三))







——《大话设计模式》)

——归并排序 + 外排序)




 Object Pascal 学习笔记---第10章第1节(定义属性))

