遥感图像(RSI)中的目标检测始终是遥感界一个充满活力的研究主题。 最近,基于深度卷积神经网络 (CNN) 的方法,包括基于区域 CNN 和基于 You-Only-Look-Once 的方法,已成为 RSI 目标检测的事实上的标准。 CNN 擅长局部特征提取,但在捕获全局特征方面存在局限性。 然而,基于注意力的变压器可以获取远距离的 RSI 关系。 因此,本研究对用于遥感目标检测(TRD)的变压器进行了研究。 具体来说,所提出的 TRD 是 CNN 和带有编码器和解码器的多层 Transformer 的组合。 为了从 RSI 中检测对象,修改后的 Transformer 被设计为聚合多个尺度上的全局空间位置的特征,并对成对实例之间的交互进行建模。 然后,由于源数据集(例如ImageNet)和目标数据集(即RSI数据集)差异较大,为了减少数据集之间的差异,将TRD与传输CNN(T- 提出了基于注意力机制的TRD)来调整预训练模型以实现更好的RSI目标检测。 由于Transformer的训练总是需要丰富的、注释良好的训练样本,而RSI目标检测的训练样本数量通常是有限的,为了避免过拟合,数据增强与Transformer相结合来提高RSI的检测性能 。 所提出的带有数据增强的 T-TRD(T-TRD-DA)在两个广泛使用的数据集(即 NWPU VHR-10 和 DIOR)上进行了测试,实验结果表明所提出的模型提供了有竞争力的结果(即, 与竞争基准方法相比,百倍平均精度为 87.9 和 66.8,最多分别比 NWPU VHR-10 和 DIOR 数据集上的比较方法高出 5.9 和 2.4,这表明基于 Transformer 的方法打开了 RSI 对象检测的新窗口。
综上所述,本研究的主要贡献如下。
(1) 提出了一种基于 Transformer 的端到端 RSI 对象检测框架 TRD,其中对 Transformer 进行了改造,以有效地集成全局空间位置的特征并捕获特征嵌入和对象实例的关系。 此外,引入可变形注意模块作为所提出的TRD的重要组成部分,它仅关注稀疏的采样特征集并缓解高计算复杂度的问题。 因此,TRD 可以处理多个尺度的 RSI,并从 RSI 中识别出感兴趣的对象。
(2)使用预训练的CNN作为特征提取的主干。 此外,为了减轻两个数据集(即ImageNet和RSI数据集)之间的差异,T-TRD中使用注意力机制对特征进行重新加权,进一步提高了RSI检测性能。 因此,预训练的主干可以更好地迁移并获得有判别性的金字塔特征。
(3)数据增强,包括样本扩展和多样本融合,用于丰富训练样本的方向、尺度和背景的多样性。 在提出的 T-TRD-DA 中,减轻了使用不足的训练样本进行基于 Transformer 的 RSI 目标检测的影响。

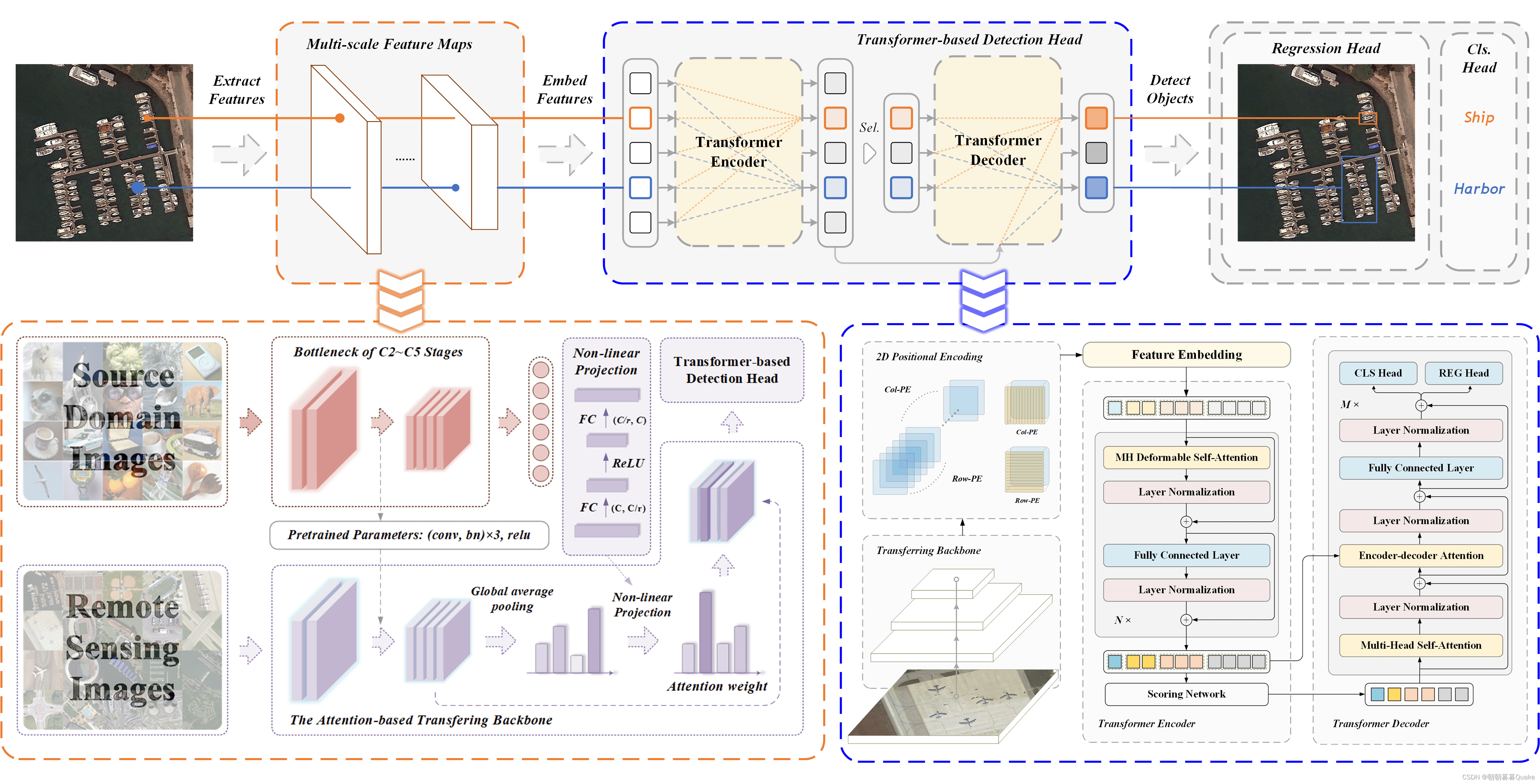
所提出的基于 Transformer 的 RSI 对象检测框架的概述架构。
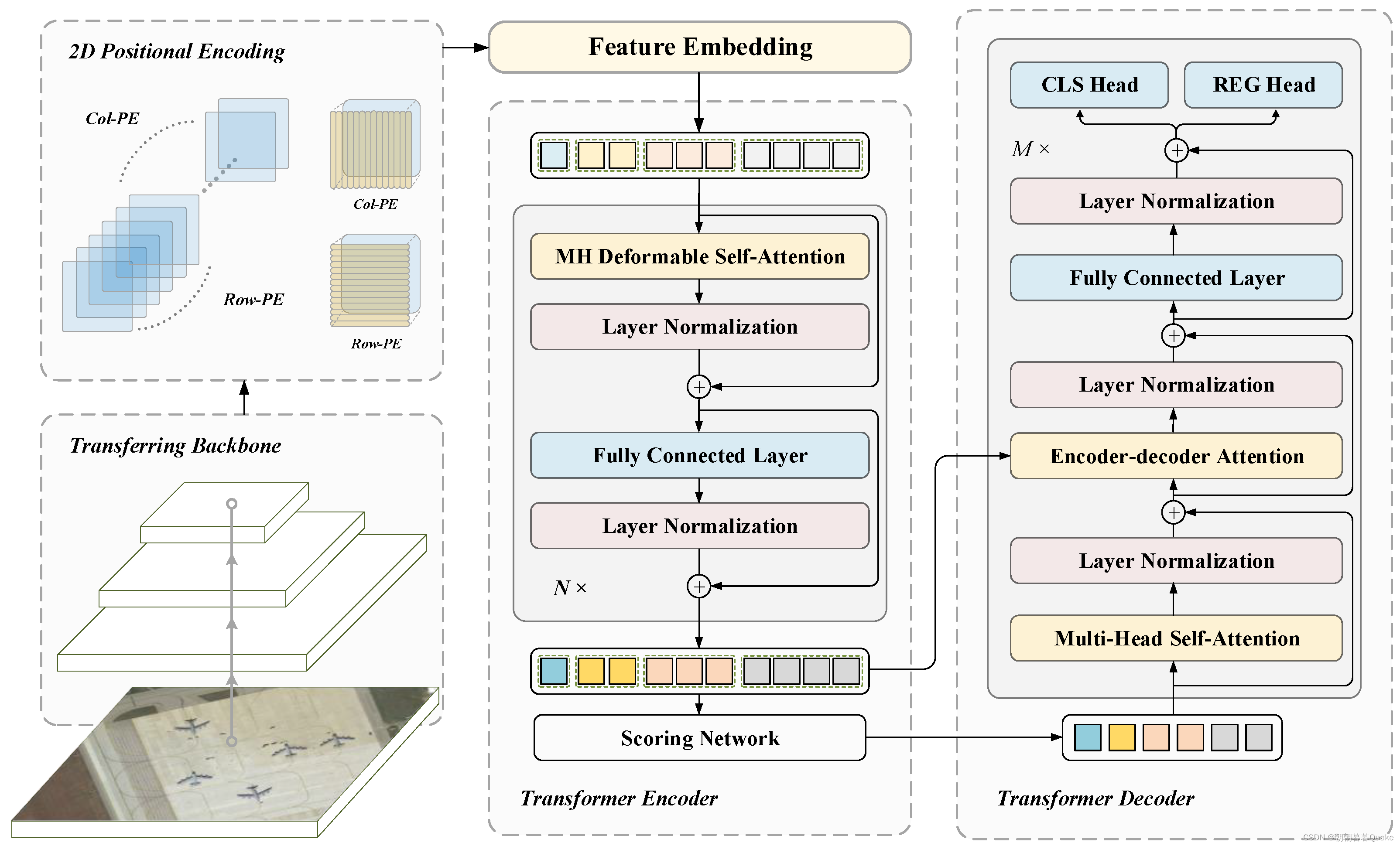
图 2 显示了拟议 TRD 的框架。 首先使用 CNN 主干从 RSI 中提取金字塔多尺度特征图。 然后将它们嵌入 2D 位置编码并转换为可以输入 Transformer 的序列。 Transformer 被改造,以处理图像嵌入序列并对检测到的对象实例进行预测。
Transformer 中的 MHSA 聚合了输入的元素,并且不区分它们的位置; 因此,Transformer 具有排列不变性。 为了缓解这个问题,我们需要在特征图中嵌入空间信息。 因此,𝐿之后
-级特征金字塔{𝒙𝑙}𝐿𝑙=1 从卷积主干中提取,在每个级别补充二维位置编码。 具体来说,将原始 Transformer 的正弦和余弦位置编码分别扩展到列和行位置编码。 它们都是通过对行或列的维度以及𝑑的一半进行编码获得的
通道,然后复制到另一个空间维度。 最终的位置编码与它们连接起来。
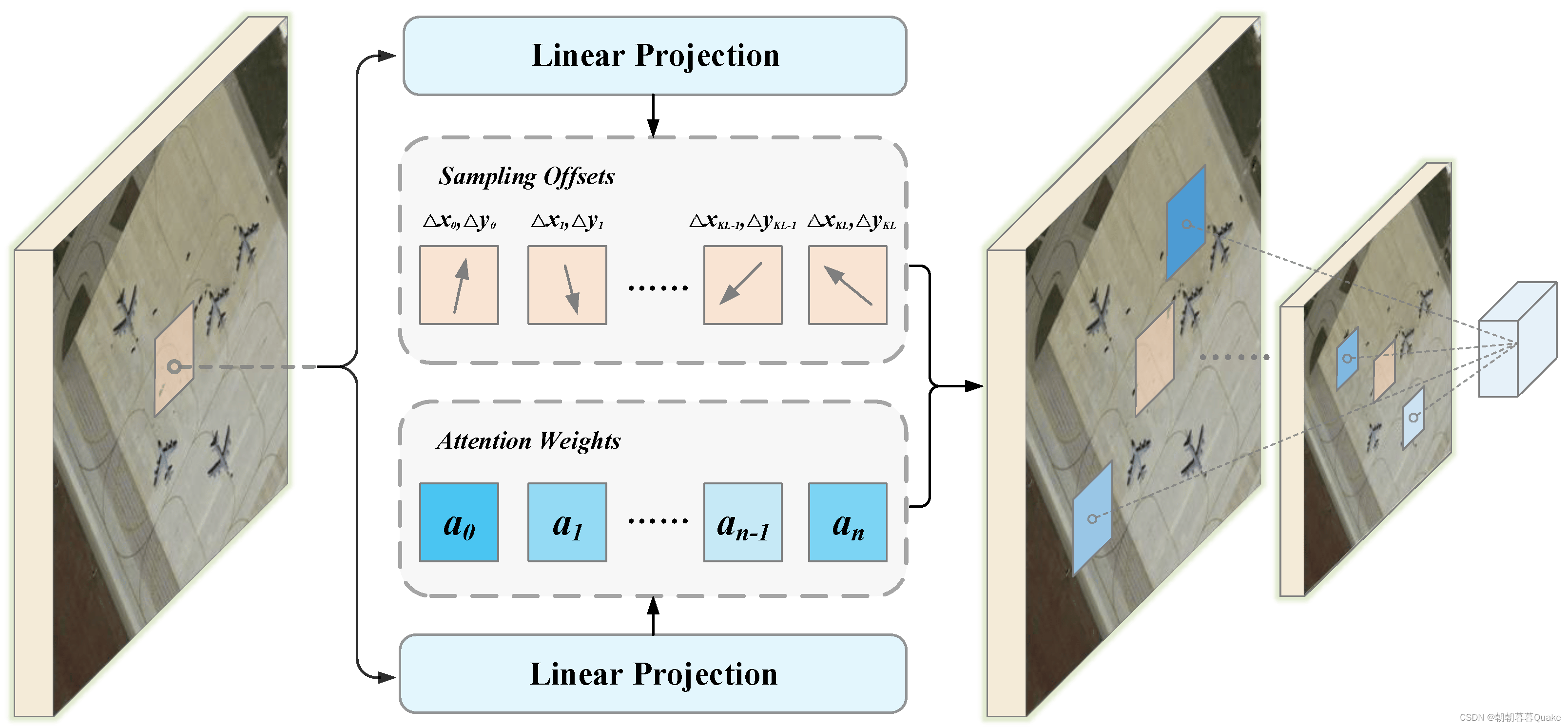
为了增强小物体实例的检测性能,探索了利用多尺度特征图的想法,其中低层次和高分辨率的特征图有利于识别小物体。 然而,高分辨率特征图导致传统的基于 MHSA 的 Transformer 的计算和存储复杂度很高,因为 MHSA 层测量每对参考点的兼容性。 相比之下,可变形注意力模块仅关注参考点周围几个自适应位置处的一组固定数量的基本采样点,这极大地降低了计算和存储复杂度。 因此,Transformer可以有效地扩展到RSI多尺度特征的聚合。
图 3 显示了可变形注意力模块的示意图。 该模块为每个尺度级别中的每个元素生成特定数量的采样偏移和注意力权重。 不同级别地图采样位置的特征被聚合为空间和比例感知元素。


![JavaScript(JS)三种使用方式,三种输出方式,及快速注释。---[用于后续web渗透内容]](http://pic.xiahunao.cn/JavaScript(JS)三种使用方式,三种输出方式,及快速注释。---[用于后续web渗透内容])







——Async Gearbox使用及上板测试)

)





)
