目录
一、决策树
二、朴素贝叶斯
三、人工神经网络
四、利用三种方法进行鸢尾花数据集分类
一、决策树
决策树是一种常用的机器学习算法,用于分类和回归任务。它是一种树形结构,其中每个内部节点表示一个特征或属性,每个分支代表这个特征的一个可能的取值,而每个叶子节点代表一个类别标签或者是一个数值。
决策树的构建过程通常包括以下几个步骤:
特征选择:根据某种准则选择最优的特征,使得每次分裂后的数据集能够尽可能地纯净(即同一类别的样本尽可能地聚集在一起)。
树的构建:根据选定的特征,将数据集分割成较小的子集,并递归地重复这个过程,直到子集中的样本都属于同一类别或达到停止条件。
停止条件:可以是树的深度达到预定值、节点中的样本数量小于某个阈值、或者子集中的样本属于同一类别等。
剪枝:为了防止过拟合,可以通过剪枝技术对生成的决策树进行修剪,去除一些不必要的分支。
决策树的优点包括易于理解和解释,能够处理数值型和类别型数据,对缺失值不敏感,能够处理不相关特征,以及能够在相对较短的时间内对大型数据集做出预测等。然而,决策树也有一些缺点,比如容易产生过拟合,对于某些复杂的关系可能表现不佳,以及对于不平衡的数据集可能不够稳健等。
二、朴素贝叶斯
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理的分类算法,它假设特征之间相互独立。尽管这个假设在现实情况中并不总是成立,但朴素贝叶斯仍然是一个简单而有效的分类算法,在文本分类和垃圾邮件过滤等领域被广泛应用。
这个算法的基本思想可以用贝叶斯定理来描述,即通过计算后验概率来进行分类:
朴素贝叶斯算法通常有三种常见的模型:
多项式朴素贝叶斯:适用于特征是离散值的情况,比如文本分类中的词频统计。
高斯朴素贝叶斯:适用于特征是连续值的情况,假设特征的分布服从高斯分布。
伯努利朴素贝叶斯:适用于特征是二元的情况,比如文本分类中的词是否出现。

朴素贝叶斯算法的优点包括简单、高效、适用于高维数据和大规模数据集,缺点是对特征之间的依赖关系做了较强的假设,可能导致分类性能下降。
三、人工神经网络
人工神经网络(Artificial Neural Network,ANN)是受到生物神经系统启发而设计的一种机器学习模型。它由大量的人工神经元组成,这些神经元之间通过连接进行信息传递和处理。人工神经网络通常用于模式识别、分类、回归等任务。
人工神经网络的基本组成部分包括:
神经元(Neuron):模拟生物神经元的基本单位,每个神经元接收来自其他神经元的输入,并产生一个输出。神经元的输入通过权重加权求和,并经过激活函数进行处理,得到神经元的输出。
连接(Connection):连接神经元之间的通道,用于传递信息。每个连接都有一个权重,用于调节输入信号的影响程度。
层(Layer):神经元按照层次结构排列,一般分为输入层、隐藏层和输出层。输入层接收外部输入,输出层产生最终的输出,而隐藏层在输入层和输出层之间进行信息的传递和转换。
人工神经网络的训练过程通常包括以下几个步骤:
初始化:随机初始化网络中的权重和偏置。
前向传播:从输入层开始,通过连接将输入信号传递到隐藏层和输出层,并经过激活函数处理得到每个神经元的输出。
计算损失:根据模型的输出和真实标签之间的差异,计算损失函数,用于衡量模型的性能。
反向传播:利用反向传播算法,根据损失函数计算每个参数(权重和偏置)对损失的梯度,然后根据梯度更新参数。
迭代优化:重复执行前向传播和反向传播过程,直到损失函数收敛或达到预定的迭代次数。
常见的人工神经网络结构包括多层感知机(Multilayer Perceptron,MLP)、卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)等。每种结构都有其特定的应用场景和优缺点,可以根据任务的需求选择合适的结构。
四、利用三种方法进行鸢尾花数据集分类
from sklearn.datasets import load_iris # 导入方法类iris = load_iris() #导入数据集iris
iris_feature = iris.data #特征数据
iris_target = iris.target #分类数据
print (iris.data) #输出数据集
print (iris.target) #输出真实标签
print (len(iris.target) )
print (iris.data.shape ) #150个样本 每个样本4个特征from sklearn.tree import DecisionTreeClassifier #导入决策树DTC包from sklearn.datasets import load_iris # 导入方法类iris = load_iris() #导入数据集iris
iris_feature = iris.data #特征数据
iris_target = iris.target #分类数据clf1 = DecisionTreeClassifier() # 所以参数均置为默认状态
clf1.fit(iris.data, iris.target) # 使用训练集训练模型
#print(clf)
predicted = clf1.predict(iris.data)
#print(predicted)
# print("使用决策树算法:")
# print("精度是:{:.3f}".format(clf.score(iris.data, iris.target)))
# viz code 可视化 制作一个简单易读的PDF
iris = load_iris() #导入数据集iris
iris_feature = iris.data #特征数据
iris_target = iris.target #分类数据clf = DecisionTreeClassifier() # 所以参数均置为默认状态
clf.fit(iris.data, iris.target) # 使用训练集训练模型
#print(clf)
predicted = clf.predict(iris.data)
#print(predicted)# 获取花卉两列数据集
X = iris.data
L1 = [x[0] for x in X]
#print(L1)
L2 = [x[1] for x in X]#输出放在最后方便对比#使用朴素贝叶斯算法对鸢尾花数据集分类
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB, GaussianNB
import matplotlib.pyplot as plt
import numpy as np
import matplotlib as mpl
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipelineiris = datasets.load_iris() # 加载鸢尾花数据
iris_x = iris.data # 获取数据
# print(iris_x)
iris_x = iris_x[:, :2] # 取前两个特征值
# print(iris_x)
iris_y = iris.target # 0, 1, 2
x_train, x_test, y_train, y_test = train_test_split(iris_x, iris_y, test_size=0.75, random_state=1) # 对数据进行分类 一部分最为训练一部分作为测试
# clf = GaussianNB()
# ir = clf.fit(x_train, y_train)
clf = Pipeline([('sc', StandardScaler()),('clf', GaussianNB())]) # 管道这个没深入理解 所以不知所以然
ir = clf.fit(x_train, y_train.ravel()) # 利用训练数据进行拟合# 画图:y_hat1 = ir.predict(x_test)
result = y_hat1 == y_test
print(result)
acc1 = np.mean(result)
# print("使用决策树算法:")
# print('准确度: %.2f%%' % (100 * acc))#人工神经网络算法对鸢尾花分类
import tensorflow as tf
from sklearn import datasets
from matplotlib import pyplot as plt
import numpy as np# 导入数据,分别为输入特征和标签
x_data = datasets.load_iris().data
y_data = datasets.load_iris().target# 随机打乱数据(因为原始数据是顺序的,顺序不打乱会影响准确率)
# seed: 随机数种子,是一个整数,当设置之后,每次生成的随机数都一样(为方便教学,以保每位同学结果一致)
np.random.seed(116) # 使用相同的seed,保证输入特征和标签一一对应
np.random.shuffle(x_data)
np.random.seed(116)
np.random.shuffle(y_data)
tf.random.set_seed(116)# 将打乱后的数据集分割为训练集和测试集,训练集为前120行,测试集为后30行
x_train = x_data[:-30]
y_train = y_data[:-30]
x_test = x_data[-30:]
y_test = y_data[-30:]# 转换x的数据类型,否则后面矩阵相乘时会因数据类型不一致报错
x_train = tf.cast(x_train, tf.float32)
x_test = tf.cast(x_test, tf.float32)# from_tensor_slices函数使输入特征和标签值一一对应。(把数据集分批次,每个批次batch组数据)
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)# 生成神经网络的参数,4个输入特征故,输入层为4个输入节点;因为3分类,故输出层为3个神经元
# 用tf.Variable()标记参数可训练
# 使用seed使每次生成的随机数相同(方便教学,使大家结果都一致,在现实使用时不写seed)
w1 = tf.Variable(tf.random.truncated_normal([4, 3], stddev=0.1, seed=1))
b1 = tf.Variable(tf.random.truncated_normal([3], stddev=0.1, seed=1))lr = 0.1 # 学习率为0.1
train_loss_results = [] # 将每轮的loss记录在此列表中,为后续画loss曲线提供数据
test_acc = [] # 将每轮的acc记录在此列表中,为后续画acc曲线提供数据
epoch = 200 # 循环500轮
loss_all = 0 # 每轮分4个step,loss_all记录四个step生成的4个loss的和# 训练部分
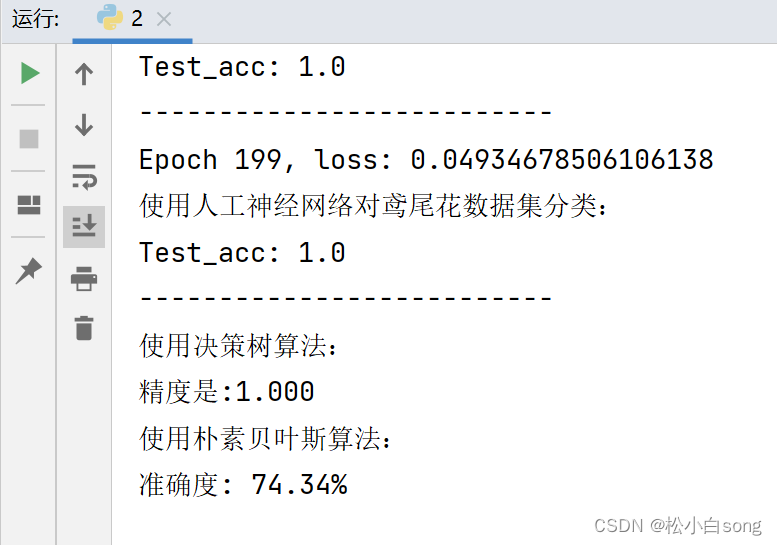
for epoch in range(epoch): #数据集级别的循环,每个epoch循环一次数据集for step, (x_train, y_train) in enumerate(train_db): #batch级别的循环 ,每个step循环一个batchwith tf.GradientTape() as tape: # with结构记录梯度信息y = tf.matmul(x_train, w1) + b1 # 神经网络乘加运算y = tf.nn.softmax(y) # 使输出y符合概率分布(此操作后与独热码同量级,可相减求loss)y_ = tf.one_hot(y_train, depth=3) # 将标签值转换为独热码格式,方便计算loss和accuracyloss = tf.reduce_mean(tf.square(y_ - y)) # 采用均方误差损失函数mse = mean(sum(y-out)^2)loss_all += loss.numpy() # 将每个step计算出的loss累加,为后续求loss平均值提供数据,这样计算的loss更准确# 计算loss对各个参数的梯度grads = tape.gradient(loss, [w1, b1])# 实现梯度更新 w1 = w1 - lr * w1_grad b = b - lr * b_gradw1.assign_sub(lr * grads[0]) # 参数w1自更新b1.assign_sub(lr * grads[1]) # 参数b自更新# 每个epoch,打印loss信息print("Epoch {}, loss: {}".format(epoch, loss_all/4))train_loss_results.append(loss_all / 4) # 将4个step的loss求平均记录在此变量中loss_all = 0 # loss_all归零,为记录下一个epoch的loss做准备# 测试部分# total_correct为预测对的样本个数, total_number为测试的总样本数,将这两个变量都初始化为0total_correct, total_number = 0, 0for x_test, y_test in test_db:# 使用更新后的参数进行预测y = tf.matmul(x_test, w1) + b1y = tf.nn.softmax(y)pred = tf.argmax(y, axis=1) # 返回y中最大值的索引,即预测的分类# 将pred转换为y_test的数据类型pred = tf.cast(pred, dtype=y_test.dtype)# 若分类正确,则correct=1,否则为0,将bool型的结果转换为int型correct = tf.cast(tf.equal(pred, y_test), dtype=tf.int32)# 将每个batch的correct数加起来correct = tf.reduce_sum(correct)# 将所有batch中的correct数加起来total_correct += int(correct)# total_number为测试的总样本数,也就是x_test的行数,shape[0]返回变量的行数total_number += x_test.shape[0]# 总的准确率等于total_correct/total_numberacc = total_correct / total_numbertest_acc.append(acc)print("使用人工神经网络对鸢尾花数据集分类:")print("Test_acc:", acc)print("--------------------------")print("使用决策树算法:")
print("精度是:{:.3f}".format(clf1.score(iris.data, iris.target)))print("使用朴素贝叶斯算法:")
print('准确度: %.2f%%' % (100 * acc1))# 绘制 loss 曲线plt.subplot(221)
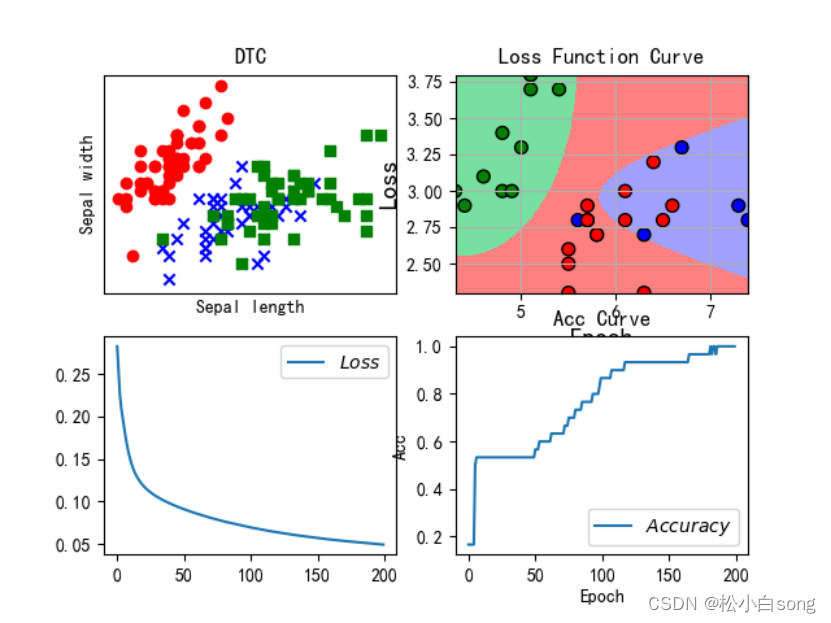
plt.scatter(X[:50, 0], X[:50, 1], color='red', marker='o', label='setosa')
plt.scatter(X[50:100, 0], X[50:100, 1], color='blue', marker='x', label='versicolor')
plt.scatter(X[100:, 0], X[100:, 1], color='green', marker='s', label='Virginica')plt.title("DTC")
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xticks(())
plt.yticks(())x1_max, x1_min = max(x_test[:, 0]), min(x_test[:, 0]) # 取0列特征得最大最小值
x2_max, x2_min = max(x_test[:, 1]), min(x_test[:, 1]) # 取1列特征得最大最小值
t1 = np.linspace(x1_min, x1_max, 500) # 生成500个测试点
t2 = np.linspace(x2_min, x2_max, 500)
x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
x_test1 = np.stack((x1.flat, x2.flat), axis=1)
y_hat = ir.predict(x_test1) # 预测
mpl.rcParams['font.sans-serif'] = [u'simHei'] # 识别中文保证不乱吗
mpl.rcParams['axes.unicode_minus'] = False
cm_light = mpl.colors.ListedColormap(['#77E0A0', '#FF8080', '#A0A0FF']) # 测试分类的颜色
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b']) # 样本点的颜色plt.subplot(222)
plt.pcolormesh(x1, x2, y_hat.reshape(x1.shape), cmap=cm_light) # y_hat 25000个样本点的画图,
plt.scatter(x_test[:, 0], x_test[:, 1], edgecolors='k', s=50, c=y_test, cmap=cm_dark) # 测试数据的真实的样本点(散点) 参数自行百度plt.xlabel(u'花萼长度', fontsize=14)
plt.ylabel(u'花萼宽度', fontsize=14)
plt.title(u'GaussianNB对鸢尾花数据的分类结果', fontsize=18)
plt.grid(True)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)#
#plt.title('Loss Function Curve') # 图片标题
plt.xlabel('Epoch') # x轴变量名称
plt.ylabel('Loss') # y轴变量名称
plt.subplot(223)
plt.plot(train_loss_results, label="$Loss$") # 逐点画出trian_loss_results值并连线,连线图标是Loss
plt.legend() # 画出曲线图标 # 画出图像# 绘制 Accuracy 曲线
plt.subplot(224)
plt.title('Acc Curve') # 图片标题
plt.xlabel('Epoch') # x轴变量名称
plt.ylabel('Acc') # y轴变量名称
# plt.subplot(224)
plt.plot(test_acc, label="$Accuracy$") # 逐点画出test_acc值并连线,连线图标是Accuracy
plt.legend()
plt.show()结果:














详解)




