目录
一.项目背景
二. 搜索引擎的宏观原理
三.使用到的技术栈与项目环境
四.正排索引vs倒排索引
五.认识标签与去标签
六.建立索引模块
七,编写http服务端
八,编写前端页面
九.搜索结果的优化
遇到的问题:
项目源码:boost搜索引擎 · 但成伟/编程学习 - 码云 - 开源中国 (gitee.com)
一.项目背景
当前已经有许多上市公司做了搜索引擎,比如说百度,搜狗,360等等,这些项目都是很大的项目,有很高的技术门槛,我们自己实现一个完整的搜索引擎是不可能的,但是我们可以写一个简单的搜索引擎---站内搜索引擎,例如我们学习c++常用的cplusplus网站,里面就是关于c++语法和库的内容供用户使用。这就会使得搜索的数据的内容更加少,更加垂直。
搜索出来的展现结果我们即就以搜狗这样子的为基本:

本次项目我们不仅要使用boost库,其次还是针对boost网页,无站内搜索进行的站内搜索的补充的项目。(之前boost管网页是没有搜索的,但现在作者添加了搜索框)
二. 搜索引擎的宏观原理
如图,绿色框就是我们主体完成的任务,由于爬虫国家做了法律限制,我们这里就将资源全部下载下来,进行我们的资源获取。

首先通过客户端的请求,获取关键字,在服务端中进行网页的构建,然后对资源进行去标签,建立缩影,与关键字对比,获取信息并构建网页,返回给客户端。
三.使用到的技术栈与项目环境
主要使用的技术栈:
c/c++ c++11 STL,标准库Boost,第三方库json.cpp,cppjieba,cpphttp。
次要使用技术栈:
html15,css,js,jquery,Ajax.
项目环境:centos7云服务器,vim/g++/gcc/Makefile ,vs2019.
四.正排索引vs倒排索引
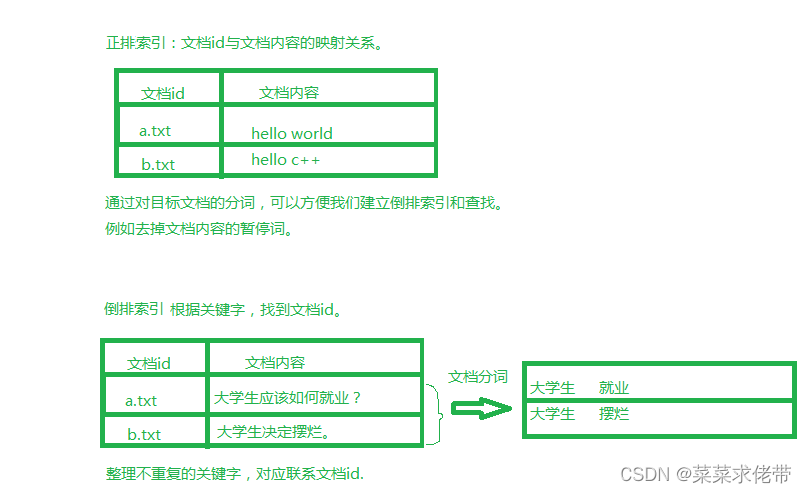
而我们在进行用户的搜索时,就可以用倒排索引去分词,再找到对应文档的id根据权重顺序展示,再根据正排索引直接找到对应的文档内容,即网页内容title+desc+url构建响应结果。
五.认识标签与去标签
第一步去Boost官网下载官网文档,这文档里面就包括了所有的内容。
文档的内容非常多,这里我们就只用目录下的doc/html中的内容做索引,所以第一步就是去掉html中的标签,获取有效内容,标签一般都是成对存在的,但也有单独的,之后吧一个文档去掉后的内容放到同一个文件,文档之间(用\3进行区分,不可显)。
编写parser.cc
在编写之前,为了方便我们去标签,我们可以直接安装boost-devel库,使用该哭中的方法进行解析。
sudo yum install -y boost-devel读取html文件的内容,并且提取其中的title标签。
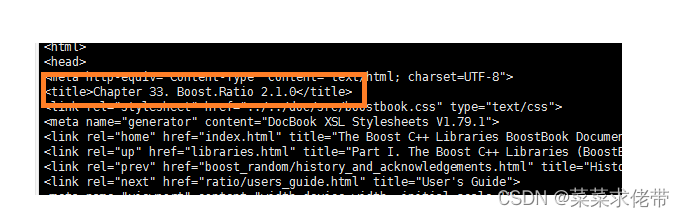
除此之外,还去提取出标签外的content

通过遍历每一个字符是否在<>内,判断它的状态是否是Lable,或者Content,最终获取内容。
解析URL,我们可以上官网看到他的url的构成,如果打开某一个文档:
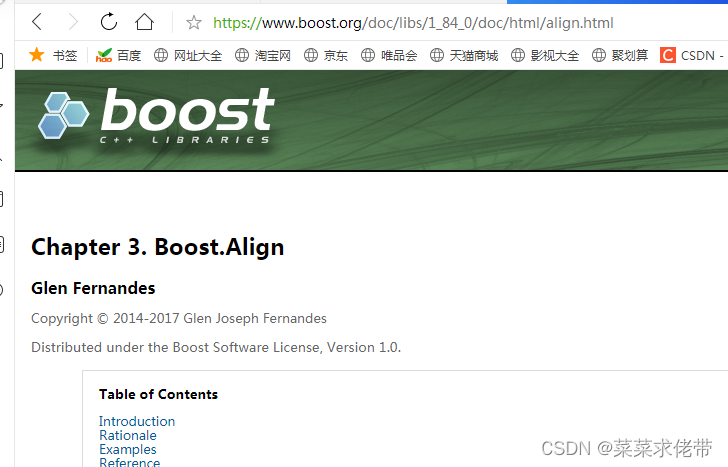
比如查看boost库中的一个align的一个用法,可以看到此时url的构成,基本是固定格式(可以根据我们下载来的html路径进行解析),同时我们还可以获取html中的网页的一点内容,比如头标题,再整合url:
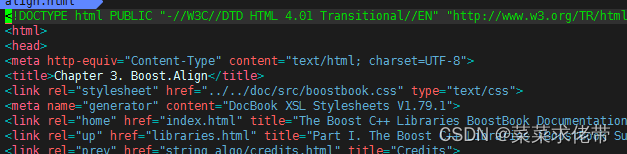

最终解析完成,将整理的DocInfo中的title,content,url保存至指定目录,格式为title/3content/3url/ntitle/3content/3/url/n..........。
六.建立索引模块
完成了解析文档的任务,接下来就是将解析文档后的内容与文件建立索引以便更好的查找。
即文档id与文件的正排映射,文档内容中的关键字与文档的倒排映射。
正排映射我们直接用一个数组让下标与文档与之对应。
有了正排映射,我们还需要倒排映射,因为搜索的过程是先根据用户的输入分词,进入倒排索引查找文档id,之后再根据文档id正派索引找到文档。
在进行倒排映射时,我们就需要对内容进行分词,并且统计词的频率,然后根据词的频率确定文档的优先级(那个文档被优先展示)。这里我们需要使用一个库-cppjieba,进行分词。
同时构建jieba对象,将所有暂停词的路径导入,边下去掉暂停词的方法。
同时为了更方便的找到词库,我们建立对应路径的符号链接,之后修改demo.cpp上的头文件即路径即可,根据demo.cpp,我们来实现我们的分词(注意将desps下的limpne拷到include/jieba)。
完成主要的搜索引擎方法的模块,我们就可以建立搜索引擎了。
通过文件名获取信息,同时初始化(创建)正排索引,与倒排索引,之后再根据用户的输入信息的分词,去倒排索引里面查找id,再根据id正排查找相关的文档。
返回对应文档之后读取其中信息,我们构建为json串,并且对content的内容要进行切割,本身我们只需要一部分即可。
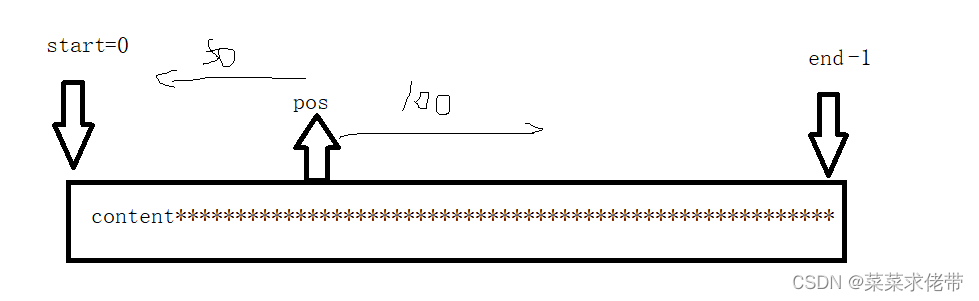
七,编写http服务端
使用第三方库cpphttp进行httpsever的服务端的编写。
注意事项:cpphttp库的编译需要使用较新版本的gcc,而我们使用的云服务器的centos默认是4.8.5,版本较低,直接使用会保报错。使用scl安装较新版本的gcc,在此之前先安装scl。
sudo yum install cento-release-scl scl-utils-build之后升级gcc
sudo yum install -y devtoolset-7-gcc devtoolset-7-gcc-c++失败使用指令重新安装
yum install -y centos-release-scl centos-release-scl-rh
启动
scl enable devtoolset-7 bash
gcc -v该指令我们可以添加到每次启动的脚本里:~/.bash_profile
安装cpphttplib
由于直接安装最新版本的cpphttplib,如果你不是最新的gcc,运行可能会保存,我们这里使用对应的0.7.15cpphttplib。
https://github.com/yhirose/cpp-httplib/tags?after=v0.8.5之后就可以编写客户端,并且设置外部根目录(如主页)wwwroot,但是此时什么都与没有,我们还需要在里面写我们的网页:index.html,并且添加到wwwroot中。
直接访问,不添加get请求时,是访问我们的root网页(index)外部网页,获取到get请求后,此时才会响应我们的服务端中的返回的内容。
在根据关键字解析内容时再根据content_type对照表找到json格式对应的格式。
httpserver.cc
#include"http.h"
#include"sercher.hpp"
const std::string root_path="./wwwroot";
const std::string input="../Data/updata_html/raw.txt";
int main()
{//初始化搜索namesapce_sercher::sercher serch;serch.InitSercher(input);httplib::Server svr;//设置服务svr.set_base_dir(root_path.c_str());//参数一为 参数二为lanmda,函数体为设置响应//get去请求并做响应 /s发送请求svr.Get("/s",[&serch](const httplib::Request &req,httplib::Response &rep){if(!req.has_param("word")){//请求必须带参数word//请求是否有内容,通过word获取搜索关键字 rep.set_content("搜索需要提供关键字","text/plain: charset=utf-8");return;}//提取搜索关键字std::string word=req.get_param_value("word");std::cout<<"用户正在搜索"<<word<<std::endl;std::string json_string;serch.Sercher(word,&json_string);//拿到解析完,返回给响应rep.set_content(json_string,"application/json");//根据content对照表转化json格式的字符串});//启动服务svr.listen("0.0.0.0",8081);return 0;
}
八,编写前端页面
当服务器构建完成,且根据请求发送对应的解析后的数据,就只剩最后一个模块了,编写前端页面。
使用vscode编写,!table生成骨架。网页由标签构成,标签分为单标签与双标签。
对于前端,html就像网页的骨架,css就相当于网页皮肉(美化),js就相当于灵魂(网页的动态效果),和前后端交互。
这里我们就先一个简单的html展示搜索引擎:
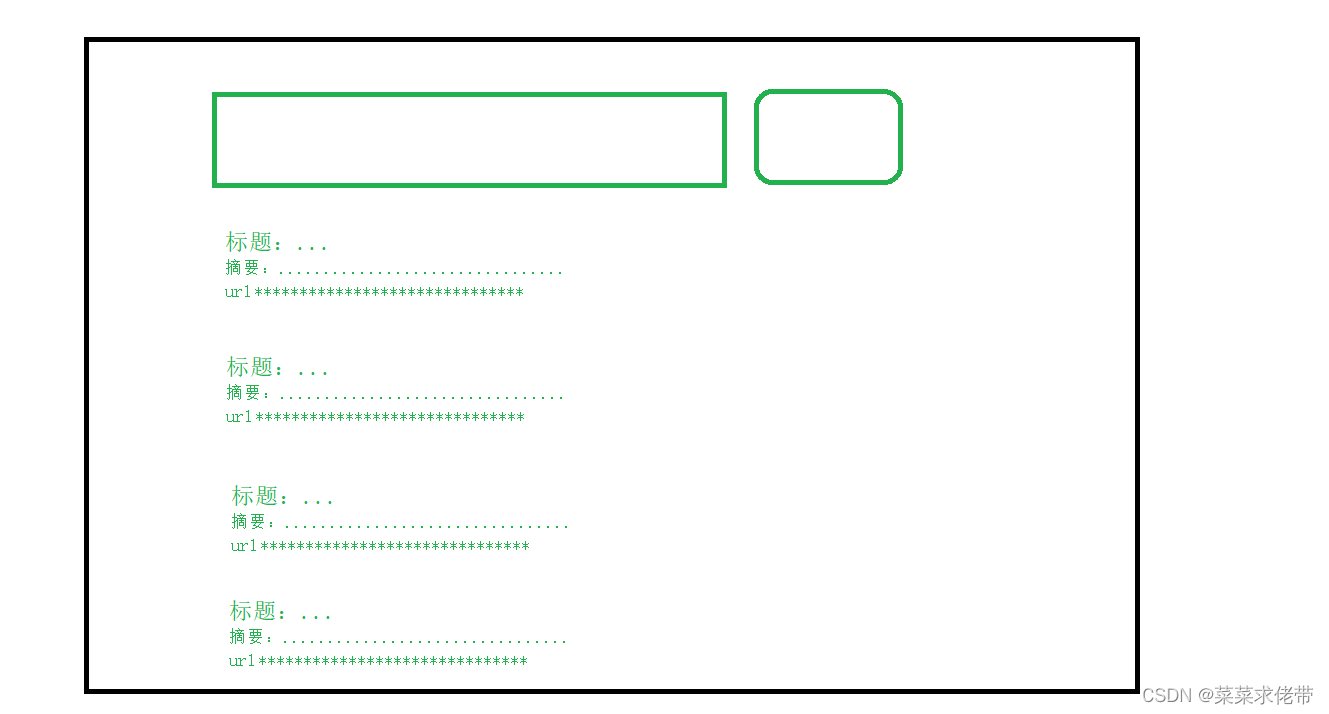
首先创建骨架,之后根据我们的的设计进行body的编写。
1.首先设定标签container标识在该区域内进行界面的设计,之后就是再contain之中再加入div-搜索标签,里面放入input输入框,设置默认显示内容value,button按钮,写入内容。
2.创建标签result,带面里面是我们要放的搜索内容,接下来创建标签item代表每一个搜索的结果,里面主要由三部分组成,标签a代表标题,标签p代表摘要,标签i代表url。之后再多创建几个该Item.这样我们的基本骨架就好了。
之后稍微使用css美化一下,这里就直接内联式的写入其中,这要也就是设置我们的标签的属性达到美化:
1.选择特定的标签。
2.设置标签属性。
首先对title进行美化创建style,*{ }清除内外边距,让title居中显示,.contaner,选择类标签为container的,之后就是诸葛选择标签,修改颜色,字体,大小,边界等。
编写完毕后,最后就需要编写js使得我们的页面能与后端连接起来:
编写js实现前后端交互(时间处理函数):
直接使用原生js,成本比较高,我们这里使用Jquery,直接定义在线使用jquery的链接。
之后对于按钮定义对应的处理事件,然后按照模板重新动态生成搜索结果。
九.搜索结果的优化
首先就是去掉重复文档。
之前搜索时,根据搜索的一句话,拆分成多个关键字,然后遍历每个关键字,去倒排索引表里找,
并返回找到的有关的文档信息链表,不为空,就将该文档信息插入到结果链表中,但是这样存在一个问题,那就是多个关键字都是一句话的,对应的也都是同一个文档的信息,因此在查找时,就出出现重复的文档。
因此这里还需要再查找时,再建立一个哈希表用文档id映射文档信息,这样从倒排链表里查到的文档链表,先进行过滤,将哈希表id 映射新的文档信息,这个新的文档信息就是相同文档信息(文档id不变,关键字为关键字数组,权重为权重之和)的结合。
之后排序时以及构建json串时,使用我们哈希表存储的文档信息。
遇到的问题:
问题:搜索时拆分的字符时大写,就算全转为小写,但是文档如果是大写呢?存在查找的时候出现npos,解决办法:在查找时江都区道德内容临时做大小写调整使用seech进行查找。
疑惑:分词出现问题,次数不匹配,有的关键词并未完全分离,所以出现测次数不匹配。
遇到的问题:内存分配异常,可能是内存不足,或者参数错误.,建立索引的过程较慢。
字符串截取问题
解决的问题:提供的测试用例有问题,静态变量未全局初始化,临时变量都使用move转化为右值引用。
在完成前端的编写时,再次访问页面,访问不了,且服务器直接挂了。原因:编写html出现错误。