diffusion model
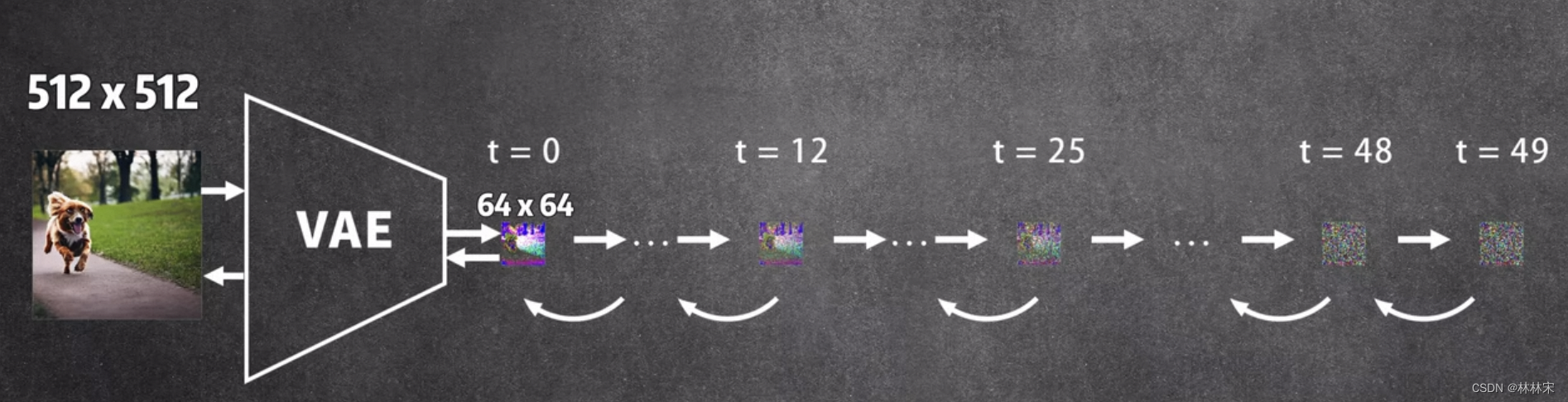
- latent diffusion :先对图片降维,然后在降维空间做diffusion;stable diffusion即基于此方法实现的,因此计算量很小;
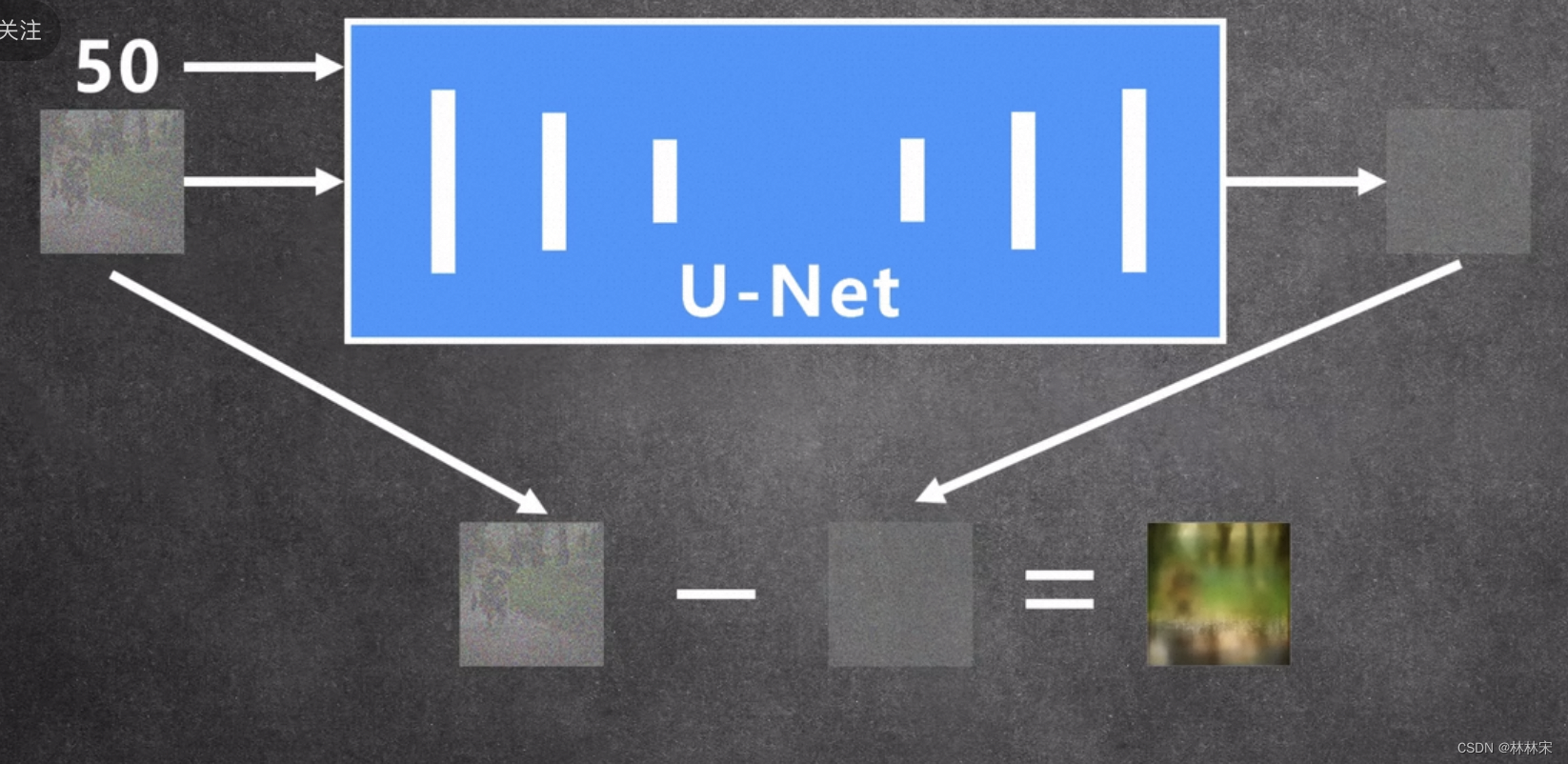
- 共用降噪网络U-Net:输入noisy image+step,告诉网络当前的噪声等级;预测出来噪声,noisy image-noise,得到降噪之后的图片;然后继续送进网络,再做一次这样的推理;
stable diffusion整体
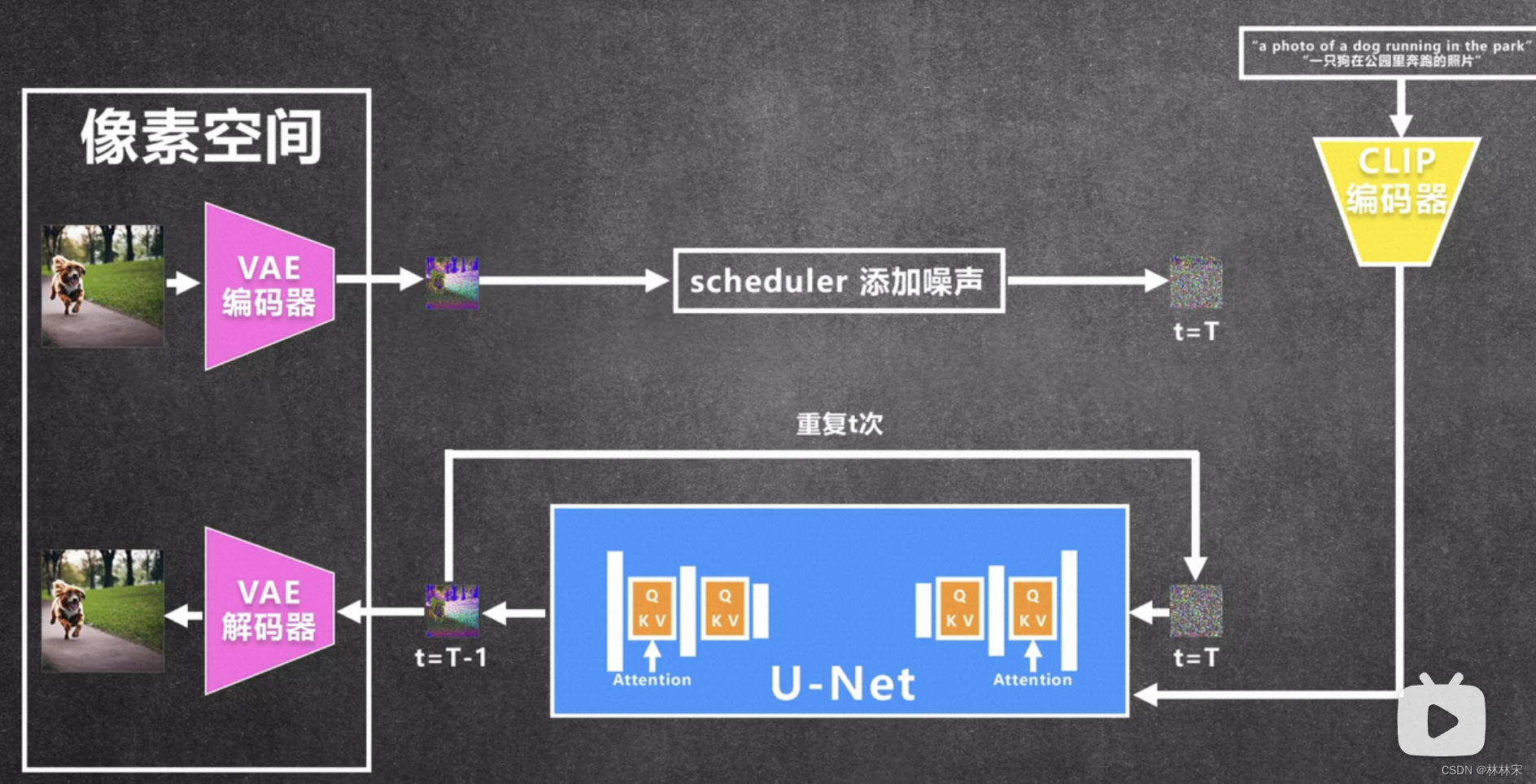
stable diffusion拆解

-
stable diffusion的推理流程:CLIP模型对文本进行编码,得到文本-图片共享域的embedding;然后送给lattent diffusion,最后输出经过解码器重建为高清图片。
-
diffusion 正向流程是图片加白噪声,具体加的方法看schedule的设置,比如每次加一定量;或者先加的少,后加的多—图片特征损失的比较慢;高斯噪声可以累加,因此在设置step=100的时候,实际上每一步的结果都可以直接推出来了;


-
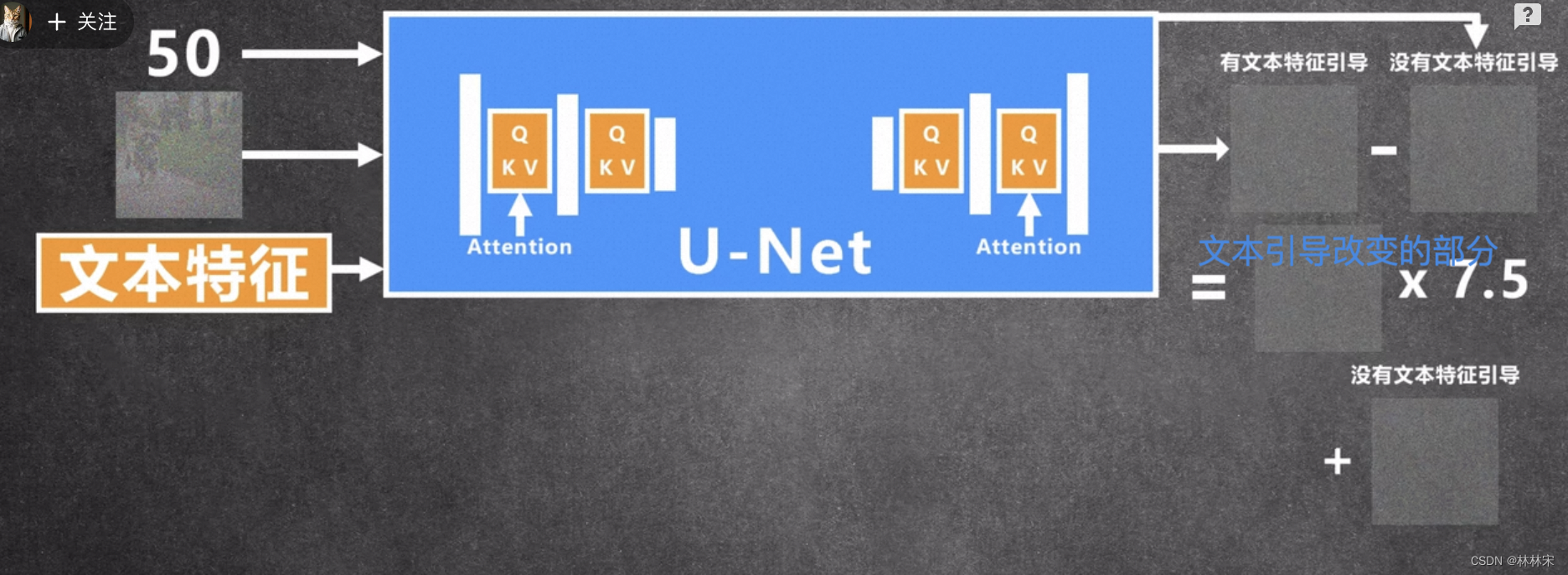
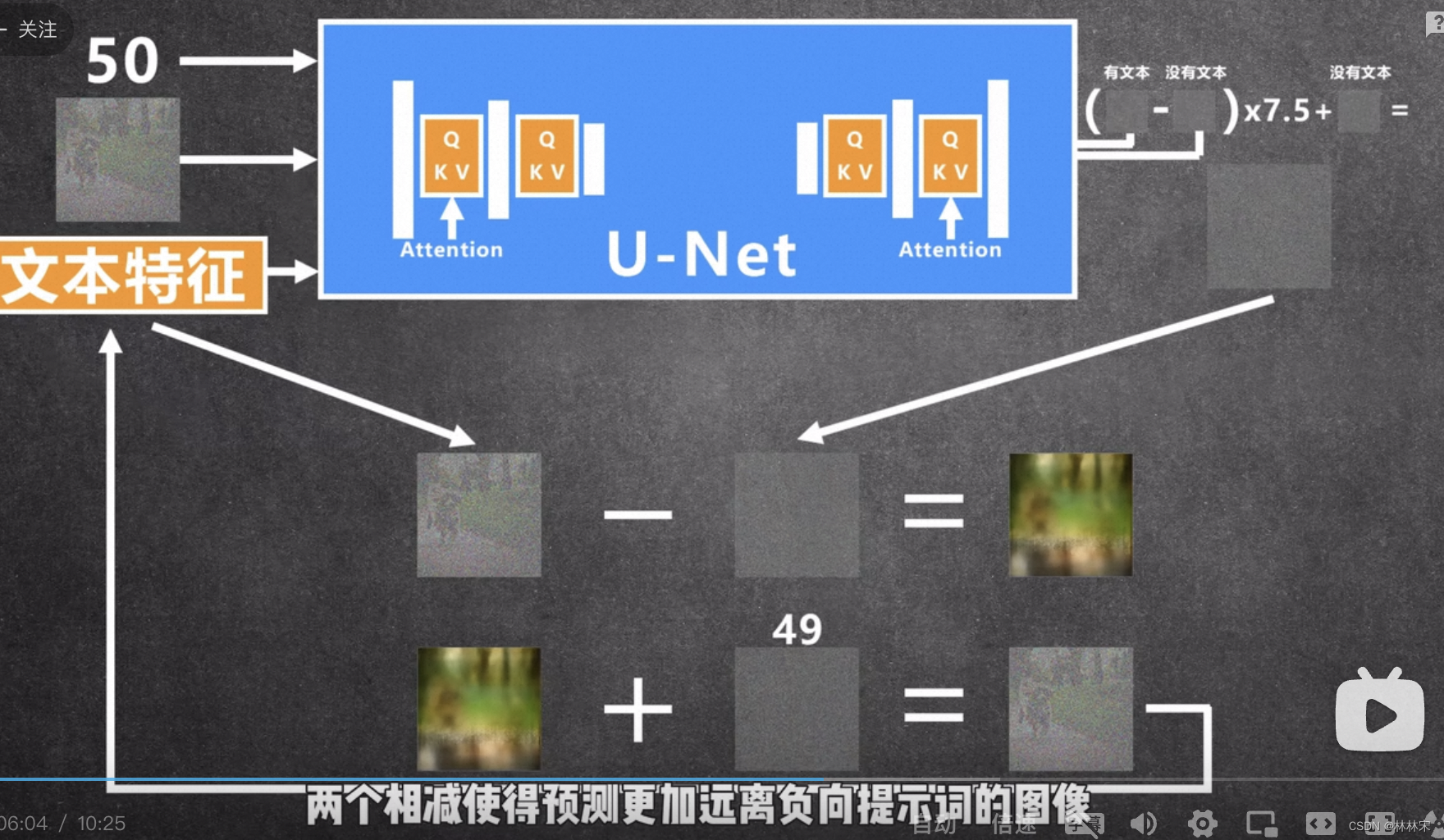
stable diffusion的输入【step, noisy image,文本特征】,为了加强文本对生成内容的控制,引入classifier free guidance进行控制;有文本控制和没有文本控制的情况下,生成两种噪声,互减之后的部分既是文本引导改变的噪声部分,乘一定的系数对文本引导改变的结果进行加强,再加上没有文本引导部分的噪声,合并成本轮预测的噪声。
-
进阶玩法:webUI上有正向提示词,和负向提示词;可以通过classifier free guidance进行加强or减弱的控制;
-
VAE和CLIP模型都是预先训练好的;stable diffusion 2用的是LAION数据集训练的CLIP模型;官网有模型公开,但有的模型没有训练使用的数据集公开;



















