文章目录
- 一、Ranger概述与安装
- 1、Ranger概述
- 1.1 Ranger介绍
- 1.2 Ranger的目标
- 1.3 Ranger支持的框架
- 1.4 Ranger的架构
- 1.5 Ranger的工作原理
- 2、Ranger安装
- 2.1 创建系统用户和Kerberos主体
- 2.2 数据库环境准备
- 2.3 安装RangerAdmin
- 2.4 启动RangerAdmin
- 二、Ranger简单使用
- 1、安装 RangerUsersync
- 1.1 RangerUsersync简介
- 1.2 RangerUsersync安装
- 1.3 RangerUsersync启动
- 2、安装Ranger Hive-plugin
- 2.1 Ranger Hive-plugin简介
- 2.2 Ranger Hive-plugin安装
- 2.3 在ranger admin上配置hive插件
- 3、使用Ranger对Hive进行权限管理
- 3.1 权限控制初体验
- 3.2 Ranger授权模型
一、Ranger概述与安装
1、Ranger概述
1.1 Ranger介绍
Ranger的官网:https://ranger.apache.org/
Apache Ranger是一个Hadoop平台上的全方位数据安全管理框架,它可以为整个Hadoop生态系统提供全面的安全管理。
随着企业业务的拓展,企业可能在多用户环境中运行多个工作任务,这就需要一个可以对安全策略进行集中管理,配置和监控用户访问的框架。Ranger由此产生
1.2 Ranger的目标
- 允许用户使用UI或REST API对所有和安全相关的任务进行集中化的管理
- 允许用户使用一个管理工具对操作Hadoop体系中的组件和工具的行为进行细粒度的授权
- 支持Hadoop体系中各个组件的授权认证标准
- 增强了对不同业务场景需求的授权方法支持,例如基于角色的授权或基于属性的授权
- 支持对Hadoop组件所有涉及安全的审计行为的集中化管理
1.3 Ranger支持的框架
- Apache Hadoop
- Apache Hive
- Apache HBase
- Apache Storm
- Apache Knox
- Apache Solr
- Apache Kafka
- YARN
- NIFI
1.4 Ranger的架构

1.5 Ranger的工作原理
Ranager的核心是Web应用程序,也称为RangerAdmin模块,此模块由管理策略,审计日志和报告等三部分组成。
管理员角色的用户可以通过RangerAdmin提供的web界面或REST APIS来定制安全策略。这些策略会由Ranger提供的轻量级的针对不同Hadoop体系中组件的插件来执行。插件会在Hadoop的不同组件的核心进程启动后,启动对应的插件进程来进行安全管理
2、Ranger安装
Ranger2.0要求对应的Hadoop为3.x以上,Hive为3.x以上版本,JDK为1.8以上版本。Hadoop及Hive等需开启用户认证功能,本文基于开启Kerberos安全认证的Hadoop和Hive环境。注:本文中所涉及的Ranger相关组件均安装在hadoop102节点
2.1 创建系统用户和Kerberos主体
Ranger的启动和运行需使用特定的用户,故须在Ranger所在节点创建所需系统用户并在Kerberos中创建所需主体
# 创建ranger系统用户
useradd ranger -G hadoop
echo ranger | passwd --stdin ranger# 检查HTTP主体是否正常(该主体在Hadoop开启Kerberos时已创建)
# 使用keytab文件认证HTTP主体
kinit -kt /etc/security/keytab/spnego.service.keytab HTTP/hadoop102@EXAMPLE.COM
# 查看认证状态
klist
kdestroy # 创建rangeradmin主体
kadmin -padmin/admin -wadmin -q"addprinc -randkey rangeradmin/hadoop102"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/rangeradmin.keytab rangeradmin/hadoop102"
chown ranger:ranger /etc/security/keytab/rangeradmin.keytab
# 创建rangerlookup主体
kadmin -padmin/admin -wadmin -q"addprinc -randkey rangerlookup/hadoop102"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/rangerlookup.keytab rangerlookup/hadoop102"
chown ranger:ranger /etc/security/keytab/rangerlookup.keytab
# 创建rangerusersync主体
kadmin -padmin/admin -wadmin -q"addprinc -randkey rangerusersync/hadoop102"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/rangerusersync.keytab rangerusersync/hadoop102"
chown ranger:ranger /etc/security/keytab/rangerusersync.keytab2.2 数据库环境准备
mysql -uroot -p123456
# 在MySQL数据库中创建Ranger存储数据的数据库
create database ranger;
# 更改mysql密码策略,为了可以采用比较简单的密码
set global validate_password_length=4;
set global validate_password_policy=0;
# 创建用户
grant all privileges on ranger.* to ranger@'%' identified by 'ranger';2.3 安装RangerAdmin
# 官网:https://ranger.apache.org/
# 在hadoop102的/opt/module路径上创建一个ranger
# https://www.apache.org/dyn/closer.lua/ranger/2.0.0/apache-ranger-2.0.0.tar.gz
# 使用Maven命令编译,注意需要python,maven,git,java环境
# 具体编译可以参考:https://blog.csdn.net/weixin_38586230/article/details/105725346
mvn -DskipTests=true clean package
# 资源获取:https://download.csdn.net/download/lemon_TT/87961006
mkdir /opt/module/ranger
tar -zxvf ranger-2.0.0-admin.tar.gz -C /opt/module/ranger
# 进入/opt/module/ranger/ranger-2.0.0-admin路径,对install.properties配置
vim install.properties
# ===================================================
# 修改以下配置内容:
#mysql驱动
SQL_CONNECTOR_JAR=/opt/software/mysql-connector-java-5.1.37.jar#mysql的主机名和root用户的用户名密码
db_root_user=root
db_root_password=123456
db_host=hadoop102#ranger需要的数据库名和用户信息,和2.2.1创建的信息要一一对应
db_name=ranger
db_user=ranger
db_password=ranger#Ranger各组件的admin用户密码
rangerAdmin_password=atguigu123
rangerTagsync_password=atguigu123
rangerUsersync_password=atguigu123
keyadmin_password=atguigu123#ranger存储审计日志的路径,默认为solr,这里为了方便暂不设置
audit_store=#策略管理器的url,rangeradmin安装在哪台机器,主机名就为对应的主机名
policymgr_external_url=http://hadoop102:6080#启动ranger admin进程的linux用户信息
unix_user=ranger
unix_user_pwd=ranger
unix_group=ranger#Kerberos相关配置
spnego_principal=HTTP/hadoop102@EXAMPLE.COM
spnego_keytab=/etc/security/keytab/spnego.service.keytab
admin_principal=rangeradmin/hadoop102@EXAMPLE.COM
admin_keytab=/etc/security/keytab/rangeradmin.keytab
lookup_principal=rangerlookup/hadoop102@EXAMPLE.COM
lookup_keytab=/etc/security/keytab/rangerlookup.keytab
hadoop_conf=/opt/module/hadoop-3.1.3/etc/hadoop# ===================================================# 在/opt/module/ranger/ranger-2.0.0-admin目录下执行安装脚本
./setup.sh
# 若安装过程中发现Error executing: CREATE FUNCTION `getXportalUIdByLoginId`(input_val VARCHAR(100)) RETURNS int(11) BEGIN DECLARE myid INT; SELECT x_portal_user.id into myid FROM x_portal_user WHERE x_portal_user.login_id = input_val; RETURN myid; END
# 导入失败,log_bin_trust_function_creators 为 OFF
# 进入mysql进行设置
show variables like '%func%';
set global log_bin_trust_function_creators=1;
drop database ranger;
create database ranger;
# 最后重新安装# 修改/opt/module/ranger/ranger-2.0.0-admin/conf/ranger-admin-site.xml配置文件中的以下属性
vim /opt/module/ranger/ranger-2.0.0-admin/conf/ranger-admin-site.xml修改如下参数
<property><name>ranger.jpa.jdbc.password</name><value>ranger</value><description />
</property><property><name>ranger.service.host</name><value>hadoop102</value>
</property>
2.4 启动RangerAdmin
# 启动ranger-admin(以ranger用户启动)
sudo -i -u ranger ranger-admin start
# ranger-admin在安装时已经配设置为开机自启动,因此之后无需再手动启动
jps
# 进程名字为EmbeddedServer
# 访问Ranger的WebUI,地址为:http://hadoop102:6080,账号密码admin/atguigu123
# 停止ranger(此处不用执行)
sudo -i -u ranger ranger-admin stop二、Ranger简单使用
https://cwiki.apache.org/confluence/display/RANGER/Row-level+filtering+and+column-masking+using+Apache+Ranger+policies+in+Apache+Hive
1、安装 RangerUsersync
1.1 RangerUsersync简介
RangerUsersync作为Ranger提供的一个管理模块,可以将Linux机器上的用户和组信息同步到RangerAdmin的数据库中进行管理
1.2 RangerUsersync安装
# 解压
tar -zxvf ranger-2.0.0-usersync.tar.gz -C /opt/module/ranger/
# 在/opt/module/ranger/ranger-2.0.0-usersync目录下修改以下文件
vim install.properties
# ================================
#rangeradmin的url
POLICY_MGR_URL =http://hadoop102:6080#同步间隔时间,单位(分钟)
SYNC_INTERVAL = 1#运行此进程的linux用户
unix_user=ranger
unix_group=ranger#rangerUserSync用户的密码,参考rangeradmin中install.properties的配置
rangerUsersync_password=atguigu123#Kerberos相关配置
usersync_principal=rangerusersync/hadoop102@EXAMPLE.COM
usersync_keytab=/etc/security/keytab/rangerusersync.keytab
hadoop_conf=/opt/module/hadoop-3.1.3/etc/hadoop# ================================# 在/opt/module/ranger/ranger-2.0.0-usersync目录下执行安装脚本
./setup.sh
# 修改/opt/module/ranger/ranger-2.0.0-usersync/conf/ranger-ugsync-site.xml配置文件中的以下参数
<property><name>ranger.usersync.enabled</name><value>true</value>
</property>1.3 RangerUsersync启动
# 启动之前,在ranger admin的web-UI界面,http://hadoop102:6080/index.html#!/users/usertab
# 启动RangerUserSync(使用ranger用户启动)
sudo -i -u ranger ranger-usersync start
# 启动后,再次查看用户信息
# 说明ranger-usersync工作正常!
# ranger-usersync服务也是开机自启动的,因此之后不需要手动启动2、安装Ranger Hive-plugin
2.1 Ranger Hive-plugin简介
Ranger Hive-plugin是Ranger对hive进行权限管理的插件。需要注意的是,Ranger Hive-plugin只能对使用jdbc方式访问hive的请求进行权限管理,hive-cli并不受限制
2.2 Ranger Hive-plugin安装
# 解压软件
tar -zxvf ranger-2.0.0-hive-plugin.tar.gz -C /opt/module/ranger/
# 配置软件
vim install.properties
# 修改以下内容
# ===================================
#策略管理器的url地址
POLICY_MGR_URL=http://hadoop102:6080#组件名称
REPOSITORY_NAME=hive#hive的安装目录
COMPONENT_INSTALL_DIR_NAME=/opt/module/hive#hive组件的启动用户
CUSTOM_USER=hive#hive组件启动用户所属组
CUSTOM_GROUP=hadoop
# =====================================
# 启用Ranger Hive-plugin,在/opt/module/ranger/ranger-2.0.0-hive-plugin下执行以下命令
./enable-hive-plugin.sh
# 查看$HIVE_HOME/conf目录是否出现以下配置文件,如出现则表示Hive插件启用成功。
ls $HIVE_HOME/conf | grep -E hiveserver2\|ranger
# 重启Hiveserver2,需使用hive用户启动
sudo -i -u hive hiveserver22.3 在ranger admin上配置hive插件
谁启动hiveserver2谁设置为admin角色,我这里hive启动,将角色设置为Admin
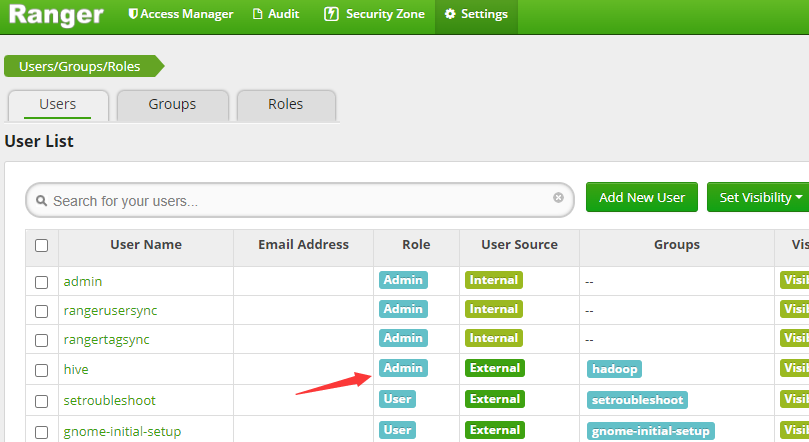
配置Hive插件,点击Access Manager,添加Hive Manager,配置服务详情
Service Name:hive
Username:rangerlookup
Password:rangerlookup
jdbc.driverClassName:org.apache.hive.jdbc.HiveDriver
jdbc.url:jdbc:hive2://hadoop102:10000/;principal=hive/hadoop102@EXAMPLE.COM
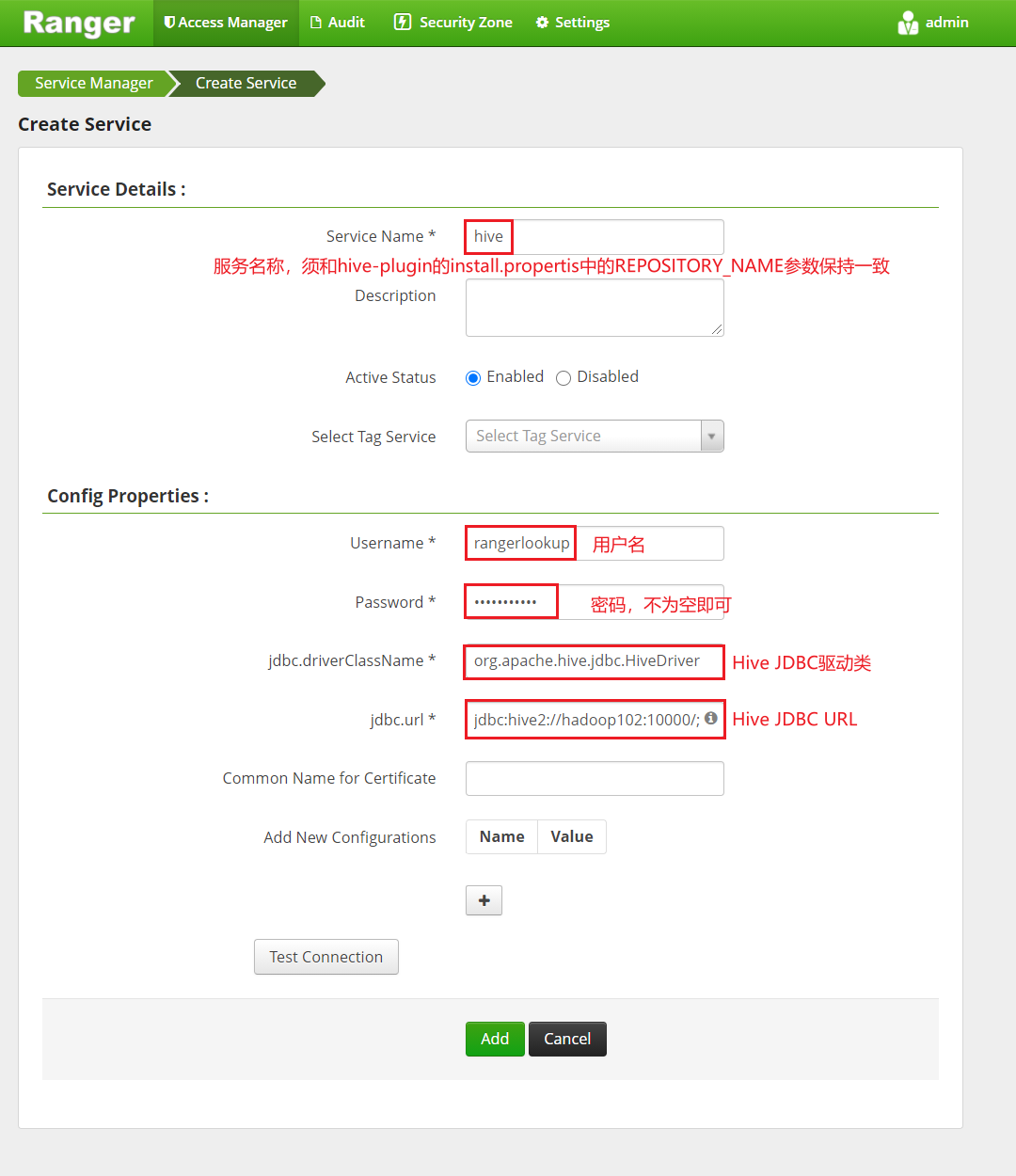
先进行add,如何在编辑进行测试,可以发现成功连接了
3、使用Ranger对Hive进行权限管理
3.1 权限控制初体验
查看默认的访问策略,此时只有rangerlookup用户拥有对所有库、表和函数的访问权限,故理论上其余用户是不能访问任何Hive资源的
# 验证:使用atguigu用户尝试进行认证,认证成功后,使用beeline客户端连接Hiveserver2
# 首先进行认证
kinit atguigu
beeline -u "jdbc:hive2://hadoop102:10000/;principal=hive/hadoop102@EXAMPLE.COM"
# 执行以下sql语句,验证当前用户为atguigu
select current_user();
# 执行use gmall语句,结果atguigu用户没有对gmall库的使用权限
use gmall;
# 赋予atguigu用户对gmall数据库的访问权限
# 点击hive->点击Add New Policy
# 配置授权策略,将gmall库的所有表的所有权限均授予给了atguigu用户

等待片刻,在回到beeline客户端,重新执行use gmall语句,此时atguigu用户已经能够使用gmall库,并且可访问gmall库下的所有表了
3.2 Ranger授权模型
Ranger所采用的权限管理模型可归类为RBAC(Role-Based Access Control )基于角色的访问控制。基础的RBAC模型共包含三个实体,分别是用户(user)、角色(role)和权限(permission)。用户需划分为某个角色,权限的授予对象也是角色,例如用户张三为管理角色,那他就拥有了管理员角色的所有权限。
Ranger的权限管理模型比基础的RBAC模型要更加灵活,以下是Ranger的权限管理模型。
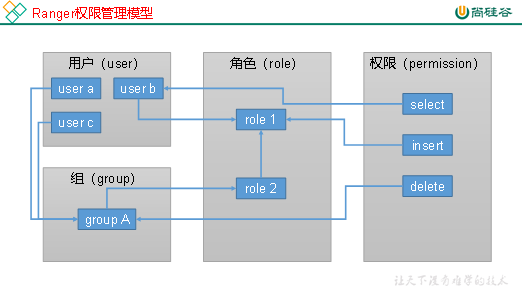





 Error : out of bounds)
)


)
 clicked() clicked(bool)}达成巧用)



TinyBERT: Distilling BERT for Natural Language Understanding)

WILDCHAT:570K CHATGPT INTERACTION LOGS IN THE WILD)

 - 24 信息系统安全(1)》)
