数据分析(2)
本文介绍pandas的另一种数据类型DataFrame,中文叫数据框
DataFrame
定义:
DataFrame是一个二维的矩阵数据表,通过行和列,可以定位一个值。
在某种程度上,可以认为DataFrame是“具有相同index的series的集合”
定位:
1.行索引(index),可以用来定位到具体的某一行
2.列索引(columns),用来定位到具体的某一列
通过index和columns,可以定位到一个值,能快速进行数据的筛选和定位
DataFrame构造函数
import pandas as pddata = {'rank':[1,2,3,4],'GDP':[80855,77388,68024,47251]}
city = ['GD','JS','SD','ZJ']
df = pd.DataFrame(data,index=city)
print(df)
运行结果:

第一个常用参数:data,表示需要传入的数据,可以是字典,列表等。若不传入数据,会生成一个空的DataFrame。
第二个常用参数:index,参数index用于定义DataFrame的行索引(index),如果不传入可选参数,index就会默认从0开始生成。
import pandas as pddata = {'rank':[1,2,3,4],'GDP':[80855,77388,68024,47251]}
city = ['GD','JS','SD','ZJ']
df = pd.DataFrame(data,index=city)
print(df.dtypes) #输出df每一列数据的数据类型
print(df.values) #输出df的每一列的数据的值
print(df.index) #输出变量df的行索引
运行结果:

DataFrame的轴
轴(axis),是用来为超过一维的数组定义属性,二维数组有两个轴,三维数组有三个轴,以此类推。
eg:对于DataFrame而言,第0轴垂直向下,即axis=0是垂直方向进行操作;第1轴水平向右,即asix=1是水平方向进行操作。

如果要按行或者按列来对DataFrame内的数据进行求和,可以使用sum()函数。
那么在sum()函数中,就可以使用axis参数来指定求和的方向。
如下图所示

当axis=0时,是在垂直的方向上进行求和操作;
当axis=1时,是在水平的方向上进行求和操作。
文件读取
在大多数情况下,处理数据和分析数据时,我们的数据来源都是CSV文件和Excel文件
pandas的DataFrame有大量数据处理的方法,所以pandas会将数据读取为DataFrame对象,以便进行后续的数据处理操作。
CSV(Comma-Separated Values)文件以纯文本的形式存储数字、文本等表格数据。它的数据格式如图所示,文件中多个数据之间通常用逗号分隔,每一列的数据都是相同的结构。
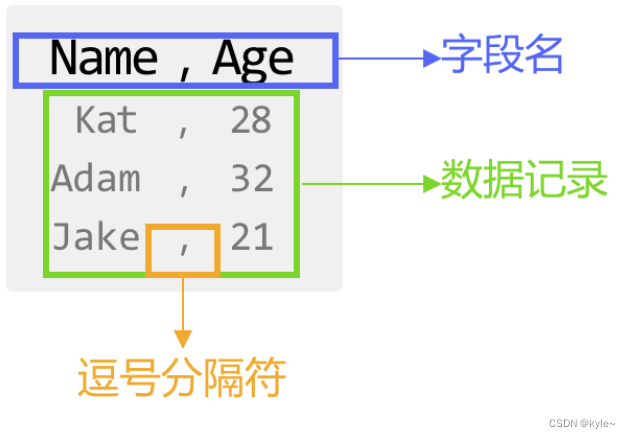
读取CSV文件
在pandas模块中,读取CSV文件主要使用pd.read_csv()函数。
import pandas as pddata = pd.read_csv("path")
参数:
必选参数: 要读取的CSV文件的文件路径
可选参数:1.指定行索引:index_col
2.获取指定列
3.添加colums:header=None和names
4.设置格式参数encoding=“utf-8”,避免读取csv文件乱码
保存CSV文件
保存CSV文件主要使用DataFrame(变量名).to_csv()
data.to_csv("path")
必选参数:要保存CSV文件的文件路径
可选参数:设置索引参数index = False,这样就不会将行索引信息写入第一列
设置参数encoding=“utf-8-sig”,避免产生csv文件乱码
读取Excel文件
在pandas模块中,读取excel文件主要使用pd.read_excel()函数。
data=pd.read_excel(".xlsx",sheet_name="XXX")
参数:
必选参数:要读取的Excel文件的文件路径
可选参数:当我们需要读取指定工作表时,pd.read_excel()函数提供了一个参数sheet_name = “”,将要读取的工作表名称作为字符串传入该参数即可
江湖可能因为少了谁而失色,却不会因为少了谁后就不再是江湖。 —高手寂寞
)








)

)







