简介
Protocol Buffers(protobuf),它是 Google 开发的一种数据序列化协议(与 XML、JSON 类似)。
优点:
- 效率高:Protobuf 以二进制格式存储数据,比如 XML 和 JSON 等文本格式更紧凑,也更快。序列化和反序列化的速度也很快。
- 跨语言支持:Protobuf 支持多种编程语言,包括 C++、Java、Python 等。
- 清晰的结构定义:使用 protobuf,可以清晰地定义数据的结构,这有助于维护和理解。
- 向后兼容性:你可以添加或者删除字段,而不会破坏老的应用程序。这对于长期的项目来说是非常有价值的。
缺点:
- 不直观:由于 protobuf 是二进制格式,人不能直接阅读和修改它。这对于调试和测试来说可能会有些困难。
- 缺乏一些数据类型:例如没有内建的日期、时间类型,对于这些类型的数据,需要手动转换成可以支持的类型,如 string 或 int。
- 需要额外的编译步骤:你需要先定义数据结构,然后使用 protobuf 的编译器将其编译成目标语言的代码,这是一个额外的步骤,可能会影响开发流程。
编码原理
举例
对于 protobuf 它的编码是很紧凑的,我们先看一下 message 的结构,举一个简单的例子:
message Student {string name = 1;int32 age = 2;
}message 是一系列键值对,编码过之后实际上只有 tag 序列号和对应的值,这一点相比我们熟悉的 json 很不一样,所以对于 protobuf 来说没有 .proto 文件是无法解出来的:
对于 tag 来说,它保存了 message 字段的编号以及类型信息,我们可以做个实验,把 name 这个 tag 编码后的二进制打印出来:
func main() {student := student.Student{}student.Name = "t"marshal, _ := proto.Marshal(&student)fmt.Println(fmt.Sprintf("%08b", marshal)) // 00001010 00000001 01110100
}
打印出来的结果是这样:

上图中,由于 name 是 string 类型,所以第一个 byte 是 tag,第二 byte 是 string 的长度,第三个 byte 是值,也就是我们上面设置的 “t”。
tag
我们下面先看看 tag:
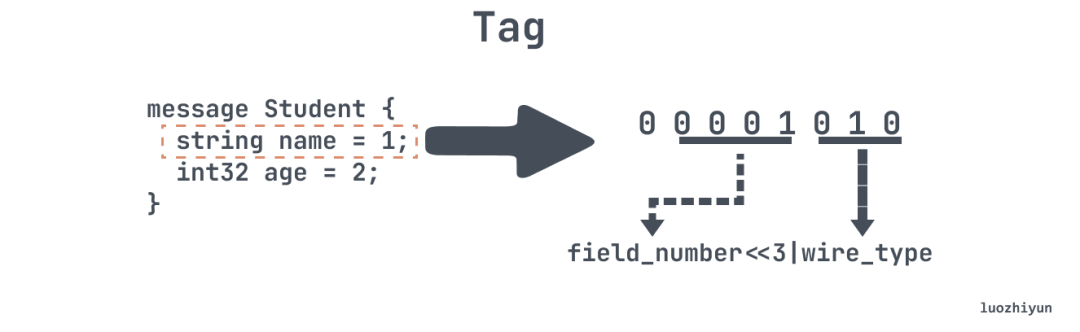
tag 里面会包含两部分信息:字段序号,字段类型,计算方式就是上图的公式。
① 第一个 bit 是标记位,表示是否字段结尾,这里是 0 表示 tag 已结尾,tag 占用 1byte;
② 接下来 4 个 bit 表示的是字段序号,这里0001 表示序号1。 所以范围 1 到 15 中的字段编号只需要 1 bit 进行编码
做个实验看看,将 tag 改成 16:
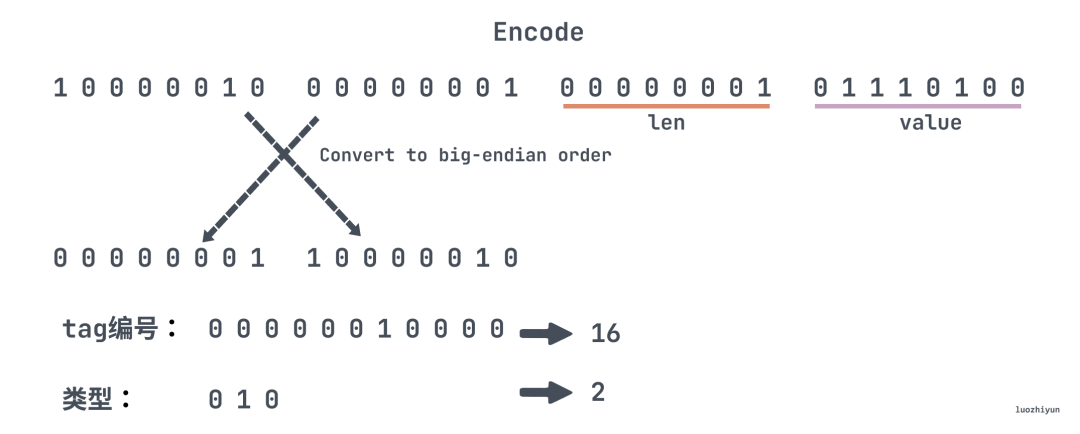
protobuf 是小端编码的,需要转成大端方便阅读:
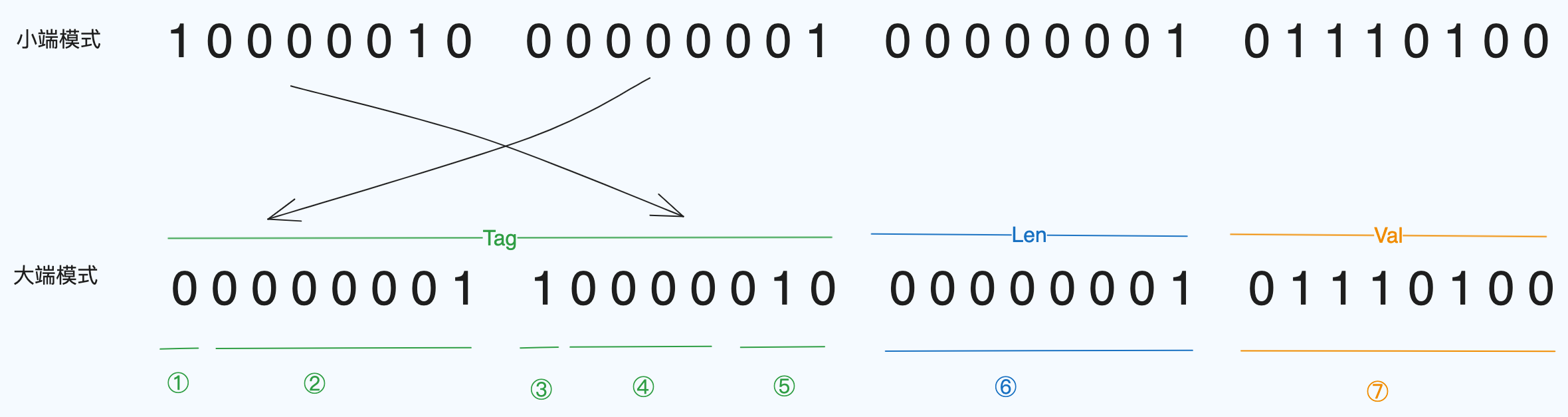
由上图所示,
① 和 ③Tag的每个 byte 第一个 bit 表示是否结束,0 表示结束,所以上面 tag 用两个 byte 表示。
⑤ 去掉每个 byte 第一个 bit 之后,后三位( 0 1 0)表示类型,是 1,
② ④ 其余位是字段序号 (0 0 0 0 0 0 1 0 0 0 0) 表示 16。
所以从上面编码规则我们也可以知道,字段尽可能精简一些,字段尽量不要超过 16 个,这样Tag 就可以用一个 byte 表示了。
同时我们也可以知道,protobuf 序列化是不带字段名的,所以如果客户端的 proto 文件只修改了字段名,请求服务端是安全的,服务端继续用根据序列编号还是解出来原来的字段。但是需要注意的是不要修改字段类型。
类型
类型,protobuf 共定义了 6 种类型,其中两种是废弃的:
| ID | Name | Used For |
| 0 | VARINT | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | I64 | fixed64, sfixed64, double |
| 2 | LEN | string, bytes, embedded messages, packed repeated fields |
| 3 | SGROUP | group start (deprecated) |
| 4 | EGROUP | group end (deprecated) |
| 5 | I32 | fixed32, sfixed32, float |
上面的例子中,Name 是 string 类型所以上面 tag 类型解出来是 010 ,也就是 2。
参考:数据序列化工具Protobuf编码&避坑指南-腾讯云开发者社区-腾讯云






和机器视觉的算子(operator))

外部资源释放和内存池销毁)



)




![C语言经典例题[24]](http://pic.xiahunao.cn/C语言经典例题[24])

