1打家劫舍
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
示例 1:
输入:[1,2,3,1] 输出:4 解释:偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。偷窃到的最高金额 = 1 + 3 = 4 。
示例 2:
输入:[2,7,9,3,1] 输出:12 解释:偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。偷窃到的最高金额 = 2 + 9 + 1 = 12 。
提示:
1 <= nums.length <= 1000 <= nums[i] <= 400
思路:
大家如果刚接触这样的题目,会有点困惑,当前的状态我是偷还是不偷呢?
仔细一想,当前房屋偷与不偷取决于 前一个房屋和前两个房屋是否被偷了。由于不能偷相邻的房屋,所以偷窃当前房屋的决策实际上是一个在两种选择中取最优值的问题:偷窃当前房屋或者不偷窃当前房屋。因此,我们使用动态规划来记录偷窃到每个房屋时的最大金额,通过比较偷窃当前房屋和不偷窃当前房屋两种选择的结果,来更新动态规划数组。
我们可以用一个数组 dp 来记录到每个房屋为止能够偷窃到的最高金额,其中 dp[i] 表示偷窃到第 i 个房屋时的最大金额。
具体的解题思路如下:
- 对于第一个房屋,最大金额就是该房屋内的现金数目。
- 对于第二个房屋,由于不能偷相邻的房屋,所以最大金额就是第一个房屋的金额和第二个房屋的金额中的较大值。
- 对于第三个房屋及之后的每个房屋,最大金额就是当前房屋金额加上前两个房屋中能够偷窃到的最大金额。
- 确定dp数组(dp table)以及下标的含义
-
dp[i]:考虑下标i(包括i)以内的房屋,最多可以偷窃的金额为dp[i]。
- 确定递推公式
-
决定dp[i]的因素就是第i房间偷还是不偷。
如果偷第i房间,那么dp[i] = dp[i - 2] + nums[i] ,即:第i-1房一定是不考虑的,找出 下标i-2(包括i-2)以内的房屋,最多可以偷窃的金额为dp[i-2] 加上第i房间偷到的钱。
如果不偷第i房间,那么dp[i] = dp[i - 1],即考 虑i-1房,然后dp[i]取最大值,即dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
- dp数组如何初始化
-
从递推公式dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);可以看出,递推公式的基础就是dp[0] 和 dp[1]
从dp[i]的定义上来讲,dp[0] 一定是 nums[0],dp[1]就是nums[0]和nums[1]的最大值即:dp[1] = max(nums[0], nums[1]);
- 确定遍历顺序
-
dp[i] 是根据dp[i - 2] 和 dp[i - 1] 推导出来的,那么一定是从前到后遍历!
-
代码:
class Solution { public:int rob(vector<int>& nums) {// 处理特殊情况:空数组和只有一个房屋的情况if (nums.size() == 0) return 0; // 如果房屋数量为0,则返回0if (nums.size() == 1) return nums[0]; // 如果只有一个房屋,则返回该房屋的金额// 初始化动态规划数组vector<int> dp(nums.size()); // 创建一个大小为nums.size()的数组dp,用于记录偷窃到每个房屋时的最大金额dp[0] = nums[0]; // 第一个房屋的最大金额就是该房屋内的现金数目dp[1] = max(nums[0], nums[1]); // 第二个房屋的最大金额为第一个房屋的金额和第二个房屋的金额中的较大值// 动态规划递推过程for (int i = 2; i < nums.size(); i++) {// 对于第三个房屋及之后的每个房屋,最大金额就是当前房屋金额加上前两个房屋中能够偷窃到的最大金额dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);}// 返回最终结果,即偷窃到的最高金额return dp[nums.size() - 1];} };2打家劫舍 II
你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都 围成一圈 ,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警 。
给定一个代表每个房屋存放金额的非负整数数组,计算你 在不触动警报装置的情况下 ,今晚能够偷窃到的最高金额。
示例 1:
输入:nums = [2,3,2] 输出:3 解释:你不能先偷窃 1 号房屋(金额 = 2),然后偷窃 3 号房屋(金额 = 2), 因为他们是相邻的。
示例 2:
输入:nums = [1,2,3,1] 输出:4 解释:你可以先偷窃 1 号房屋(金额 = 1),然后偷窃 3 号房屋(金额 = 3)。偷窃到的最高金额 = 1 + 3 = 4 。
示例 3:
输入:nums = [1,2,3] 输出:3
提示:
1 <= nums.length <= 1000 <= nums[i] <= 1000
思路:
这个问题是「打家劫舍」问题的一个变种,房屋围成一圈,即第一个房屋和最后一个房屋相邻。因此,在考虑偷取的时候需要考虑首尾房屋不能同时偷取的情况。
解题思路可以借鉴动态规划的思想,但是需要分情况讨论:
- 如果偷取了第一间房屋,则最后一间房屋不能偷取,因此偷取范围为第一间到倒数第二间房屋;
- 如果没有偷取第一间房屋,则最后一间房屋可以选择偷取或不偷取,偷取范围为第二间到最后一间房屋。
因此,可以将问题分解为两个子问题,分别计算偷取第一间房屋和不偷取第一间房屋的最大金额,然后取两者中的最大值即可。
代码:
class Solution {
public:// 主函数,计算在不触动警报装置的情况下,能够偷窃到的最高金额int rob(vector<int>& nums) {if (nums.size() == 0) return 0; // 如果房屋数量为0,则返回0if (nums.size() == 1) return nums[0]; // 如果房屋数量为1,则返回唯一的房屋金额// 计算情况二:偷取第一间房屋int result1 = robRange(nums, 0, nums.size() - 2);// 计算情况三:不偷取第一间房屋int result2 = robRange(nums, 1, nums.size() - 1);// 返回两种情况中的最大值return max(result1, result2);}// 实现打家劫舍的逻辑,计算指定范围内的最大金额int robRange(vector<int>& nums, int start, int end) {if (end == start) return nums[start]; // 如果只有一个房屋,则直接返回该房屋的金额vector<int> dp(nums.size()); // 创建动态规划数组,用于记录偷取每个房屋时的最大金额dp[start] = nums[start]; // 初始化动态规划数组的起始值dp[start + 1] = max(nums[start], nums[start + 1]); // 初始化动态规划数组的第二个值// 动态规划递推过程for (int i = start + 2; i <= end; i++) {// 计算偷窃到当前房屋的最大金额,选择偷取当前房屋或不偷取当前房屋的最大值dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);}// 返回指定范围内的最大金额return dp[end];}
};3打家劫舍 III
小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为 root 。
除了 root 之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果 两个直接相连的房子在同一天晚上被打劫 ,房屋将自动报警。
给定二叉树的 root 。返回 在不触动警报的情况下 ,小偷能够盗取的最高金额 。
示例 1:

输入: root = [3,2,3,null,3,null,1] 输出: 7 解释: 小偷一晚能够盗取的最高金额 3 + 3 + 1 = 7
示例 2:
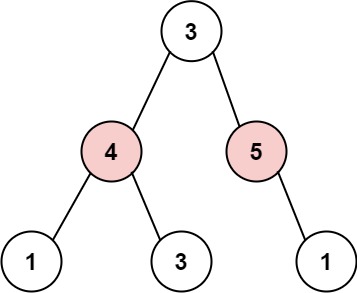
输入: root = [3,4,5,1,3,null,1] 输出: 9 解释: 小偷一晚能够盗取的最高金额 4 + 5 = 9
提示:
- 树的节点数在
[1, 104]范围内 0 <= Node.val <= 104
思路:
- 设计一个包含两个元素的数组
dp,dp[0]表示不偷当前节点能获得的最大金额,dp[1]表示偷当前节点能获得的最大金额。 - 对于每个节点,有两种情况:偷或者不偷。
- 如果偷当前节点,则其左右子节点不能被偷,所以偷当前节点的最大金额为当前节点的值加上不偷左右子节点的最大金额。
- 如果不偷当前节点,则其左右子节点可以被偷或者不偷,所以不偷当前节点的最大金额为左右子节点偷或不偷的最大金额之和。
- 最后返回根节点偷或不偷的最大金额中的较大值。
代码:
class Solution {
public:// 主函数,计算在不触动警报装置的情况下,能够偷窃到的最高金额int rob(TreeNode* root) {// 调用辅助函数,获取根节点为起点的偷窃情况vector<int> result = robTree(root);// 返回偷窃根节点和不偷窃根节点的最大金额return max(result[0], result[1]);}// 辅助函数,计算以当前节点为根节点的偷窃情况// 返回长度为2的数组,0:不偷,1:偷vector<int> robTree(TreeNode* cur) {// 如果当前节点为空,返回{0, 0},表示不偷任何东西if (cur == NULL) return vector<int>{0, 0};// 递归调用,获取左右子树的偷窃情况vector<int> left = robTree(cur->left);vector<int> right = robTree(cur->right);// 偷当前节点,那么就不能偷左右子节点int val1 = cur->val + left[0] + right[0];// 不偷当前节点,那么可以偷也可以不偷左右子节点,取较大的情况int val2 = max(left[0], left[1]) + max(right[0], right[1]);// 返回当前节点偷与不偷的最大金额return {val2, val1};}
};4最后一个单词的长度
给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。
单词 是指仅由字母组成、不包含任何空格字符的最大
子字符串
。
示例 1:
输入:s = "Hello World" 输出:5 解释:最后一个单词是“World”,长度为5。
示例 2:
输入:s = " fly me to the moon " 输出:4 解释:最后一个单词是“moon”,长度为4。
示例 3:
输入:s = "luffy is still joyboy" 输出:6 解释:最后一个单词是长度为6的“joyboy”。
提示:
1 <= s.length <= 104s仅有英文字母和空格' '组成s中至少存在一个单词
思路:
由于字符串中至少存在一个单词,因此字符串中一定有字母。首先找到字符串中的最后一个字母,该字母即为最后一个单词的最后一个字母。
从最后一个字母开始继续反向遍历字符串,直到遇到空格或者到达字符串的起始位置。遍历到的每个字母都是最后一个单词中的字母,因此遍历到的字母数量即为最后一个单词的长度。
代码:
class Solution {
public:// 计算最后一个单词的长度int lengthOfLastWord(string s) {int i = s.size() - 1; // 从字符串末尾开始向前遍历int count = 0; // 计数器,用于记录最后一个单词的长度// 跳过末尾的空格while (s[i] == ' ') {i--;}// 计算最后一个单词的长度while (i >= 0 && s[i] != ' ') {i--;count++;}return count; // 返回最后一个单词的长度}
};5市场分析 I
表: Users
+----------------+---------+ | Column Name | Type | +----------------+---------+ | user_id | int | | join_date | date | | favorite_brand | varchar | +----------------+---------+ user_id 是此表主键(具有唯一值的列)。 表中描述了购物网站的用户信息,用户可以在此网站上进行商品买卖。
表: Orders
+---------------+---------+ | Column Name | Type | +---------------+---------+ | order_id | int | | order_date | date | | item_id | int | | buyer_id | int | | seller_id | int | +---------------+---------+ order_id 是此表主键(具有唯一值的列)。 item_id 是 Items 表的外键(reference 列)。 (buyer_id,seller_id)是 User 表的外键。
表:Items
+---------------+---------+ | Column Name | Type | +---------------+---------+ | item_id | int | | item_brand | varchar | +---------------+---------+ item_id 是此表的主键(具有唯一值的列)。
编写解决方案找出每个用户的注册日期和在 2019 年作为买家的订单总数。
以 任意顺序 返回结果表。
查询结果格式如下。
示例 1:
输入: Users 表: +---------+------------+----------------+ | user_id | join_date | favorite_brand | +---------+------------+----------------+ | 1 | 2018-01-01 | Lenovo | | 2 | 2018-02-09 | Samsung | | 3 | 2018-01-19 | LG | | 4 | 2018-05-21 | HP | +---------+------------+----------------+ Orders 表: +----------+------------+---------+----------+-----------+ | order_id | order_date | item_id | buyer_id | seller_id | +----------+------------+---------+----------+-----------+ | 1 | 2019-08-01 | 4 | 1 | 2 | | 2 | 2018-08-02 | 2 | 1 | 3 | | 3 | 2019-08-03 | 3 | 2 | 3 | | 4 | 2018-08-04 | 1 | 4 | 2 | | 5 | 2018-08-04 | 1 | 3 | 4 | | 6 | 2019-08-05 | 2 | 2 | 4 | +----------+------------+---------+----------+-----------+ Items 表: +---------+------------+ | item_id | item_brand | +---------+------------+ | 1 | Samsung | | 2 | Lenovo | | 3 | LG | | 4 | HP | +---------+------------+ 输出: +-----------+------------+----------------+ | buyer_id | join_date | orders_in_2019 | +-----------+------------+----------------+ | 1 | 2018-01-01 | 1 | | 2 | 2018-02-09 | 2 | | 3 | 2018-01-19 | 0 | | 4 | 2018-05-21 | 0 | +-----------+------------+----------------+
思路:-- 在用户表和订单表之间进行左连接,以保证即使某些用户在2019年没有订单也能够显示出来
-- 使用 left join 来保留 users 表中的所有用户,即使他们在订单表中没有对应的记录
-- 使用 count() 函数来计算每个用户在2019年的订单数量
-- 使用 year() 函数来提取订单日期的年份,并将其与2019进行比较
-- 最后按照用户 ID 分组,并选择用户 ID、加入日期和2019年的订单数量作为结果
代码:
select user_id as buyer_id, -- 选择用户 ID 作为买家 IDjoin_date, -- 选择用户的加入日期count(order_id) as orders_in_2019 -- 计算用户在2019年的订单数量
from Users as u -- 从用户表中选择用户信息
left join Orders as o on u.user_id = o.buyer_id and year(order_date)='2019' -- 使用左连接关联订单表,并筛选出2019年的订单
group by user_id; -- 按照用户 ID 进行分组
![[重学Python]Day 2 Python经典案例简单习题6个](http://pic.xiahunao.cn/[重学Python]Day 2 Python经典案例简单习题6个)





)




![[BT]BUUCTF刷题第17天(4.15)](http://pic.xiahunao.cn/[BT]BUUCTF刷题第17天(4.15))
)





)