文章目录
- 一、DolphinScheduler概述和部署
- 1、DolphinScheduler简介
- 1.1 概述
- 1.2 核心架构
- 2、DolphinScheduler部署模式
- 2.1 概述
- 2.2 单机模式
- 2.3 伪集群模式
- 2.4 集群模式
- 3、DolphinScheduler集群模式部署
- 3.1 集群规划与准备
- 3.2 下载与配置部署脚本
- 3.3 初始化数据库
- 3.4 一键部署DolphinScheduler
- 3.5 DolphinScheduler启停命令
- 二、DolphinScheduler操作
- 1、工作流传参
- 1.1 内置参数
- 1.2 参数传递
- 2、引用依赖资源
- 3、数据源配置
- 4、告警实例配置
- 4.1 邮箱告警实例配置
- 4.2 其他告警
- 5、其他注意事项
- 三、Airflow
- 1、Airflow基本概念
- 1.1 概述
- 1.2 名词解释
- 2、Airflow安装
- 2.1 python环境安装
- 2.2 安装Airflow
- 3、修改数据库与调度器
- 3.1 修改数据库为mysql
- 3.2 修改执行器
- 4、部署使用
- 4.1 环境部署启动
- 4.2 Dag任务操作
- 4.3 配置邮件服务器
- 四、Azkaban
- 1、Azkaban入门
- 1.1 上传jar包和配置sql
- 1.2 配置Executor Server
- 1.3 配置Web Server
- 2、Work Flow案例实操
- 2.1 HelloWorld案例
- 2.2 作业依赖案例
- 2.3 自动失败重试案例
- 2.4 手动失败重试案例
- 3、JavaProcess作业类型案例
- 3.1 概述
- 3.2 案例
- 4、条件工作流案例
- 4.1 概述
- 4.2 运行时参数案例
- 4.3 预定义宏案例
- 5、邮箱告警
- 6、Azkaban多Executor模式注意事项
一、DolphinScheduler概述和部署
官网:https://dolphinscheduler.apache.org/
1、DolphinScheduler简介
1.1 概述
Apache DolphinScheduler是一个分布式、易扩展的可视化DAG工作流任务调度平台。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用
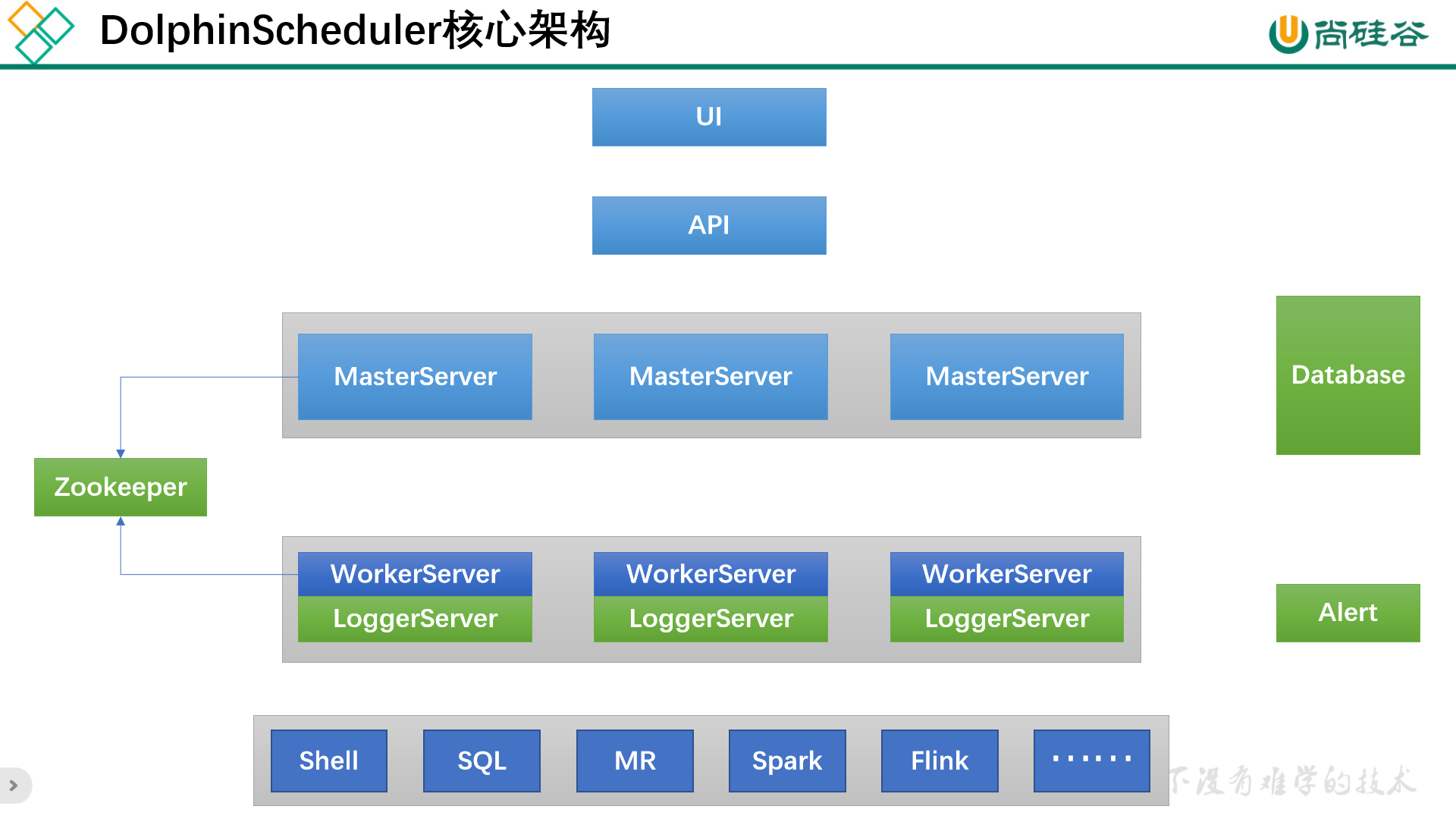
1.2 核心架构
DolphinScheduler的主要角色如下:
- MasterServer采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交、任务监控,并同时监听其它MasterServer和WorkerServer的健康状态
- WorkerServer也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务
- ZooKeeper服务,系统中的MasterServer和WorkerServer节点都通过ZooKeeper来进行集群管理和容错
- Alert服务,提供告警相关服务
- API接口层,主要负责处理前端UI层的请求
- UI,系统的前端页面,提供系统的各种可视化操作界面
2、DolphinScheduler部署模式
https://dolphinscheduler.apache.org/zh-cn/docs/2.0.3/部署指南_menu
2.1 概述
DolphinScheduler支持多种部署模式,包括单机模式(Standalone)、伪集群模式(Pseudo-Cluster)、集群模式(Cluster)等
2.2 单机模式
单机模式(standalone)模式下,所有服务均集中于一个StandaloneServer进程中,并且其中内置了注册中心Zookeeper和数据库H2。只需配置JDK环境,就可一键启动DolphinScheduler,快速体验其功能
由于DolphinScheduler的单机模式使用的是内置的ZK和数据库,故在集群模式下所做的相关配置在单机模式下并不可见,所以需要重新配置,必要的配置为创建租户和创建用户
bin/dolphinscheduler-daemon.sh start standalone-server
2.3 伪集群模式
伪集群模式(Pseudo-Cluster)是在单台机器部署 DolphinScheduler 各项服务,该模式下master、worker、api server、logger server等服务都只在同一台机器上。Zookeeper和数据库需单独安装并进行相应配置
2.4 集群模式
集群模式(Cluster)与伪集群模式的区别就是在多台机器部署 DolphinScheduler各项服务,并且可以配置多个Master及多个Worker
3、DolphinScheduler集群模式部署
3.1 集群规划与准备
- 三台节点均需部署JDK(1.8+),并配置相关环境变量
- 需部署数据库,支持MySQL(5.7+)或者PostgreSQL(8.2.15+)。如 MySQL 则需要 JDBC Driver 8.0.16
- 需部署Zookeeper(3.4.6+)
- 如果启用 HDFS 文件系统,则需要 Hadoop(2.6+)环境
- 三台节点均需安装进程管理工具包psmisc
sudo yum install -y psmisc
3.2 下载与配置部署脚本
wget https://archive.apache.org/dist/dolphinscheduler/2.0.3/apache-dolphinscheduler-2.0.3-bin.tar.gz
tar -zxvf apache-dolphinscheduler-2.0.3-bin.tar,gz修改解压目录下的conf/config目录下的install_config.conf文件,不需要修改的可以直接略过
# ---------------------------------------------------------
# INSTALL MACHINE
# ---------------------------------------------------------
# A comma separated list of machine hostname or IP would be installed DolphinScheduler,
# including master, worker, api, alert. If you want to deploy in pseudo-distributed
# mode, just write a pseudo-distributed hostname
# Example for hostnames: ips="ds1,ds2,ds3,ds4,ds5", Example for IPs: ips="192.168.8.1,192.168.8.2,192.168.8.3,192.168.8.4,192.168.8.5"
ips="hadoop102,hadoop103,hadoop104"
# 将要部署任一 DolphinScheduler 服务的服务器主机名或 ip 列表# Port of SSH protocol, default value is 22. For now we only support same port in all `ips` machine
# modify it if you use different ssh port
sshPort="22"# A comma separated list of machine hostname or IP would be installed Master server, it
# must be a subset of configuration `ips`.
# Example for hostnames: masters="ds1,ds2", Example for IPs: masters="192.168.8.1,192.168.8.2"
masters="hadoop102"
# master 所在主机名列表,必须是 ips 的子集# A comma separated list of machine <hostname>:<workerGroup> or <IP>:<workerGroup>.All hostname or IP must be a
# subset of configuration `ips`, And workerGroup have default value as `default`, but we recommend you declare behind the hosts
# Example for hostnames: workers="ds1:default,ds2:default,ds3:default", Example for IPs: workers="192.168.8.1:default,192.168.8.2:default,192.168.8.3:default"
workers="hadoop102:default,hadoop103:default,hadoop104:default"
# worker主机名及队列,此处的 ip 必须在 ips 列表中# A comma separated list of machine hostname or IP would be installed Alert server, it
# must be a subset of configuration `ips`.
# Example for hostname: alertServer="ds3", Example for IP: alertServer="192.168.8.3"
alertServer="hadoop102"
# 告警服务所在服务器主机名
# A comma separated list of machine hostname or IP would be installed API server, it
# must be a subset of configuration `ips`.
# Example for hostname: apiServers="ds1", Example for IP: apiServers="192.168.8.1"
apiServers="hadoop102"
# api服务所在服务器主机名# A comma separated list of machine hostname or IP would be installed Python gateway server, it
# must be a subset of configuration `ips`.
# Example for hostname: pythonGatewayServers="ds1", Example for IP: pythonGatewayServers="192.168.8.1"
# pythonGatewayServers="ds1"
# 不需要的配置项,可以保留默认值,也可以用 # 注释# The directory to install DolphinScheduler for all machine we config above. It will automatically be created by `install.sh` script if not exists.
# Do not set this configuration same as the current path (pwd)
installPath="/opt/module/dolphinscheduler"
# DS 安装路径,如果不存在会创建# The user to deploy DolphinScheduler for all machine we config above. For now user must create by yourself before running `install.sh`
# script. The user needs to have sudo privileges and permissions to operate hdfs. If hdfs is enabled than the root directory needs
# to be created by this user
deployUser="atguigu"
# 部署用户,任务执行服务是以 sudo -u {linux-user} 切换不同 Linux 用户的方式来实现多租户运行作业,因此该用户必须有免密的 sudo 权限。# The directory to store local data for all machine we config above. Make sure user `deployUser` have permissions to read and write this directory.
dataBasedirPath="/tmp/dolphinscheduler"
# 前文配置的所有节点的本地数据存储路径,需要确保部署用户拥有该目录的读写权限# ---------------------------------------------------------
# DolphinScheduler ENV
# ---------------------------------------------------------
# JAVA_HOME, we recommend use same JAVA_HOME in all machine you going to install DolphinScheduler
# and this configuration only support one parameter so far.
javaHome="/opt/module/jdk1.8.0_212"
# JAVA_HOME 路径# DolphinScheduler API service port, also this is your DolphinScheduler UI component's URL port, default value is 12345
apiServerPort="12345"# ---------------------------------------------------------
# Database
# NOTICE: If database value has special characters, such as `.*[]^${}\+?|()@#&`, Please add prefix `\` for escaping.
# ---------------------------------------------------------
# The type for the metadata database
# Supported values: ``postgresql``, ``mysql`, `h2``.
# 注意:数据库相关配置的 value 必须加引号,否则配置无法生效DATABASE_TYPE="mysql"
# 数据库类型# Spring datasource url, following <HOST>:<PORT>/<database>?<parameter> format, If you using mysql, you could use jdbc
# string jdbc:mysql://127.0.0.1:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8 as example
# SPRING_DATASOURCE_URL=${SPRING_DATASOURCE_URL:-"jdbc:h2:mem:dolphinscheduler;MODE=MySQL;DB_CLOSE_DELAY=-1;DATABASE_TO_LOWER=true"}
SPRING_DATASOURCE_URL="jdbc:mysql://hadoop102:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8"
# 数据库 URL# Spring datasource username
# SPRING_DATASOURCE_USERNAME=${SPRING_DATASOURCE_USERNAME:-"sa"}
SPRING_DATASOURCE_USERNAME="dolphinscheduler"
# 数据库用户名# Spring datasource password
# SPRING_DATASOURCE_PASSWORD=${SPRING_DATASOURCE_PASSWORD:-""}
SPRING_DATASOURCE_PASSWORD="dolphinscheduler"
# 数据库密码# ---------------------------------------------------------
# Registry Server
# ---------------------------------------------------------
# Registry Server plugin name, should be a substring of `registryPluginDir`, DolphinScheduler use this for verifying configuration consistency
registryPluginName="zookeeper"
# 注册中心插件名称,DS 通过注册中心来确保集群配置的一致性# Registry Server address.
registryServers="hadoop102:2181,hadoop103:2181,hadoop104:2181"
# 注册中心地址,即 Zookeeper 集群的地址# Registry Namespace
registryNamespace="dolphinscheduler"
# DS 在 Zookeeper 的结点名称# ---------------------------------------------------------
# Worker Task Server
# ---------------------------------------------------------
# Worker Task Server plugin dir. DolphinScheduler will find and load the worker task plugin jar package from this dir.
taskPluginDir="lib/plugin/task"# resource storage type: HDFS, S3, NONE
resourceStorageType="HDFS"
# 资源存储类型# resource store on HDFS/S3 path, resource file will store to this hdfs path, self configuration, please make sure the directory exists on hdfs and has read write permissions. "/dolphinscheduler" is recommended
resourceUploadPath="/dolphinscheduler"
# 资源上传路径# if resourceStorageType is HDFS,defaultFS write namenode address,HA, you need to put core-site.xml and hdfs-site.xml in the conf directory.
# if S3,write S3 address,HA,for example :s3a://dolphinscheduler,
# Note,S3 be sure to create the root directory /dolphinscheduler
defaultFS="hdfs://hadoop102:8020"
# 默认文件系统# if resourceStorageType is S3, the following three configuration is required, otherwise please ignore
s3Endpoint="http://192.168.xx.xx:9010"
s3AccessKey="xxxxxxxxxx"
s3SecretKey="xxxxxxxxxx"# resourcemanager port, the default value is 8088 if not specified
resourceManagerHttpAddressPort="8088"
# yarn RM http 访问端口# if resourcemanager HA is enabled, please set the HA IPs; if resourcemanager is single node, keep this value empty
yarnHaIps=
# Yarn RM 高可用 ip,若未启用 RM 高可用,则将该值置空# if resourcemanager HA is enabled or not use resourcemanager, please keep the default value; If resourcemanager is single node, you only need to replace 'yarnIp1' to actual resourcemanager hostname
singleYarnIp="hadoop103"
# Yarn RM 主机名,若启用了 HA 或未启用 RM,保留默认值# who has permission to create directory under HDFS/S3 root path
# Note: if kerberos is enabled, please config hdfsRootUser=
hdfsRootUser="atguigu"
# 拥有 HDFS 根目录操作权限的用户# 下面是如果hdfs开启了验证在操作的
# kerberos config
# whether kerberos starts, if kerberos starts, following four items need to config, otherwise please ignore
kerberosStartUp="false"
# kdc krb5 config file path
krb5ConfPath="$installPath/conf/krb5.conf"
# keytab username,watch out the @ sign should followd by \\
keytabUserName="hdfs-mycluster\\@ESZ.COM"
# username keytab path
keytabPath="$installPath/conf/hdfs.headless.keytab"
# kerberos expire time, the unit is hour
kerberosExpireTime="2"# use sudo or not
sudoEnable="true"# worker tenant auto create
workerTenantAutoCreate="false"
3.3 初始化数据库
DolphinScheduler 元数据存储在关系型数据库中,故需创建相应的数据库和用户
# 创建数据库
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
# 创建用户
CREATE USER 'dolphinscheduler'@'%' IDENTIFIED BY 'dolphinscheduler';# 提高密码复杂度或者执行以下命令降低MySQL密码强度级别
set global validate_password_length=4;
set global validate_password_policy=0;
# 赋予用户相应权限
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%';
flush privileges;# 拷贝MySQL驱动到DolphinScheduler的解压目录下的lib中
cp /opt/software/mysql-connector-java-8.0.16.jar lib/# 执行数据库初始化脚本
# 数据库初始化脚本位于DolphinScheduler解压目录下的script目录中,即/opt/software/ds/apache-dolphinscheduler-2.0.3-bin/script/
script/create-dolphinscheduler.sh3.4 一键部署DolphinScheduler
# 启动zk
zk.sh start
# 一键部署并启动DolphinScheduler
./install.sh
# 查看DolphinScheduler进程
# ApiApplicationServer
# WorkerServer
# MasterServer
# AlertServer
# LoggerServer# ----------
# 访问DolphinScheduler UI
# DolphinScheduler UI地址为http://hadoop102:12345/dolphinscheduler
# 初始用户的用户名为:admin,密码为dolphinscheduler123
3.5 DolphinScheduler启停命令
安装完后得去/opt/module/dolphinscheduler修改或启停
# 一键启停所有服务
./bin/start-all.sh
./bin/stop-all.sh
# 注意同Hadoop的启停脚本进行区分
# 启停 Master
./bin/dolphinscheduler-daemon.sh start master-server
./bin/dolphinscheduler-daemon.sh stop master-server
# 启停 Worker
./bin/dolphinscheduler-daemon.sh start worker-server
./bin/dolphinscheduler-daemon.sh stop worker-server
# 启停 Api
./bin/dolphinscheduler-daemon.sh start api-server
./bin/dolphinscheduler-daemon.sh stop api-server
# 启停 Logger
./bin/dolphinscheduler-daemon.sh start logger-server
./bin/dolphinscheduler-daemon.sh stop logger-server
# 启停 Alert
./bin/dolphinscheduler-daemon.sh start alert-server
./bin/dolphinscheduler-daemon.sh stop alert-server
二、DolphinScheduler操作
入门文档可以参考:https://dolphinscheduler.apache.org/zh-cn/docs/2.0.3/guide/quick-start
1、工作流传参
https://dolphinscheduler.apache.org/zh-cn/docs/2.0.3/功能介绍_menu/参数_menu
DolphinScheduler支持对任务节点进行灵活的传参,任务节点可通过${参数名}引用参数值
1.1 内置参数
基础内置参数
| 变量名 | 参数 | 说明 |
|---|---|---|
| system.biz.date | ${system.biz.date} | 定时时间前一天,格式为 yyyyMMdd |
| system.biz.curdate | ${system.biz.curdate} | 定时时间,格式为 yyyyMMdd |
| system.datetime | ${system.datetime} | 定时时间,格式为 yyyyMMddHHmmss |
衍生内置参数
可通过衍生内置参数,设置任意格式、任意时间的日期。
- 自定义日期格式:可以对 $[yyyyMMddHHmmss] 任意分解组合,如 $[yyyyMMdd], $[HHmmss], $[yyyy-MM-dd]。
- 使用 add_months() 函数:该函数用于加减月份, 第一个入口参数为[yyyyMMdd],表示返回时间的格式 第二个入口参数为月份偏移量,表示加减多少个月
| 参数 | 说明 |
|---|---|
| $[add_months(yyyyMMdd,12*N)] | 后 N 年 |
| $[add_months(yyyyMMdd,-12*N)] | 前 N 年 |
| $[add_months(yyyyMMdd,N)] | 后 N 月 |
| $[add_months(yyyyMMdd,-N)] | 前 N 月 |
| $[yyyyMMdd+7*N] | 后 N 周 |
| $[yyyyMMdd-7*N] | 前 N 周 |
| $[yyyyMMdd+N] | 后 N 天 |
| $[yyyyMMdd-N] | 前 N 天 |
| $[HHmmss+N/24] | 后 N 小时 |
| $[HHmmss-N/24] | 前 N 小时 |
| $[HHmmss+N/24/60] | 后 N 分钟 |
| $[HHmmss-N/24/60] | 前 N 分钟 |
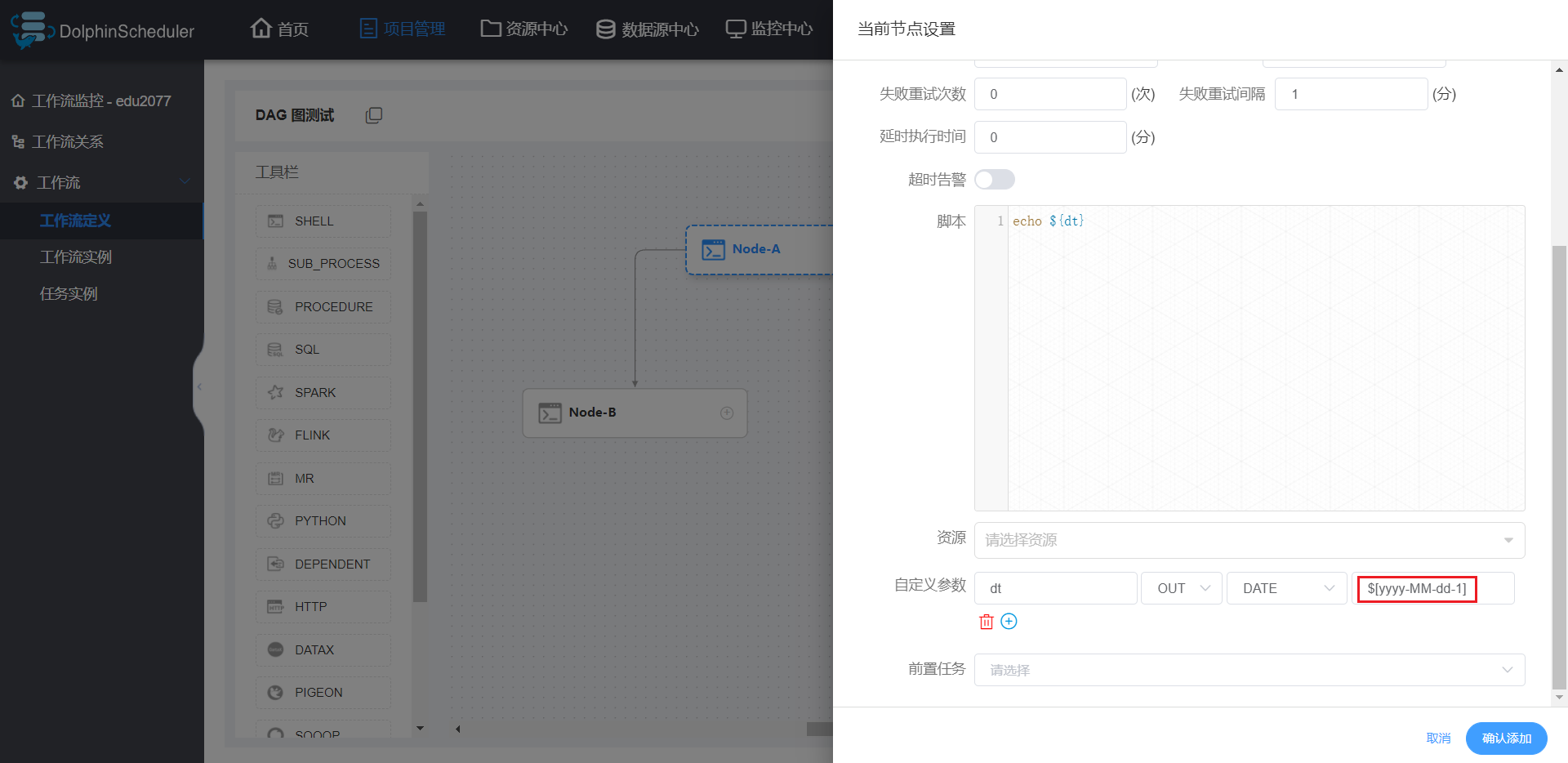
相关说明
- dt:参数名
- IN:IN 表示局部参数仅能在当前节点使用,OUT 表示局部参数可以向下游传递(目前支持这个特性的任务类型有:Shell、SQL、Procedure;同时若节点之间没有依赖关系,则局部参数无法传递)
- DATE:数据类型,日期
- $[yyyy-MM-dd]:自定义格式的衍生内置参数
全局参数在工作流定义,本地参数在节点定义,本地参数 > 全局参数 > 上游任务传递的参数
1.2 参数传递
- 本地参数 > 全局参数 > 上游任务传递的参数;
- 多个上游节点均传递同名参数时,下游节点会优先使用值为非空的参数;
- 如果存在多个值为非空的参数,则按照上游任务的完成时间排序,选择完成时间最早的上游任务对应的参数。
2、引用依赖资源
有些任务需要引用一些额外的资源,例如MR、Spark等任务须引用jar包,Shell任务需要引用其他脚本等。DolphinScheduler提供了资源中心来对这些资源进行统一管理。
如果需要用到资源上传功能,针对单机可以选择本地文件目录作为上传文件夹(此操作不需要部署 Hadoop)。当然也可以选择上传到 Hadoop or MinIO 集群上,此时则需要有Hadoop (2.6+) 或者 MinIO 等相关环境。本文在部署 DS 集群时指定了文件系统为 HDFS
https://dolphinscheduler.apache.org/zh-cn/docs/2.0.3/guide/resource
3、数据源配置
https://dolphinscheduler.apache.org/zh-cn/docs/2.0.3/功能介绍_menu/数据源中心_menu
数据源中心支持MySQL、POSTGRESQL、HIVE/IMPALA、SPARK、CLICKHOUSE、ORACLE、SQLSERVER等数据源。此处仅对 HIVE 数据源进行介绍
- 数据源:选择HIVE
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述,可置空
- IP/主机名:输入连接HIVE的IP
- 端口:输入连接HIVE的端口,默认 10000
- 用户名:设置连接HIVE的用户名,如果没有配置 HIVE 权限管理,则用户名可以任意,但 HIVE 表数据存储在 HDFS,为了保证对所有表的数据均有操作权限,此处选择 HDFS 超级用户 atguigu(注:HDFS 超级用户名与执行 HDFS 启动命令的 Linux 节点用户名相同)
- 密码:设置连接HIVE的密码,如果没有配置 HIVE 权限管理,则密码置空即可
- 数据库名:输入连接HIVE的数据库名称
- Jdbc连接参数:用于HIVE连接的参数设置,以JSON形式填写,没有参数可置空
然后在工作流中可以选择SQL

- 节点名称:自定义节点名称
- 环境名称:HIVE 执行所需环境
- 数据源:类型选择 HIVE,数据源选择上文配置的 HIVE 数据源
- SQL 类型:根据SQL 语句选择,此处选用默认的“查询”即可
- SQL 语句:要执行的 SQL 语句,末尾不能有分号,否则报错:语法错误
4、告警实例配置
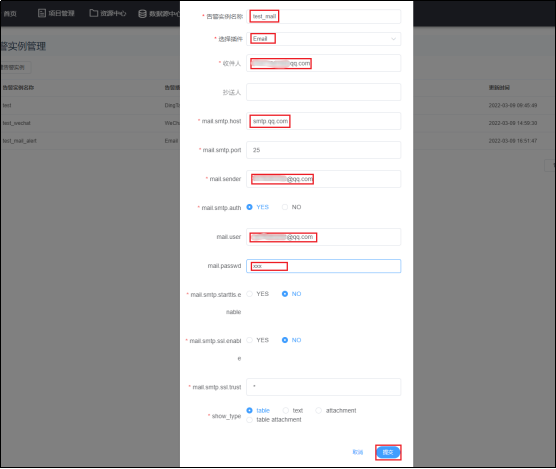
4.1 邮箱告警实例配置
POP3,IMAP,SMTP描述
需要登陆管理员账户
- 告警实例名称:在告警组配置时可以选择的告警插件实例名称,用户自定义
- 选择插件:选择 Email 则为邮箱告警实例
- 收件人:接收方邮箱地址,收件人不需要开启 SMTP 服务
- 抄送人:抄送是指用户给收件人发出邮件的同时把该邮件发送给另外的人,收件人之外的收件方都是抄送人,“收件人”可以获知该邮件的所有抄送人;抄送人可以为空。
- mail.smtp.host:邮箱的 SMTP 服务器域名,对于 QQ 邮箱,为 smtp.qq.com。各邮箱的 SMTP 服务器见此链接:https://blog.csdn.net/wustzjf/article/details/52481309
- mail.smtp.port:邮箱的 SMTP 服务端口号,主流邮箱均为 25 端口,使用默认值即可
- mail.sender:发件方邮箱地址,需要开启 SMTP 服务
- mail.user:与 mail.sender 保持一致即可
- mail.password:获取的邮箱授权码。未列出的选项保留默认值或默认选项即可
4.2 其他告警
其他告警可以参考:https://dolphinscheduler.apache.org/zh-cn/docs/3.0.0
同时还可以电话告警,这里有个运维平台是一站式集成的,睿象云官网:https://www.aiops.com/
5、其他注意事项
DolphinScheduler的环境变量是不和主机共享的,默认需要进入/opt/module/dolphinscheduler/conf/env/dolphinscheduler_env.sh进行修改,也可以直接在admin用户下在可视化界面进行创建,创建节点的时候选择即可
三、Airflow
1、Airflow基本概念
官方网站:https://airflow.apache.org
1.1 概述
Airflow是一个以编程方式编写,安排和监视工作流的平台。使用Airflow将工作流编写任务的有向无环图(DAG)。Airflow计划程序在遵循指定的依赖项,同时在一组工作线程上执行任务。丰富的命令实用程序使在DAG上执行复杂的调度变的轻而易举。丰富的用户界面使查看生产中正在运行的管道,监视进度以及需要时对问题进行故障排除变的容易
1.2 名词解释
- Dynamic:Airflow配置需要实用Python,允许动态生产管道。这允许编写可动态。这允许编写可动态实例化管道的代码
- Extensible:轻松定义自己的运算符,执行程序并扩展库,使其适合于您的环境
- Elegant:Airlfow是精简的,使用功能强大的Jinja模板引擎,将脚本参数化内置于Airflow的核心中
- Scalable:Airflow具有模板块架构,并使用消息队列来安排任意数量的工作任务
2、Airflow安装
2.1 python环境安装
# Superset是由Python语言编写的Web应用,要求Python3.8的环境
# 这里使用MiniConda作为包管理器
# 下载地址:https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
# 加载环境变量配置文件,使之生效
source ~/.bashrc
# Miniconda安装完成后,每次打开终端都会激活其默认的base环境,我们可通过以下命令,禁止激活默认base环境
conda config --set auto_activate_base false# 配置conda国内镜像
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --set show_channel_urls yes
# 创建Python3.8环境
conda create --name airflow python=3.8
# 创建环境:conda create -n env_name
# 查看所有环境:conda info --envs
# 删除一个环境:conda remove -n env_name --all
# 激活airflow环境
conda activate airflow
# 执行python -V命令查看python版本
python -V2.2 安装Airflow
conda activate airflow
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
sudo mkdir ~/.pip
sudo vim ~/.pip/pip.conf
#添加以下内容
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host = https://pypi.tuna.tsinghua.edu.cn
# 安装airflow
pip install "apache-airflow==2.4.3"
# 初始化airflow
airflow db init
# 查看版本
airflow version
# airflow安装好存放路径
pwd
# 启动airflow web服务,启动后浏览器访问http://hadoop102:8081
airflow webserver -p 8081 -D
# 启动airflow调度
airflow scheduler -D
# 创建账号
airflow users create \
--username admin \
--firstname atguigu \
--lastname atguigu \
--role Admin \
--email shawn@atguigu.com# 启动停止脚本
vim af.sh
#!/bin/bashcase $1 in
"start"){echo " --------启动 airflow-------"ssh hadoop102 "conda activate airflow;airflow webserver -p 8081 -D;airflow scheduler -D; conda deactivate"
};;
"stop"){echo " --------关闭 airflow-------"ps -ef|egrep 'scheduler|airflow-webserver'|grep -v grep|awk '{print $2}'|xargs kill -15
};;
esac# 添加权限即可使用
chmod +x af.sh3、修改数据库与调度器
3.1 修改数据库为mysql
# https://airflow.apache.org/docs/apache-airflow/2.4.3/howto/set-up-database.html#setting-up-a-mysql-database
# 在MySQL中建库
CREATE DATABASE airflow_db CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
# 如果报错Linux error:1425F102:SSL routines:ssl_choose_client_version:unsupported protocol,可以关闭MySQL的SSL证书
SHOW VARIABLES LIKE '%ssl%';
# 修改配置文件my.cnf,加入以下内容
# disable_ssl
skip_ssl# 添加python连接的依赖:
pip install mysql-connector-python
# 修改airflow的配置文件
vim ~/airflow/airflow.cfg
[database]
# The SqlAlchemy connection string to the metadata database.
# SqlAlchemy supports many different database engines.
# More information here:
# http://airflow.apache.org/docs/apache-airflow/stable/howto/set-up-database.html#database-uri
#sql_alchemy_conn = sqlite:home/atguigu/airflow/airflow.db
sql_alchemy_conn = mysql+mysqlconnector://root:123456@hadoop102:3306/airflow_db# 关闭airflow,初始化后重启
af.sh stop
airflow db init
# 初始化报错1067 - Invalid default value for ‘update_at’
# 原因:字段 'update_at' 为 timestamp类型,取值范围是:1970-01-01 00:00:00 到 2037-12-31 23:59:59(UTC +8 北京时间从1970-01-01 08:00:00 开始),而这里默认给了空值,所以导致失败
set GLOBAL sql_mode='STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
# 重启MySQL会造成参数失效,推荐将参数写入到配置文件my.cnf中
sql_mode = STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
# 重启
af.sh start# 重新创建账号登录
airflow users create \
--username admin \
--firstname atguigu \
--lastname atguigu \
--role Admin \
--email shawn@atguigu.com3.2 修改执行器
官网不推荐在开发中使用顺序执行器,会造成任务调度阻塞
# 修改airflow的配置文件
[core]
# The executor class that airflow should use. Choices include
# ``SequentialExecutor``, ``LocalExecutor``, ``CeleryExecutor``, ``DaskExecutor``,
# ``KubernetesExecutor``, ``CeleryKubernetesExecutor`` or the
# full import path to the class when using a custom executor.
executor = LocalExecutor# dags_folder是保存文件位置
4、部署使用
文档:https://airflow.apache.org/docs/apache-airflow/2.4.3/howto/index.html
4.1 环境部署启动
# 需要启动hadoop和spark的历史服务器
# 编写.py脚本,创建work-py目录用于存放python调度脚本
mkdir ~/airflow/dags
cd dags/
vim test.py编写脚本
#!/usr/bin/python
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime, timedeltadefault_args = {# 用户'owner': 'test_owner',# 是否开启任务依赖'depends_on_past': True, # 邮箱'email': ['403627000@qq.com'],# 启动时间'start_date':datetime(2022,11,28),# 出错是否发邮件报警'email_on_failure': False,# 重试是否发邮件报警'email_on_retry': False,# 重试次数'retries': 1,# 重试时间间隔'retry_delay': timedelta(minutes=5),
}
# 声明任务图
dag = DAG('test', default_args=default_args, schedule_interval=timedelta(days=1))# 创建单个任务
t1 = BashOperator(# 任务idtask_id='dwd',# 任务命令bash_command='ssh hadoop102 "/opt/module/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.1.3.jar 10 "',# 重试次数retries=3,# 把任务添加进图中dag=dag)t2 = BashOperator(task_id='dws',bash_command='ssh hadoop102 "/opt/module/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.1.3.jar 10 "',retries=3,dag=dag)t3 = BashOperator(task_id='ads',bash_command='ssh hadoop102 "/opt/module/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.1.3.jar 10 "',retries=3,dag=dag)# 设置任务依赖
t2.set_upstream(t1)
t3.set_upstream(t2)
注意一些注意事项
-
必须导包
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
-
default_args 设置默认参数
-
depends_on_past 是否开启任务依赖
-
schedule_interval 调度频率
-
retries 重试次数
-
start_date 开始时间
-
BashOperator 具体执行任务,如果为true前置任务必须成功完成才会走下一个依赖任务,如果为false则忽略是否成功完成
-
task_id 任务唯一标识(必填)
-
bash_command 具体任务执行命令
-
set_upstream 设置依赖
4.2 Dag任务操作
# 过段时间会加载
airflow dags list
# 查看所有任务
airflow list_dags
# 查看单个任务
airflow tasks list test --tree
# 如果删除的话需要UI和底层都删除才行
4.3 配置邮件服务器
修改airflow配置文件,用stmps服务对应587端口,
vim ~/airflow/airflow.cfg
smtp_host = smtp.qq.com
smtp_starttls = True
smtp_ssl = False
smtp_user = xx@qq.com
# smtp_user =
smtp_password = qluxdbuhgrhgbigi
# smtp_password =
smtp_port = 587
smtp_mail_from = xx@qq.com# 然后重启
af.sh stop
af.sh star
# 编辑test.py脚本,并且替换
#!/usr/bin/python
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.operators.email_operator import EmailOperator
from datetime import datetime, timedeltadefault_args = {# 用户'owner': 'test_owner',# 是否开启任务依赖'depends_on_past': True, # 邮箱'email': ['xx@qq.com'],# 启动时间'start_date':datetime(2022,11,28),# 出错是否发邮件报警'email_on_failure': False,# 重试是否发邮件报警'email_on_retry': False,# 重试次数'retries': 1,# 重试时间间隔'retry_delay': timedelta(minutes=5),
}
# 声明任务图
dag = DAG('test', default_args=default_args, schedule_interval=timedelta(days=1))# 创建单个任务
t1 = BashOperator(# 任务idtask_id='dwd',# 任务命令bash_command='ssh hadoop102 "/opt/module/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.1.3.jar 10 "',# 重试次数retries=3,# 把任务添加进图中dag=dag)t2 = BashOperator(task_id='dws',bash_command='ssh hadoop102 "/opt/module/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.1.3.jar 10 "',retries=3,dag=dag)t3 = BashOperator(task_id='ads',bash_command='ssh hadoop102 "/opt/module/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.1.3.jar 10 "',retries=3,dag=dag)email=EmailOperator(task_id="email",to="yaohm163@163.com ",subject="test-subject",html_content="<h1>test-content</h1>",cc="xx@qq.com ",dag=dag)t2.set_upstream(t1)
t3.set_upstream(t2)
email.set_upstream(t3)
四、Azkaban
azkaban官网:https://azkaban.github.io/downloads.html
1、Azkaban入门
1.1 上传jar包和配置sql
首先获取azkaban的三个包,可以自行编译,github地址
# https://pan.baidu.com/s/10zD2Y_h0oB_rC-BAjLal1g%C2%A0 密码:zsxa
# 将azkaban-db-3.84.4.tar.gz,azkaban-exec-server-3.84.4.tar.gz,azkaban-web-server-3.84.4.tar.gz上传到hadoop102的/opt/software路径
# 新建/opt/module/azkaban目录,并将所有tar包解压到这个目录下
mkdir /opt/module/azkaban
# 解压
tar -zxvf azkaban-db-3.84.4.tar.gz -C /opt/module/azkaban/
tar -zxvf azkaban-exec-server-3.84.4.tar.gz -C /opt/module/azkaban/
tar -zxvf azkaban-web-server-3.84.4.tar.gz -C /opt/module/azkaban/
# 进入到/opt/module/azkaban目录,依次修改名称
mv azkaban-exec-server-3.84.4/ azkaban-exec
mv azkaban-web-server-3.84.4/ azkaban-web# ==============然后配置mysql=====================
mysql -uroot -p123456
# 登陆MySQL,创建Azkaban数据库
create database azkaban;
# 创建azkaban用户并赋予权限
set global validate_password_length=4;
set global validate_password_policy=0;
CREATE USER 'azkaban'@'%' IDENTIFIED BY '000000';
# 赋予Azkaban用户增删改查权限
GRANT SELECT,INSERT,UPDATE,DELETE ON azkaban.* to 'azkaban'@'%' WITH GRANT OPTION;
# 创建Azkaban表,完成后退出MySQL
use azkaban;
source /opt/module/azkaban/azkaban-db-3.84.4/create-all-sql-3.84.4.sql
quit;# 更改MySQL包大小;防止Azkaban连接MySQL阻塞
sudo vim /etc/my.cnf
# 在[mysqld]下面加一行max_allowed_packet=1024M
[mysqld]
max_allowed_packet=1024M
# 重启MySQL
sudo systemctl restart mysqld1.2 配置Executor Server
Azkaban Executor Server处理工作流和作业的实际执行
# 编辑azkaban.properties
vim /opt/module/azkaban/azkaban-exec/conf/azkaban.properties
# 修改如下属性
#...
default.timezone.id=Asia/Shanghai
#...
azkaban.webserver.url=http://hadoop102:8081executor.port=12321
#...
database.type=mysql
mysql.port=3306
mysql.host=hadoop102
mysql.database=azkaban
mysql.user=azkaban
mysql.password=000000
mysql.numconnections=100# 同步azkaban-exec到所有节点
xsync /opt/module/azkaban/azkaban-exec
# 必须进入到/opt/module/azkaban/azkaban-exec路径,分别在三台机器上,启动executor server
bin/start-exec.sh
bin/start-exec.sh
bin/start-exec.sh
# 注意:如果在/opt/module/azkaban/azkaban-exec目录下出现executor.port文件,说明启动成功
# 下面激活executor,需要分别在三台机器依次执行
curl -G "hadoop102:12321/executor?action=activate" && echo
curl -G "hadoop103:12321/executor?action=activate" && echo
curl -G "hadoop104:12321/executor?action=activate" && echo
# 如果三台机器都出现如下提示,则表示激活成功
{"status":"success"}1.3 配置Web Server
Azkaban Web Server处理项目管理,身份验证,计划和执行触发
# 编辑azkaban.properties
vim /opt/module/azkaban/azkaban-web/conf/azkaban.properties
# 修改如下属性
...
default.timezone.id=Asia/Shanghai
...
database.type=mysql
mysql.port=3306
mysql.host=hadoop102
mysql.database=azkaban
mysql.user=azkaban
mysql.password=000000
mysql.numconnections=100
...
azkaban.executorselector.filters=StaticRemainingFlowSize,CpuStatus# 说明:
# StaticRemainingFlowSize:正在排队的任务数;
# CpuStatus:CPU占用情况
# MinimumFreeMemory:内存占用情况。测试环境,必须将MinimumFreeMemory删除掉,否则它会认为集群资源不够,不执行。# 修改azkaban-users.xml文件,添加atguigu用户
vim /opt/module/azkaban/azkaban-web/conf/azkaban-users.xml
<azkaban-users><user groups="azkaban" password="azkaban" roles="admin" username="azkaban"/><user password="metrics" roles="metrics" username="metrics"/><user password="atguigu" roles="admin" username="atguigu"/><role name="admin" permissions="ADMIN"/><role name="metrics" permissions="METRICS"/>
</azkaban-users># 必须进入到hadoop102的/opt/module/azkaban/azkaban-web路径,启动web server
bin/start-web.sh
# 访问http://hadoop102:8081,并用atguigu用户登陆2、Work Flow案例实操
2.1 HelloWorld案例
# 在windows环境,新建azkaban.project文件,编辑内容如下
# 注意:该文件作用,是采用新的Flow-API方式解析flow文件
azkaban-flow-version: 2.0
# 新建basic.flow文件,内容如下
nodes:- name: jobAtype: commandconfig:command: echo "Hello World"# Name:job名称
# Type:job类型。command表示你要执行作业的方式为命令
# Config:job配置# 将azkaban.project、basic.flow文件压缩到一个zip文件,文件名称必须是英文
# 在WebServer新建项目:http://hadoop102:8081/index
# 然后上传压缩文件,执行,查看日志2.2 作业依赖案例
需求:JobA和JobB执行完了,才能执行JobC
# 修改basic.flow为如下内容
nodes:- name: jobCtype: command# jobC 依赖 JobA和JobBdependsOn:- jobA- jobBconfig:command: echo "I’m JobC"- name: jobAtype: commandconfig:command: echo "I’m JobA"- name: jobBtype: commandconfig:command: echo "I’m JobB"2.3 自动失败重试案例
需求:如果执行任务失败,需要重试3次,重试的时间间隔10000ms
nodes:- name: JobAtype: commandconfig:command: sh /not_exists.shretries: 3retry.backoff: 10000
也可以在Flow全局配置中添加任务失败重试配置,此时重试配置会应用到所有Job
config:retries: 3retry.backoff: 10000
nodes:- name: JobAtype: commandconfig:command: sh /not_exists.sh
2.4 手动失败重试案例
需求:JobA⇒JobB(依赖于A)⇒JobC⇒JobD⇒JobE⇒JobF。生产环境,任何Job都有可能挂掉,可以根据需求执行想要执行的Job。
nodes:- name: JobAtype: commandconfig:command: echo "This is JobA."- name: JobBtype: commanddependsOn:- JobAconfig:command: echo "This is JobB."- name: JobCtype: commanddependsOn:- JobBconfig:command: echo "This is JobC."- name: JobDtype: commanddependsOn:- JobCconfig:command: echo "This is JobD."- name: JobEtype: commanddependsOn:- JobDconfig:command: echo "This is JobE."- name: JobFtype: commanddependsOn:- JobEconfig:command: echo "This is JobF."
在可视化界面,Enable和Disable下面都分别有如下参数:
- Parents:该作业的上一个任务
- Ancestors:该作业前的所有任务
- Children:该作业后的一个任务
- Descendents:该作业后的所有任务
- Enable All:所有的任务
3、JavaProcess作业类型案例
3.1 概述
JavaProcess类型可以运行一个自定义主类方法,type类型为javaprocess,可用的配置为:
- Xms:最小堆
- Xmx:最大堆
- classpath:类路径
- java.class:要运行的Java对象,其中必须包含Main方法
- main.args:main方法的参数
3.2 案例
新建一个azkaban的maven工程,然后创建包名:com.atguigu,创建AzTest类
package com.atguigu;public class AzTest {public static void main(String[] args) {System.out.println("This is for testing!");}
}
打包成jar包azkaban-1.0-SNAPSHOT.jar,新建testJava.flow,内容如下
nodes:- name: test_javatype: javaprocessconfig:Xms: 96MXmx: 200Mjava.class: com.atguigu.AzTest
**将Jar包、flow文件和project文件打包成javatest.zip **,然后上传执行
4、条件工作流案例
4.1 概述
条件工作流功能允许用户自定义执行条件来决定是否运行某些Job。条件可以由当前Job的父Job输出的运行时参数构成,也可以使用预定义宏。在这些条件下,用户可以在确定Job执行逻辑时获得更大的灵活性,例如,只要父Job之一成功,就可以运行当前Job
4.2 运行时参数案例
基本原理:父Job将参数写入JOB_OUTPUT_PROP_FILE环境变量所指向的文件;子Job使用 ${jobName:param}来获取父Job输出的参数并定义执行条件
支持的条件运算符:
(1)== 等于
(2)!= 不等于
(3)> 大于
(4)>= 大于等于
(5)< 小于
(6)<= 小于等于
(7)&& 与
(8)|| 或
(9)! 非
需求分析:
# JobA执行一个shell脚本。
# JobB执行一个shell脚本,但JobB不需要每天都执行,而只需要每个周一执行# 新建JobA.sh
#!/bin/bash
echo "do JobA"
wk=`date +%w`
echo "{\"wk\":$wk}" > $JOB_OUTPUT_PROP_FILE# 新建JobB.sh
#!/bin/bash
echo "do JobB"# 新建condition.flow
nodes:- name: JobAtype: commandconfig:command: sh JobA.sh- name: JobBtype: commanddependsOn:- JobAconfig:command: sh JobB.shcondition: ${JobA:wk} == 1# 最后将JobA.sh、JobB.sh、condition.flow和azkaban.project打包成condition.zip
4.3 预定义宏案例
Azkaban中预置了几个特殊的判断条件,称为预定义宏。预定义宏会根据所有父Job的完成情况进行判断,再决定是否执行。可用的预定义宏如下:
(1)all_success: 表示父Job全部成功才执行(默认)
(2)all_done:表示父Job全部完成才执行
(3)all_failed:表示父Job全部失败才执行
(4)one_success:表示父Job至少一个成功才执行
(5)one_failed:表示父Job至少一个失败才执行
# 需求
# JobA执行一个shell脚本
# JobB执行一个shell脚本
# JobC执行一个shell脚本,要求JobA、JobB中有一个成功即可执行# 新建JobA.sh
#!/bin/bash
echo "do JobA"# 新建JobC.sh
#!/bin/bash
echo "do JobC"# 新建macro.flow
nodes:- name: JobAtype: commandconfig:command: sh JobA.sh- name: JobBtype: commandconfig:command: sh JobB.sh- name: JobCtype: commanddependsOn:- JobA- JobBconfig:command: sh JobC.shcondition: one_success5、邮箱告警
首先申请好邮箱,然后配置
# 在azkaban-web节点hadoop102上,编辑/opt/module/azkaban/azkaban-web/conf/azkaban.properties,修改如下内容
vim /opt/module/azkaban/azkaban-web/conf/azkaban.properties
# 添加如下内容:
#这里设置邮件发送服务器,需要 申请邮箱,切开通stmp服务,以下只是例子
mail.sender=atguigu@126.com
mail.host=smtp.126.com
mail.user=atguigu@126.com
mail.password=用邮箱的授权码# 保存并重启web-server
bin/shutdown-web.sh
bin/start-web.sh# 编辑basic.flow
nodes:- name: jobAtype: commandconfig:command: echo "This is an email test."# 将azkaban.project和basic.flow压缩成email.zip
# 然后上传,在可视化页面里选择邮箱告警
# 针对电话告警,可以使用睿象云,https://www.aiops.com/
6、Azkaban多Executor模式注意事项
Azkaban多Executor模式是指,在集群中多个节点部署Executor。在这种模式下, Azkaban web Server会根据策略,选取其中一个Executor去执行任务。为确保所选的Executor能够准确的执行任务,我们须在以下两种方案任选其一,推荐使用方案二。
方案一:指定特定的Executor(hadoop102)去执行任务
# 在MySQL中azkaban数据库executors表中,查询hadoop102上的Executor的idmysql> use azkaban;
mysql> select * from executors;# 在执行工作流程时选择Flow Parameters加入useExecutor属性
方案二:在Executor所在所有节点部署任务所需脚本和应用
官网文档:https://azkaban.readthedocs.io/en/latest/configuration.html

LAMMPS 的输出)











)
——组件注册)
--语法入门)
![DataX自动化生成配置json,创建ODS表,多线程调度脚本[mysql-->hive]](http://pic.xiahunao.cn/DataX自动化生成配置json,创建ODS表,多线程调度脚本[mysql-->hive])


