MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images
MVSplat:稀疏多视点图像的高效3D高斯溅射
粤东陈浩飞徐 2,3 郑传霞 4 庄伯涵1
Marc Pollefeys2,5 Andreas Geiger3 Tat-Jen Cham6 Jianfei Cai
Marc Pollefeys 2,5 Andreas盖革 3 Tat-Jen Cham 6 蔡剑飞1
Abstract 摘要 MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images
We propose MVSplat, an efficient feed-forward 3D Gaussian Splatting model learned from sparse multi-view images. To accurately localize the Gaussian centers, we propose to build a cost volume representation via plane sweeping in the 3D space, where the cross-view feature similarities stored in the cost volume can provide valuable geometry cues to the estimation of depth. We learn the Gaussian primitives’ opacities, covariances, and spherical harmonics coefficients jointly with the Gaussian centers while only relying on photometric supervision. We demonstrate the importance of the cost volume representation in learning feed-forward Gaussian Splatting models via extensive experimental evaluations. On the large-scale RealEstate10K and ACID benchmarks, our model achieves state-of-the-art performance with the fastest feed-forward inference speed (22 fps). Compared to the latest state-of-the-art method pixelSplat, our model uses 10× fewer parameters and infers more than 2× faster while providing higher appearance and geometry quality as well as better cross-dataset generalization.
我们提出了MVSplat,这是一种从稀疏多视图图像中学习的高效前馈3D高斯溅射模型。为了准确地定位高斯中心,我们建议通过在3D空间中进行平面扫描来构建成本体积表示,其中存储在成本体积中的跨视图特征相似性可以为深度估计提供有价值的几何线索。我们学习高斯基元的不透明度,协方差和球谐系数联合高斯中心,而只依赖于光度监督。我们通过大量的实验评估证明了成本体积表示在学习前馈高斯溅射模型中的重要性。在大规模RealEstate10K和ACID基准测试中,我们的模型以最快的前馈推理速度(22 fps)实现了最先进的性能。 与最新的最先进的方法pixelSplat相比,我们的模型使用了 10× 更少的参数,推断速度超过 2× ,同时提供了更高的外观和几何质量以及更好的跨数据集泛化。
Keywords:
Feature Matching Cost Volume Gaussian Splatting关键词:特征匹配代价体积高斯溅射
MVSplat
![[Uncaptioned image]](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Farxiv.org%2Fhtml%2F2403.14627v1%2Fx1.png&pos_id=yFatTPXH)
Figure 1: Our MVSplat outperforms pixelSplat [1] in terms of both appearance and geometry quality with 10× fewer parameters and more than 2× faster inference speed.
图一:我们的MVSplat在外观和几何质量方面都优于pixelSplat [ 1],参数更少,推理速度更快。
1Introduction 1介绍
3D scene reconstruction and novel view synthesis from very sparse (i.e., as few as two) images pose a fundamental challenge in computer vision. While remarkable progress has been made using neural scene representations, e.g., Scene Representation Networks (SRN) [25], Neural Radiance Fields (NeRF) [16] and Light Filed Networks (LFN) [24], these methods are still not satisfactory for practical applications due to expensive per-scene optimization [18, 29, 32], high memory cost [2, 11, 33] and slow rendering speed [30, 38].
3D场景重建和新的视图合成从非常稀疏(即,少至两个)图像对计算机视觉提出了根本性的挑战。虽然使用神经场景表示已经取得了显著的进展,例如,场景表示网络(SRN)[ 25],神经辐射场(NeRF)[ 16]和光场网络(LFN)[ 24],由于昂贵的每个场景优化[18,29,32],高内存成本[2,11,33]和缓慢的渲染速度[30,38],这些方法对于实际应用仍然不令人满意。
Recently, 3D Gaussian Splatting (3DGS) [12] has emerged as an efficient and expressive 3D representation thanks to its fast rendering speed and high quality. Using rasterization-based rendering, 3DGS inherently avoids the expensive volumetric sampling process of NeRF, leading to highly efficient and high-quality 3D reconstruction and novel view synthesis.
最近,3D高斯飞溅(3DGS)[ 12]由于其快速渲染速度和高质量,已成为一种高效和富有表现力的3D表示。使用基于光栅化的渲染,3DGS本质上避免了NeRF昂贵的体积采样过程,从而实现了高效和高质量的3D重建和新颖的视图合成。
Subsequently, several feed-forward Gaussian Splatting methods have been proposed to explore 3D reconstruction from sparse view images, notably Splatter Image [27] and pixelSplat [1]. Splatter Image regresses pixel-aligned Gaussian parameters from a single view using a U-Net architecture, which achieves promising results for single object 3D reconstruction. However, 3D reconstruction from a single image is inherently ill-posed and ambiguous, which makes it particularly challenging to apply to more general and larger scene-level reconstruction, the key focus of our paper. For general scene reconstruction, pixelSplat [1] proposes to regress Gaussian parameters from two input views. Specifically, pixelSplat predicts a probabilistic depth distribution from features, and then depths are sampled from the learned distribution. Despite pixelSplat learns cross-view-aware features with an epipolar transformer, it is still challenging to predict a reliable probabilistic depth distribution solely from image features, making pixelSplat’s geometry reconstruction of comparably low quality and exhibit noisy artifacts (see Fig. 1 and Fig. 4). For improved geometry reconstruction results, slow depth finetuning with an additional depth regularization loss is required.
随后,提出了几种前馈高斯溅射方法来探索稀疏视图图像的3D重建,特别是Splatter Image [ 27]和pixelSplat [ 1]。Splatter Image使用U-Net架构从单个视图回归像素对齐的高斯参数,从而实现了单目标3D重建的有希望的结果。然而,从单个图像进行3D重建本质上是病态和模糊的,这使得它特别具有挑战性,适用于更一般和更大的场景级重建,我们的论文的重点。对于一般场景重建,pixelSplat [ 1]提出从两个输入视图回归高斯参数。具体来说,pixelSplat从特征中预测概率深度分布,然后从学习的分布中采样深度。 尽管pixelSplat使用极线Transformer学习跨视图感知特征,但仅从图像特征预测可靠的概率深度分布仍然具有挑战性,使得pixelSplat的几何重建质量很低,并表现出噪声伪影(参见图1和图4)。为了改善几何重建结果,需要具有附加深度正则化损失的缓慢深度微调。
To accurately localize the 3D Gaussian centers, we propose to build a cost volume representation via plane sweeping [37, 35] in 3D space. Specifically, the cost volume stores cross-view feature similarities for all potential depth candidates, where the similarities can provide valuable geometry cues to the localization of 3D surfaces (e.g., high similarity more likely indicates a surface point). With our cost volume representation, the task is formulated as learning to perform feature matching to identify the Gaussian centers, unlike the data-driven 3D regression from image features in previous works [27, 1]. Such a formulation reduces the task’s learning difficulty, enabling our method to achieve state-of-the-art performance with lightweight model size and fast speed.
为了准确定位3D高斯中心,我们建议通过3D空间中的平面扫描[37,35]来构建成本体积表示。具体地,成本体积存储所有潜在深度候选的交叉视图特征相似性,其中相似性可以为3D表面的定位提供有价值的几何线索(例如,更高的相似性更可能指示表面点)。通过我们的成本体积表示,该任务被制定为学习执行特征匹配以识别高斯中心,这与之前作品中的图像特征数据驱动的3D回归不同[27,1]。这样的公式降低了任务的学习难度,使我们的方法能够实现最先进的性能与轻量级的模型大小和快速。
We obtain 3D Gaussian centers by unprojecting the multi-view-consistent depths estimated by our constructed multi-view cost volumes with a 2D network. Additionally, we also predict other Gaussian properties (covariance, opacity and spherical harmonics coefficients), in parallel with the depths. This enables the rendering of novel view images using the predicted 3D Gaussians with the differentiable splatting operation [12]. Our full model MVSplat is trained end-to-end purely with the photometric loss between rendered and ground truth images.
我们获得3D高斯中心通过非投影的多视图一致的深度估计我们构建的多视图成本卷与2D网络。此外,我们还预测其他高斯属性(协方差,不透明度和球谐系数),与深度平行。这使得能够使用预测的3D高斯和可微溅射操作来渲染新视图图像[ 12]。我们的完整模型MVSplat是端到端训练的,完全使用渲染图像和地面实况图像之间的光度损失。
On the large-scale RealEstate10K [42] and ACID [14] benchmarks, our cost volume-based method MVSplat achieves state-of-the-art performance with the fastest feed-forward inference speed (22 fps). Compared to the state-of-the-art pixelSplat [1] (see Fig. 1), our model uses 10× fewer parameters and infers more than 2× faster while providing higher appearance and geometry quality as well as better cross-dataset generalization. Extensive ablation studies and analysis underscore the significance of our feature matching-based cost volume design in enabling highly efficient feed-forward 3D Gaussian Splatting models.
在大规模RealEstate10K [ 42]和ACID [ 14]基准测试中,我们基于成本体积的方法MVSplat以最快的前馈推理速度(22 fps)实现了最先进的性能。与最先进的pixelSplat [ 1](见图1)相比,我们的模型使用了 10× 更少的参数,推断速度比 2× 更快,同时提供了更高的外观和几何质量以及更好的跨数据集泛化。广泛的消融研究和分析强调了我们基于特征匹配的成本体积设计在实现高效前馈3D高斯溅射模型方面的重要性。
2Related Work 2相关工作
Sparse View Scene Reconstruction and Synthesis. The original NeRF and 3DGS methods are both designed for very dense views (e.g., 100) as inputs, which can be tedious to capture for real-world applications. Recently, there have been growing interests [18, 29, 2, 3, 33, 1, 32] in scene reconstruction and synthesis from sparse input views (e.g., 2 or 3). Existing sparse view methods can be broadly classified into two categories: per-scene optimization and cross-scene feed-forward inference methods. Per-scene approaches mainly focus on designing effective regularization terms [18, 29, 39, 4, 32] to better constrain the optimization process. However, they are inherently slow at inference time due to the expensive per-scene gradient back-propagation process. In contrast, feed-forward models [38, 2, 3, 33, 1, 27] learn powerful priors from large-scale datasets, so that 3D reconstruction and view synthesis can be achieved via a single feed-forward inference by taking sparse views as inputs, which makes them significantly faster than per-scene optimization methods.
稀疏视图场景重建与合成。原始NeRF和3DGS方法都是针对非常密集的视图(例如,100)作为输入,这对于现实世界的应用程序来说可能是乏味的。最近,人们对从稀疏输入视图(例如,2或3)。现有的稀疏视图方法可以大致分为两类:逐场景优化和跨场景前馈推理方法。每场景方法主要关注设计有效的正则化项[18,29,39,4,32]以更好地约束优化过程。然而,由于昂贵的每场景梯度反向传播过程,它们在推理时固有地慢。 相比之下,前馈模型[38,2,3,33,1,27]从大规模数据集学习强大的先验知识,因此可以通过将稀疏视图作为输入,通过单个前馈推理实现3D重建和视图合成,这使得它们比每个场景的优化方法更快。
Feed-Forward NeRF. pixelNeRF [38] pioneered the paradigm of predicting pixel-aligned features from images for radiance field reconstruction. The performance of feed-forward NeRF models progressively improved with the use of feature matching information [2, 3], Transformers [21, 6, 17] and 3D volume representations [2, 33]. The state-of-the-art feed-forward NeRF model MuRF [33] is based on a target view frustum volume and a (2+1)D CNN for radiance field reconstruction, where the 3D volume and CNN need to be constructed and inferred for every target view. This makes MuRF expensive to train, with comparably slow rendering. Most importantly, all existing feed-forward NeRF models suffer from an expensive per-pixel volume sampling in the rendering process.
前馈NeRF。pixelNeRF [ 38]开创了从辐射场重建图像预测像素对齐特征的范例。前馈NeRF模型的性能随着特征匹配信息[2,3]、变压器[21,6,17]和3D体积表示[2,33]的使用而逐步提高。最先进的前馈NeRF模型MuRF [ 33]基于目标视锥体积和用于辐射场重建的(2+1)D CNN,其中需要为每个目标视图构建和推断3D体积和CNN。这使得MuRF的训练成本很高,渲染速度非常慢。最重要的是,所有现有的前馈NeRF模型都在渲染过程中遭受昂贵的每像素体积采样。
Feed-Forward 3DGS. 3D Gaussian Splatting avoids NeRF’s expensive volume sampling via a rasterization-based splatting approach, where novel views can be rendered very efficiently from a set of 3D Gaussian primitives. Very recently, a few feed-forward 3DGS models have been proposed to solve the sparse view to 3D task. Splatter Image [27] proposes to regress pixel-aligned Gaussian parameters from a single view with a U-Net. However, it mainly focuses on single object reconstruction, while we target a more general setting and larger scenes. pixelSplat [1] proposes to regress Gaussian parameters from two input views, where the epipolar geometry is leveraged to learn cross-view aware features. However, it estimates depth by sampling from a predicted distribution, which is ambiguous and can lead to poor geometry reconstruction. In contrast, we learn to predict depth directly from the feature matching information encoded within a cost volume, which makes it more geometry-aware and leads to a more lightweight model (10× fewer parameters and more than 2× faster) and significantly better geometries. Another related work GPS-Gaussian [41] proposes a feed-forward Gaussian model for the reconstruction of humans, instead of general scenes. It relies on two rectified stereo images to estimate the disparity, while our method works for general unrectified multi-view posed images. During training, GPS-Gaussian requires ground truth depth for supervision, while our model is trained from RGB images alone.
前馈3DGS。3D高斯溅射通过基于栅格化的溅射方法避免了NeRF昂贵的体积采样,其中可以从一组3D高斯基元非常有效地渲染新视图。最近,已经提出了一些前馈3DGS模型来解决稀疏视图到3D任务。Splatter Image [ 27]建议使用U-Net从单个视图回归像素对齐的高斯参数。然而,它主要集中在单个对象重建,而我们的目标是更一般的设置和更大的场景。pixelSplat [ 1]提出从两个输入视图回归高斯参数,其中利用对极几何来学习交叉视图感知特征。然而,它通过从预测分布中采样来估计深度,这是模糊的,并且可能导致不良的几何重建。 相比之下,我们学会了直接从编码在成本卷中的特征匹配信息中预测深度,这使得它更具几何感知性,并导致更轻量级的模型(参数更少,速度超过1#)和更好的几何形状。另一个相关的工作GPS-Gaussian [ 41]提出了一个前馈高斯模型来重建人类,而不是一般的场景。它依赖于两个校正的立体图像来估计视差,而我们的方法适用于一般未校正的多视图图像。在训练过程中,GPS-Gaussian需要地面实况深度进行监督,而我们的模型仅从RGB图像进行训练。
Multi-View Stereo. Multi-View Stereo (MVS) is a classic technique for reconstructing 3D scene structures from 2D images. Despite the conceptual similarity with the well-established MVS reconstruction pipeline [22, 37, 7], our approach possesses unique advantages. Unlike typical MVS methods involving separate depth estimation and point cloud fusion stages, we exploit the unique properties of the 3DGS representation to infer 3D structure in a single step, simply considering the union of the unprojected per-view depth predictions as the global 3D representation. Besides, existing MVS networks [37, 7, 5] are mostly trained with ground truth depth as supervision. In contrast, our model is fully differentiable and does not require ground truth geometry supervision for training, making it more scalable and suitable for in-the-wild scenarios.
多视图立体。多视点立体(MVS)是从二维图像重建三维场景结构的经典技术。尽管与成熟的MVS重建管道[22,37,7]在概念上相似,但我们的方法具有独特的优势。与涉及单独的深度估计和点云融合阶段的典型MVS方法不同,我们利用3DGS表示的独特属性来在单个步骤中推断3D结构,简单地考虑将未投影的每视图深度预测的联合作为全局3D表示。此外,现有的MVS网络[37,7,5]大多使用地面实况深度作为监督进行训练。相比之下,我们的模型是完全可微的,不需要地面真实几何监督进行训练,使其更具可扩展性,适用于野外场景。
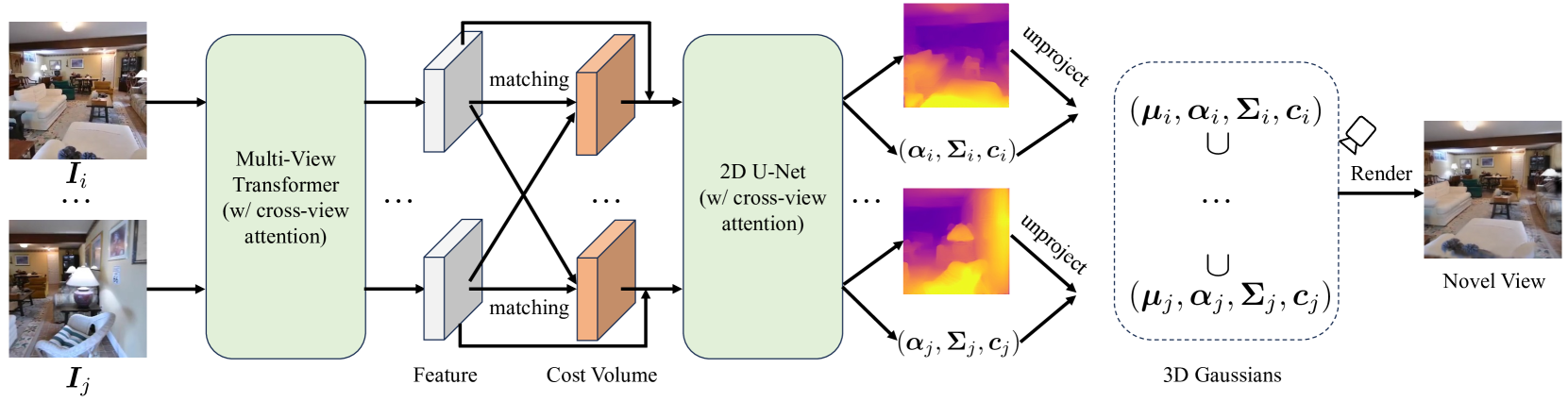
Figure 2:Overview of MVSplat. Given multiple posed images as input, we first extract multi-view image features with a multi-view Transformer, which contains self- and cross-attention layers to exchange information across views. Next, we construct per-view cost volumes using plane sweeping. The Transformer features and cost volumes are concatenated together as input to a 2D U-Net (with cross-view attention) for cost volume refinement and predicting per-view depth maps. The per-view depth maps are unprojected to 3D and combined using a simple deterministic union operation as the 3D Gaussian centers. The opacity, covariance and color Gaussian parameters are predicted jointly with the depth maps. Finally, novel views are rendered from the predicted 3D Gaussians with the splatting operation.
图2:MVSplat概述。给定多个构成的图像作为输入,我们首先提取多视图图像特征与多视图Transformer,其中包含自我和交叉注意层交换信息的意见。接下来,我们使用平面扫描构建每个视图的成本量。将Transformer特征和成本体积连接在一起作为2D U-Net(具有交叉视图注意力)的输入,用于成本体积细化和预测每视图深度图。每视图深度图未投影到3D,并且使用简单的确定性联合操作作为3D高斯中心来组合。不透明度、协方差和颜色高斯参数与深度图联合预测。最后,从预测的3D高斯与飞溅操作渲染新的视图。
3Method 3方法
We begin with � sparse-view images ℐ={𝑰�}�=1�, (𝑰�∈ℝ�×�×3) and their corresponding camera projection matrices 𝒫={𝑷�}�=1�, 𝑷�=𝐊�[𝐑�|𝐭�], calculated via intrinsic 𝐊�, rotation 𝐑� and translation 𝐭� matrices. Our goal is to learn a mapping �𝜽 from images to 3D Gaussian parameters:
我们开始于 � 稀疏视图图像 ℐ={𝑰�}�=1� 、( 𝑰�∈ℝ�×�×3 )及其对应的相机投影矩阵 𝒫={𝑷�}�=1� 、 𝑷�=𝐊�[𝐑�|𝐭�] ,其经由固有矩阵 𝐊� 、旋转矩阵 𝐑� 和平移矩阵 𝐭� 计算。我们的目标是学习从图像到3D高斯参数的映射 �𝜽 :
| �𝜽:{(𝑰�,𝑷�)}�=1�↦{(𝝁�,��,𝚺�,𝒄�)}�=1�×�×�, | (1) |
where we parameterize �𝜽 as a feed-forward network and 𝜽 are the learnable parameters optimized from a large-scale training dataset. We predict the Gaussian parameters, including position 𝝁�, opacity ��, covariance 𝚺� and color 𝒄� (represented as spherical harmonics) in a pixel-aligned manner, and thus the total number of 3D Gaussians is �×�×� for � input images with shape �×�.
其中,我们将 �𝜽 参数化为前馈网络,而 𝜽 是从大规模训练数据集优化的可学习参数。我们以像素对齐的方式预测高斯参数,包括位置 𝝁� 、不透明度 �� 、协方差 𝚺� 和颜色 𝒄� (表示为球谐函数),因此对于具有形状 �×� 的 � 输入图像,3D高斯的总数是 �×�×� 。
To enable high-quality rendering and reconstruction, it is crucial to predict the position 𝝁� precisely since it defines the center of the 3D Gaussian [12]. In this paper, we present MVSplat, a Gaussian-based feed-forward model for novel view synthesis. Unlike pixelSplat [1] that predicts probabilistic depth, we develop an efficient and high-performance multi-view depth estimation model that enables unprojecting predicted depth maps as the Gaussian centers, in parallel with another branch for prediction of other Gaussian parameters (��, 𝚺� and 𝒄�). Our full model, illustrated in Fig. 2, is trained end-to-end using only a simple rendering loss for supervision. Next, we discuss key components.
为了实现高质量的渲染和重建,精确预测位置 𝝁� 至关重要,因为它定义了3D高斯的中心[ 12]。在本文中,我们提出了MVSplat,一个基于高斯的前馈模型的新颖的视图合成。与预测概率深度的pixelSplat [ 1]不同,我们开发了一种高效且高性能的多视图深度估计模型,该模型能够将未投影的预测深度图作为高斯中心,与用于预测其他高斯参数( �� , 𝚺� 和 𝒄� )的另一个分支并行。我们的完整模型(如图2所示)是端到端训练的,只使用简单的渲染损失进行监督。接下来,我们讨论关键组件。
3.1Multi-View Depth Estimation
3.1多视点深度估计
Our depth model is purely based on 2D convolutions and attentions, without any 3D convolutions used in many previous MVS [37, 7, 5] and feed-forward NeRF [2, 33] models. This makes our model highly efficient. Our depth model includes multi-view feature extraction, cost volume construction, cost volume refinement, depth estimation, and depth refinement, as introduced next.
我们的深度模型纯粹基于2D卷积和注意力,没有任何在许多以前的MVS [37,7,5]和前馈NeRF [2,33]模型中使用的3D卷积。这使得我们的模型非常有效。我们的深度模型包括多视图特征提取、成本体积构建、成本体积细化、深度估计和深度细化,如下面所介绍的。
Multi-view feature extraction. To construct the cost volumes, we first extract multi-view image features with a CNN and Transformer architecture [34, 35]. More specifically, a shallow ResNet-like CNN is first used to extract 4× downsampled per-view image features, and then we use a multi-view Transformer with self- and cross-attention layers to exchange information between different views. For better efficiency, we use Swin Transformer’s local window attention [15] in our Transformer architecture. When more than two views are available, we perform cross-attention for each view with respect to all the other views, which has exactly the same learnable parameters as the 2-view scenario. After this operation, we obtain cross-view aware Transformer features {𝑭�}�=1� (𝑭�∈ℝ�4×�4×�), where � denotes the channel dimension.
多视图特征提取。为了构建成本卷,我们首先使用CNN和Transformer架构提取多视图图像特征[34,35]。更具体地说,首先使用一个类似于浅ResNet的CNN来提取 4× 下采样的每视图图像特征,然后我们使用一个具有自我和交叉注意层的多视图Transformer来在不同视图之间交换信息。为了提高效率,我们在Transformer架构中使用Swin Transformer的本地窗口注意力[ 15]。当有两个以上的视图可用时,我们对每个视图相对于所有其他视图执行交叉注意,这与2视图场景具有完全相同的可学习参数。在此操作之后,我们获得交叉视图感知的Transformer特征 {𝑭�}�=1� ( 𝑭�∈ℝ�4×�4×� ),其中 � 表示通道维度。
Cost volume construction. An important component of our model is the cost volume, which models cross-view feature matching information with respect to different depth candidates via the plane-sweep stereo approach [37, 35]. Note that we construct � cost volumes for � input views to predict � depth maps. Here, we take view �’s cost volume construction as an example. Given the near and far depth ranges, we first uniformly sample � depth candidates {��}�=1� in the inverse depth domain and then warp view �’s feature 𝑭� to view � with the camera projection matrices 𝑷�, 𝑷� and each depth candidate ��, to obtain � warped features
建造成本量。我们模型的一个重要组成部分是成本体积,它通过平面扫描立体方法[ 37,35]对不同深度候选者的跨视图特征匹配信息进行建模。请注意,我们为 � 输入视图构建 � 成本量以预测 � 深度图。在此,我们以3#视图的成本量构建为例。给定近和远深度范围,我们首先在逆深度域中对 � 深度候选 {��}�=1� 进行均匀采样,然后利用相机投影矩阵 𝑷� 、 𝑷� 和每个深度候选 �� 将视图 � 的特征 𝑭� 扭曲到视图 � ,以获得 � 扭曲特征
| 𝑭���→�=𝒲(𝑭�,𝑷�,𝑷�,��)∈ℝ�4×�4×�,�=1,2,⋯,�, | (2) |
where 𝒲 denotes the warping operation [35]. We then compute the dot product [36, 35] between 𝑭� and 𝑭���→� to obtain the correlation
其中 𝒲 表示扭曲操作[ 35]。然后,我们计算 𝑭� 和 𝑭���→� 之间的点积[ 36,35]以获得相关性
| 𝑪���=𝑭�⋅𝑭���→��∈ℝ�4×�4,�=1,2,⋯,�. | (3) |
When there are more than two views as inputs, we similarly warp another view’s feature to view � as in Eq. 2 and compute their correlations via Eq. 3. Finally, all the correlations are pixel-wise averaged, enabling the model to accept an arbitrary number of views as inputs.
当有两个以上的视图作为输入时,我们类似地将另一个视图的特征扭曲到视图 � ,如等式2所示。2并通过等式计算它们的相关性。3.最后,所有的相关性都是逐像素平均的,使模型能够接受任意数量的视图作为输入。
Collecting all the correlations we obtain view �’s cost volume
收集所有相关性,我们获得视图 � 的成本量
| 𝑪�=[𝑪�1�,𝑪�2�,⋯,𝑪���]∈ℝ�4×�4×�. | (4) |
Overall, we obtain � cost volumes {𝑪�}�=1� for � input views.
总的来说,我们为 � 输入视图获得 � 成本卷 {𝑪�}�=1� 。
Cost volume refinement. As the cost volume in Eq. 4 can be ambiguous for texture-less regions, we propose to further refine it with an additional lightweight 2D U-Net [20, 19]. The U-Net takes the concatenation of Transformer features 𝑭� and cost volume 𝑪� as inputs, and outputs a residual Δ𝑪�∈ℝ�4×�4×� that is added to the initial cost volume 𝑪�. We obtain the refined cost volume as
成本量细化。作为Eq中的成本量。4对于纹理较少的区域可能是模糊的,我们建议使用额外的轻量级2D U-Net [ 20,19]进一步完善它。U-Net将Transformer特征 𝑭� 和成本量 𝑪� 的级联作为输入,并输出残差 Δ𝑪�∈ℝ�4×�4×� ,该残差被添加到初始成本量 𝑪� 。我们得到精确的成本量为
| 𝑪~�=𝑪�+Δ𝑪�∈ℝ�4×�4×�. | (5) |
To exchange information between cost volumes of different views, we inject three cross-view attention layers at the lowest resolution of the U-Net architecture. The cross-view attention layers are able to accept arbitrary number of views as input since it computes the cross-attention for each view with respect to all the other views, where such an operation does not depend on the number of views. The low-resolution cost volume 𝑪~� is finally upsampled to full resolution 𝑪^�∈ℝ�×�×� with a CNN-based upsampler.
为了在不同视图的成本量之间交换信息,我们在U-Net架构的最低分辨率下注入了三个跨视图注意层。交叉视图注意力层能够接受任意数量的视图作为输入,因为它计算每个视图相对于所有其他视图的交叉注意力,其中这样的操作不依赖于视图的数量。低分辨率成本体积 𝑪~� 最终用基于CNN的上采样器上采样到全分辨率 𝑪^�∈ℝ�×�×� 。
Depth estimation. We use the softmax operation to obtain per-view depth predictions. Specifically, we first normalize the refined cost volume 𝑪^� in the depth dimension and then perform a weighted average of all depth candidates 𝑮=[�1,�2,⋯,��]∈ℝ�:
深度估计。我们使用softmax操作来获得每个视图的深度预测。具体地,我们首先在深度维度中归一化细化的成本体积 𝑪^� ,然后执行所有深度候选 𝑮=[�1,�2,⋯,��]∈ℝ� 的加权平均:
| 𝑽�=softmax(𝑪^�)𝑮∈ℝ�×�. | (6) |
Depth refinement. To further improve the performance, we introduce an additional depth refinement step to enhance the quality of the above predicted depth. The refinement is performed with a very lightweight 2D U-Net, which takes multi-view images, features and current depth predictions as input, and outputs per-view residual depths. The residual depths are then added to the current depth predictions as the final depth outputs. Similar to the U-Net used in the above cost volume refinement, we also introduce cross-view attention layers in the lowest resolution to exchange information across views. More implementation details are presented in the supplementary material Appendix 0.C.
深度细化。为了进一步提高性能,我们引入了一个额外的深度细化步骤,以提高上述预测深度的质量。细化是用一个非常轻量级的2D U-Net执行的,它将多视图图像、特征和当前深度预测作为输入,并输出每个视图的残余深度。然后将残余深度添加到当前深度预测作为最终深度输出。与上述成本量细化中使用的U-Net类似,我们还引入了最低分辨率的跨视图注意力层,以跨视图交换信息。更多实施细节见补充材料附录0.C。
3.2Gaussian Parameters Prediction
3.2高斯参数预测
Gaussian centers �. After obtaining the multi-view depth predictions, we directly unproject them to 3D point clouds using the camera parameters. We transform the per-view point cloud into an aligned world coordinate system and directly combine them as the centers of the 3D Gaussians.
高斯中心 � 。在获得多视图深度预测之后,我们使用相机参数直接将其解投影到3D点云。我们将每个视点的点云转换成一个对齐的世界坐标系,并直接将它们联合收割机作为3D高斯的中心。
Opacity �. From the matching distribution obtained via the softmax(𝑪^�) operation in Eq. 6, we can also obtain the matching confidence as the maximum value of the softmax output. Such matching confidence shares a similar physical meaning with the opacity (points with higher matching confidence are more likely to be on the surface), and thus we use two convolution layers to predict the opacity from the matching confidence input.
不透明度 � 。根据通过等式11中的 softmax(𝑪^�) 操作获得的匹配分布,6,我们还可以获得匹配置信度作为softmax输出的最大值。这种匹配置信度与不透明度具有类似的物理意义(具有较高匹配置信度的点更有可能在表面上),因此我们使用两个卷积层来预测来自匹配置信度输入的不透明度。
Covariance 𝚺 and color �. We predict these parameters by two convolution layers that take as inputs the concatenated image features, refined cost volume and the original multi-view images. Similar to other 3DGS approaches [12, 1], the covariance matrix 𝚺 is composed of a scaling matrix and a rotation matrix represented via quaternions, and the color 𝒄 is calculated from the predicted spherical harmonic coefficients.
协方差 𝚺 和颜色 � 。我们通过两个卷积层来预测这些参数,这两个卷积层将级联图像特征、细化成本体积和原始多视图图像作为输入。类似于其他3DGS方法[12,1],协方差矩阵 𝚺 由通过四元数表示的缩放矩阵和旋转矩阵组成,并且颜色 𝒄 从预测的球谐系数计算。
3.3Training Loss 3.3训练损失
Our model predicts a set of 3D Gaussian parameters {(𝝁�,��,𝚺�,𝒄�)}�=1�×�×�, which are then used for rendering images at novel viewpoints. Our full model is trained with ground truth target RGB images as supervision. The training loss is calculated as a linear combination of ℓ2 and LPIPS [40] losses, with loss weights of 1 and 0.05, respectively.
我们的模型预测了一组3D高斯参数 {(𝝁�,��,𝚺�,𝒄�)}�=1�×�×� ,然后将其用于在新视点处渲染图像。我们的完整模型使用地面真实目标RGB图像作为监督进行训练。训练损失计算为 ℓ2 和LPIPS [ 40]损失的线性组合,损失权重分别为1和0.05。
4Experiments 4实验
4.1Settings
Datasets. We assess our model on the large-scale RealEstate10K [42] and ACID [14] datasets. RealEstate10K contains real estate videos downloaded from YouTube, which are split into 67,477 training scenes and 7,289 testing scenes, while ACID contains nature scenes captured by aerial drone, split into 11,075 training scenes and 1,972 testing scenes. Both datasets provide estimated camera intrinsic and extrinsic parameters for each frame. Following pixelSpalt [1], we evaluate all methods on three target novel viewpoints for each test scene. Furthermore, to further evaluate the cross-dataset generalization ability, we also directly evaluate on the multi-view DTU [10] dataset, which contains object-centric scenes with camera poses. On DTU dataset, we report results on 16 validation scenes, with 4 novel views for each scene.
数据集。我们在大规模RealEstate10K [ 42]和ACID [ 14]数据集上评估我们的模型。RealEstate10K包含从YouTube下载的房地产视频,分为67,477个训练场景和7,289个测试场景,而ACID包含空中无人机拍摄的自然场景,分为11,075个训练场景和1,972个测试场景。这两个数据集都提供了每个帧的估计相机内部和外部参数。在pixelSpalt [ 1]之后,我们对每个测试场景的三个目标新颖视点评估所有方法。此外,为了进一步评估跨数据集的泛化能力,我们还直接在多视图DTU [ 10]数据集上进行评估,该数据集包含具有相机姿势的以对象为中心的场景。在DTU数据集上,我们报告了16个验证场景的结果,每个场景有4个新视图。
Metrics. For quantitative results, we report the standard image quality metrics, including pixel-level PSNR, patch-level SSIM [31], and feature-level LPIPS [40]. The inference time and model parameters are also reported to enable thorough comparisons of speed and accuracy trade-offs. For a fair comparison, all experiments are conducted on 256×256 resolutions following existing models [1, 27].
指标.对于定量结果,我们报告了标准图像质量指标,包括像素级PSNR,补丁级SSIM [ 31]和特征级LPIPS [ 40]。还报告了推理时间和模型参数,以便对速度和精度进行全面比较。为了公平比较,所有实验都是按照现有模型在 256×256 分辨率上进行的[ 1,27]。
Implementation details. Our MVSplat is implemented with PyTorch, along with an off-the-shelf 3DGS render implemented in CUDA. Our multi-view Transformer contains 6 stacked self- and cross-attention layers. We sample 128 depth candidates when constructing the cost volumes in all the experiments. All models are trained on a single A100 GPU for 300,000 iterations with the Adam [13] optimizer. More details are provided in the supplementary material Appendix 0.C. Code and models are available at GitHub - donydchen/mvsplat: 🌊[arXiv'24] MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images.
实施细节。我们的MVSplat是用PyTorch实现的,沿着一个在CUDA中实现的现成3DGS渲染器。我们的多视图Transformer包含6个堆叠的自我和交叉注意层。在所有实验中构建成本卷时,我们对128个深度候选者进行了采样。所有模型都在单个A100 GPU上使用Adam优化器进行300,000次迭代训练。更多详情见补充材料附录0.C。代码和模型可在https://github.com/donydchen/mvsplat上获得。
4.2Main Results 4.2主要结果
| Method | Time 时间(s) | Param(M) | RealEstate10K [42] [ 42]第四十二话 | ACID [14] | ||||
|---|---|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | LPIPS↓ | PSNR↑ | SSIM↑ | LPIPS↓ | |||
| pixelNeRF [38] [ 38]第三十八话 | 5.299 | 28.2 | 20.43 | 0.589 | 0.550 | 20.97 | 0.547 | 0.533 |
| GPNR [26] | 13.340 | 9.6 | 24.11 | 0.793 | 0.255 | 25.28 | 0.764 | 0.332 |
| AttnRend [6] | 1.325 | 125.1 | 24.78 | 0.820 | 0.213 | 26.88 | 0.799 | 0.218 |
| MuRF [33] | 0.186 | 5.3 | 26.10 | 0.858 | 0.143 | 28.09 | 0.841 | 0.155 |
| pixelSplat [1] | 0.104 | 125.4 | 25.89 | 0.858 | 0.142 | 28.14 | 0.839 | 0.150 |
| MVSplat | 0.044 | 12.0 | 26.39 | 0.869 | 0.128 | 28.25 | 0.843 | 0.144 |
Table 1:Comparison with state of the art. Running time includes both encoder and render, note that 3DGS based methods (pixelSplat and MVSplat) render dramatically faster (∼500FPS for the render). Performances are averaged over thousands of test scenes in each dataset. For each scene, the model takes two views as input and renders three novel views for evaluation. Our MVSplat performs the best in terms of all visual metrics and runs the fastest with a lightweight model size.
表一:运行时间包括编码器和渲染,注意基于3DGS的方法(pixelSplat和MVSplat)渲染速度快得多(渲染的FPS为 ∼500 )。每个数据集中数千个测试场景的性能平均值。对于每个场景,模型将两个视图作为输入,并渲染三个新视图以进行评估。我们的MVSplat在所有视觉指标方面表现最好,并且在轻量级模型大小下运行速度最快。
Baselines. We compare MVSplat with several representative feed-forward methods that focus on scene-level novel view synthesis from sparse views, including i) Light Field Network-based GPNR [26] and AttnRend [6], ii) NeRF-based pixelNeRF [38] and MuRF [33], iii) the latest state-of-the-art 3DGS-based model pixelSplat [1]. We conduct thorough comparisons with the latter, being the most closely related to our method.
基线。我们将MVSplat与几种代表性的前馈方法进行了比较,这些方法专注于从稀疏视图合成场景级新视图,包括i)基于光场网络的GPNR [ 26]和AttnRend [ 6],ii)基于NeRF的pixelNeRF [ 38]和MuRF [ 33],iii)最新的基于3DGS-based模型pixelSplat [ 1]。我们与后者进行了彻底的比较,后者与我们的方法关系最密切。
Assessing image quality. We report results on the RealEstate10K [42] and ACID [14] benchmarks in Tab. 1. Our MVSplat surpasses all previous state-of-the-art models in terms of all metrics on visual quality, with more obvious improvements in the LPIPS metric, which is better aligned with human perception. This includes pixelNeRF [38], GPNR [26], AttnRend [6] and pixelSplat [1], with results taken directly from the pixelSplat [1] paper, and the recent state-of-the-art NeRF-based method MuRF [33], for which we re-train and evaluate its performance using the officially released code.
评估图像质量。我们在Tab中报告了RealEstate10K [ 42]和ACID [ 14]基准测试的结果。1.我们的MVSplat在视觉质量的所有指标方面都超过了所有以前最先进的模型,在LPIPS指标方面有更明显的改进,更好地与人类感知保持一致。这包括pixelNeRF [ 38],GPNR [ 26],AttnRend [ 6]和pixelSplat [ 1],结果直接取自pixelSplat [ 1]论文,以及最近最先进的基于NeRF的方法MuRF [ 33],我们使用官方发布的代码重新训练和评估其性能。

Figure 3:Comparisons with the state of the art. The first three rows are from RealEstate10K (indoor scenes), while the last one is from ACID (outdoor scenes). Models are trained with a collection of training scenes from each indicated dataset, and tested on novel scenes from the same dataset. MVSplat surpasses all other competitive models in rendering challenging regions due to the effectiveness of our cost volume-based geometry representation.
图三:与最先进技术的比较。前三行来自RealEstate10K(室内场景),而最后一行来自ACID(室外场景)。模型使用来自每个指定数据集的训练场景集合进行训练,并在来自相同数据集的新场景上进行测试。MVSplat在渲染具有挑战性的区域方面超越了所有其他竞争模型,这是由于我们基于成本体积的几何表示的有效性。
The qualitative comparisons of the top three best models are visualized in Fig. 3. MVSplat achieves the highest quality on novel view results even under challenging conditions, such as these regions with repeated patterns (“window frames” in 1st row), or these present in only one of the input views (“stair handrail” and “lampshade” in 2nd and 3rd rows), or when depicting large-scale outdoor objects captured from distant viewpoints (“bridge” in 4th row). The baseline methods exhibit obvious artifacts for these regions, while our MVSplat shows no such artifacts due to our cost volume-based geometry representation. More evidence and detailed analysis regarding how MVSplat effectively infers the geometry structures are presented in Sec. 4.3.
前三个最佳模型的定性比较如图3所示。即使在具有挑战性的条件下,MVSplat也能实现最高质量的新视图结果,例如这些区域具有重复的图案(第一行中的“窗框”),或者这些区域仅存在于一个输入视图中(第二行和第三行中的“楼梯扶手”和“灯罩”),或者当描绘从远处视点捕获的大型户外对象时(第四行中的“桥梁”)。基线方法对这些区域表现出明显的伪影,而我们的MVSplat由于我们基于成本体积的几何表示而没有显示出这样的伪影。更多关于MVSplat如何有效地推断几何结构的证据和详细分析在第二节中介绍。4.3.



)




)










