一.正则表达式
- 正则表达式(Regular Expression、regex 或 regexp, 缩写为RE), 又称规则表达式,是计算机科学中的一个概念。正则表通常被用来检索、替换那些符合某个模式(规则)的文本。正则表达式是对字符串(包括普通字符(例如, a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式, 就是用事先定义好的一些特定字符、及这些特定字符的组合, 组成一个“规则字符串”, 这个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,模式描述在搜索文本时要匹配的一个或多个字符串。
- 正则表达式这个概念最初是由 Unix中的工具软件(例如 sed 和grep)普及开的。支持正则表达式的指令如: locate|find|vim|grep|sed|awk, 我们将详细讲解grep|sed|awk。
- 正则表达式由元字符组成,元字符是在正则表达式中具有“特殊意义的专用字符”。不同的字符有不同的含义,有的元字符可以表示一类字符,因此由元字符组成的正则表达式可以表示一类字符,当构建好一个规则, 并设计好能准确表达这个规则的正则表达式, 那么就可以使用这个正则表达式从指定内容中获取符合这个规则的内容, 或者判断某个内容是否符合这个规则。
| 元字符 | 说明 | 实例 | 匹配的字符串示例 |
| 一般字符 | 匹配自身 | haha | haha |
| 匹配除换行'\n'以为的任意一个字符,在DOTALL模式中也能匹配换行符。 | a.c | abc,adc..... | |
| \ | 转义字符串,改变后一个字符的意思 | a\.c | a.c |
| [...] | 字符集,对应位置可以是其中的任意一个字符 | a[bcd]e | abe,ace,ade |
| \d | 数字,等价于[0-9] | a\dc a[0-9]/c | a1c,a2c.... |

| [:lower:] | 小写字母 | ||
| [:upper:] | 大写字母 | ||
| [:punct:] | 标点符号 | ||
| [:space:] | 换行符、回车等空白字符 |
二.grep
- grep命令是一种强大的文本搜索工具, 它能使用正则表达式搜索文本, 并把匹配的行打印出来(匹配到的标红)。grep全称是 Global Regular Expression Print, 表示全局正则表达式打印。
- grep的工作方式是, 在一个或多个文件中搜索字符串模板, 模板后的所有字符串被看作文件名。搜索的结果被送到标准输出, 不影响原文件内容。
- grep可用于 shell脚本, 因为 grep通过返回一个状态值来说明搜索的状态, 如果模板搜索成功, 则返回0, 如果搜索不成功,则返回1, 如果搜索的文件不存在, 则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
egrep= grep-E: 扩展的正则表达式(除了\<,\>,\b 使用其他正则都可以去掉\)。
- 【命令格式】gre p [option] pattern file
- 【功能】用于过滤、搜索特定的字符。
【命令参数】
- -A<显示行数>: -A NUM,--after-context = NUM, 除了显示符合范本样式的那一行之外, 并显示该行之后的内容。
- -B<显示行数>: --before-context=NUM, 除了显示符合样式的那一行之外, 并显示该行之前的内容。
- -C<显示行数>: -NUM,--context=NUM, 除了显示符合样式的那一行之外, 并显示该行之前后的内容。
- -c: 统计匹配的行数
- -e : 实现多个选项间的逻辑 or 关系
- -E: 扩展的正则表达式,grep-E等同于 egrep
- -fFUE:从 FILE 获取 PATTERN 匹配
- -F: 相当于 fgrep
- -i-ignore-case#忽略字符大小写的差别。
- -n: 显示匹配的行号
- -o: 仅显示匹配到的字符串
- -q: 静默模式,不输出任何信息
- -s: 不显示错误信息.
- -v: 显示不被 pattern 匹配到的行, 相当于[^] 反向匹配
- -w: 匹配 整个单词
1.案例(匹配字符)
本例主要练习匹配字符。root用户家目录下的 test01. prel文件为匹配规则、test01 文件为普通文本文件。使用grep按照test01. prel中指定规则匹配文件test01中的字符。
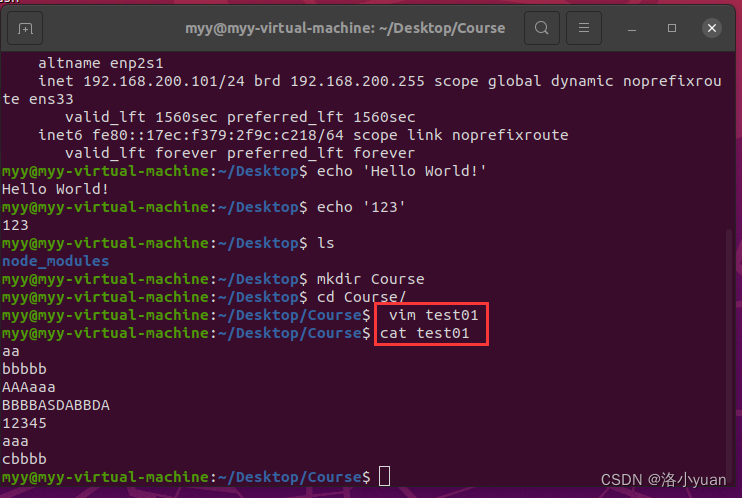
1.显示含有字符A的行,及后一行

2.显示含有字符A的行,及前一行:

3.显示含有字符A的行,及前后各一行

4.统计含有aaa的行数

5.显示含有AAA或bbb的行:
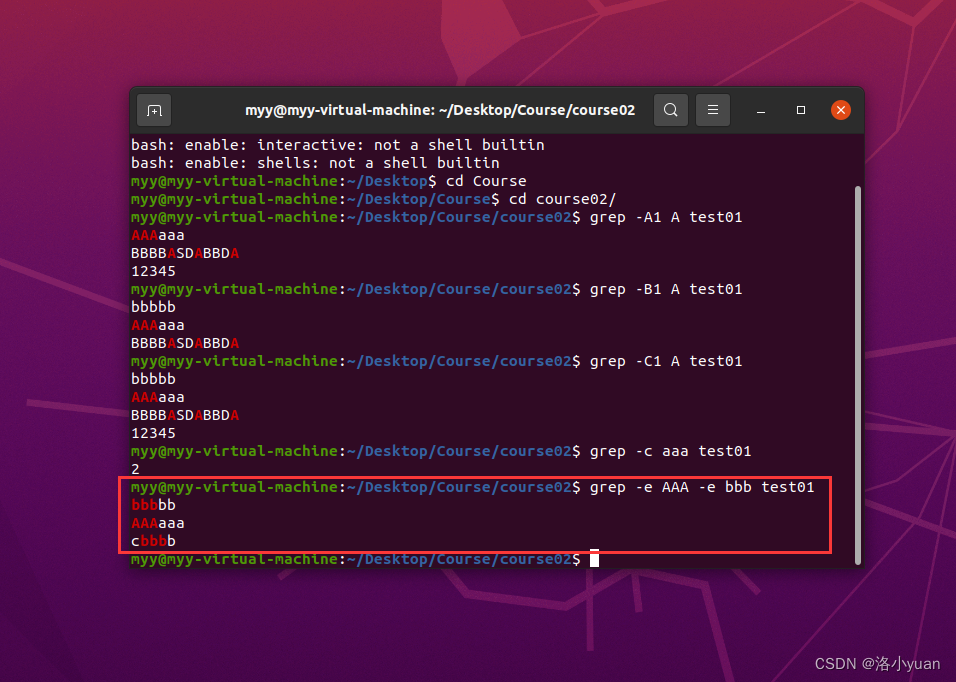
6.从文件test01.prel获取匹配规则:创建test01.prel

7.显示含有b的行,忽略·大小写并显示所在行号:

8.匹配字符串Aa:

9.静默模式匹配字符aa:
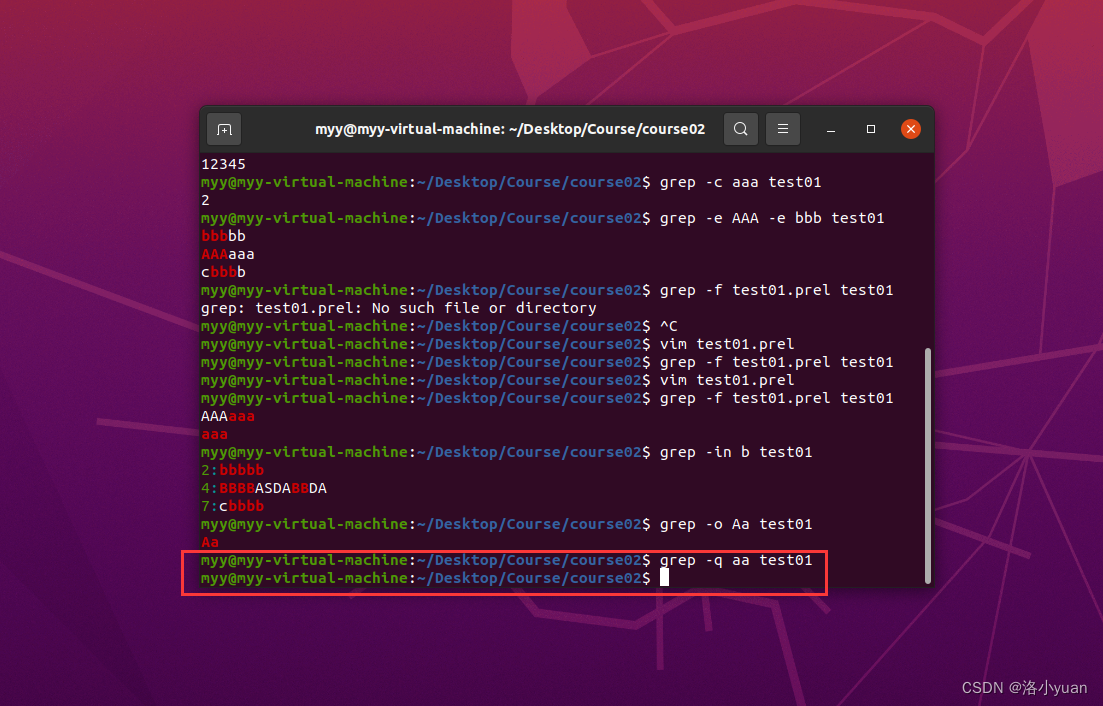
10.显示没有匹配到aa的行:

11.精确匹配单词aa:
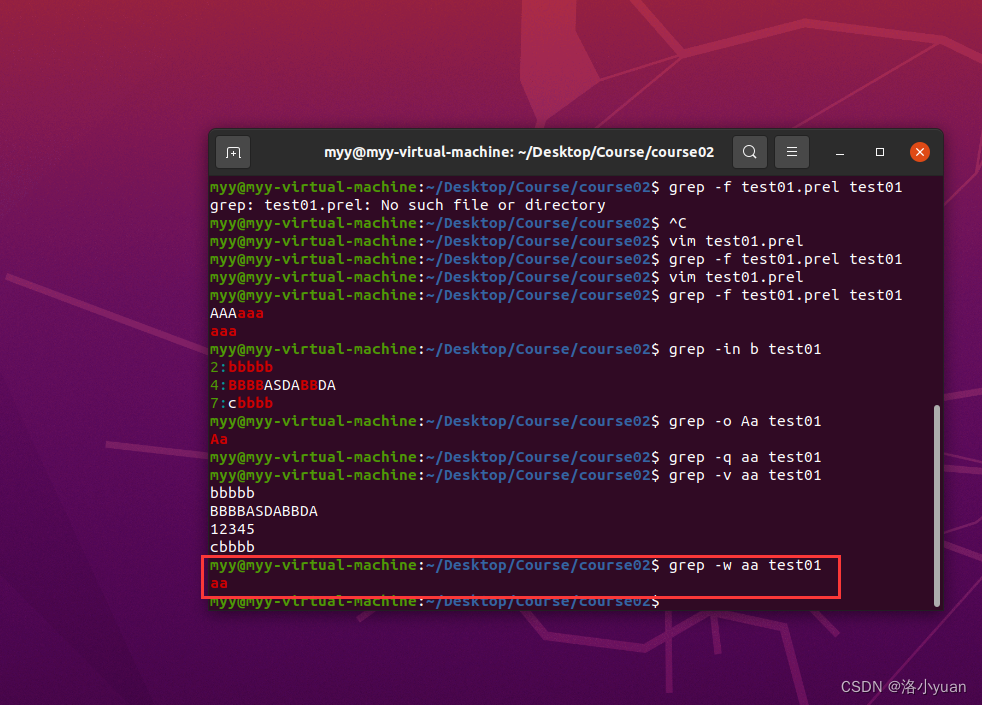
2.案例(匹配次数相关正则使用)
【例 2-2】本例主要练习匹配次数相关正则的使用。在 root用户家目录下有文件test_grep_02, 使用正则, 匹配字符。注意, 第三行为 Tab缩进后换行、第四行为四个空格后回车、第五第六行为回车空行。
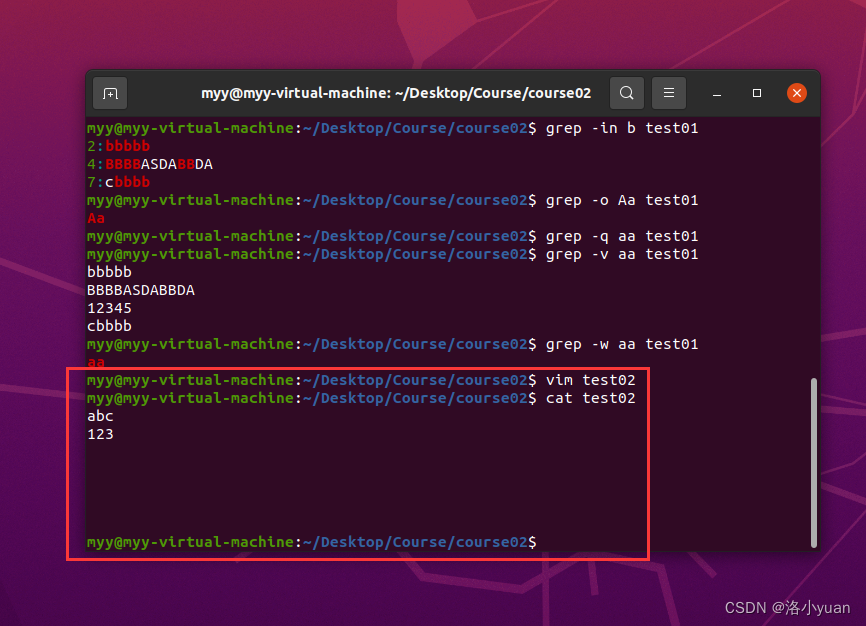
1.匹配除了换行外,任意单个字符:

2.匹配字符a、/:
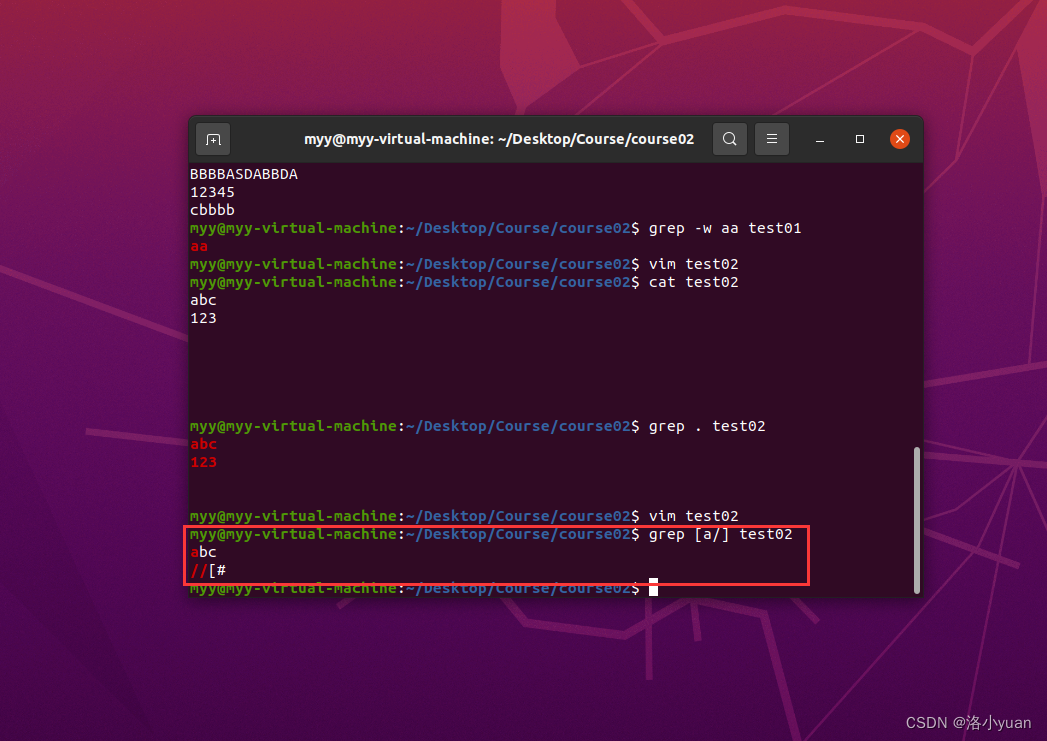
3.匹配abc之外的字符:
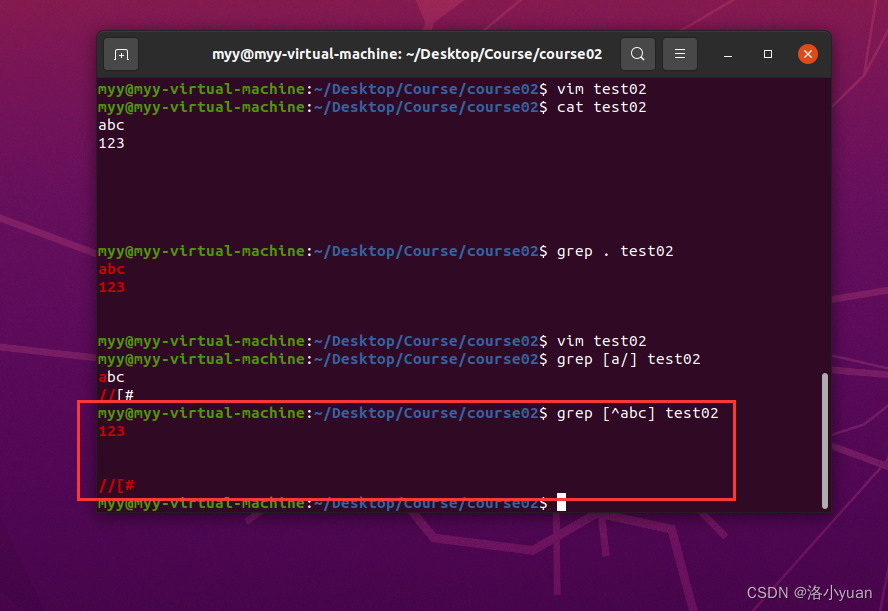
4.匹配字母和数字:

5.匹配字母:
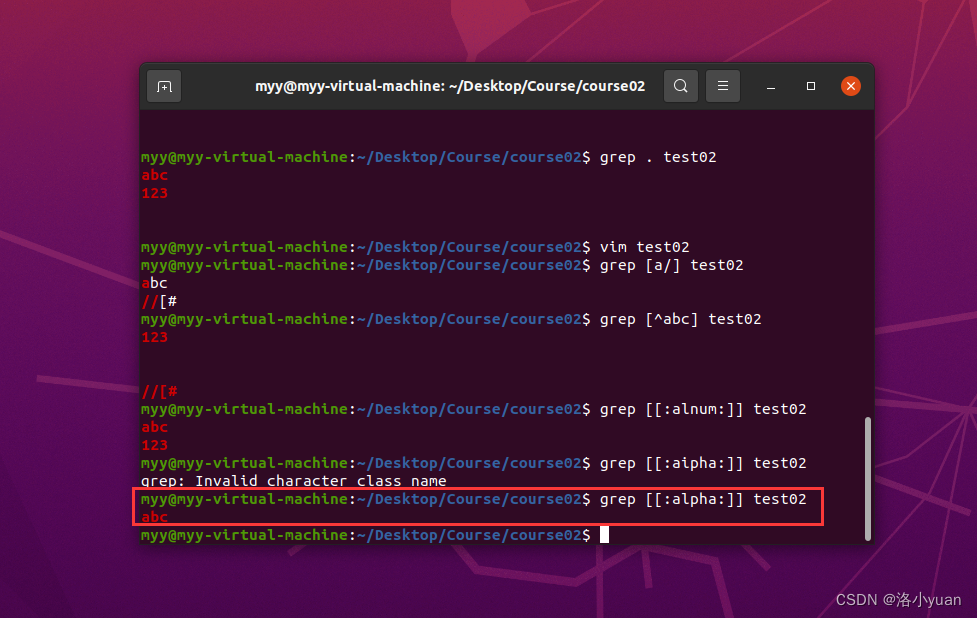
6.匹配数字:
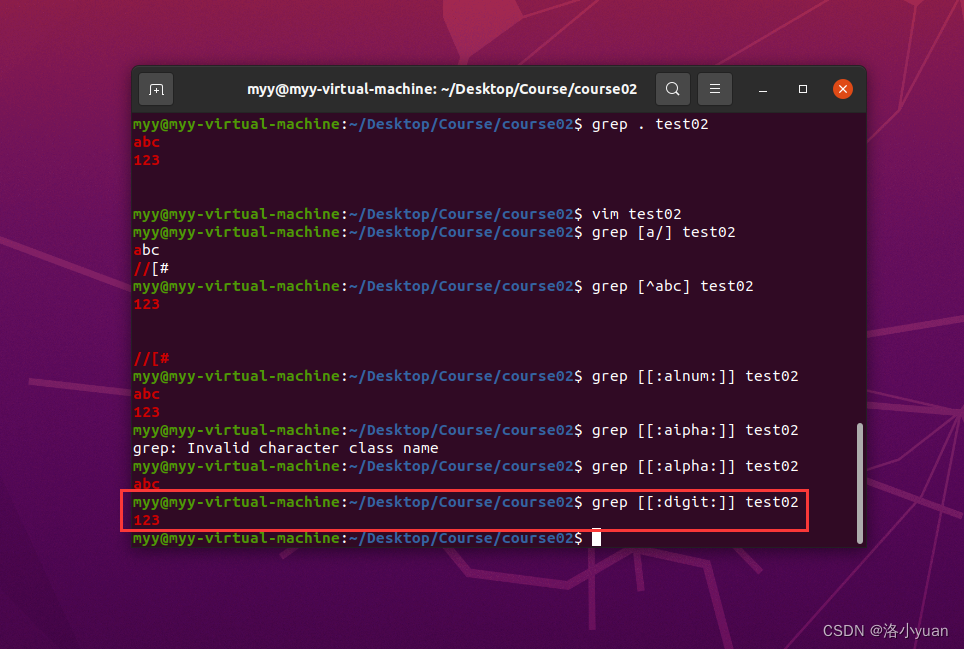
7.匹配字母a-z:

8.匹配空格:

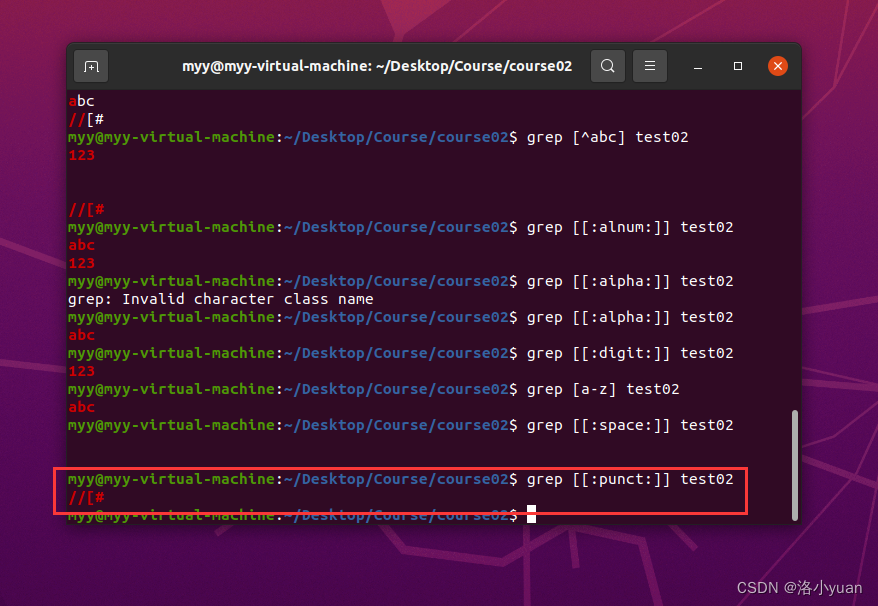
9.匹配标点符号:
3.案例(位置锚点)
【例2-3】本例主要练习位置锚定, 即定位出现的位置相关正则的使用。在 root用户家目录下有文件test_grep_03, 使用正则, 匹配字符。
1.匹配"o"0次或任意多次:

2.匹配"o"任意多次,不包括0次

3.匹配"o"0次或者1次:

4.匹配“o”至少1次

5.匹配"o"1-2次:

6.匹配“o”至少10次:
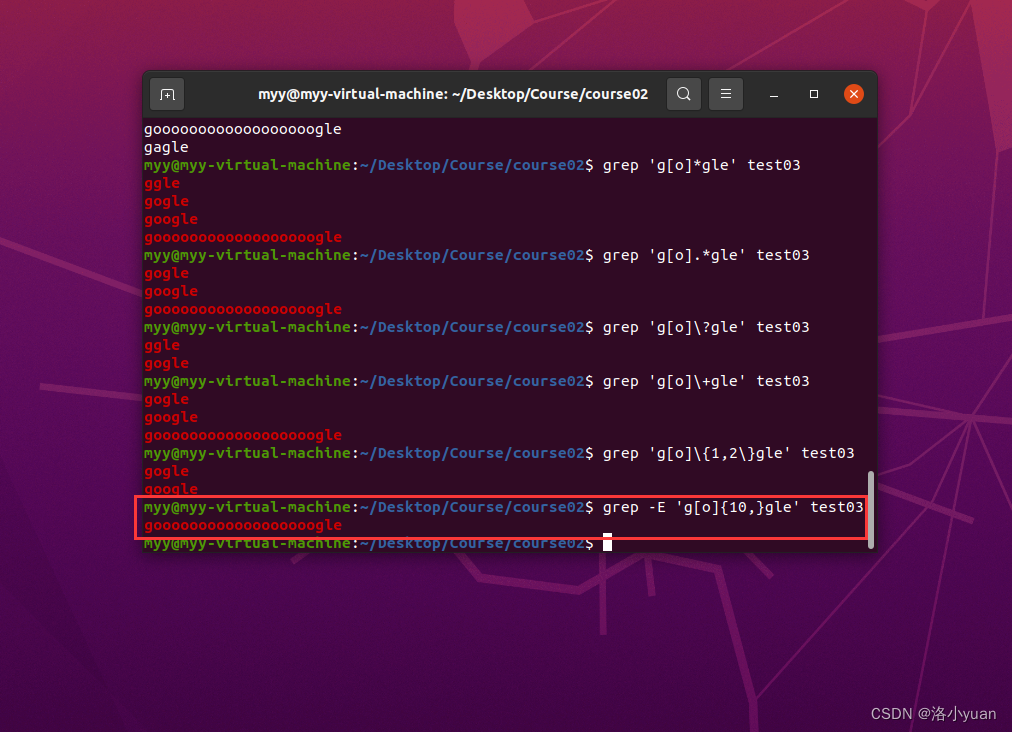
7.匹配"o"至多10次:
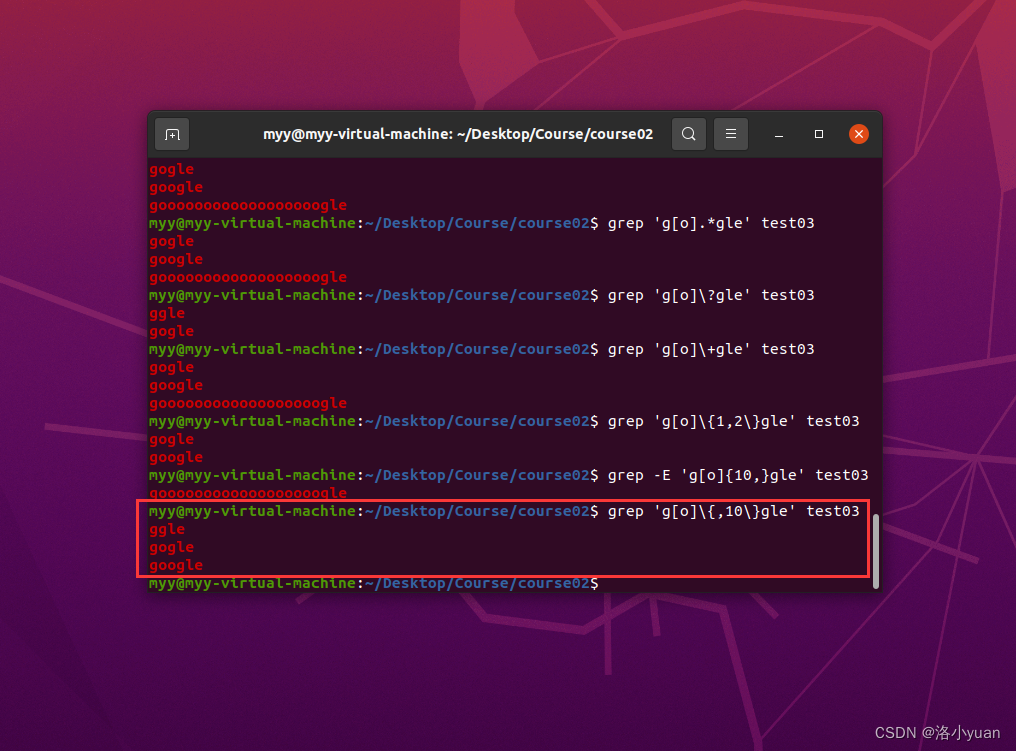
4.使用正则,匹配字符
【例2-4】在 root用户家目录下有文件test_grep_04,使用正则, 匹配字符。注意, 第二行为Tab空格, 第三、第四为空行。

1.行首锚定,匹配出行首为a的行:
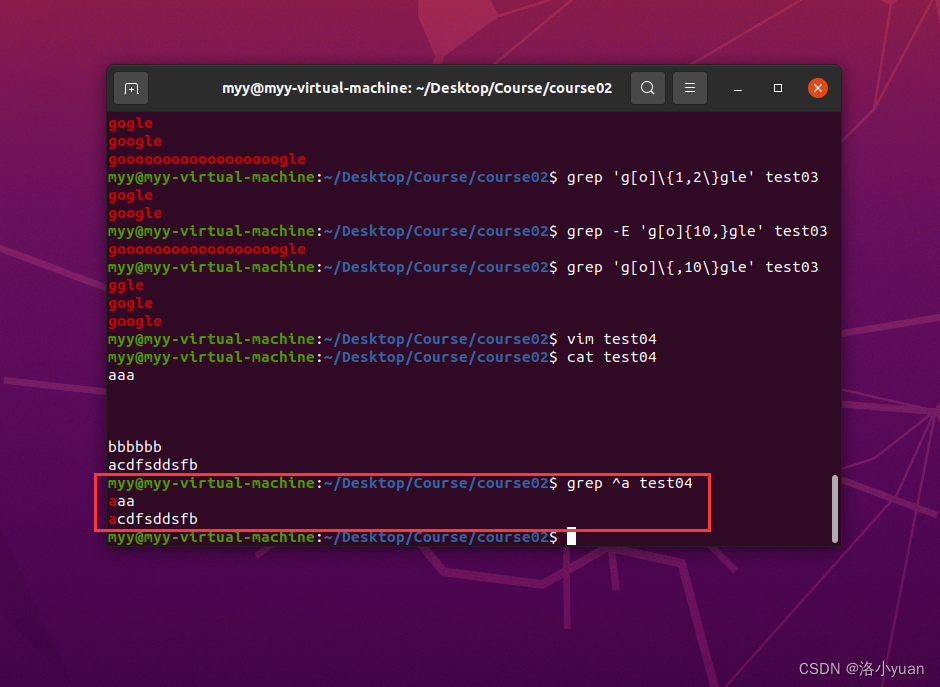
2.行尾锚定,匹配出行尾为b的行:
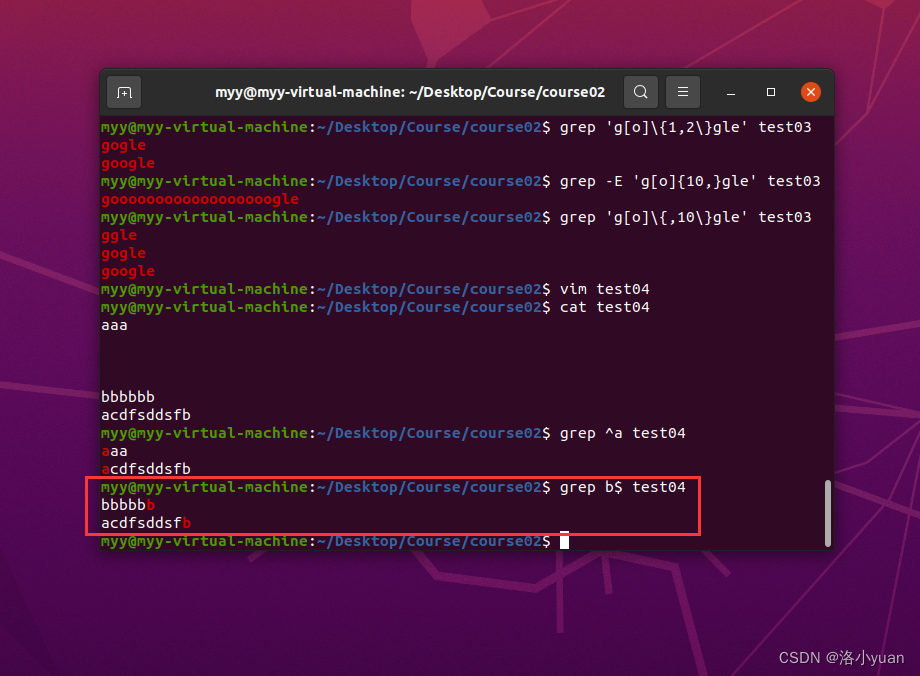
3.匹配出空行:

4.匹配出以空格开头的行:

5.词首、词尾锚定,匹配出词首为a、词尾为b的词

5.分组
通过\(\)将一个或多个字符捆绑在一起,当作一个整体进行处理。分组括号中的模式匹配到的内容,会被正则表达式引擎记录在内部变量中, 这些变量的命名方式是\1,\2,\3……
6.后向引用
引用前面的分组中的模式所匹配的字符。\1 表示从左侧起第一个括号以及与之匹配右括号之间的模式所匹配到的字符;\2 表示从左侧其第二个括号以及与之匹配右括号之间的模式所匹配的字符;\&表示前面的分组中匹配的所有字符。如图2-1为后向引用示意图。

7.案例(分组和后向引用相关正则表达式)
【例2-5】本例主要练习分组和后向引用相关正则的使用。在用户家目录下有test_grep_05文件, 使用正则, 匹配满足条件的字符。

1.匹配以He开头的分组:

2.匹配以He开头、He结尾的分组:
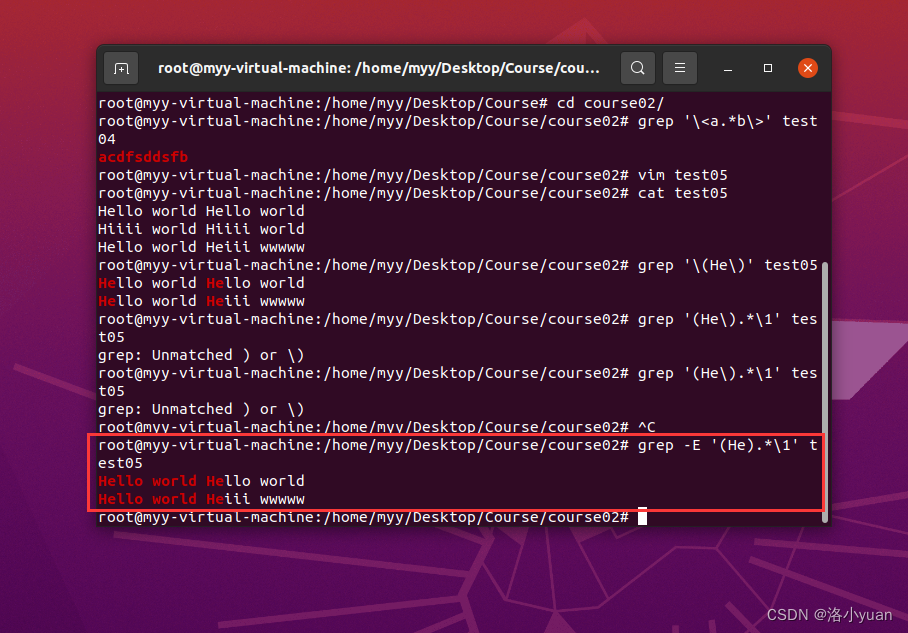
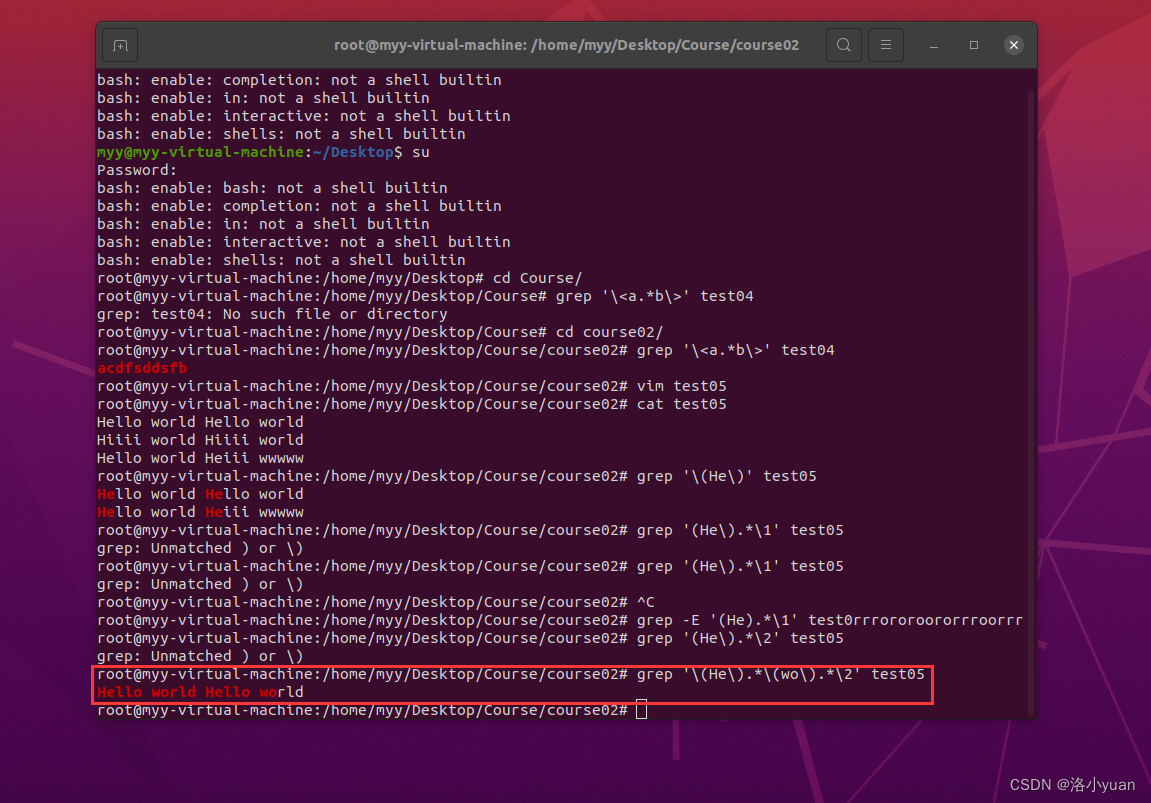
3.匹配He.*wo开头、wo结尾的分组
三.sed
sed 是 stream editor 的缩写, 中文称之为“流编辑器”。sed 命令是一个面向行处理的工具, 它以“行”为处理单位,针对每一行进行处理, 处理后的结果会输出到标准输出(STDOUT)。sed 命令不会对读取的文件做任何贸然的修改,而是首先将内容都输出到标准输出中。
1.sed 工作流
首先, sed把当前正在处理的行, 保存在一个临时缓存区中(也成为模式空间),然后处理临时缓冲区中的行, 完成后, 把该行回显到屏幕上;
sed把每一行都存在临时缓冲区,对这个副本进行编辑, 所以不会修改源文件;
sed 主要用来自动编辑一个或多个文件;简化对文件的反复操作,编写转换程序等。
2.sed使用方法
sed 常见的使用方法有两种, 一种为“命令行”模式; 另一种为“脚本”模式。可类比Python语言学习时, 两种编程方式。
【命令格式】sed [参数]'[地址定界] command'file
【功能】用于过滤、搜索特定的字符。
【参数】:

| -i | -- -i-place | 直接将处理的结果写入文件 |
【command】常用的有如下几种:
- d: 表示删除行。
- p: 打印该行。
- a:在当前行之后插入新行新内容, 每行末尾需要使用‘\’续行。
- i: 在当前行之前插入新行新内容, 每行末尾需要使用‘\’续行。
- c: c符号后的新行新内容, 替换当前行中的文本, 每行末尾需要使用‘\’续行, 整行替换。
- r:读取指定文件的内容。
- w:写入指定文件。
- s: 替换指定字符。
3.参数-n
- -n:静默模式。不能出模式空间内容到屏幕
案例
在root用户家目录下有文件test01,对文件进行处理:
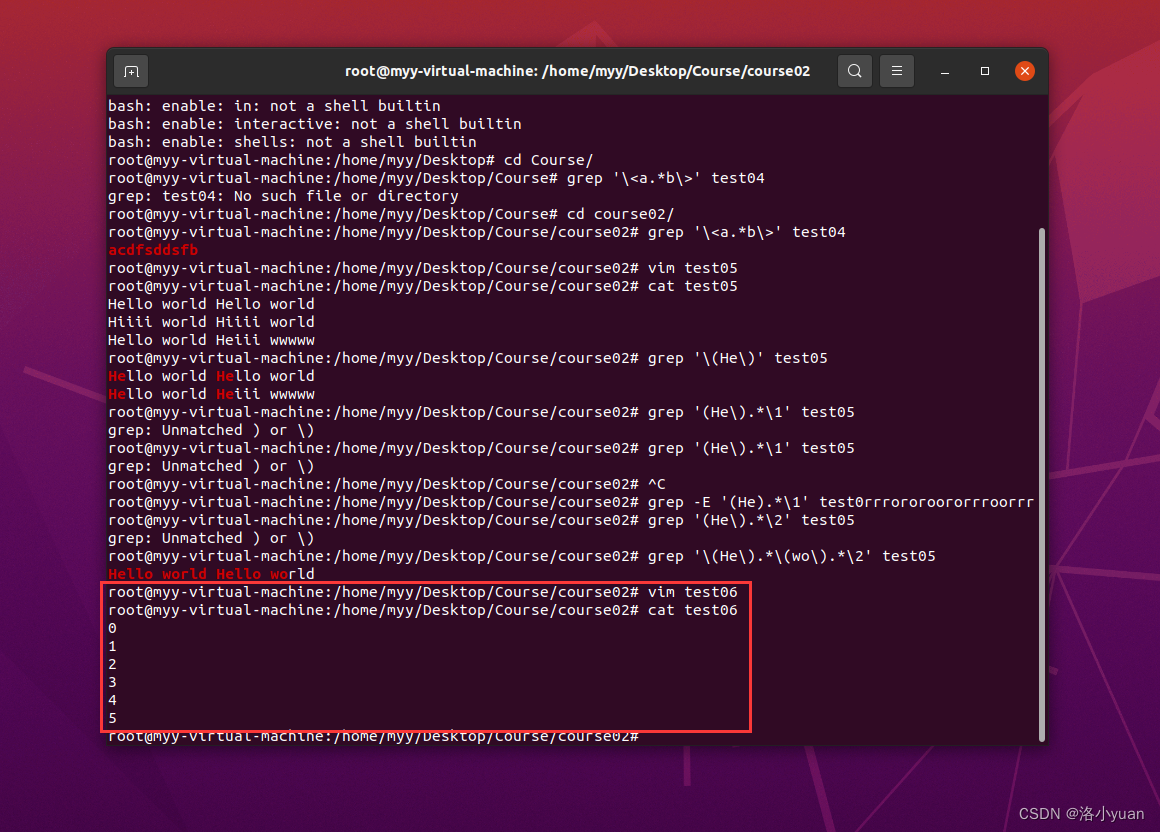
使用静态模式和非静态模式,输出含有"4"的行。

注意观察, 在非静默模式下, 由于打印输出到4时, 符合“模板”匹配规则, 故将结果直接回显打印在了屏幕上;而静默模式下, 仅仅输出了符合“模板”匹配规则的结果,文本本身没有被输出, 相当于输出静默。
-n常常和p命令一起使用, 仅输出那些匹配的行, 无关行不做输出。
4.命令p、命令d
- d:表示删除行
- p:打印该行
续test06案例
1.分别输出第1行、第2行、第3~4行、最后一行
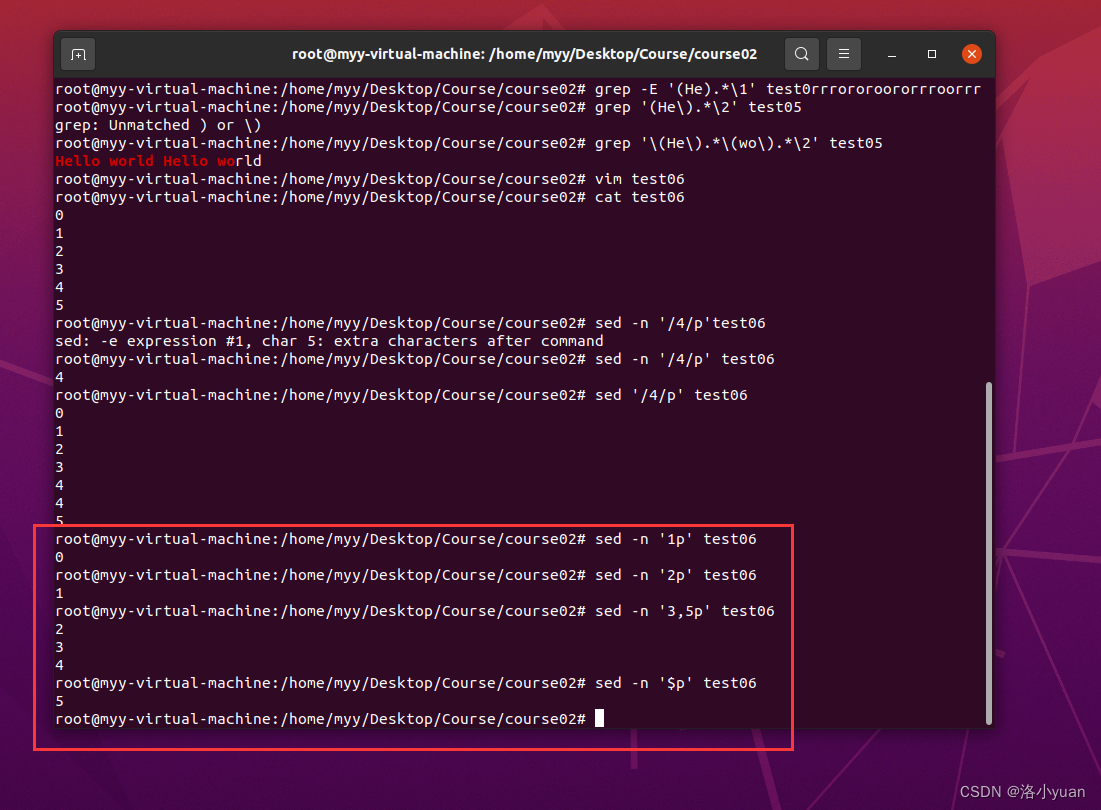
2.删除第1行,并查看原文件是否发生变化
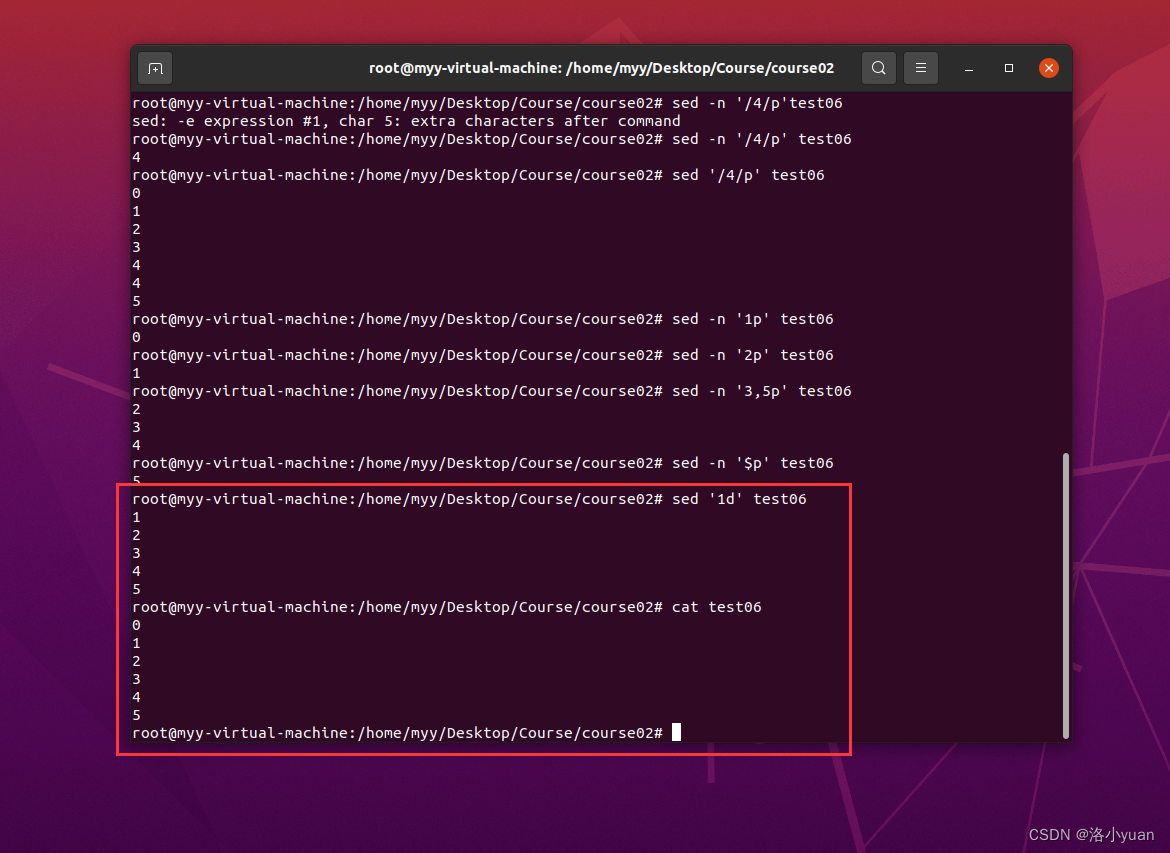
通过观察输出和查看源文件, 发现, sed 执行结果并不影响原文件。执行删除行的指令后,原文件内容不变。
5.命令a、命令i和命令c
- a: 在当前行之后插入新行新内容, 每行末尾需要使用‘\’续行;
- is:在当前行之前插入新行新内容, 每行末尾需要使用‘\’续行;
- c: c符号后的新行新内容,替换当前行中的文本, 每行末尾需要使用“\’续行,整行替换。
续案例test06
1.向最后一行之后添加9999:

2.向当前行之后插入文本9999
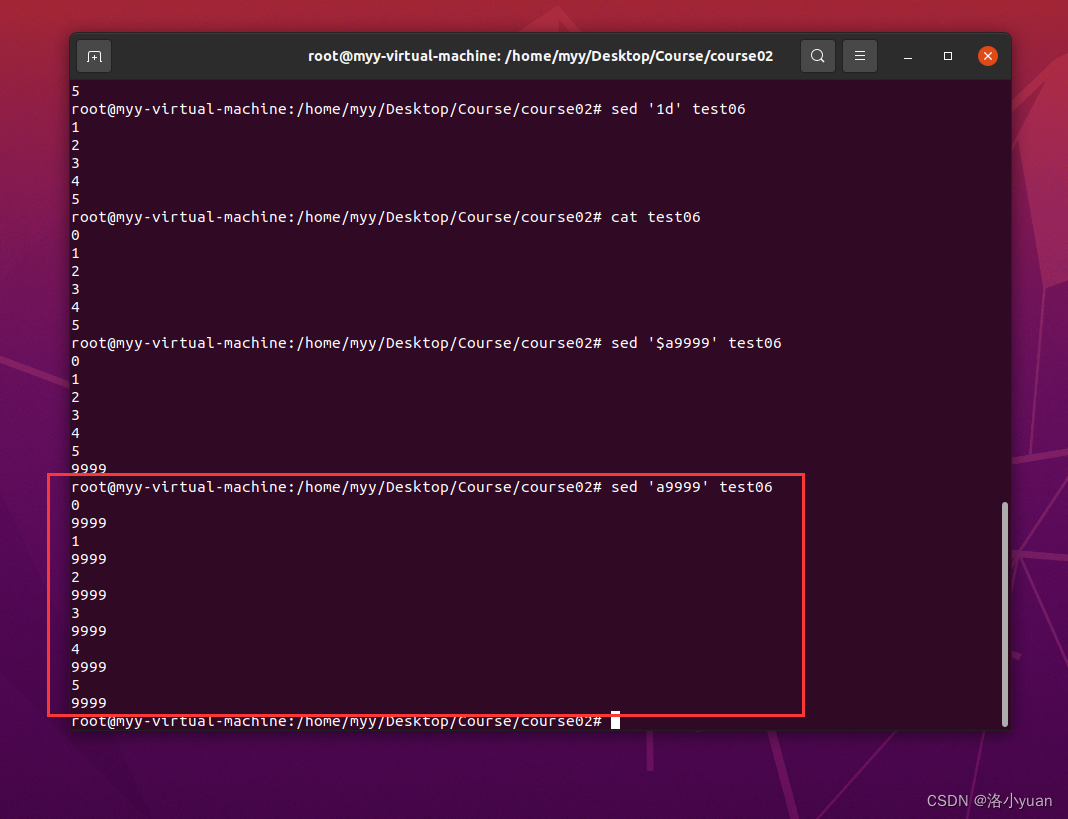
3.向当前行之前插入文本6666:

4.向末行之前插入文本6666
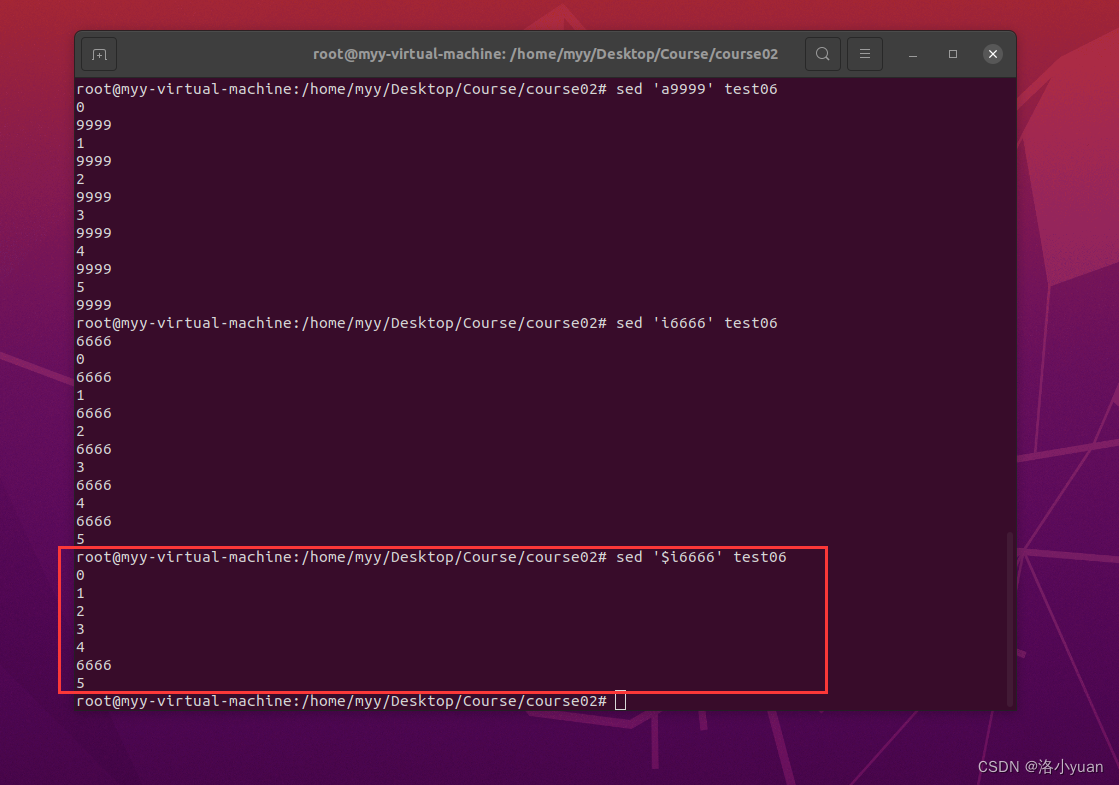
5.用文本Hello world替换第5行:
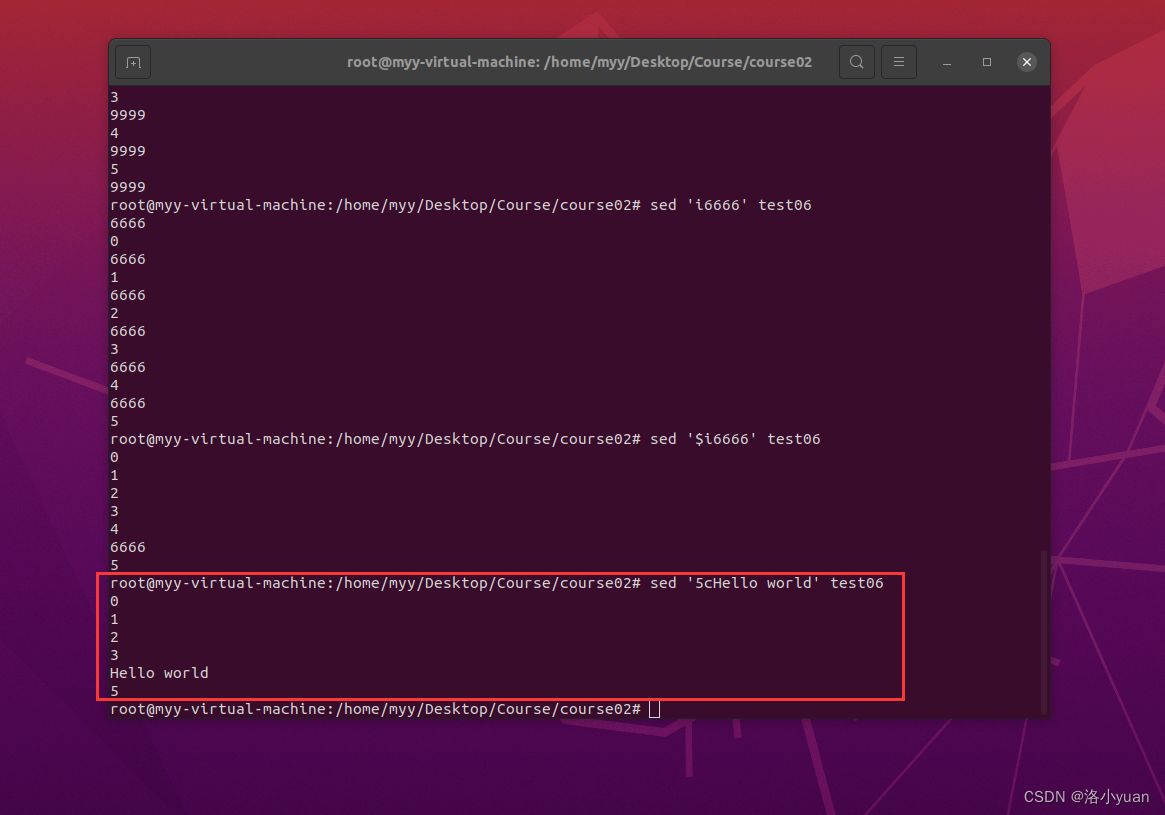
6.用文本hello world替换每一行:
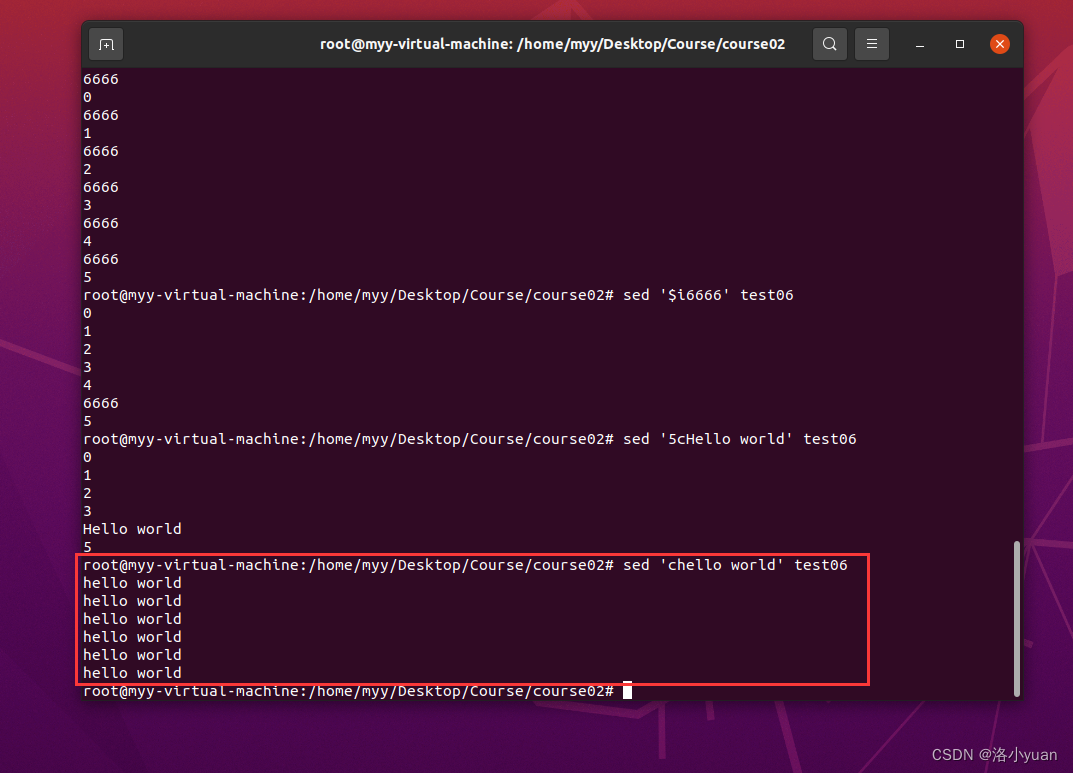
7.向末行插入多行文本yyyy换行8888:
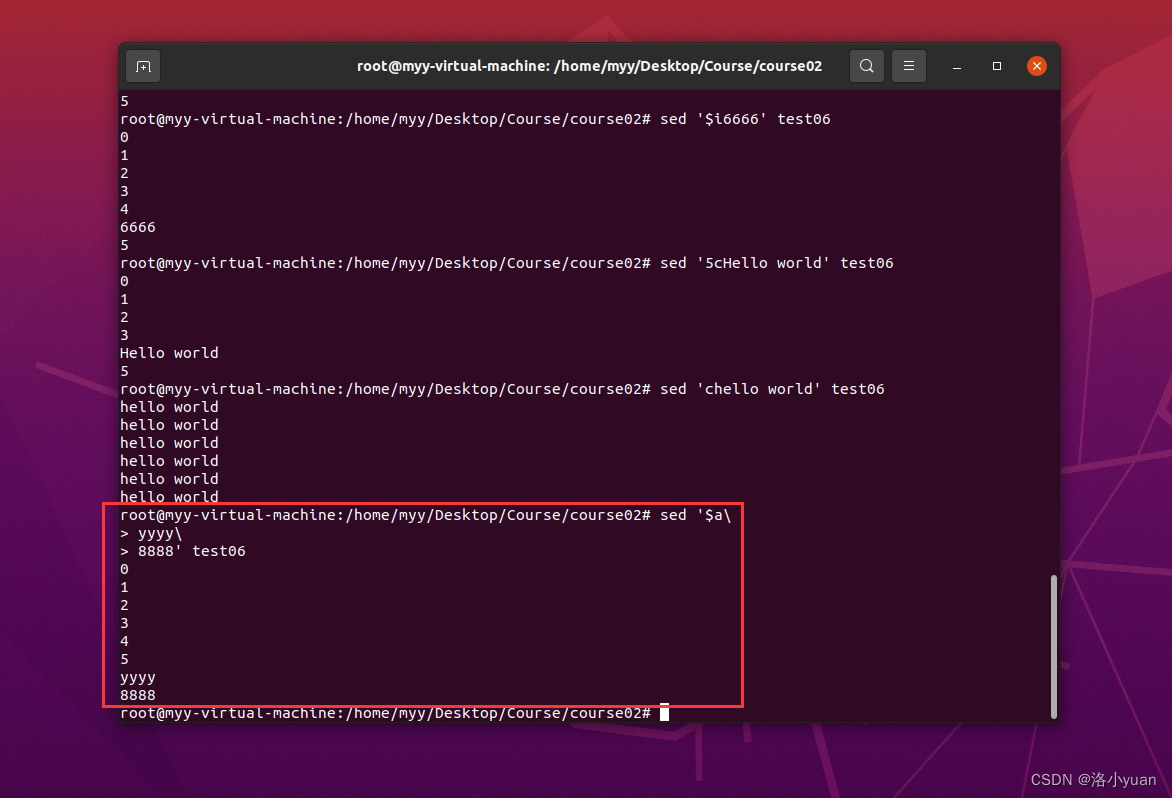
注意:为了实现多行文本插入,在每一行需要加续行符“\”
6.命令r、命令w
- r: 读取指定文件的内容。
- w: 写入指定文件。
将/etc/hosts拷贝到用户家目录下, 重命名为 cp_hosts。对文件执行以下操作:
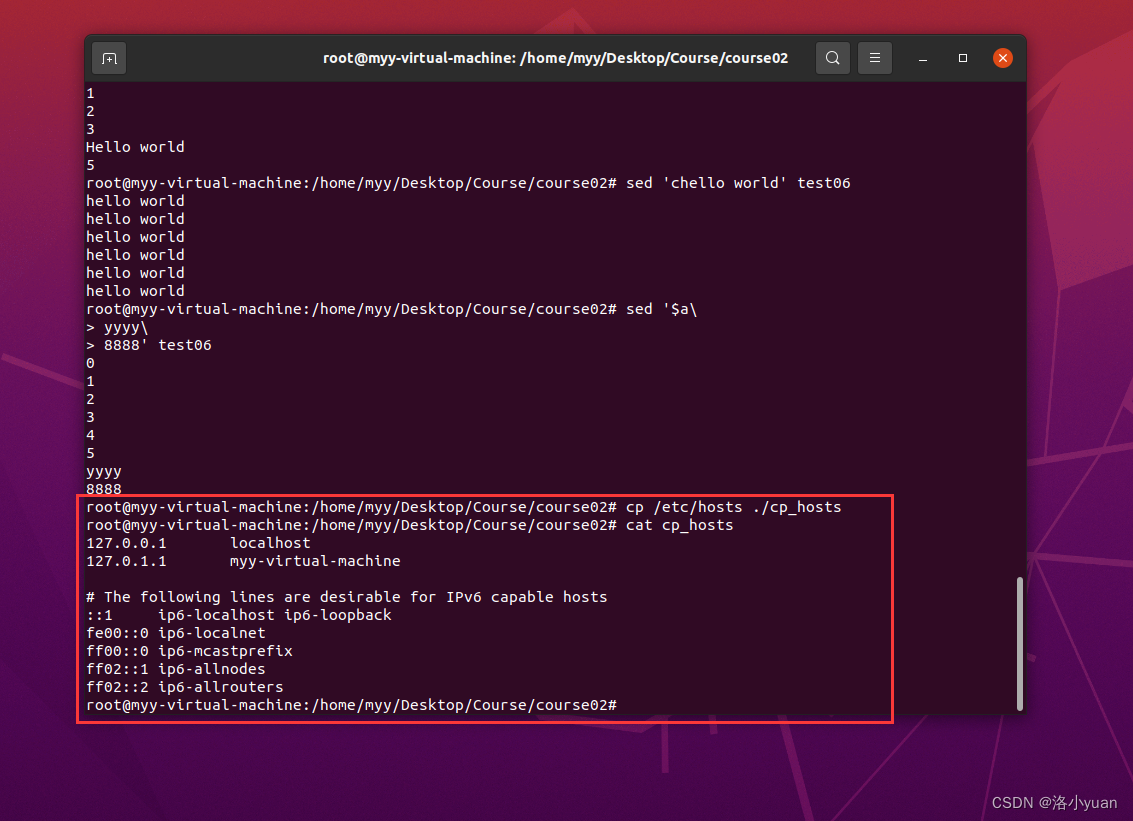
1.将cp_hosts的内容append到test06的第三行后
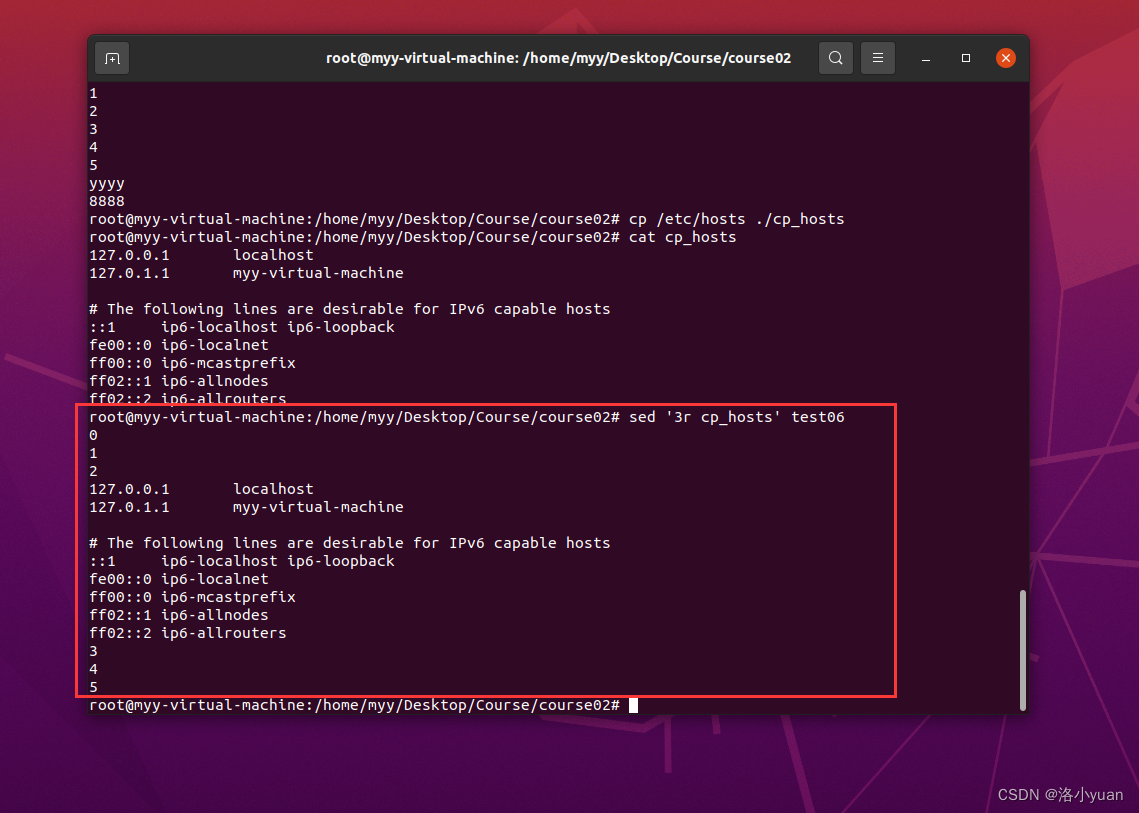
2.将cp_hosts的内容append到test06的末行后:

将/etc/passwd拷贝到用户家目录下,重命名为cp_passwd
1.将test06的内容覆盖写到cp_passwd文件中

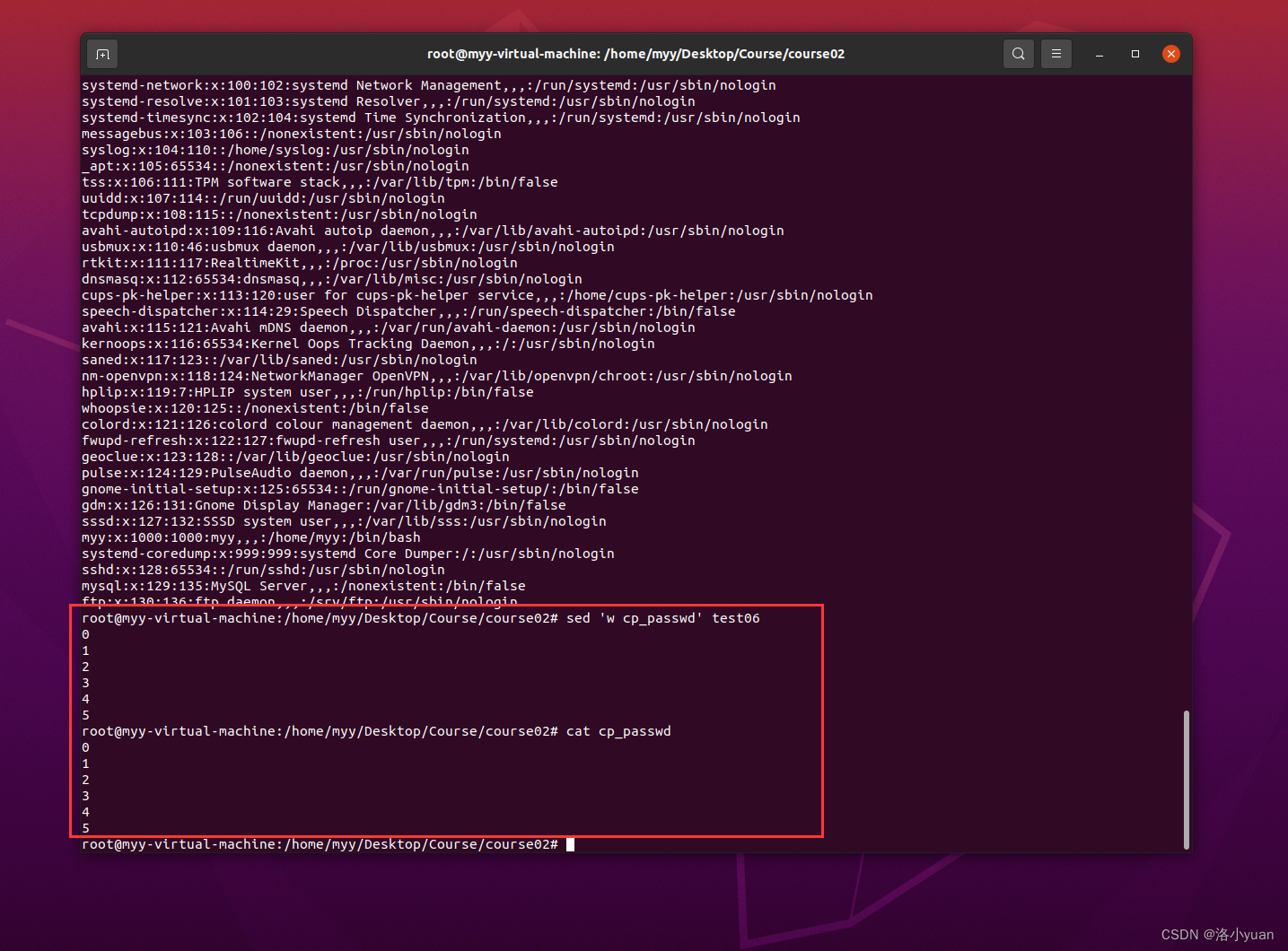
2.将test06的末尾行内容,覆盖写到cp_passwd文件中

7.命令s与参数-i
- s:替换指定字符
- -i:直接将处理结果写到文件中。
在root用户家目录下有文件test07,对该文件进行处理

1.替换test07中的"This"为"Doudou",原文件内容不变
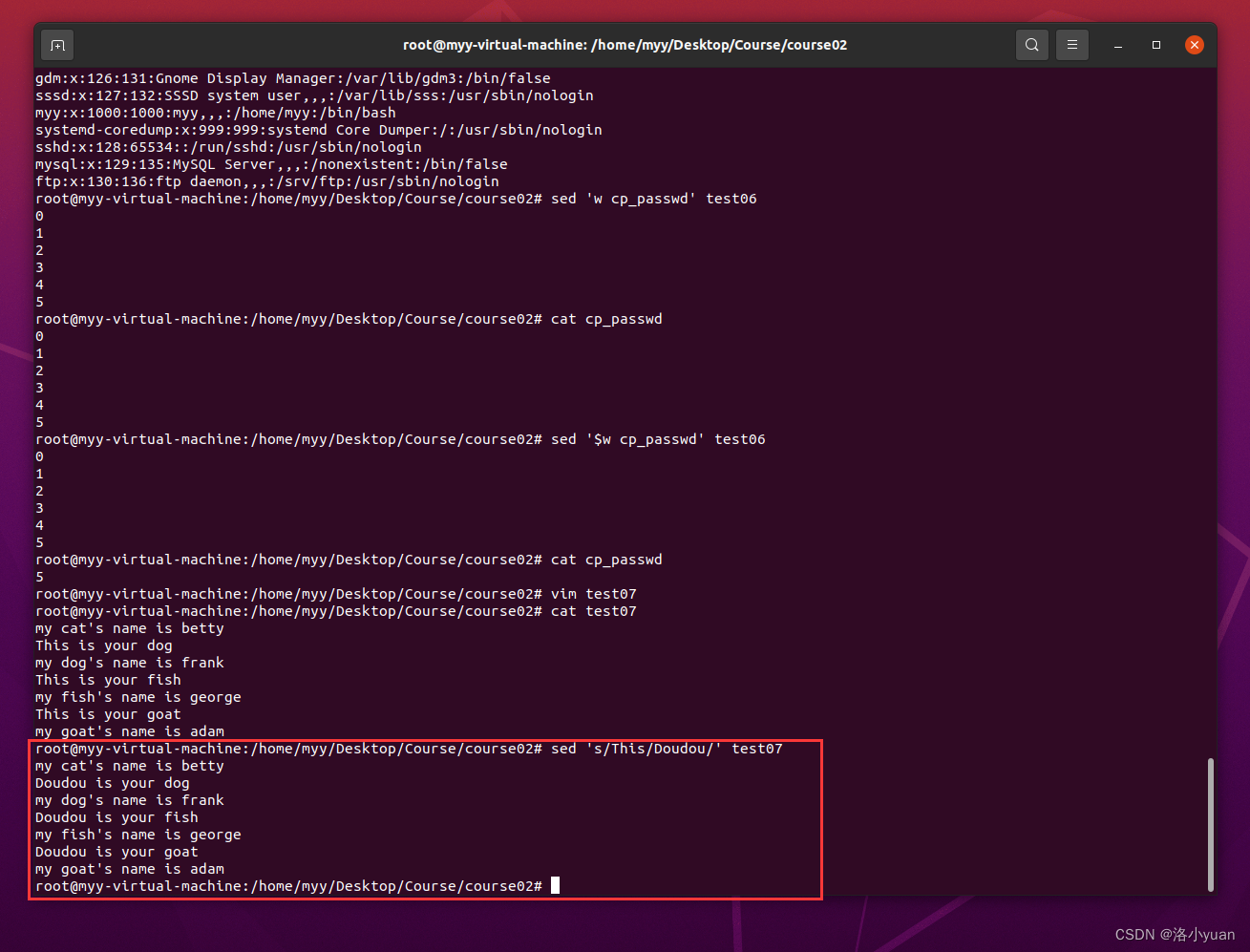
2.修改test07,将其中的"This"替换为"Doubu"


)

















:openssl ssl_read:error:0A000126:报错)