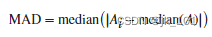目录
- 一、概述
- 1.1 维度
- 1.2 sklearn中的降维算法
- 二、降维实现原理
- 2.1 PCA与SVD
- 2.2 降维实现
- 2.3 降维过程
- 三、鸢尾花数据集降维
- 3.1 高维数据的可视化
- 3.2 探索降维后的数据
- 3.3 累积可解释方差贡献率曲线
- 四、选n_components参数方法
- 4.1 最大似然估计自选超参数
- 4.2 按信息量占比选超参数
一、概述
1.1 维度
1. 对于数组和Series来说,维度就是功能shape返回的结果,shape中返回了几个数字,就是几维。索引以外的数据,不分行列的叫一维(此时shape返回唯一的维度上的数据个数);有行列之分叫二维(shape返回行×列),也称为表。
2. 数组中的每一张表,都可以是一个特征矩阵或一个DataFrame,这些结构永远只有一张表,所以一定有行列,其中行是样本,列是特征。针对每一张表,维度指的是样本的数量或特征的数量,一般无特别说明,指的都是特征的数量。除了索引之外,一个特征是一维,两个特征是二维,n个特征是n维。

3. 对图像来说,维度就是图像中特征向量的数量。特征向量可以理解为是坐标轴,一个特征向量定义一条直线,是一维,两个相互垂直的特征向量定义一个平面,即一个直角坐标系,就是二维,三个相互垂直的特征向量定义一个空间,即一个立体直角坐标系,就是三维。三个以上的特征向量相互垂直,定义人眼无法看见,也无法想象的高维空间。
1.2 sklearn中的降维算法
1. 降维算法中的”降维“,指的是降低特征矩阵中特征的数量。上周的课中我们说过,降维的目的是为了让算法运算更快,效果更好,但其实还有另一种需求:数据可视化。从上面的图我们其实可以看得出,图像和特征矩阵的维度是可以相互对应的,即一个特征对应一个特征向量,对应一条坐标轴。所以,三维及以下的特征矩阵,是可以被可视化的,这可以帮助我们很快地理解数据的分布,而三维以上特征矩阵的则不能被可视化,数据的性质也就比较难理解。
2. sklearn中降维算法都被包括在模块decomposition中,这个模块本质是一个矩阵分解模块。模块其中的SVD和主成分分析PCA都属于矩阵分解算法中的入门算法,都是通过分解特征矩阵来进行降维。
二、降维实现原理
2.1 PCA与SVD
1. 在降维过程中,我们会减少特征的数量,这意味着删除数据,数据量变少则表示模型可以获取的信息会变少,模型的表现可能会因此受影响。同时,在高维数据中,必然有一些特征是不带有效的信息的(比如噪音),或者有一些特征带有的信息和其他一些特征是重复的(比如一些特征可能会线性相关)。
我们希望能够找出一种办法来帮助我们衡量特征上所带的信息量,让我们在降维的过程中,能够即减少特征的数量,又保留大部分有效信息——将那些带有重复信息的特征合并,并删除那些带无效信息的特征等等——逐渐创造出能够代表原特征矩阵大部分信息的,特征更少的,新特征矩阵。
2. 之前的文章中提到过一种重要的特征选择方法:方差过滤。如果一个特征的方差很小,则意味着这个特征上很可能有大量取值都相同(比如90%都是1,只有10%是0,甚至100%是1),那这一个特征的取值对样本而言就没有区分度,这种特征就不带有有效信息。从方差的这种应用就可以推断出,如果一个特征的方差很大,则说明这个特征上带有大量的信息。因此,在降维中,PCA使用的信息量衡量指标,就是样本方差,又称可解释性方差,方差越大,特征所带的信息量越多。
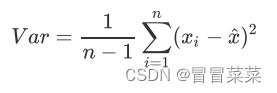
2.2 降维实现
1. 模块:sklearn.decomposition.PCA (n_components=None, copy=True, whiten=False, svd_solver=’auto’, tol=0.0,iterated_power=’auto’, random_state=None)。
2. PCA作为矩阵分解算法的核心算法,其实没有太多参数,但不幸的是每个参数的意义和运用都很难,因为几乎每个参数都涉及到高深的数学原理。为了参数的运用和意义变得明朗,我们来看一组简单的二维数据的降维。
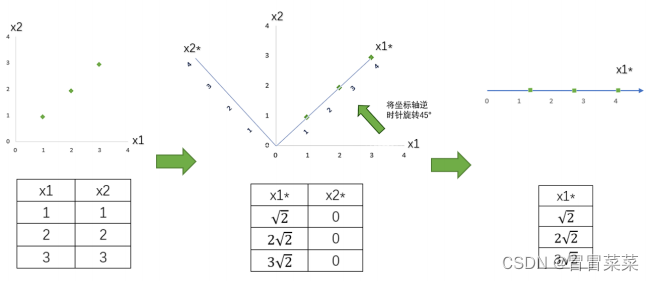
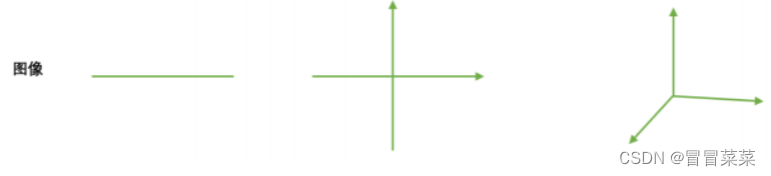
(1)我们现在有一组简单的数据,有特征x1和x2,三个样本数据的坐标点分别为(1,1),(2,2),(3,3)。我们可以让x1和x2分别作为两个特征向量,很轻松地用一个二维平面来描述这组数据。这组数据现在每个特征的均值都为2,方差则等于:

(2)每个特征的数据一模一样,因此方差也都为1,数据的方差总和是2。现在我们的目标是:只用一个特征向量来描述这组数据,即将二维数据降为一维数据,并且尽可能地保留信息量,
即让数据的总方差尽量靠近2。于是,我们将原本的直角坐标系逆时针旋转45°,形成了新的特征向量组成的新平面,方差为:
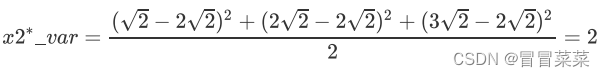
(3)通过旋转原有特征向量组成的坐标轴来找到新特征向量和新坐标平面,我们将三个样本点的信息压缩到了一条直线上,实现了二维变一维,并且尽量保留原始数据的信息。一个成功的降维,就实现了。
2.3 降维过程
1. 结合上面的例子进行过程对比:
| 过程 | 二维特征矩阵 | n维特征矩阵 |
|---|---|---|
| 1 | 输入原数据,结构为 (3,2) ,找出原本的2个特征对应的直角坐标系,本质是找出这2个特征构成的2维平面 | 输入原数据,结构为 (m,n), 找出原本的n个特征向量构成的n维空间V |
| 2 | 决定降维后的特征数量:1 | 决定降维后的特征数量:k |
| 3 | 旋转,找出一个新坐标系,本质是找出2个新的特征向量,以及它们构成的新2维平面,新特征向量让数据能够被压缩到少数特征上,并且总信息量不损失太多 | 通过某种变化,找出n个新的特征向量,以及它们构成的新n维空间V |
| 4 | 找出数据点在新坐标系上,2个新坐标轴上的坐标 | 找出原始数据在新特征空间V中的n个新特征向量上对应的值,即“将数据映射到新空间中” |
| 5 | 选取第1个方差最大的特征向量,删掉没有被选中的特征,成功将2维平面降为1维 | 选取前k个信息量最大的特征,删掉没有被选中的特征,成功将n维空间V降为k维 |
2. 在步骤3当中,我们用来找出n个新特征向量,让数据能够被压缩到少数特征上并且总信息量不损失太多的技术就是矩阵分解。
PCA和SVD是两种不同的降维算法,但他们都遵从上面的过程来实现降维,只是两种算法中矩阵分解的方法不同,信息量的衡量指标不同罢了。
-
PCA使用方差作为信息量的衡量指标,并且特征值分解来找出空间V。降维时,它会通过一系列数学的神秘操作将特征矩阵X分解为三个矩阵。Σ是一个对角矩阵(即除了对角线上有值,其他位置都是0的矩阵),其对角线上的元素就是方差。降维完成之后,PCA找到的每个新特征向量就叫做“主成分”,而被丢弃的特征向量被认为信息量很少,这些信息很可能就是噪音。
-

-
SVD使用奇异值分解来找出空间V,其中Σ也是一个对角矩阵,不过它对角线上的元素是奇异值,这也是SVD中用来衡量特征上的信息量的指标。
-

三、鸢尾花数据集降维
3.1 高维数据的可视化
1. 代码块:
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris #鸢尾花数据集
from sklearn.decomposition import PCA
import pandas as pdiris = load_iris()
y = iris.target
X = iris.data
#print(pd.DataFrame(X)) 可以看到有四个特征,就是四维的特征矩阵pca = PCA(n_components=2) #实例化
pca = pca.fit(X) #拟合模型
X_dr = pca.transform(X) #获取新矩阵
#X_dr = PCA(2).fit_transform(X)
#print(pd.DataFrame(X_dr))colors = ['red', 'black', 'orange']
plt.figure()
for i in [0,1,2]:plt.scatter(X_dr[y == i, 0], X_dr[y == i, 1], alpha = .7 #透明度, c = colors[i], label = iris.target_names[i])
plt.legend()
plt.title('PCA of IRIS dataset')
plt.show()
2. 结果:鸢尾花的分布被展现在我们眼前了,明显这是一个分簇的分布,并且每个簇之间的分布相对比较明显,也许versicolor和virginia这两种花之间会有一些分类错误,但setosa肯定不会被分错。这样的数据很容易分类,可以遇见,KNN,随机森林,神经网络,朴素贝叶斯,Adaboost这些分类器在鸢尾花数据集上,未调整的时候都可以有95%上下的准确率。
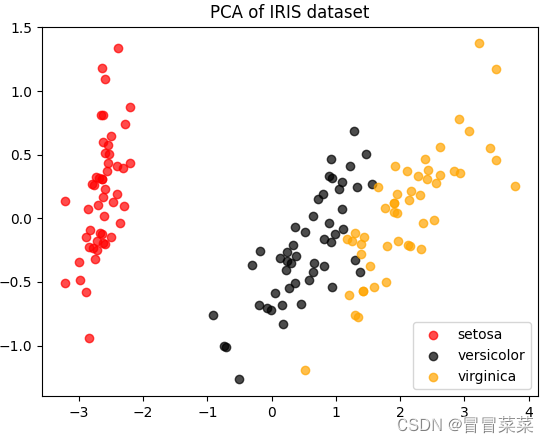
3.2 探索降维后的数据
#属性explained_variance_,查看降维后每个新特征向量上所带的信息量大小(可解释性方差的大小)
print(pca.explained_variance_) #结果:[4.22824171 0.24267075]#属性explained_variance_ratio,查看降维后每个新特征向量所占的信息量占原始数据总信息量的百分比
#又叫做可解释方差贡献率
print(pca.explained_variance_ratio_) #结果:[0.92461872 0.05306648]#大部分信息都被有效地集中在了第一个特征上,效果很好
print(pca.explained_variance_ratio_.sum()) #结果:0.9776852063187949
3.3 累积可解释方差贡献率曲线
1. 当参数n_components中不填写任何值,则默认返回min(X.shape)个特征,一般来说,样本量都会大于特征数目,所以什么都不填就相当于转换了新特征空间,但没有减少特征的个数。一般来说,不会使用这种输入方式。但我们却可以使用这种输入方式来画出累计可解释方差贡献率曲线,以此选择最好的n_components的整数取值。累积可解释方差贡献率曲线是一条以降维后保留的特征个数为横坐标,降维后新特征矩阵捕捉到的可解释方差贡献率为纵坐标的曲线,能够帮助我们决定n_components最好的取值。
2. 代码块:
pca_line = PCA().fit(X)
plt.plot([1,2,3,4],np.cumsum(pca_line.explained_variance_ratio_))
plt.xticks([1,2,3,4]) #这是为了限制坐标轴显示为整数
plt.xlabel("number of components after dimension reduction")
plt.ylabel("cumulative explained variance ratio")
plt.show()

四、选n_components参数方法
4.1 最大似然估计自选超参数
1. 除了输入整数,n_components还有哪些选择呢?之前我们提到过,矩阵分解的理论发展在业界独树一帜,勤奋智慧的数学大神Minka, T.P.在麻省理工学院媒体实验室做研究时找出了让PCA用最大似然估计(maximum likelihood estimation)自选超参数的方法,输入“mle”作为n_components的参数输入,就可以调用这种方法。
2. 代码块:
pca_mle = PCA(n_components="mle")
pca_mle = pca_mle.fit(X)
X_mle = pca_mle.transform(X)
print(pd.DataFrame(X_mle))
#可以发现,mle为我们自动选择了3个特征print(pca_mle.explained_variance_ratio_.sum())
#得到了比设定2个特征时更高的信息含量,对于鸢尾花这个很小的数据集来说,3个特征对应这么高的信息含量,并不需要去纠结于只保留2个特征,毕竟三个特征也可以可视化
4.2 按信息量占比选超参数
1. 输入[0,1]之间的浮点数,并且让参数svd_solver ==‘full’,表示希望降维后的总解释性方差占比大于n_components指定的百分比,即是说,希望保留百分之多少的信息量。比如说,如果我们希望保留97%的信息量,就可以输入n_components = 0.97,PCA会自动选出能够让保留的信息量超过97%的特征数量。
2. 代码块:
pca_f = PCA(n_components=0.97,svd_solver="full")
pca_f = pca_f.fit(X)
X_f = pca_f.transform(X)
print(pca_f.explained_variance_ratio_)







![SpringMVC自定义注解---[详细介绍]](https://img-blog.csdnimg.cn/6416408a92cf4728b2eeb305a06df3d7.png)