背景
针对AI解题业务场景,靠着ToT、CoT等提示词规则去引导模型的输出答案,一定程度相比Zero-shot解答质量更高(正确率、格式)等。但是针对某些测试CASE,LLM仍然不能输出期望的正确结果,将AI解题应用生产仍有距离,因此需要另寻其他方案提高LLM在AI解题业务场景的可应用性。
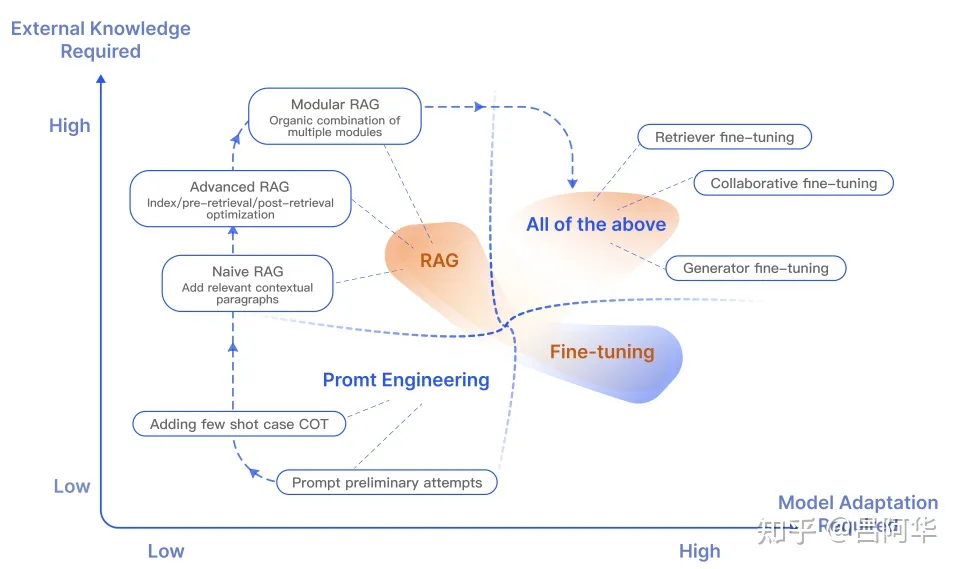
提升LLM针对某业务应用能力常见的方案有:模型微调、提示词工程、检索增强生成**RAG(Retrieval-Augmented Generation)**即从外部数据库获取额外信息辅助模型生成内容,比如AI解题场景可以利用题库已经生产的试题答案、解析辅助LLM生成内容,特别是对知识密集型任务,可以一定程度提升LLM在某场景下能力。
背景知识
1、关于Transformer
GPT 模型的基本原则是通过语言建模将世界知识压缩到仅解码器 (decoder-only) 的 Transformer 模型中,这样它就可以恢复(或记忆)世界知识的语义,并充当通用任务求解器。
Transformer 是一种基于注意力机制(Attention Mechanism)的深度学习模型,它在自然语言处理(NLP)领域取得了革命性的进展。该模型最初由 Vaswani 等人在 2017 年的论文《Attention Is All You Need》中提出。与传统的循环神经网络(RNN)和卷积神经网络(CNN)不同,Transformer 完全依赖于注意力机制来处理序列数据,这使得它在处理长距离依赖问题上具有显著优势,并且能够进行高效的并行计算。
**Transformer 模型的核心思想是通过自注意力(Self-Attention)机制来捕捉序列内部不同位置之间的依赖关系。简单理解就是理解语意,**这种机制允许模型在计算当前位置的表示时,同时考虑序列中其他位置的信息,从而更好地理解序列的全局结构。
Transformer 模型主要由两大部分组成:编码器(Encoder)和解码器(Decoder)。
- 编码器:由多个相同的编码器层(Encoder Layer)堆叠而成,每一层包含两个子层:多头自注意力机制(Multi-Head Self-Attention)和位置全连接前馈网络(Position-Wise Feed-Forward Networks)。编码器的作用是将输入序列转换成一系列连续的表示,这些表示捕捉了序列中每个元素的上下文信息。
- 解码器:同样由多个相同的解码器层(Decoder Layer)堆叠而成,每一层包含三个子层:多头自注意力机制、编码器-解码器注意力机制(Encoder-Decoder Attention)和位置全连接前馈网络。解码器的作用是利用编码器的输出和之前已经生成的输出来生成下一个元素。
Transformer 模型的这些特性使其在机器翻译、文本摘要、问答系统等多个 NLP 任务中取得了优异的表现,并且催生了一系列基于 Transformer 的预训练模型,如 BERT、GPT等。
- BART模型是使用标准Transformer模型整体结构的预训练语言模型。作为一种强大的NLP模型,BART被广泛应用于各种任务中,例如文本摘要、文本翻译、文本生成等。在文本翻译任务中,BART能够同时处理源语言和目标语言的句子,并生成高质量的翻译结果。在文本摘要任务中,预训练BART能够对长篇文档进行总结,生成简洁明了的摘要。在文本生成任务中,BART能够根据给定的输入序列,生成与输入序列相关的新文本。
- BERT模型是仅使用Transformer-Encoder结构的预训练语言模型。BERT的预训练包括两个主要任务:掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)。MLM任务通过随机遮蔽输入文本中的一些词,然后让模型预测这些遮蔽词,从而学习语言的上下文关系。NSP任务则是让模型预测两个句子是否是连续的文本,从而学习句子间的关系。比较适合没有文本生成的任务如文本分类、实体识别。
- GPT模型是仅使用Transformer-Decoder结构的预训练语言模型。GPT采用了自回归语言模型(Autoregressive Language Model)作为其预训练任务。在这个任务中,模型被训练为基于给定文本的前文来预测下一个词,这种方式使得GPT能够生成连贯和流畅的文本。预训练:GPT在大量的文本数据上进行预训练,学习语言的通用模式和知识。比较适合文本生成。
【论文解读】Transformer: Attention is all you need
使用Transformer加载预训练模型demo
from transformers import GPT2Tokenizer, GPT2LMHeadModel# 加载预训练模型和分词器
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')# 编码输入文本
input_text = "The quick brown fox jumps over the lazy dog"
input_ids = tokenizer.encode(input_text, return_tensors='pt')# 生成文本
output = model.generate(input_ids, max_length=50, num_return_sequences=1)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)print(generated_text)使用Transformer微调预训练模型demo
步骤 1: 安装必要的库,确保你已经安装了transformers和torch库。如果没有安装,可以通过以下命令安装:
pip install transformers torch
步骤 2: 准备聊天数据,为了微调模型,你需要准备聊天数据。这里我们假设你已经有了一个格式化的数据集,其中包含了输入文本和对应的回复。为了简化示例,我们将直接在代码中定义一小部分数据。
# 示例聊天数据
chat_data = [{"input": "Hello, how are you?", "reply": "I am fine, thank you."},{"input": "What is your name?", "reply": "I am a chatbot."},# 添加更多数据...
]
步骤 3: 加载预训练模型和分词器,我们将使用GPT-2作为基础模型进行微调。
from transformers import GPT2Tokenizer, GPT2LMHeadModel, AdamW, get_linear_schedule_with_warmup# 加载预训练的模型和分词器
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
步骤 4: 数据预处理,将聊天数据转换为模型可以理解的格式。
# 编码聊天数据
inputs = [tokenizer.encode(f"input: {data['input']} reply:", add_special_tokens=True) for data in chat_data]
replies = [tokenizer.encode(data['reply'], add_special_tokens=True) for data in chat_data]
步骤 5: 微调模型,接下来,我们将在聊天数据上微调模型。这里只展示了一个非常简化的训练循环,实际应用中可能需要更复杂的数据处理和训练逻辑。
import torch# 简单的训练循环
optimizer = AdamW(model.parameters(), lr=5e-5)
for epoch in range(1): # 假设只训练1个epochmodel.train()for input_ids, reply_ids in zip(inputs, replies):optimizer.zero_grad()# 将输入和回复拼接起来作为模型的输入input_ids = torch.tensor(input_ids).unsqueeze(0)reply_ids = torch.tensor(reply_ids).unsqueeze(0)inputs_and_reply = torch.cat((input_ids, reply_ids), dim=1)outputs = model(inputs_and_reply, labels=inputs_and_reply)loss = outputs.lossloss.backward()optimizer.step()print(f"Epoch {epoch}, Loss: {loss.item()}")
步骤 6: 使用微调后的模型,微调完成后,你可以使用微调后的模型进行聊天。
# 使用微调后的模型生成回复
input_text = "Hello, how are you?"
input_ids = tokenizer.encode(f"input: {input_text} reply:", return_tensors='pt')
output = model.generate(input_ids, max_length=50, num_return_sequences=1)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)print(generated_text)
自监督学习和自注意力机制
Transformer架构核心就是自注意力机制,自注意力机制通过计算每个单词对句子中其他所有单词的注意力得分来工作。这些得分表示在处理当前单词时,其他单词的重要性程度。然后,这些得分被用来生成加权的单词表示,这些表示捕获了整个句子的上下文信息。
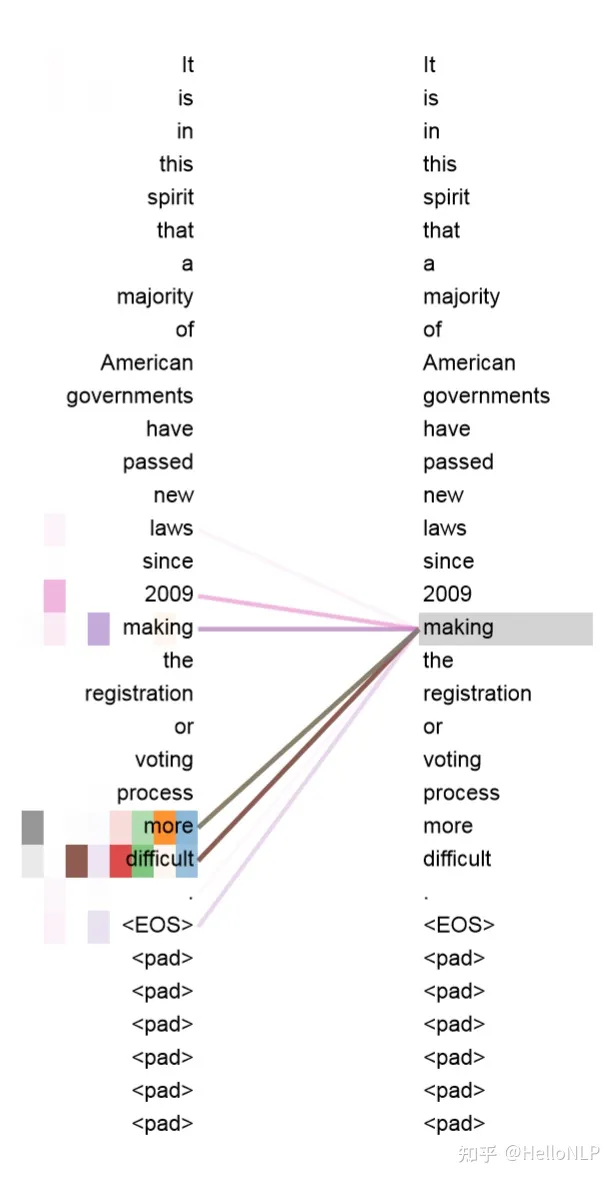
对于预训练模型Bert、ChatGPT等模型,采用自监督学习进行模型预训练,就是不需要额外的数据标注,通过借助辅助的训练任务,比如辅助任务(Pretext Task)来从数据本身学习有用的特征表示。自监督学习的关键在于设计这样的辅助任务,使得模型能够从未标注的数据中学习到有用的信息。
总的来说,自注意力机制为自监督学习提供了强大的工具,使得模型能够在无监督的条件下学习到有用的特征表示,这对于提高模型的泛化能力和解决标注数据稀缺的问题具有重要意义。
2、关于RAG
大型语言模型(LLM)相较于传统的语言模型具有更强大的能力,然而在某些情况下,它们仍可能无法提供准确的答案。为了解决大型语言模型在生成文本时面临的一系列挑战,提高模型的性能和输出质量,研究人员提出了一种新的模型架构:检索增强生成(RAG, Retrieval-Augmented Generation)。该架构巧妙地整合了从庞大知识库中检索到的相关信息,并以此为基础,指导大型语言模型生成更为精准的答案,从而显著提升了回答的准确性与深度。
- 知识的局限性:模型自身的知识完全源于它的训练数据,而现有的主流大模型(ChatGPT、文心一言、通义千问…)的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的,这部分知识也就无从具备。
- 幻觉问题:所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它有时候会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识。
- 数据安全性:对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
而RAG是解决上述问题的一套有效方案。
3、关于AI解题现状
在使用未进行微调的ChatGPT4 + 系列提示词规则优化后,对于英语学科的单选、翻译、阅读理解等解题质量(解答正确率、知识范围)不能满足直接投入AI解题生产(目前教研挑选的少量CASE测评正确率普遍在95%以上,具有片面、随机性)
目前提示词规则运用了系列规则,如易错题IoT、提示词思维树ToT等,准确率一定提升,仍面临的问题
- 易错题IoT需要手动配置,目前是加载上下文,支持的数量有限,可能会重复配置,另外是错题应该是分类的,吧每个都配置也不现实。
- 需要教研进行监督和纠正AI解题的答案,生成的答案可信度无法度量,不能直接投入使用。
- …
另基本可以得出结论仅靠提示词规则已经无法再提高模型的应用能力。
出现解答试题错误的一种原因就是LLM预训练的知识(记忆)范围不能很好的涉及某些试题、知识点。
针对这种原因以及易错题IoT目前问题,可以考虑运用现有题库利用RAG框架进行检索增强生成,即搜索知识点 or已经正确生产的相似题 相关知识结合代解答的试题传给LLM让其解答,拓展LLM的知识(记忆)以及一些思维思考规则,提高模型能解题场景应用能力。
需要学习RAG相关知识,可行性研究,设计使用架构,实验测评等。
4、关于词向量
在RAG(Retrieval Augmented Generation,检索增强生成)方面词向量的优势主要有两点:-
- 词向量比文字更适合检索。当我们在数据库检索时,如果数据库存储的是文字,主要通过检索关键词(词法搜索)等方法找到相对匹配的数据,匹配的程度是取决于关键词的数量或者是否完全匹配查询句的;但是词向量中包含了原文本的语义信息,可以通过计算问题与数据库中数据的点积、余弦距离、欧几里得距离等指标,直接获取问题与数据在语义层面上的相似度;
- 词向量比其它媒介的综合信息能力更强,当传统数据库存储文字、声音、图像、视频等多种媒介时,很难去将上述多种媒介构建起关联与跨模态的查询方法;但是词向量却可以通过多种向量模型将多种数据映射成统一的向量形式。
RAG论文学习
论文1-RAG概述
论文 Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (知识密集型 NLP 任务的检索增强生成)作者们探讨了如何通过结合预训练的语言模型和非参数记忆(即检索机制)来提高自然语言处理(NLP)任务的性能,特别是在需要大量知识密集型任务中。
预训练的神经语言模型已经显示出从数据中学习大量深入知识的能力,但这些模型无法轻松扩展或修改它们的记忆,也不能直接提供对其预测的洞察,有时还可能产生“幻觉”。混合模型结合了参数记忆和非参数(即基于检索的)记忆,可以解决一些问题,因为知识可以直接修改和扩展,访问的知识可以被检查和解释。
作者在多种知识密集型任务中进行了RAG实验,包括开放域问答、抽象问答生成、Jeopardy问题生成和事实验证。RAG在开放域问答任务上取得了新的最先进水平,并在生成任务中表现出更好的性能。

RAG框架,RAG在LLM应用场景中分为
- 基础RAG:最原始部分,结合了信息检索和文本生成两个阶段,当模型收到一个查询任务,首先从数据库搜索相关的信息片段,然后送进生成器模型,该模型结合原始查询和检索到的信息来生成回答。基础RAG的关键在于它将检索和生成紧密结合,使得生成的回答能够利用检索到的实时外部信息。
- 高级RAG:基础RAG的改进,引入预检索、后检索优化策略,预检索阶段会对查询重写或者拓展来提高检索的准确性以及相关性,后检索阶段对检索到的信息进一步处理,如重排序,信息压缩或合成等,更好的为生成服务。
- 模块RAG:更加灵活的RAG,允许根据应用需求进行替换重新配置,模块化设计,动态选取检索模块、生成器。
优化高效和准确的检索,实现高效而准确的搜索设计两部分优化,文档块大小(Document Chunk Size)优化和向量模型(Embedding Models)优化,而考虑到RAG的使用者未必有能力/资源进行模型优化,所以可以着重关注文档大小优化部分。
文中阐述的内容大致如下:
较小的文档块可以提高信息检索的精确度,但可能丢失上下文;较大的块提供更多上下文,但可能包含不相关信息。使用者可以根据内容复杂度或查询性质,动态调整块的大小。并通过不同块大小的测试,找到最佳平衡点。
第4节还提到用**查询重写(Query Rewrite)和向量转换(Embedding Transformation)**来对齐用户查询和文档的语义空间,以及使用监督训练(Supervised Training)让检索器的输出与大型语言模型的偏好相对齐,想了解细节的可以阅读原文。
优化生成器,生成器决定了最终呈现给用户的答案,文中也给出一些优化的方案。检索得到相应信息后,在提交至生成器之前需要进行后检索处理(Post-retrieval Processing),指的是进一步处理、过滤或优化检索器从大型文档数据库中检索到的相关信息。然后再进行信息压缩(Information Compression)和结果重排(Result Rerank)。这一过程的主要目的是提高检索结果的质量,以更好地满足用户需求或后续任务。比如减轻上下文长度限制和对冗余信息的易感性。
论文2-RAG优化思路概述
论文 《A Guide on 12 Tuning Strategies for Production-Ready RAG Applications》towardsdatascience.com/a-guide-on-12-tuning-strategies-for-production-ready-rag-applications-7ca646833439 用于生产就绪RAG应用的12种调优策略指南,论文提供优化思路,主要分为构建RAG管道、查询搜索阶段。
在RAG管道的摄取阶段,主要关注的是数据的准备和处理,以及如何有效地存储和索引数据。
- 数据清理(Data Cleaning):这个阶段需要确保数据质量,包括基本的自然语言处理清理技术,确保信息一致性和事实准确性。
- 分块(Chunking):将文档分割成逻辑上连贯的信息片段,这可能涉及将长文档分割成较小部分或将较小片段组合成连贯段落。
- 向量模型(Embedding Models):向量模型是检索的核心,向量的质量极大影响检索结果。可以考虑使用不同的向量模型,有条件的话可以对特定用例进行微调。
- 元数据(Metadata):在向量数据库中存储向量时,可以添加元数据,以便于后续的搜索结果后处理。
- 多索引(Multi-indexing):如果元数据不足以提供额外信息以逻辑上分隔不同类型的上下文,可以尝试使用多个索引。
- 索引算法(Indexing Algorithms):选择和调整近似最近邻(ANNS)搜索算法,比如Facebook的Faiss、Spotify的Annoy、Google的ScaNN和HNSWLIB。
在查询搜索阶段,推理阶段涉及检索和生成过程,主要关注如何改进检索结果的相关性和生成响应的质量。
- 查询转换(Query Transformations):如果搜索查询未产生满意的结果,可以尝试不同的查询转换技术,如重新措辞(Rephrasing)、**假设文档嵌入(HyDE) **或 子查询(Sub-queries)。
- 检索参数(Retrieval Parameters):考虑是否需要语义搜索或混合搜索,并调整聚合稀疏和密集检索方法的权重。
- 高级检索策略(Advanced Retrieval Strategies):探索高级检索策略,如句子窗口检索或自动合并检索。
- 重新排序模型(Re-ranking Models):使用重新排序模型来消除不相关的搜索结果。
- **大语言模型(LLMs): **LLM是生成响应的核心组件。可以根据需求选择不同的LLM,并考虑针对特定用例进行微调。
- **提示词工程(Prompt Engineering): **提示词的使用将显著影响LLM的完成情况。
论文3-RAG优化之混合搜索
论文 《Improving Retrieval Performance in RAG Pipelines with Hybrid Search》 主要讨论了如何通过结合传统的基于关键词的搜索和当下流行的向量搜索来找到更相关的搜索结果,以提高RAG管道的性能。在RAG管道的开发中,达到初步的80%性能相对容易,但要实现剩余的20%以达到生产就绪状态则颇具挑战。作者强调,改进RAG管道的检索组件是一个常见的主题,其中**混合搜索(Hybrid Search)**是一个重要的策略。
混合搜索的概念
Hybrid search is a search technique that combines two or more search algorithms to improve the relevance of search results. Although it is not defined which algorithms are combined, hybrid search most commonly refers to the combination of traditional keyword-based search and modern vector search.
混合搜索是一种搜索技术,它结合了两种或多种搜索算法,以提高搜索结果的相关性。虽然没有定义组合哪些算法,但混合搜索通常是指传统的基于关键字的搜索和现代矢量搜索的组合。
Traditionally, keyword-based search was the obvious choice for search engines. But with the advent of Machine Learning (ML) algorithms, vector embeddings enabled a new search technique — called vector or semantic search — that allowed us to search across data semantically. However, both search techniques have essential tradeoffs to consider:
传统上,基于关键字的搜索是搜索引擎的首选。但是随着机器学习(ML)算法的出现,向量嵌入启用了一种新的搜索技术-称为向量或语义搜索-允许我们在语义上搜索数据。然而,这两种搜索技术都有必要考虑的权衡:
- Keyword-based search: While its exact keyword-matching capabilities are beneficial for specific terms, such as product names or industry jargon, it is sensitive to typos and synonyms, which lead it to miss important context.基于关键字的搜索:虽然其精确的关键词匹配功能对特定术语(如产品名称或行业术语)是有益的,但它对错别字和同义词很敏感,这导致它错过了重要的上下文。
- Vector or semantic search: While its semantic search capabilities allow multi-lingual and multi-modal search based on the data’s semantic meaning and make it robust to typos, it can miss essential keywords. Additionally, it depends on the quality of the generated vector embeddings and is sensitive to out-of-domain terms.基于矢量或语义搜索:虽然它的语义搜索功能允许基于数据的语义进行多语言和多模式搜索,并使其对拼写错误具有鲁棒性,但它可能会错过重要的关键字。此外,它取决于生成的向量嵌入的质量,并且对域外项敏感。
混合搜索的过程,混合搜索结合了基于关键字和矢量搜索技术,通过融合它们的搜索结果并重新排序。需要结合具体场景调整权重参数。
根据您的上下文类型和查询,您必须确定三种搜索技术中哪一种对您的RAG应用程序最有益。因此,控制基于关键字的搜索和语义搜索之间的权重的参数alpha可以被视为需要调整的超参数。
# 混合搜索得分# alpha = 1: Pure vector search 向量搜索权重
# alpha = 0: Pure keyword search 关键词搜索权重
hybrid_score = (1 - alpha) * sparse_score + alpha * dense_score对比关键词搜索和向量搜索的一个的在线demo:awesome-moviate
混合搜索适合什么场景
When Would You Use Hybrid Search (Hybrid Search Use Cases)
什么时候使用混合搜索(混合搜索用例)
Hybrid search is ideal for use cases where you want to enable semantic search capabilities for a more human-like search experience but also require exact phrase matching for specific terms, such as product names or serial numbers.
混合搜索是理想的用例,您希望启用语义搜索功能以获得更人性化的搜索体验,但也需要对特定术语(如产品名称或序列号)进行精确的短语匹配。
RAG实践
实践结合 LangChain 进行操作管理、OpenAI 语言模型和 Weaviate 向量数据库,来实现一个简易的 RAG 流程。参考:
检索增强生成(RAG):从理论到 LangChain 实践 [译]、
GitHub - langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications
LangChain入门:构建LLM-Powered应用程序的初学者指南
langchain-openai-demo
# 简单使用LangChain + OpenAI的demo,需要代理import langchain
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParserfrom langchain_openai import ChatOpenAI
import os# insert your API_TOKEN here
os.environ["OPENAI_API_KEY"] = 'sk-xxx'if __name__ == '__main__':llm = ChatOpenAI(openai_api_key="sk-xxx")# print(llm.invoke("how can langsmith help with testing?"))# 使用langchainprompt = ChatPromptTemplate.from_messages([("system", "You are world class technical documentation writer."),("user", "{input}")])output_parser = StrOutputParser()# 上面代码中我们使用 LCEL 将不同的组件拼凑成一个链,# 在此链中,用户输入传递到提示模板,然后提示模板输出传递到模型,# 然后模型输出传递到输出解析器。| 的符号类似于 Unix 管道运算符,# 它将不同的组件链接在一起,# 将一个组件的输出作为下一个组件的输入。chain = prompt | llm | output_parserchain.invoke({"input": "how can langsmith help with testing?"})由于访问OpenAI接口需要代理,因此可以使用其他开源的模型,参考(推荐还是最新的英文文档):https://python.langchain.com/docs/integrations/llms/huggingface_pipelines、https://python.langchain.com/docs/integrations/llms/huggingface_endpoint
huggingface-demo
如何使用使用Huggingface Hub的开源模型,离线共有三种方式,任选一种即可https://www.langchain.com.cn/modules/models/llms/integrations/huggingface_hub
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch# 使用提前下载文件,这个模型要收费
hf_YOUR_TOKEN = 'sk-xxx'
tokenizer = AutoTokenizer.from_pretrained("databricks/dbrx-instruct", trust_remote_code=True, token=hf_YOUR_TOKEN)
model = AutoModelForCausalLM.from_pretrained("databricks/dbrx-instruct", device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True, token=hf_YOUR_TOKEN)# 保存到指定文件夹
tokenizer.save_pretrained("./models/databricks/bigscience_t0")
model.save_pretrained("./models/databricks/bigscience_t0")input_text = "What does it take to build a great LLM?"
messages = [{"role": "user", "content": input_text}]
input_ids = tokenizer.apply_chat_template(messages, return_dict=True, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")outputs = model.generate(**input_ids, max_new_tokens=200)
print(tokenizer.decode(outputs[0]))# 如huggingface在线的一个开源模型
# https://huggingface.co/databricks/dbrx-instruct,
# 使用如果报下面错可以考虑把模型下载到本地OSError: We couldn't connect to 'https://huggingface.co' to load this
file, couldn't find it in the cached files and it looks like databric
ks/dbrx-instruct is not the path to a directory containing a file nam
ed config.json.或者使用阿里开元社区开源模型,参考:https://www.modelscope.cn/models/qwen/Qwen1.5-MoE-A2.7B/summary
from modelscope import snapshot_download, AutoTokenizer, AutoModelForCausalLM
import torch
model_dir = snapshot_download("Shanghai_AI_Laboratory/internlm-7b", revision='v1.0.2')
tokenizer = AutoTokenizer.from_pretrained(model_dir, device_map="auto", trust_remote_code=True)
if __name__ == '__main__':# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and might cause OOM Error.model = AutoModelForCausalLM.from_pretrained(model_dir,device_map="auto", offload_folder="offload", trust_remote_code=True, torch_dtype=torch.float16)model = model.eval()inputs = tokenizer(["A beautiful flower"], return_tensors="pt")# for k,v in inputs.items():# inputs[k] = v.cuda()gen_kwargs = {"max_length": 128, "top_p": 0.8, "temperature": 0.8, "do_sample": True, "repetition_penalty": 1.1}output = model.generate(**inputs, **gen_kwargs)output = tokenizer.decode(output[0].tolist(), skip_special_tokens=True)print(output)#A beautiful flower box made of white rose wood. It is a perfect gift for weddings, birthdays and anniversaries.#All the roses are from our farm Roses Flanders. Therefor you know that these flowers last much longer than those in store or online!</s>
langchain-rag-demo
RAG流程分为数据处理、检索、增强、生成
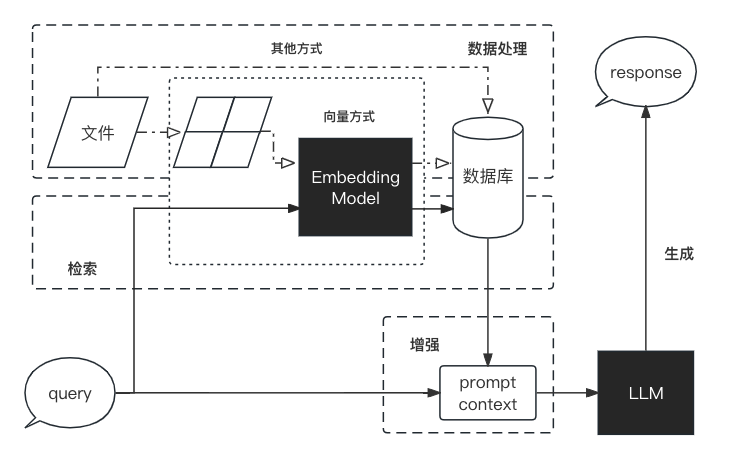
框架:LangChain
Embedding模型:GPT、智谱、M3E
数据库:Chroma
大模型:GPT、讯飞星火、文心一言、GLM 等
前后端:Gradio 和 Streamlit
llm接入langchain
使用千帆平台的文心模型
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplatefrom wenxin_llm import Wenxin_LLMfrom dotenv import find_dotenv, load_dotenv
import os# 读取本地/项目的环境变量。# find_dotenv()寻找并定位.env文件的路径
# load_dotenv()读取该.env文件,并将其中的环境变量加载到当前的运行环境中
# 如果你设置的是全局的环境变量,这行代码则没有任何作用。
_ = load_dotenv(find_dotenv())# 获取环境变量 API_KEY
wenxin_api_key = os.environ["QIANFAN_AK"]
wenxin_secret_key = os.environ["QIANFAN_SK"]if __name__ == '__main__':# 封装langchain接口调用llm = Wenxin_LLM(api_key=wenxin_api_key, secret_key=wenxin_secret_key, system="你是一个助手!")# 2、直接调用# llm = QianfanLLMEndpoint(streaming=True)# res = llm("你好,请你自我介绍一下!")# print(res)prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")output_parser = StrOutputParser()chain = prompt | llm | output_parserprint(chain.invoke({"topic": "ice cream"}))
ps:对于第一种方式,需要定义继承langchain LLM的类
#!/usr/bin/env python
# -*- encoding: utf-8 -*-from typing import Any, List, Mapping, Optional, Dict
from langchain_core.callbacks.manager import CallbackManagerForLLMRun
from langchain_core.language_models.llms import LLM
import qianfan# 继承自 langchain.llms.base.LLM
class Wenxin_LLM(LLM):# 默认选用 ERNIE-Bot-turbo 模型,即目前一般所说的百度文心大模型model: str = "ERNIE-Bot-turbo"# 温度系数temperature: float = 0.1# API_Keyapi_key: str = None# Secret_Keysecret_key: str = None# 系统消息system: str = Nonedef _call(self, prompt: str, stop: Optional[List[str]] = None,run_manager: Optional[CallbackManagerForLLMRun] = None,**kwargs: Any):def gen_wenxin_messages(prompt):'''构造文心模型请求参数 messages请求参数:prompt: 对应的用户提示词'''messages = [{"role": "user", "content": prompt}]return messageschat_comp = qianfan.ChatCompletion(ak=self.api_key, sk=self.secret_key)message = gen_wenxin_messages(prompt)resp = chat_comp.do(messages=message,model=self.model,temperature=self.temperature,system=self.system)return resp["result"]# 首先定义一个返回默认参数的方法@propertydef _default_params(self) -> Dict[str, Any]:"""获取调用Ernie API的默认参数。"""normal_params = {"temperature": self.temperature,}# print(type(self.model_kwargs))return {**normal_params}@propertydef _llm_type(self) -> str:return "Wenxin"@propertydef _identifying_params(self) -> Mapping[str, Any]:"""Get the identifying parameters."""return {**{"model": self.model}, **self._default_params}
ps:LangChain 的 LangChain Expression Language (LCEL)语法支持,LangChain表达式语言或LCEL是一种声明式的方式,可以轻松地将链组合在一起。LCEL从第一天开始就被设计为支持将原型投入生产,没有代码更改,从最简单的 “prompt + LLM” 链到最复杂的链(我们已经看到人们成功地在生产中运行了100多个步骤的LCEL链)。翻译官网文档https://blog.agiexplained.com/2024/03/17/LangChain-LCEL-intro/index.html
搭建知识库
测试使用相关工具包加载pdf文件,完成简单数据清洗、数据分割、数据embedding存储到向量数据库Chroma
数据分割:单个文档的长度往往会超过模型支持的上下文,导致检索得到的知识太长超出模型的处理能力
需要将单个文档按长度或者按固定的规则分割成若干个 chunk,然后将每个 chunk 转化为词向量,存储到向量数据库中。
在检索时,我们会以 chunk 作为检索的元单位,也就是每一次检索到 k 个 chunk 作为模型可以参考来回答用户问题的知识,这个 k 是我们可以自由设定的。
Langchain 中文本分割器都根据 chunk_size (块大小)和 chunk_overlap (块与块之间的重叠大小)进行分割。
- chunk_size 指每个块包含的字符或 Token (如单词、句子等)的数量
- chunk_overlap 指两个块之间共享的字符数量,用于保持上下文的连贯性,避免分割丢失上下文信息
数据清洗与分割demo
import re
from langchain.document_loaders.pdf import PyMuPDFLoader
'''
* RecursiveCharacterTextSplitter 递归字符文本分割
RecursiveCharacterTextSplitter 将按不同的字符递归地分割(按照这个优先级["\n\n", "\n", " ", ""]),这样就能尽量把所有和语义相关的内容尽可能长时间地保留在同一位置
RecursiveCharacterTextSplitter需要关注的是4个参数:* separators - 分隔符字符串数组
* chunk_size - 每个文档的字符数量限制
* chunk_overlap - 两份文档重叠区域的长度
* length_function - 长度计算函数
'''
# 导入文本分割器
from langchain.text_splitter import RecursiveCharacterTextSplitter"""
数据清洗
"""
def data_cleaning(pdf_pages):for pdf_page in pdf_pages:# 匹配了一个前后不是中文字符的换行符。pattern = re.compile(r'[^\u4e00-\u9fff](\n)[^\u4e00-\u9fff]', re.DOTALL)pdf_page.page_content = re.sub(pattern, lambda match: match.group(0).replace('\n', ''), pdf_page.page_content)pdf_page.page_content = pdf_page.page_content.replace('•', '')pdf_page.page_content = pdf_page.page_content.replace(' ', '')pdf_page.page_content = pdf_page.page_content.replace('\n\n', '\n')return pdf_pages"""
数据分割
"""
def data_split(pdf_pages):# 知识库中单段文本长度CHUNK_SIZE = 500# 知识库中相邻文本重合长度OVERLAP_SIZE = 50# # 使用递归字符文本分割器text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE,chunk_overlap=OVERLAP_SIZE)# print(text_splitter.split_text(pdf_pages[1].page_content[0:1000]))split_docs = text_splitter.split_documents(pdf_pages)print(f"切分后的文件数量:{len(split_docs)}")print(f"切分后的字符数(可以用来大致评估 token 数):{sum([len(doc.page_content) for doc in split_docs])}")return split_docsif __name__ == '__main__':# 创建一个 PyMuPDFLoader Class 实例,输入为待加载的 pdf 文档路径loader = PyMuPDFLoader("../asserts/搜索技术3-Lucene数据存储之BKD磁盘树.pdf")# 调用 PyMuPDFLoader Class 的函数 load 对 pdf 文件进行加载pdf_pages = loader.load()print(f"载入后的变量类型为:{type(pdf_pages)},", f"该 PDF 一共包含 {len(pdf_pages)} 页")# 载入后的变量类型为:<class 'list'>, 该 PDF 一共包含 20 页pdf_page = pdf_pages[0]print(f"每一个元素的类型:{type(pdf_page)}.",f"该文档的描述性数据:{pdf_page.metadata}",f"查看该文档的内容:\n{pdf_page.page_content}",sep="\n------\n")print("============================================")# re数据清洗,去掉换行以及空格cleaning_pdf_pages = data_cleaning(pdf_pages)print(f"清洗之后每一个元素的类型:{type(cleaning_pdf_pages[0])}.",f"清洗之后该文档的描述性数据:{cleaning_pdf_pages[0].metadata}",f"清洗之后查看该文档的内容:\n{cleaning_pdf_pages[0].page_content}",sep="\n------\n")将分割的数据进行embedding,langchain支持自己封装,也可以使用开源的,然后存入向量数据库
Langchain 集成了超过 30 个不同的向量存储库。我们选择 Chroma 是因为它轻量级且数据存储在内存中,这使得它非常容易启动和开始使用。
# 使用 OpenAI Embedding
# from langchain.embeddings.openai import OpenAIEmbeddings
# 使用百度千帆 Embedding
import osfrom dotenv import find_dotenv, load_dotenv
from langchain.embeddings.baidu_qianfan_endpoint import QianfanEmbeddingsEndpoint
# 使用我们自己封装的智谱 Embedding,需要将封装代码下载到本地使用
# from zhipuai_embedding import ZhipuAIEmbeddingsfrom langchain.vectorstores.chroma import Chroma
import re
from langchain.document_loaders.pdf import PyMuPDFLoader
'''
* RecursiveCharacterTextSplitter 递归字符文本分割
RecursiveCharacterTextSplitter 将按不同的字符递归地分割(按照这个优先级["\n\n", "\n", " ", ""]),这样就能尽量把所有和语义相关的内容尽可能长时间地保留在同一位置
RecursiveCharacterTextSplitter需要关注的是4个参数:* separators - 分隔符字符串数组
* chunk_size - 每个文档的字符数量限制
* chunk_overlap - 两份文档重叠区域的长度
* length_function - 长度计算函数
'''
# 导入文本分割器
from langchain.text_splitter import RecursiveCharacterTextSplitter# 读取本地/项目的环境变量。# find_dotenv()寻找并定位.env文件的路径
# load_dotenv()读取该.env文件,并将其中的环境变量加载到当前的运行环境中
# 如果你设置的是全局的环境变量,这行代码则没有任何作用。
_ = load_dotenv(find_dotenv())# 获取环境变量 API_KEY
wenxin_api_key = os.environ["QIANFAN_ACCESS_KEY"]
wenxin_secret_key = os.environ["QIANFAN_SECRET_KEY"]"""
数据清洗
"""
def data_cleaning(pdf_pages):for pdf_page in pdf_pages:# 匹配了一个前后不是中文字符的换行符。pattern = re.compile(r'[^\u4e00-\u9fff](\n)[^\u4e00-\u9fff]', re.DOTALL)pdf_page.page_content = re.sub(pattern, lambda match: match.group(0).replace('\n', ''), pdf_page.page_content)pdf_page.page_content = pdf_page.page_content.replace('•', '')pdf_page.page_content = pdf_page.page_content.replace(' ', '')pdf_page.page_content = pdf_page.page_content.replace('\n\n', '\n')return pdf_pages"""
数据分割
"""
def data_split(pdf_pages):# 知识库中单段文本长度CHUNK_SIZE = 500# 知识库中相邻文本重合长度OVERLAP_SIZE = 50# # 使用递归字符文本分割器text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE,chunk_overlap=OVERLAP_SIZE)# print(text_splitter.split_text(pdf_pages[1].page_content[0:1000]))split_docs = text_splitter.split_documents(pdf_pages)print(f"切分后的文件数量:{len(split_docs)}")print(f"切分后的字符数(可以用来大致评估 token 数):{sum([len(doc.page_content) for doc in split_docs])}")return split_docsdef data_process(path):loader = PyMuPDFLoader(path)# 调用 PyMuPDFLoader Class 的函数 load 对 pdf 文件进行加载pdf_pages = loader.load()# 数据清洗cleaning_pdf_pages = data_cleaning(pdf_pages)# 数据分割split_pdf_pages = data_split(cleaning_pdf_pages)return split_pdf_pagesdef data_presist_chroma(split_docs):# 定义 Embeddings# embedding = OpenAIEmbeddings()# embedding = ZhipuAIEmbeddings()embedding = QianfanEmbeddingsEndpoint()# 定义持久化路径persist_directory = '../vector_db/chroma'# 分割的数据vectordb = Chroma.from_documents(documents=split_docs[:20], # 为了速度,只选择前 20 个切分的 doc 进行生成;使用千帆时因QPS限制,建议选择前 5 个docembedding=embedding,persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上)vectordb.persist()print(f"向量库中存储的数量:{vectordb._collection.count()}")question = "什么是四叉树"sim_docs = vectordb.similarity_search(question, k=3)print(f"检索到的内容数:{len(sim_docs)}")for i, sim_doc in enumerate(sim_docs):print(f"检索到的第{i}个内容: \n{sim_doc.page_content[:200]}", end="\n--------------\n")# 最大边际相关性 (MMR, Maximum marginal relevance) 检索mmr_docs = vectordb.max_marginal_relevance_search(question, k=3)for i, sim_doc in enumerate(mmr_docs):print(f"MMR 检索到的第{i}个内容: \n{sim_doc.page_content[:200]}", end="\n--------------\n")if __name__ == '__main__':path = "../asserts/搜索技术3-Lucene数据存储之BKD磁盘树.pdf"data = data_process(path)data_presist_chroma(data)向量紧邻搜索结果
D:\mysoftware\anaconda3_data\envs\langchain-rag-demo\python.exe D:\myproject\my_github_projects\learn-fun-projects-demo\learn-langchain-rag-demo\embedding\qianfeng-embedding-demo.py
切分后的文件数量:48
切分后的字符数(可以用来大致评估 token 数):18258
[INFO] [04-14 11:43:55] openapi_requestor.py:336 [t:14412]: requesting llm api endpoint: /embeddings/embedding-v1
[INFO] [04-14 11:43:55] oauth.py:222 [t:14412]: trying to refresh access_token for ak `ASbxGD***`
[INFO] [04-14 11:43:56] oauth.py:237 [t:14412]: sucessfully refresh access_token
[INFO] [04-14 11:43:58] openapi_requestor.py:336 [t:14412]: requesting llm api endpoint: /embeddings/embedding-v1
向量库中存储的数量:20[INFO] [04-14 11:43:59] openapi_requestor.py:336 [t:14412]: requesting llm api endpoint: /embeddings/embedding-v1
检索到的内容数:3
检索到的第0个内容:
(包含实际对象),要么是内部节点(包含四个子节点)。
四叉树又分为点四叉树和边四叉树,以边四叉树为例,具体的实现源码参考:空间搜索优化算法之——
四叉树-掘金
--------------
检索到的第1个内容:
首先看BSP,Binaryspacepartitioning(BSP)是一种使用超平面递归划分空间到凸集的一种方法。使用
该方法划分空间可以得到表示空间中对象的一个树形数据结构。这个树形数据结构被我们叫做BSP树。
可以分为轴对齐、多边形对齐BSP,这两种方式就是选择超平面的方式不一样,已轴对齐BSP通过构建过
程简单理解,就是选择一个超平面,这个超平面是跟选取的轴垂直的一个平面,通过超平面将空间
--------------
检索到的第2个内容:
前言
基础的数据结构如二叉树衍生的的平衡二叉搜索树通过左旋右旋调整树的平衡维护数据,靠着二分算法
能满足一维度数据的logN时间复杂度的近似搜索。对于大规模多维度数据近似搜索,Lucene采用一种
BKD结构,该结构能很好的空间利用率和性能。
本片博客主要学习常见的多维数据搜索数据结构、KD-Tree的构建、搜索过程以针对高维度数据容灾的
优化的BBF算法,以及BKD结构原理。
感受算法之美结构之
--------------
[INFO] [04-14 11:43:59] openapi_requestor.py:336 [t:14412]: requesting llm api endpoint: /embeddings/embedding-v1
MMR 检索到的第0个内容:
(包含实际对象),要么是内部节点(包含四个子节点)。
四叉树又分为点四叉树和边四叉树,以边四叉树为例,具体的实现源码参考:空间搜索优化算法之——
四叉树-掘金
--------------
MMR 检索到的第1个内容:
首先看BSP,Binaryspacepartitioning(BSP)是一种使用超平面递归划分空间到凸集的一种方法。使用
该方法划分空间可以得到表示空间中对象的一个树形数据结构。这个树形数据结构被我们叫做BSP树。
可以分为轴对齐、多边形对齐BSP,这两种方式就是选择超平面的方式不一样,已轴对齐BSP通过构建过
程简单理解,就是选择一个超平面,这个超平面是跟选取的轴垂直的一个平面,通过超平面将空间
--------------
MMR 检索到的第2个内容:
们最熟悉的二叉查找树BST(BinarySearchTree)在多维数据的自然扩展,它是BSP(BinarySpacePartitioning)的一种。B+Tree又是对B-Tree的扩展。以下对这几种树的特点简要描述。1、KD-Tree
kd是K-Dimensional的所写,k值表示维度,KD-Tree表示能处理K维数据的树结构,当K为1的时候,就
转化为了BST结构
维基百科:在计算机科学里
--------------Process finished with exit code 0构建RAG检索问答链demo
使用RetrievalQA.from_chain_type,更多参考https://python.langchain.com/docs/use_cases/question_answering/quickstart/
# 读取本地/项目的环境变量。
import osfrom langchain.chains.retrieval_qa.base import RetrievalQA
from langchain.vectorstores.chroma import Chroma
from langchain_community.embeddings.baidu_qianfan_endpoint import QianfanEmbeddingsEndpoint
from dotenv import load_dotenv, find_dotenv
from langchain_community.llms.baidu_qianfan_endpoint import QianfanLLMEndpoint
from langchain_core.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory# find_dotenv()寻找并定位.env文件的路径
# load_dotenv()读取该.env文件,并将其中的环境变量加载到当前的运行环境中
# 如果你设置的是全局的环境变量,这行代码则没有任何作用。
_ = load_dotenv(find_dotenv())# 获取环境变量 API_KEY
wenxin_api_key = os.environ["QIANFAN_ACCESS_KEY"]
wenxin_secret_key = os.environ["QIANFAN_SECRET_KEY"]# 向量数据库持久化路径
persist_directory = './vector_db/chroma'"""
加载Chroma向量数据库
"""
def init_chroma_db(path):embedding = QianfanEmbeddingsEndpoint()# 加载数据库vectordb = Chroma(persist_directory=path, # 允许我们将persist_directory目录保存到磁盘上embedding_function=embedding)print(f"向量库中存储的数量:{vectordb._collection.count()}")return vectordb"""
相似性搜索
"""
def similarity_search_from_chroma(vectordb,ques,k=3):docs = vectordb.similarity_search(ques, k=k)print(f"检索到的内容数:{len(docs)}")for i, doc in enumerate(docs):print(f"检索到的第{i}个内容: \n {doc.page_content}",end="\n-----------------------------------------------------\n")return docs"""
构建RAG检索链
"""
def rag_chain(template,vectordb,question):llm = QianfanLLMEndpoint(streaming=True)QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context", "question"],template=template)# 借助langchain将对话上下文存储起来# memory = ConversationBufferMemory(# memory_key="chat_history", # 与 prompt 的输入变量保持一致。# return_messages=True # 将以消息列表的形式返回聊天记录,而不是单个字符串# )"""指定 llm:指定使用的 LLM指定 chain type : RetrievalQA.from_chain_type(chain_type="map_reduce"),也可以利用load_qa_chain()方法指定chain type。自定义 prompt :通过在RetrievalQA.from_chain_type()方法中,指定chain_type_kwargs参数,而该参数:chain_type_kwargs = {"prompt": PROMPT}返回源文档:通过RetrievalQA.from_chain_type()方法中指定:return_source_documents=True参数;也可以使用RetrievalQAWithSourceChain()方法,返回源文档的引用(坐标或者叫主键、索引)"""qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt": QA_CHAIN_PROMPT})# 大模型自己回答的效果prompt_template = """请回答下列问题:{}""".format(question)print("(1)大模型回答 question 的结果:")print(llm.predict(prompt_template))# rag + llm回答的效果result = qa_chain({"query": question})print("(2)大模型+知识库后回答 question 的结果:")print(result["result"])if __name__ == '__main__':# 初始化数据库path = persist_directorychroma_vectordb = init_chroma_db(path)# 搜索向量数据库# question = "什么是BKD-tree?"# result_docs = similarity_search_from_chroma(chroma_vectordb,question,3)# 构建检索问答链template = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答案。最多使用三句话。尽量使答案简明扼要。总是在回答的最后说“谢谢你的提问!”。{context}问题: {question}"""question = "为什莫要求t = Θ(min(M/B, √M))?"rag_chain(template,chroma_vectordb,question)"""向量库中存储的数量:20大模型回答 question 的结果:要求t = Θ(min(M/B, √M))的原因如下:1. 最小值优化:当M和B之间的比例较小(即M/B较小)时,t的值将受到M/B的影响更大。因此,使用min(M/B, √M)作为t的上界可以确保在M/B较小时能够得到更准确的估计。2. 性能优化:对于较小的M和B,我们通常希望算法的复杂度或时间复杂度尽可能低。因此,t的上界应基于最小可能的计算时间来选择。在这种情况下,min(M/B, √M)将确保t具有更低的上限,从而有助于性能优化。总之,要求t = Θ(min(M/B, √M))是基于最小值优化的原则,通过限制t的上界为较小的数值,可以提高算法的性能并降低其复杂度。这使得在较小输入条件下能够得到更准确的估计,并且对更大的输入也不会产生过度复杂或耗费时间的结果。大模型+知识库后回答 question 的结果:要求t = Θ(min(M/B, √M))是因为KD-Tree需要构建一个二叉树结构,树的深度通常受限于数据集的大小M和节点数B之间的最小值。为了保持树的平衡性和减少树的深度,通常需要限制节点的最大深度,即要求t = Θ(min(M/B, √M))。这样可以保证树的结构更加稳定,并且能够更有效地进行最邻近搜索。"""question = "对于大规模多维度数据近似搜索,Lucene采用什么结构?"rag_chain(template,chroma_vectordb,question)"""(1)大模型回答 question 的结果:对于大规模多维度数据近似搜索,Lucene通常采用倒排索引(Inverted Index)结构。倒排索引是一种将文档中的词汇转换为索引的数据结构,它能够快速地查找与某个词汇相关的文档。对于大规模多维度数据近似搜索,Lucene通过将文档和词汇按照多维空间进行组织,建立相应的倒排索引,从而实现对大规模多维度数据的快速搜索。具体而言,Lucene使用倒排索引来存储每个文档中出现的词汇及其在文档中的位置信息,以及这些词汇在查询中出现的频率等信息。通过这种方式,当进行搜索时,Lucene可以快速地在倒排索引中查找与查询条件匹配的文档,从而实现对大规模多维度数据的近似搜索。(2)大模型+知识库后回答 question 的结果:Lucene采用BKD-Tree结构来满足大规模多维度数据的近似搜索。"""
原生LLM和RAG+LLM给出的答案对比,搜索一个文档中问题: 对于大规模多维度数据近似搜索,Lucene采用什么结构?

"""(1)大模型回答 question 的结果:对于大规模多维度数据近似搜索,Lucene通常采用倒排索引(Inverted Index)结构。倒排索引是一种将文档中的词汇转换为索引的数据结构,它能够快速地查找与某个词汇相关的文档。对于大规模多维度数据近似搜索,Lucene通过将文档和词汇按照多维空间进行组织,建立相应的倒排索引,从而实现对大规模多维度数据的快速搜索。具体而言,Lucene使用倒排索引来存储每个文档中出现的词汇及其在文档中的位置信息,以及这些词汇在查询中出现的频率等信息。通过这种方式,当进行搜索时,Lucene可以快速地在倒排索引中查找与查询条件匹配的文档,从而实现对大规模多维度数据的近似搜索。(2)大模型+知识库后回答 question 的结果:Lucene采用BKD-Tree结构来满足大规模多维度数据的近似搜索。"""
参考
- 学习检索增强生成(RAG)技术,看这篇就够了——热门RAG文章摘译(9篇)
- 论文:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (知识密集型 NLP 任务的检索增强生成)
- 论文:《A Guide on 12 Tuning Strategies for Production-Ready RAG Applications》towardsdatascience.com/a-guide-on-12-tuning-strategies-for-production-ready-rag-applications-7ca646833439
- 文章 《Improving Retrieval Performance in RAG Pipelines with Hybrid Search》
- 实践文章:https://baoyu.io/translations/rag/retrieval-augmented-generation-rag-from-theory-to-langchain-implementation,借助LangChain、Huggingface上面的开源大模型 Intel/dynamic_tinybert 以及开源数据集databricks-dolly-15实现RAG完整流程,参考:https://mp.weixin.qq.com/s/RS4PTAP0ynKC7ZIhIaBDMw,借助LangChain、langchain_wenxin以及百度开源的数据集实现RAG完整流程 https://zhuanlan.zhihu.com/p/668082024
- 动手学大模型应用开发:https://datawhalechina.github.io/llm-universe/#/









)


以及典型算法例题)






