2024年3月5日,Stability AI公开Stable Diffusion 3论文,Scaling Rectified Flow Transformers for High-Resolution Image Synthesis。公司像往常一样承诺后续将开源代码,开源之光!!!

在LDW潜在扩散模型论文部分,我们简要回顾了AE、VAE、VQ-VAE、VQ-GAN、DDPM等内容。由于Stable Diffusion是以潜在扩散模型LDW升级而来,在这里咱们简要回顾一下。
Latent Diffusion Model Review
LDM Architecture

LDM 模型架构,为了降低训练扩散模型对算力的需求,LDM使用Autoencoder去学习能尽量表达原始image pixel space的低维潜在空间表达(latent embedding)。

相对于DDPM,LDM主要改进了两点
- 加入Autoencoder,上图左侧红色部分,使得扩散过程作用在latent space而不是像素空间上,提高图像生成效率;
- 输入条件机制,使用多模态输入控制图像生成,上图右侧灰色部分,其中条件生成控制通过Attention(上图中间部分Q、K、V)机制实现。
LDM Model
DDPM 利用改进U-Net网络预测每一步噪声,从而逐步还原原始图像,目标函数如下:
![]()
LDM 在DDPM基础上继续改进U-Net网络,同时预测噪声,作用在潜在空间 latent space上, ,目标函数如下:
![]()
备注,Zt 是根据编码器encoder编码 Xt 而来。
Conditioning Encoder

条件控制下LDM目标函数为:
![]()
U-Net Backbone
U-Net常用于图像分割,左、右两边又称为编码器和解码器,整个网络构成一个U形结构。在编码器中,网络从输入图像中提取多尺度特征表示,然后通过解码器将这些特征映射回原始图像尺寸。从架构上可以看出,左边下采样和右边上采样是两个重要的操作,用于在编码器和解码器之间传递信息。
具体来说,左边下采样将特征图尺寸缩小到更高层次。这种操作降低计算量和防止过拟合;可以很方便进行多尺度特征融合;增大感受野(大感受野使同样3*3卷积能在更大图像范围上进行特征提取)。右边上采样将特征图上采样到更高层次,以增加特征图细节信息。
下采样会导致底层特征损失,所以U-Net用跳接skip connection把上下采样起来,标准U-Net架构如图所示:

DDPM使用一种改进版U-Net,主要有两点改进:
- 原来的卷积层被替换成了ResNet残差网络,每一大层有若干个子模块。对于较深的大层,残差卷积后面还会接一个自注意力模块。
- 原来模型每一大层只有一个skip连接。现在每个大层下采样每个子模块的输出都会输入到其对称的上采样子模块上。直观来看,skip连接更多,更容易保留输入细节信息。

LDM继续改进U-Net网络
- 添加额外约束信息:把DDPM中U-Net自注意力模块换成交叉注意力模块,约束信息 C 作为Cross Attention的K, V输入模块中。
- Stable Diffusion U-Net还在结构上有少许修改,每一大层都有Transformer块,而不是较深的大层才有。

本文由深圳季连科技有限公司AIgraphX自动驾驶大模型团队编辑。下面进入SD3论文正文部分,公式和实验细节比较多,慢慢读,慢慢理解。如有错误,欢迎在评论区指正。
Abstract
扩散模型通过噪声来创建数据,逆向数据前向加噪路径,并已成为图像和视频等高维感知数据的强大生成建模技术。
Rectified flow是一种生成模型方法,它将数据和噪声直线连接(即将一个分布直线搬运到另一个分布)。
尽管它具有更好的理论性质和概念简单性,但它还没有决定性地确立为标准做法。
在这项工作中,我们改进了现有的噪声采样技术,将它们偏向于感知相关缩放来训练Rectified flow模型。通过大规模的研究,我们证明了这种方法与已建立的高分辨率文本到图像合成扩散方法相比具有优越的性能。
我们提出了一种新的基于transformer的文本到图像生成架构,该架构为两种模态使用单独的权重,并允许图像和文本token之间双向信息流,提高了文本理解、排版和人类偏好评级。
通过各种指标和人类评估,我们证明了这种架构遵循可预测的缩放趋势,较低的验证损失与改进的文本到图像性能密切相关。
我们最大模型达到SOTA,我们将公开实验数据、代码和模型权重。
1. Introduction
扩散模型从噪声创建数据。它们被训练以将数据的前向路径反转为随机噪声,因此,结合神经网络近似和泛化特性,可用于生成训练数据中不存在的新数据点,但遵循训练数据的分布。这种生成建模技术已被证明对建模高维感知数据如图像非常有效。近年来扩散模型从自然语言输入中生成高分辨率图像和视频,具有令人印象深刻的泛化能力,这已成为事实方法。由于其迭代性质和相关计算成本,以及推理过程中的长采样时间,当前对更有效训练和/或更快采样方法的研究有所增加。
虽然指定从数据到噪声的正向路径会带来有效的训练,但它也提出了选择哪条路径的问题。这种选择可能对采样产生重大影响。例如,未能从数据中去除噪声的前向过程可能会导致训练和测试分布的差异,并导致诸如灰度图像样本之类的伪影。重要的是,前向过程的选择也会影响学习的后向过程,从而影响采样效率。曲线路径需要许多集成步骤来模拟该过程,然直线路径可以用单个步骤来模拟,并且不太容易累积误差。由于每一步都对应于神经网络的评估,这对采样速度有直接影响。
前向路径的特定选择被称作Rectified Flow ,它将数据和噪声连接在一条直线上。
- Flow Straight and Fast: Learning to Generate and Transfer Data withRectified Flow
- Building Normalizing Flows with Stochastic Interpolants
- Flow Matching for Generative Modeling
到目前为止,一些优势已经在中小型实验中得到了实证证明,但这些大多仅限于类条件模型。在这项工作中,我们通过引入Rectified Flow噪声缩放的重新加权来改变这一点,类似于噪声预测扩散模型。通过大规模学习研究,已经证明我们的新方法具有很大优势。
广泛使用的文本到图像合成方法,其中固定的文本表示直接输入模型(例如通过交叉注意力)并不理想。我们提出了一种新的架构,该架构包含图像和文本token的可学习流,从而实现它们之间双向信息流。我们将此与改进的Rectified Flow方法相结合,并研究其可扩展性。
我们最大的模型无论是在即时理解和人类偏好评级的定量评估方面都优于最先进的开放模型,例如开源模型SDXL 、SDXL-Turbo、Pixart-α和闭源模型 DALL-E 3 等。
我们的核心贡献是:
- 我们对不同的扩散模型和Rectified Flow方法进行了大规模、系统的研究,以确定最佳设置。为此,我们为Rectified Flow模型引入了新的噪声采样器,这些采样器性能达到新的高度。
- 我们设计了一种新的可扩展的文本到图像合成架构,它允许文本和图像token流之间双向混合。与 UViT和 DiT 已建立的网络主干相比有更好的性能。
- 我们对模型进行了缩放研究,证明它遵循可预测的缩放趋势。通过 T2I-CompBench 、GenEval和人工评分等指标评估,较低的验证损失与改进的文本到图像性能密切相关。
2. Simulation-Free Training of Flows
考虑到生成模型,根据常微分方程 (ODE),来自噪声分布p1的样本x1到来自数据分布p0的样本x0之间的映射。
![]()
其中速度 v 由神经网络权重 Θ 参数化。Neural Ordinary Differential Equations工作建议通过可微ODE求解器直接求解方程(1)。然而,这个过程计算成本很高,尤其是对于参数化 vΘ(yt, t) 的大型网络架构。更有效的替代方法是直接回归一个向量场ut,它在p0和p1之间生成概率路径。为了构造这样的ut,我们定义了一个正向过程,对应于p0和p1 = N(0,1)之间的概率路径pt,如下所示
![]()
对于a0 = 1, b0 = 0, a1 = 0和b1 = 1,边缘分布
![]()
其与数据和噪声分布一致。
为了表达zt、x0和ε之间的关系,我们引入ψt和ut

由于zt可以写成ODE z 't = ut(zt|ε)的解,初始值z0 = x0, ut(·|ε)生成pt(·|ε)。值得注意的是,可以使用条件向量场 ut(·|ε) 构造一个边缘向量场 ut,它生成边际概率路径 pt (Flow Matching for Generative Modeling),使用条件向量场ut(·|ε):
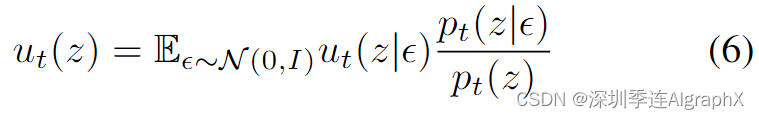
在使用流匹配Flow Matching目标回归ut时
![]()
由于等式 6 中的边缘化,进行ut的回归难以直接处理。
![]()
使用条件向量场 ut(z|ε) 提供了一个等效但易于处理的目标。
为了将损失转换为显式形式,我们插入
![]() 到(5)式。
到(5)式。

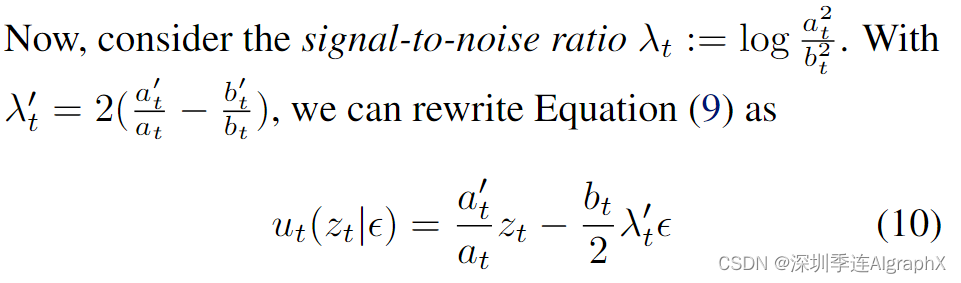
接下来,我们使用等式 (10) 将等式 (8) 重新参数化作为噪声预测目标:
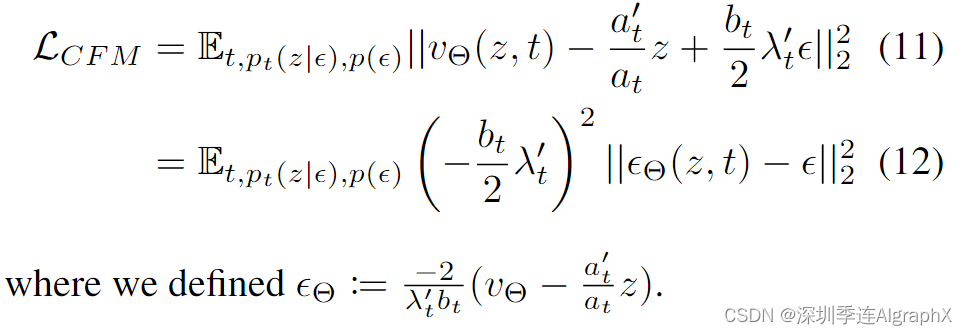
请注意,在引入与时间相关的加权时,上述目标最优值不会改变。因此,可以推导出各种加权损失函数,该函数向期望的解决方案提供信号,但可能会影响优化轨迹。为了统一分析不同方法,包括经典扩散公式,我们可以将目标写成以下形式(遵循Data Augmentation
Understanding Diffusion Model Objectives as the ELB0 with Simple (2023)):
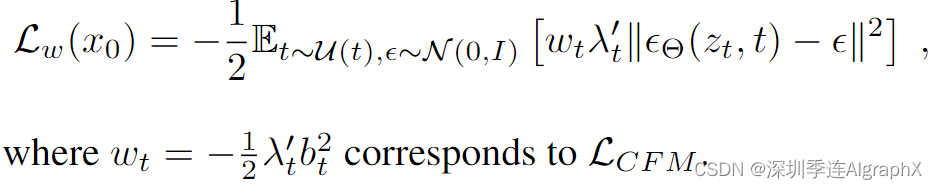
3. Flow Trajectories
在这项工作中,我们考虑了上述形式的不同变体,我们将在下面简要描述。
Rectified Flows (RF) ,Flow Matching for Generative Modelin等论文将正向过程定义为数据分布与标准正态分布之间的直线路径,即

EDM,eDiffi: Text-to-lmage Diffusion Models with an Ensemble of Expert Denoisers 论文前向过程方程为
![]()
其中 ![]()
F-1/N 是均值 Pm 和方差 P2/s 正态分布的分位数函数。请注意,此选择结果是
![]()
该网络通过 F-prediction 参数化,损失可以写成
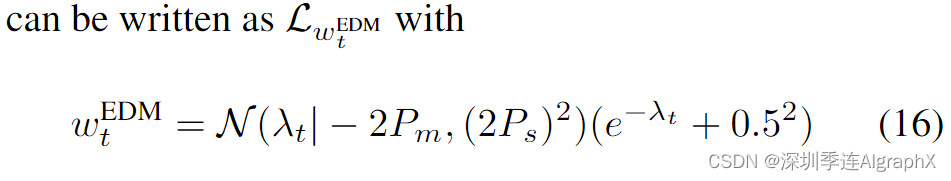


3.1. Tailored SNR Samplers for RF models
RF 损失在所有时间步上均匀地训练速度 vΘ。然而,直观地说,对于[0,1]中间的t,得到速度预测目标ε−x0更加困难。因为对于t = 0,最优预测是p1的平均值,对于t = 1,最优预测是p0的平均值。一般来说,将t的分布从常用的均匀分布U(t)更改为密度π(t)分布等价于加权损失Lwπ/t,
![]()
因此,我们的目标是通过更频繁地对中间时间步进行采样,使其获得更多的权重。接下来,我们描述用于训练模型的时间步密度 π(t)。
Logit-Normal Sampling
对中间步骤施加更多权重,一种选择是对数正态分布logit normal distribution,它的密度是
![]()
其中 logit(t) = log (t1/t),具有位置参数 m 和缩放参数 s。位置参数使我们能够将训练时间步长,要么偏向数据 p0(负 m)或偏向噪声 p1(正 m)。如下图所示,缩放参数控制分布的宽度。
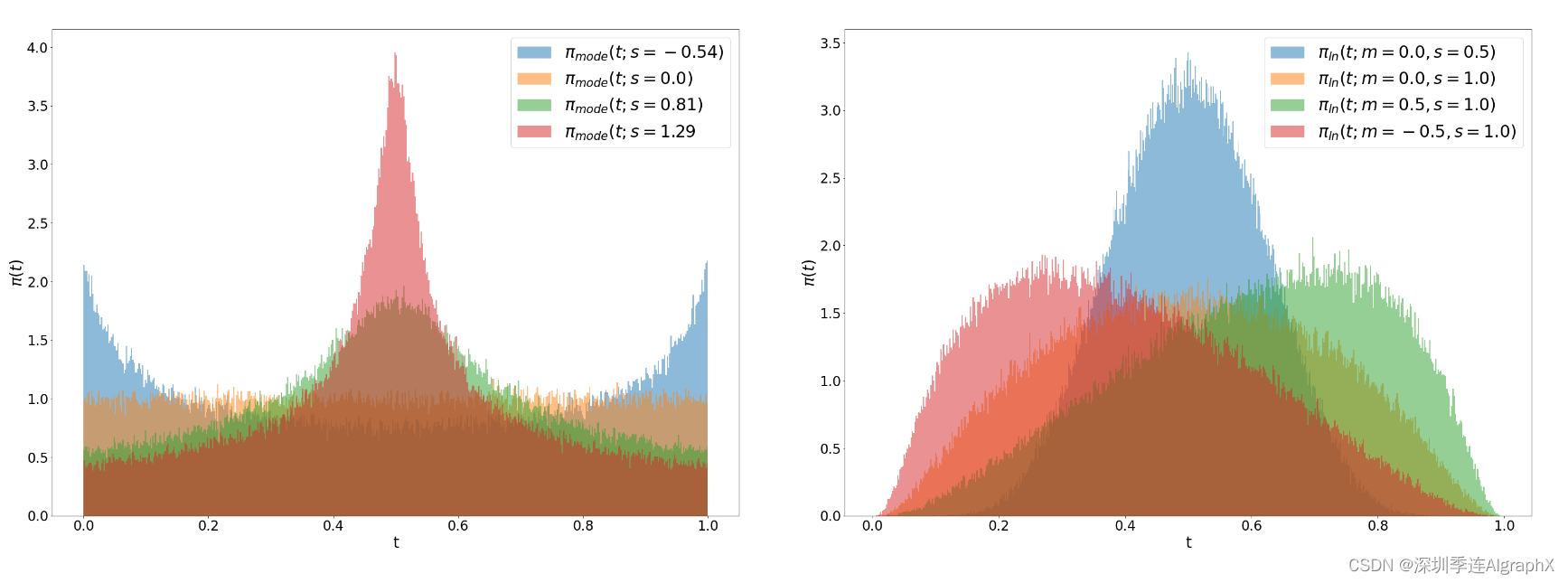
在实践中,我们从正态分布 u ∼ N (u; m, s) 中采样随机变量 u,并通过标准逻辑函数对其进行映射。
Mode Sampling with Heavy Tails
logit-normal density 在端点 0 和 1 处总是消失。为了研究这是否对性能产生不利影响,我们还使用具有严格正密度的时间步采样分布[0,1]。对于缩放参数 s,我们定义
![]()
对于 -1 ≤ s ≤ 2/(π−2) ,这个函数是单调的。

CosMap

4. Text-to-Image Architecture
对于图像的文本条件采样,我们的模型必须同时考虑文本和图像这两种模态。使用预训练模型来导出合适的表示,我们的扩散模型架构如下图 2:
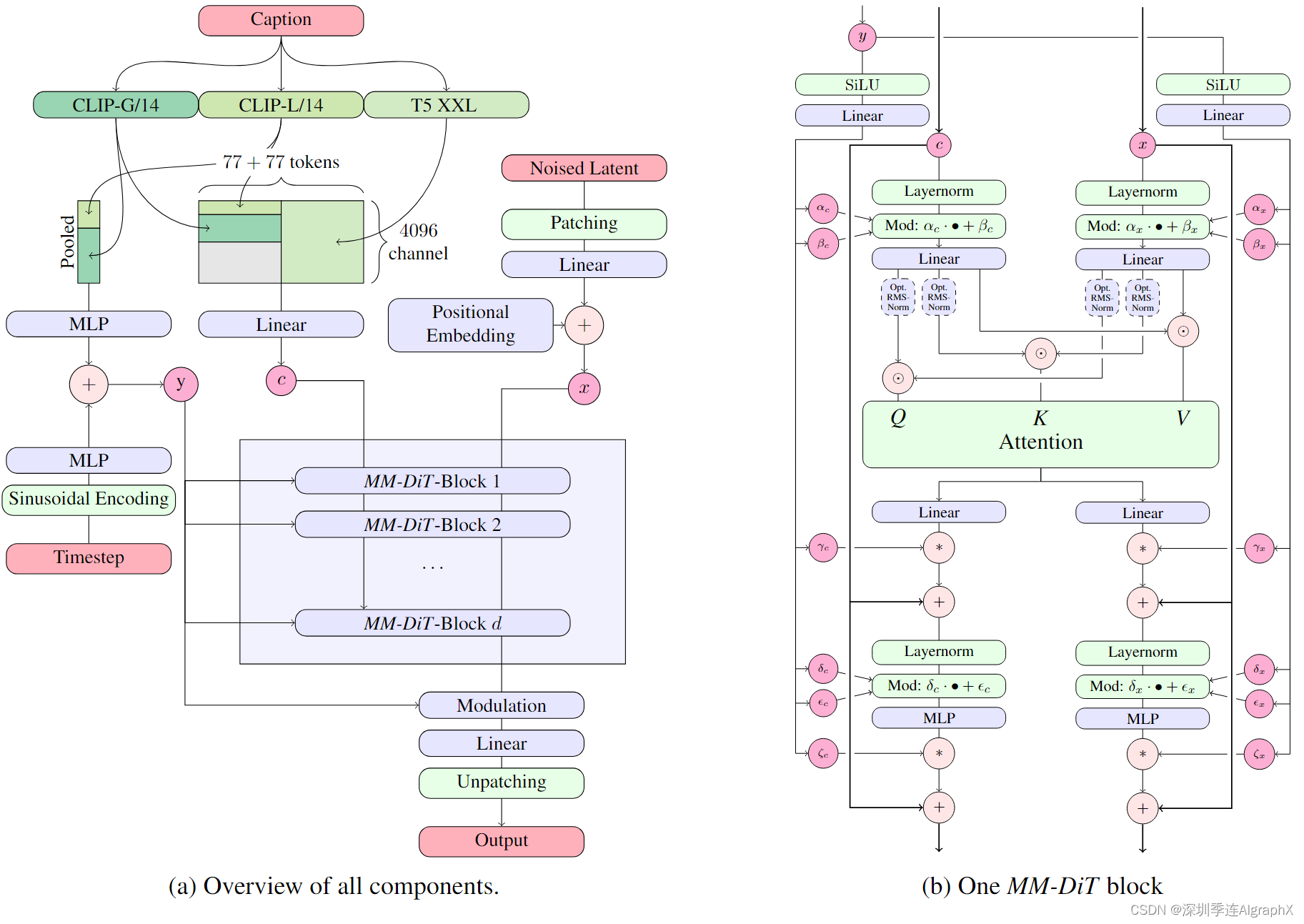
图 2。MM-DiT 模型架构。连接用⊙表示,按∗进行元素相乘。Q 和 K 的 RMS-Norm 可以添加以稳定训练运行。
我们的通用设置遵循LDM,在预训练自编码器潜在空间训练文本到图像模型。与将图像编码为潜在表示类似,我们遵循以前的方法(Imagen,eDiffi),并使用预训练的、冻结文本模型对文本条件 c 进行编码。
Multimodal Diffusion Backbone
我们的架构建立在 DiT 架构之上。DiT只考虑类条件图像生成,并使用调制机制在扩散过程和类标签的时间步长上调节网络。类似地,我们使用时间步 T 和 Cvec 嵌入作为调制机制的输入。然而,由于池化文本表示只保留有关文本输入的粗粒度信息,网络还需要来自序列 Cctxt 的信息。
我们构建了一个由文本和图像嵌入组成的序列。具体来说,我们添加了位置编码并将潜在像素表示 x ∈ Rh×w×c 的 2 × 2 块展平为长度为 1/2 · h · 1/2 · w 的patch编码序列。在将此patch编码和文本编码 Cctxt 嵌入到一个公共维度之后,我们将两个序列连接起来。然后我们遵循 DiT 并应用一系列调制注意力和 MLP。
由于文本和图像嵌入在概念上完全不同,我们对两种模态使用两组单独的权重。如图 2b 所示,这相当于每个模态有两个独立的transformer,连接两种模态的序列以进行注意力操作,使得这两种表示都可以在自己的空间中工作,但考虑到另一个表示。
对于我们的缩放实验,我们根据模型的深度d,如注意力块的数量,通过将隐藏大小设置为64·d(在MLP块中扩展为4·64·d通道),并且注意力头数量等于d,来参数化模型的大小。
5. Experiments
5.1. Improving Rectified Flows
我们目标是如方程 1 所示的理解,对归一化流进行无模拟训练是最有效的。为了实现不同方法的比较,我们控制了优化算法、模型架构、数据集和采样器。此外,不同方法的损失是不可比较的,不一定与输出样本的质量相关;我们在ImageNet和CC12M上训练模型,并使用验证损失、CLIP分数和FID在不同的采样器设置(不同的引导尺度和采样步骤)下评估模型的训练和EMA权重。我们遵循Projected GANs Converge Faster方法,计算CLIP特征上的FID。所有指标都在COCO-2014 validation split 上进行评估。
5.1.1. Results
我们在两个数据集上训练 61 个不同构思中的每一个。我们包括来自第 3 章的以下变体:
- Both ε- and v-prediction loss with linear (eps/linear, v/linear) and cosine (eps/cos,v/cos) schedule.
- RF loss with π mode(t; s) (rf/mode(s)) with 7 values for s chosen uniformly between −1 and 1.75, and additionally for s = 1.0 and s = 0 which corresponds to uniform timestep sampling (rf/mode).
- RF loss with π ln(t; m, s) (rf/lognorm(m, s)) with 30 values for (m, s) in the grid with m uniform between −1 and 1, and s uniform between 0.2 and 2.2.
- RF loss with πCosMap(t) (rf/cosmap).
- EDM (edm(Pm, Ps)) with 15 values for Pm chosen uniformly between −1.2 and 1.2 and Ps uniform between 0.6 and 1.8. Note that Pm, Ps = (−1.2, 1.2)corresponds to the parameters in (Karras et al., 2022).
- EDM with a schedule such that it matches the log-SNR weighting of rf (edm/rf) and one that matches the log-SNR weighting of v/cos (edm/cos).
对于每次运行,我们选择使用 EMA 权重评估时验证损失最小的步骤,然后收集使用 6 种不同采样器设置(无论是否使用 EMA 权重)获得的 CLIP 分数和 FID。
对于所有24种采样器设置、EMA权重和数据集选择的组合,我们使用 non-dominated 排序算法对不同方法进行排名。为此,我们根据 CLIP 和 FID 分数重复计算帕累托最优的变体,分配当前迭代索引那些变体,删除这些变体,并继续其余的变体,直到所有变体都被排名。最后,将这些排名平均化得到24个不同控制设置的结果。
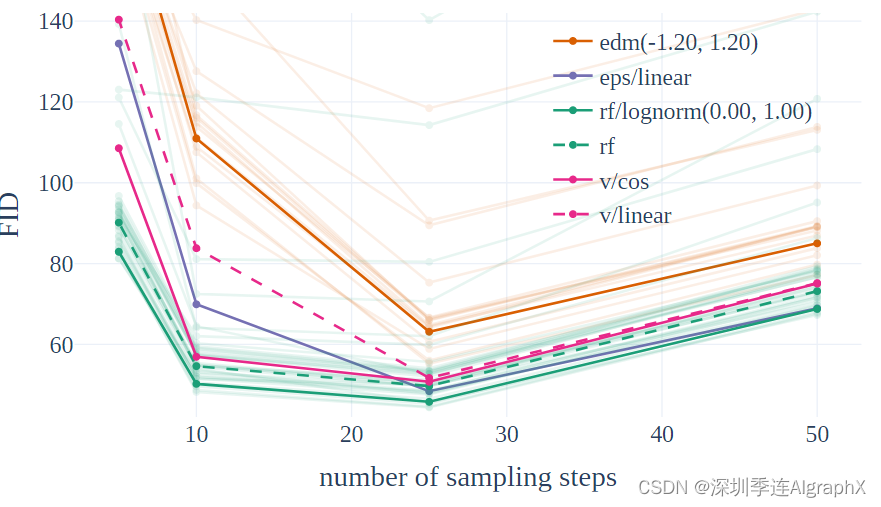
如表 1 所示,显示了使用不同超参数进行评估的两种性能最佳的变体。我们还展示了限制采样器在 5 步和 50 步的平均排名。
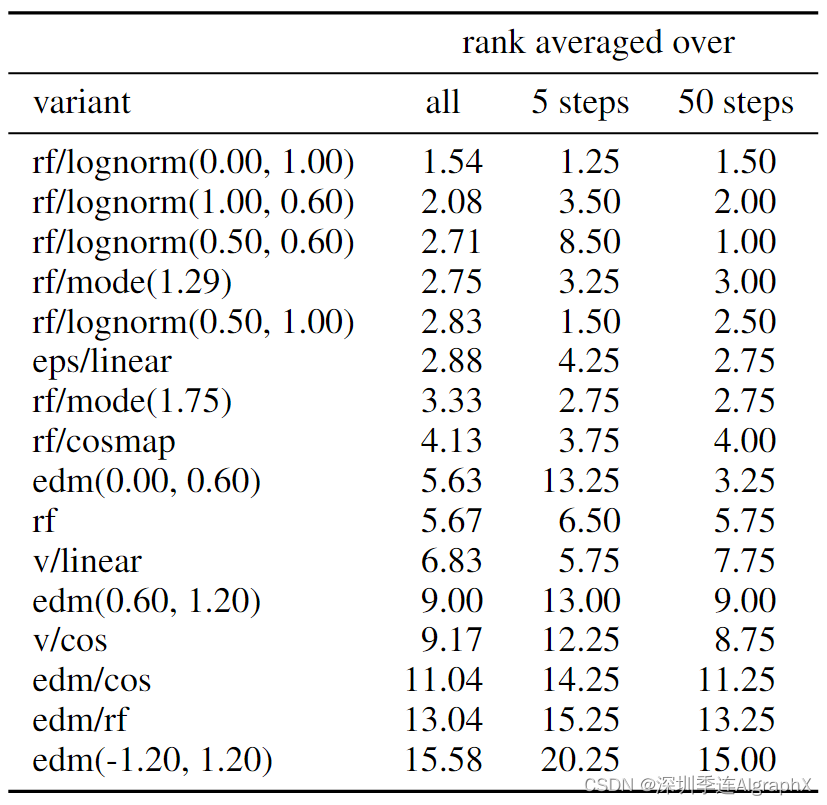
我们观察到 rf/lognorm(0.00, 1.00) 始终达到良好的排名。rectified flow优于具有均匀时间步采样的方法,从而证实了我们的假设,即中间时间步更重要。在所有变体中,只有经过修改时间步采样的方法比之前使用的LDM-Linear表现更好。
我们还观察到某些变体在某些设置中表现良好,但在其他设置中表现更差。
最后,在图 3 中显示了不同方法(edm、rf、eps 和 v)的定性结果。Rectified flow方法通常表现良好,并且在减少采样步骤数量时,性能下降较少。
5.2. Improving Modality Specific Representations
在上节中找到了一种方法之后,它使rectified flow模型不仅与已建立的扩散模型竞争,如LDM-Linear或EDM,而且甚至优于它们,我们现在转向将我们的方法应用于高分辨率图像合成。
我们算法的最终性能不仅取决于训练方法,还取决于通过神经网络参数化以及我们使用的图像和文本表示质量。在接下来的几节中,我们将描述如何改进这些组件。
5.2.1. Improved Autoencoders
潜在扩散模型通过在预训练自编码器的潜在空间中操作实现了高效率,它将输入 RGB X∈RH×W×3 映射到低维空间 x=E(X)∈Rh×w×d。该自动编码器的重建质量在潜在扩散训练后提供了可实现图像质量的上限。与 Emu 类似,我们发现增加潜在通道的数量d可以显著提高重建性能,见表3。
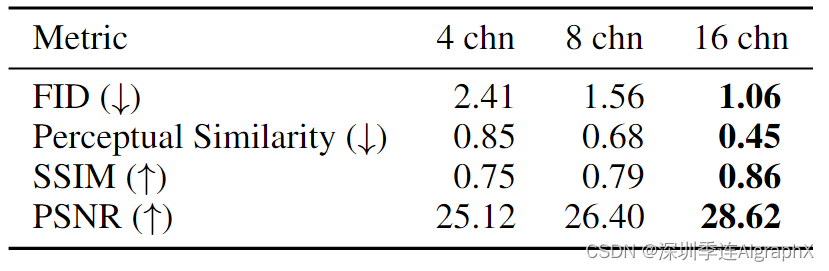
我们看到 d = 16 自动编码器在样本 FID 方面表现出更好的缩放性能。对于本文的其余部分,因此我们选择 d = 16
5.2.2. Imroved Captions
Improving image generation with better captions 表明,合成captions可以极大地改进大规模训练文本到图像模型。
这是由于大规模图像数据集附带的人工生成captions通常过于简单,过于关注图像主题,通常省略描述场景背景、构图的细节或显示的文本。
我们遵循他们的方法并使用现成的、最先进的视觉语言模型 CogVLM,为我们的大规模图像数据集创建合成标注。
由于合成captions可能会导致文本到图像模型忘记 VLM 知识语料库中不存在的某些概念,我们使用 50% 原始captions和 50% 合成captions。为了评估训练对这种captions混合的影响,我们训练了两个 d = 15 MM-DiT 模型 250k 步,一个仅在原始captions上,另一个在 50/50 混合上训练。我们使用表 4 中的 GenEval 基准评估模型。结果表明,添加合成captions训练的模型明显优于仅使用原始captions的模型。因此,我们在这项工作的其余部分使用合成模型。

5.2.3. Improved text-to-image Backbones
在本节中,我们将现有的transformer扩散主干与新的基于多模态transformer的扩散主干MM-DiT性能进行比较,如第4节所述。MM-DiT专门设计用于处理不同的领域,这里是文本和图像token,使用(两个)不同的可训练模型权重集。更具体地说,我们遵循 5.1 节中的实验设置,在 CC12M 上比较了 DiT、CrossDiT (DiT对文本 tokens 进行交叉注意而不是序列级别串接) 和我们的 MM-DiT 文本到图像性能。对于MM-DiT,我们比较了具有两组权重和三组权重的模型,后者单独处理CLIP和T5 tokens 。
最后,我们将 UViT 架构视为广泛使用 UNet 和 Transformer 变体之间的混合。我们在图 4 中分析了这些架构的收敛行为:普通 DiT 性能低于 UViT。交叉注意 DiT 的变体 CrossDiT 实现了比 UViT 更好的性能,尽管 UViT 最初似乎学习得更快。我们的 MM-DiT 变体显著优于交叉注意力和普通变体。当使用三个参数集而不是两个参数集时,我们只观察到一个小的增益(但代价是增加了参数总数和 VRAM 使用),因此在本文的其余部分选择前者。

5.3. Training at Scale
在扩大规模之前,我们对数据进行过滤和预编码,以确保安全有效的预训练。综合考虑diffusion formulations, architectures and data culminate后,我们将模型扩展到8B参数。
5.3.1. Data preprocessing
Pre-Training Mitigations
训练数据显著影响生成模型的能力。因此,数据过滤可以有效地限制不良能力。在展开训练之前,我们将数据进行了以下过滤:
- 色情内容:我们使用 NSFW 检测模型来过滤显式内容。
- 美学:删除了在评级系统预测得低分数的图像。
- 回溯:使用基于聚类的去重方法从训练数据中删除感知和语义重复。
Precomputing Image and Text Embeddings
我们的模型使用多个预训练、冻结网络的输出作为输入(自动编码器的潜变量和文本编码器的表示)。由于这些输出在训练期间是恒定的,我们为整个数据集预先计算一次。
5.3.2. Finetuning on High Resolutions
QK-Normalization
一般来说,在大小为 256^2 像素的低分辨率图像上预训练所有模型。接下来,使用混合长宽比以更高的分辨率微调。
我们发现,当转换到高分辨率时,混合精度训练可能会变得不稳定,损失发散。这可以通过切换到全精度训练来解决——但与混合精度训练相比,性能下降约 2 倍。在ViT文献中报告了更有效的替代方案:随着注意熵的不可控增长,大型视觉transformer模型训练会发散。为了避免这一点,Scaling vision transformers to 22 billion parameters 建议在注意力操作之前对 Q 和 K 进行归一化。我们遵循这种方法,并在MM-DiT架构的两个流中使用具有可学习缩放的RMS-Norm。最后,我们想指出的是,尽管这种方法通常可以帮助稳定大型模型的训练,但它不是一个通用方法,可能需要根据确切的训练设置进行调整。
Positional Encodings for Varying Aspect Ratios
在固定 256 × 256 分辨率上进行训练后,我们的目标是
- 提高分辨率
- 使推理具有灵活的长宽比成为可能
由于我们使用 2d 位置频率,我们必须根据分辨率调整它们的嵌入。在多长宽比设置中,如ViT 中嵌入的直接插值不会正确地反映边长。相反,我们使用扩展和插值位置网格的组合,随后进行频率嵌入。
Resolution-dependent shifting of timestep schedules
直观地说,由于更高的分辨率有更多的像素,我们需要更多的噪声来破坏它们的信号。因此,在随后的实验中,我们在训练期间和分辨率为 1024 × 1024 的采样期间,我们使用 α = 3.0 的偏移值。在分辨率为1024×1024 移位训练后,我们使用直接偏好优化(DPO)来对齐模型。
5.3.3. Results
在图 8 中,我们检查了 MM-DiT 的效果。对于图像,我们进行了大规模的缩放研究,并在256×256像素的分辨率上使用预编码数据,在批量大小为4096的情况下,对模型进行了500k步的训练。

对于图像和视频域,我们观察到随着模型大小和训练步骤的增加,验证损失的平稳下降。我们发现验证损失与综合评估指标 、GenEval 和人类偏好高度相关。这些结果支持验证损失作为模型性能的简单和通用的度量。我们的结果对于没有视频模型的图像都没有显示饱和。
下图 12 说明了训练更大模型、更长时间如何影响样本质量。
当增加训练图像分辨率时,我们的最大模型在大多数类别上表现出色,并在整体得分上优于DALLE 3 ,即当前最先进的提示理解技术。

表 5 显示了GenEval的全部结果。

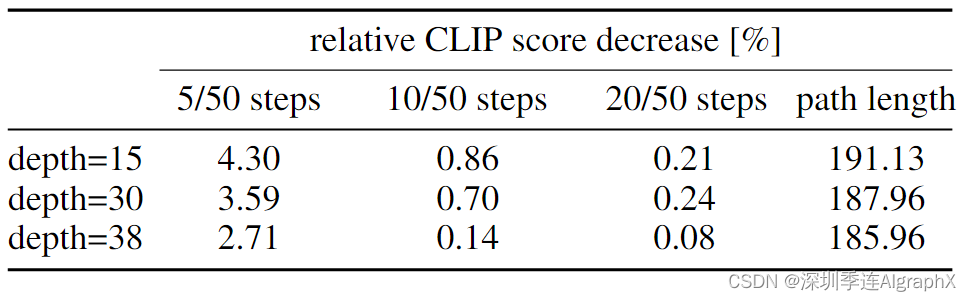
表 6 突出了一个有趣的结果:更大模型表现更好,需要更少的步骤达到其峰值性能。
Flexible Text Encoders
虽然使用多个文本编码器的主要动机是提高整体模型性能,但我们现在表明,这种选择在推理过程中额外增加了基于 MM-DiT rectified flow的灵活性。有趣的是,当仅使用两个基于CLIP的文本编码器用于文本提示,并用零替换T5 embedding时,观察到的性能下降有限。我们在图 9 中提供了定性的可视化。

我们的d = 38模型在Parti-prompts基准测试的视觉美学、提示跟随和样式生成等类别的人类偏好评估中优于当前的专有和开放SOTA生成图像模型,如下图 7 所示。

摘录模型部分效果图


6. Conclusion
在这项工作中,我们对用于文本到图像合成的rectified flow模型进行了缩放分析。我们提出了一种新的rectified flow训练时间步长采样,该采样改进了先前潜在扩散模型的扩散训练方法,并在小步采样机制中保留了rectified flow的良好特性。我们还展示了基于transformer的MM-DiT架构的优势,该架构考虑了文本到图像任务的多模态性质。最后,我们对这种组合进行了缩放研究,使其规模达到8B模型参数。
结果表明,验证损失的改善与现有的文本到图像基准以及人类偏好评估相关。这与我们在生成建模和可扩展方面的改进相结合,多模态架构实现了与最先进专有模型竞争的性能。缩放趋势没有饱和的迹象,这使得我们乐观地认为,在未来可以继续提高模型性能。
Reference
SD3-https://arxiv.org/abs/2403.03206
51-33 LDM 潜在扩散模型论文精读 + DDPM 扩散模型代码实现-CSDN博客
Stable Diffusion v1 代码解读+图解_Bilibili






![[运维|GB28181] wvp-GB28181-pro+ZLMediaKit部署GB28181协议视频平台(windows)-个人笔记](http://pic.xiahunao.cn/[运维|GB28181] wvp-GB28181-pro+ZLMediaKit部署GB28181协议视频平台(windows)-个人笔记)








)



