Netty实战精髓
前言
Netty的组成部分
1、Channel
2、Callback
3、Future
ChannelFuture 提供多个附件方法来允许一个或者多个 ChannelFutureListener 实例,这个回调方法 operationComplete() 会在操作完成时调用。
4、Event和Handler
5、EventLOOP
Netty 通过触发事件从应用程序中抽象出 Selector,从而避免手写调度代码。EventLoop 分配给每个 Channel 来处理所有的事件,包括
注册感兴趣的事件
调度事件到 ChannelHandler
安排进一步行动
Netty的整体架构
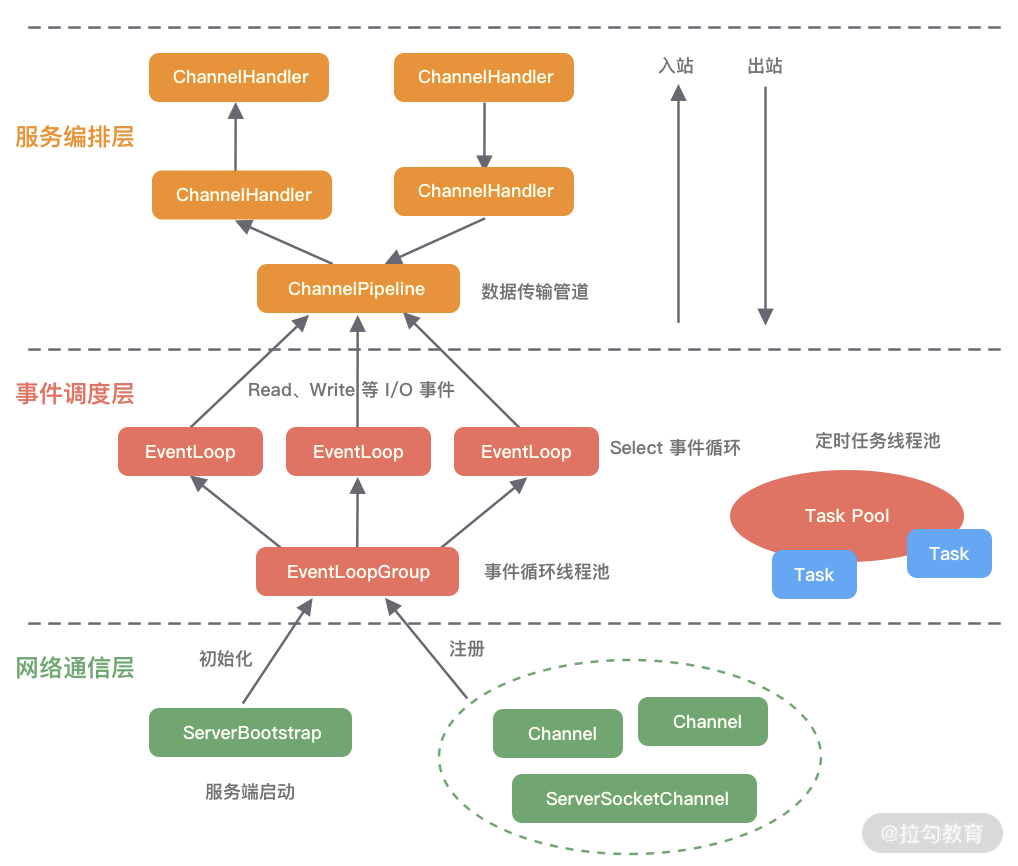
网络通信层
网络通信层的核心组件包含BootStrap、ServerBootStrap、Channel三个组件。
Bootstrap 是“引导”的意思,它主要负责整个 Netty 程序的启动、初始化、服务器连接等过程,它相当于一条主线,串联了 Netty 的其他核心组件。
一个为用于客户端引导的 Bootstrap,另一个为用于服务端引导的 ServerBootStrap,它们都继承自抽象类 AbstractBootstrap。
Bootstrap 和 ServerBootStrap 十分相似,两者非常重要的区别在于 Bootstrap 可用于连接远端服务器,只绑定一个 EventLoopGroup。而 ServerBootStrap 则用于服务端启动绑定本地端口,会绑定两个 EventLoopGroup,这两个 EventLoopGroup 通常称为 Boss 和 Worker。
Channel
Channel 的字面意思是“通道”,它是网络通信的载体。抽象了JDK的NIO,屏蔽了底层Socket的复杂性。
Channel的实现类有:
NioServerSocketChannel 异步 TCP 服务端。
NioSocketChannel 异步 TCP 客户端。
OioServerSocketChannel 同步 TCP 服务端。
OioSocketChannel 同步 TCP 客户端。
NioDatagramChannel 异步 UDP 连接。
OioDatagramChannel 同步 UDP 连接。
事件调度层
事件调度层的职责是通过 Reactor 线程模型对各类事件进行聚合处理,通过 Selector 主循环线程集成多种事件( I/O 事件、信号事件、定时事件等),实际的业务处理逻辑是交由服务编排层中相关的 Handler 完成。
事件调度层的核心组件包括 EventLoopGroup、EventLoop。
EventLoopGroup、EventLoop、Channel 的几点关系。
1、一个 EventLoopGroup 往往包含一个或者多个 EventLoop。EventLoop 用于处理 Channel 生命周期内的所有 I/O 事件,如 accept、connect、read、write 等 I/O 事件。
2、EventLoop 同一时间会与一个线程绑定,每个 EventLoop 负责处理多个 Channel。
3、每新建一个 Channel,EventLoopGroup 会选择一个 EventLoop 与其绑定。该 Channel 在生命周期内都可以对 EventLoop 进行多次绑定和解绑。
EventLoop 的实现有NioEventLoopGroup
服务编排层
服务编排层的职责是负责组装各类服务,它是 Netty 的核心处理链,用以实现网络事件的动态编排和有序传播。
服务编排层的核心组件包括 ChannelPipeline、ChannelHandler、ChannelHandlerContext。
ChannelPipeline
ChannelPipeline 是 Netty 的核心编排组件,负责组装各种 ChannelHandler,实际数据的编解码以及加工处理操作都是由 ChannelHandler 完成的。ChannelPipeline 可以理解为ChannelHandler 的实例列表——内部通过双向链表将不同的 ChannelHandler 链接在一起。当 I/O 读写事件触发时,ChannelPipeline 会依次调用 ChannelHandler 列表对 Channel 的数据进行拦截和处理。
ChannelPipeline 是线程安全的,因为每一个新的 Channel 都会对应绑定一个新的 ChannelPipeline。一个 ChannelPipeline 关联一个 EventLoop,一个 EventLoop 仅会绑定一个线程。
ChannelHandler & ChannelHandlerContext
在介绍 ChannelPipeline 的过程中,想必你已经对 ChannelHandler 有了基本的概念,数据的编解码工作以及其他转换工作实际都是通过 ChannelHandler 处理的。站在开发者的角度,最需要关注的就是 ChannelHandler,我们很少会直接操作 Channel,都是通过 ChannelHandler 间接完成。
总结
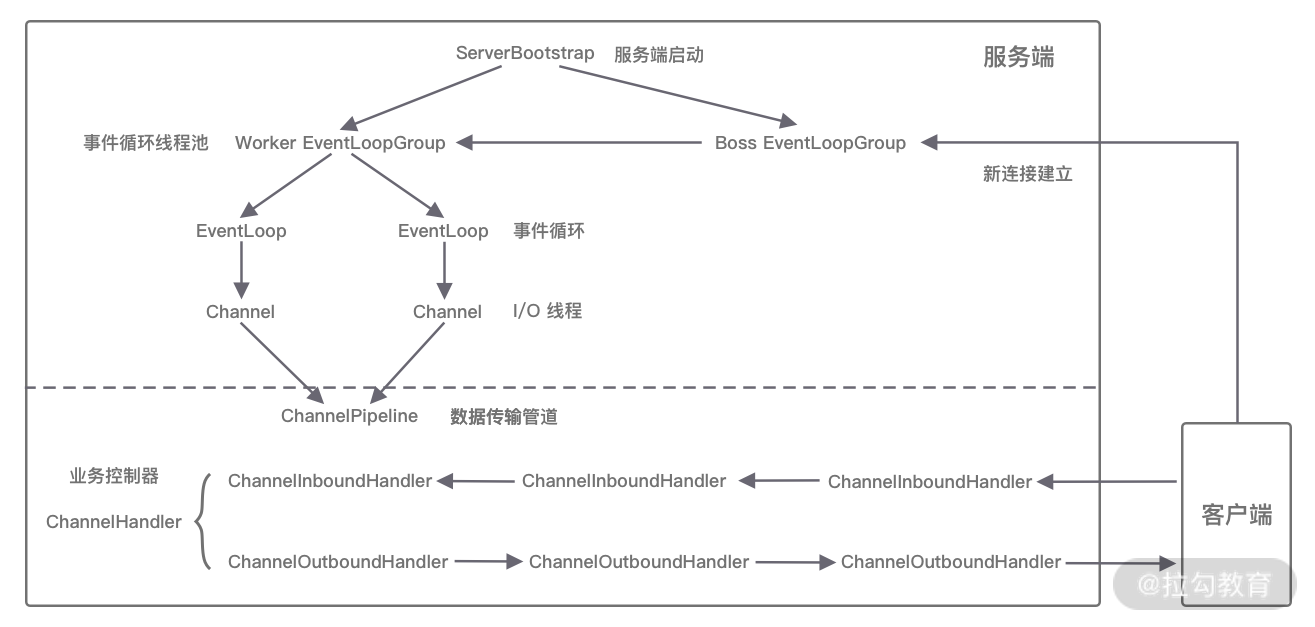
这些组件是怎么协作的呢?
- 服务端启动初始化 Boss EventLoopGroup 和 Worker EventLoopGroup 两个组件,其中Boss负责监听网络连接事件。当有新的网络事件到达时,则将Channel注册到Worker EventLoopGroup。
- Worker EventLoopGroup 会被分配到一个EventLoop负责处理Chanel的读写事件。每个 EventLoop 都是单线程 的,通过 Selector 进行事件循环。
- 当客户端发起I/O读写事件时,服务端 EventLoop 会进行数据的读取,通过 Pipeline 触发各种监听器进行数据的加工处理。
- 客户端数据会被传递到 ChannelPipeline 的第一个 ChannelBoundHandler 中,数据处理完成后,将加工完成的数据传递到下一个 ChannelboundHandler.
- 当数据写回客户端时,会将处理结果在ChannelPipeline的 ChannelOutboundHandler 中传播,最后到达客户端。
实例代码
服务端:
public class HttpServer {public void start(int port) throws InterruptedException {EventLoopGroup bossGroup = new NioEventLoopGroup();EventLoopGroup workerGroup = new NioEventLoopGroup();ServerBootstrap b = new ServerBootstrap();b.group(bossGroup, workerGroup).channel(NioServerSocketChannel.class).localAddress(new InetSocketAddress(port)).childHandler(new ChannelInitializer<SocketChannel>() {@Overrideprotected void initChannel(SocketChannel ch) throws Exception {ch.pipeline().addLast("codec", new HttpServerCodec()).addLast("compressor", new HttpContentCompressor()).addLast("aggregator", new HttpObjectAggregator(65536)).addLast("handler", new HttpServerHandler());}}).childOption(ChannelOption.SO_KEEPALIVE, true);ChannelFuture sync = b.bind().sync();System.out.println("port:"+port);sync.channel().closeFuture().sync();}public static void main(String[] args) throws InterruptedException {new HttpServer().start(8080);}
}服务端处理Handler
package Netty2;import io.netty.buffer.Unpooled;
import io.netty.channel.ChannelFutureListener;
import io.netty.channel.ChannelHandlerContext;
import io.netty.channel.SimpleChannelInboundHandler;
import io.netty.handler.codec.http.*;
import io.netty.util.CharsetUtil;public class HttpServerHandler extends SimpleChannelInboundHandler<FullHttpRequest> {@Overrideprotected void channelRead0(ChannelHandlerContext ctx, FullHttpRequest msg) throws Exception {String content = String.format("Receive http request, uri: %s, method: %s, content: %s%n", msg.uri(), msg.method(), msg.content().toString(CharsetUtil.UTF_8));FullHttpResponse response = new DefaultFullHttpResponse(HttpVersion.HTTP_1_1, HttpResponseStatus.OK, Unpooled.wrappedBuffer(content.getBytes()));ctx.writeAndFlush(response).addListener(ChannelFutureListener.CLOSE);}
}客户端:
package Netty;import io.netty.bootstrap.Bootstrap;
import io.netty.channel.ChannelFuture;
import io.netty.channel.ChannelInitializer;
import io.netty.channel.EventLoopGroup;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.SocketChannel;
import io.netty.channel.socket.nio.NioSocketChannel;import java.net.InetSocketAddress;public class EchoClient {private final String host;private final int port;public EchoClient(String host, int port) {this.host = host;this.port = port;}public void start() throws Exception {EventLoopGroup group = new NioEventLoopGroup();try {Bootstrap b = new Bootstrap();b.group(group).channel(NioSocketChannel.class).remoteAddress(new InetSocketAddress(host, port)).handler(new ChannelInitializer<SocketChannel>() {@Overridepublic void initChannel(SocketChannel ch) {ch.pipeline().addLast(new EchoClientHandler());}});ChannelFuture f = b.connect().sync();f.channel().closeFuture().sync();} finally {group.shutdownGracefully().sync();}}public static void main(String[] args) throws Exception {final String host = "localhost";final int port = 8080;new EchoClient(host, port).start();}
}客户端处理Handler
package Netty;import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
import io.netty.channel.ChannelHandler;
import io.netty.channel.ChannelHandlerContext;
import io.netty.channel.SimpleChannelInboundHandler;
import io.netty.util.CharsetUtil;@ChannelHandler.Sharable //1
public class EchoClientHandler extendsSimpleChannelInboundHandler<ByteBuf> {@Overridepublic void channelActive(ChannelHandlerContext ctx) {ctx.writeAndFlush(Unpooled.copiedBuffer("Netty rocks!",CharsetUtil.UTF_8));}@Overridepublic void channelRead0(ChannelHandlerContext ctx,ByteBuf in) {System.out.println("Client received: " + in.toString(CharsetUtil.UTF_8));}@Overridepublic void exceptionCaught(ChannelHandlerContext ctx,Throwable cause) { //4cause.printStackTrace();ctx.close();}
}Netty实现EventLoop
EventLoop是Netty的调度中心,负责监听多种事件类型
EventLoop的处理结构
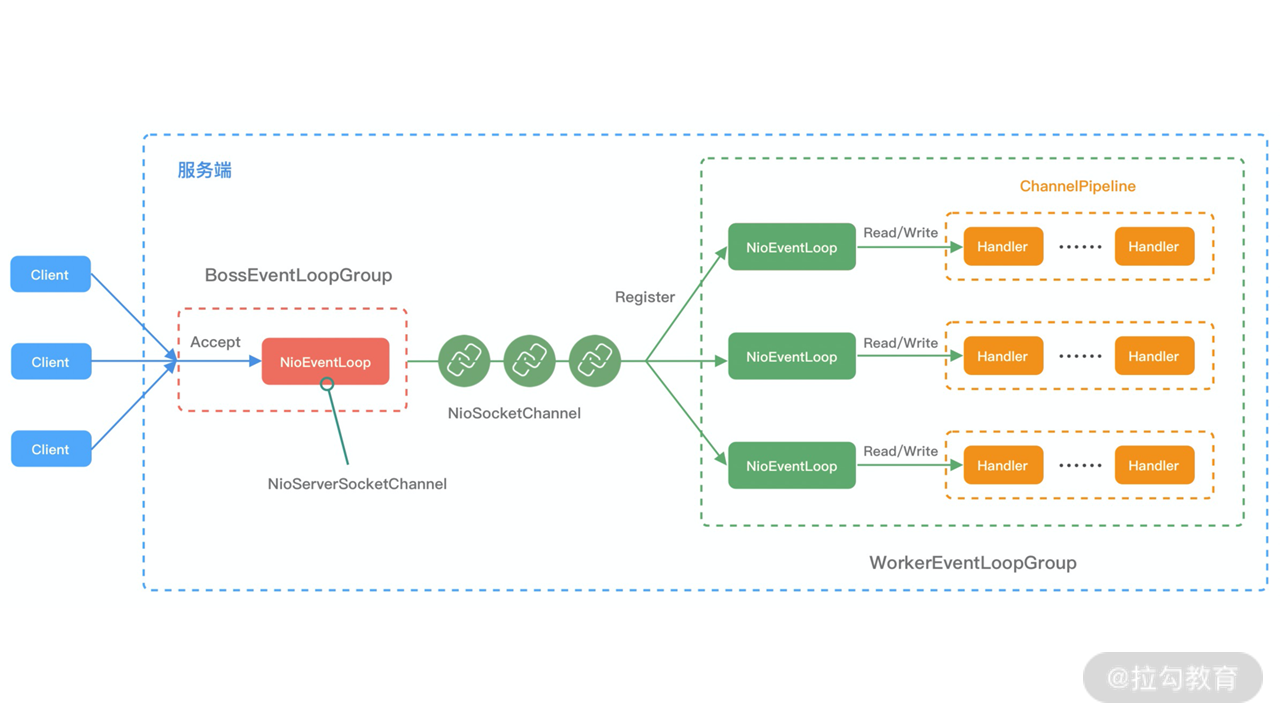
1、BossEventLoopGroup 和 WorkerEventLoopGroup 包含一个或者多个 NioEventLoop。BossEventLoopGroup 负责监听客户端的 Accept 事件,当事件触发时,将事件注册至 WorkerEventLoopGroup 中的一个 NioEventLoop 上。每新建一个 Channel, 只选择一个 NioEventLoop 与其绑定。所以说 Channel 生命周期的所有事件处理都是线程独立的,不同的 NioEventLoop 线程之间不会发生任何交集。
2、NioEventLoop 完成数据读取后,会调用绑定的 ChannelPipeline 进行事件传播,ChannelPipeline 也是线程安全的,数据会被传递到 ChannelPipeline 的第一个 ChannelHandler 中。数据处理完成后,将加工完成的数据再传递给下一个 ChannelHandler,整个过程是串行化执行,不会发生线程上下文切换的问题。
核心源码
@Overrideprotected void run() {int selectCnt = 0;for (;;) {try {int strategy;try {strategy = selectStrategy.calculateStrategy(selectNowSupplier, hasTasks());switch (strategy) {case SelectStrategy.CONTINUE:continue;case SelectStrategy.BUSY_WAIT:// fall-through to SELECT since the busy-wait is not supported with NIOcase SelectStrategy.SELECT://检查线程池是否有可利用的资源long curDeadlineNanos = nextScheduledTaskDeadlineNanos();if (curDeadlineNanos == -1L) {curDeadlineNanos = NONE; // nothing on the calendar}nextWakeupNanos.set(curDeadlineNanos);try {if (!hasTasks()) {//事件轮询strategy = select(curDeadlineNanos);}} finally {// This update is just to help block unnecessary selector wakeups// so use of lazySet is ok (no race condition)nextWakeupNanos.lazySet(AWAKE);}// fall throughdefault:}} catch (IOException e) {// If we receive an IOException here its because the Selector is messed up. Let's rebuild// the selector and retry. https://github.com/netty/netty/issues/8566rebuildSelector0();selectCnt = 0;handleLoopException(e);continue;}selectCnt++;cancelledKeys = 0;needsToSelectAgain = false;//Netty 提供了一个参数 ioRatio,可以调整 I/O 事件处理和任务处理的时间比例final int ioRatio = this.ioRatio;boolean ranTasks;if (ioRatio == 100) {try {if (strategy > 0) {//事件处理processSelectedKeys();}} finally {// Ensure we always run tasks.ranTasks = runAllTasks();}} else if (strategy > 0) {final long ioStartTime = System.nanoTime();try {processSelectedKeys();} finally {// Ensure we always run tasks.final long ioTime = System.nanoTime() - ioStartTime;ranTasks = runAllTasks(ioTime * (100 - ioRatio) / ioRatio);}} else {ranTasks = runAllTasks(0); // This will run the minimum number of tasks}if (ranTasks || strategy > 0) {if (selectCnt > MIN_PREMATURE_SELECTOR_RETURNS && logger.isDebugEnabled()) {logger.debug("Selector.select() returned prematurely {} times in a row for Selector {}.",selectCnt - 1, selector);}selectCnt = 0;} else if (unexpectedSelectorWakeup(selectCnt)) { // Unexpected wakeup (unusual case)selectCnt = 0;}} catch (CancelledKeyException e) {// Harmless exception - log anywayif (logger.isDebugEnabled()) {logger.debug(CancelledKeyException.class.getSimpleName() + " raised by a Selector {} - JDK bug?",selector, e);}} catch (Error e) {throw e;} catch (Throwable t) {handleLoopException(t);} finally {// Always handle shutdown even if the loop processing threw an exception.try {if (isShuttingDown()) {closeAll();if (confirmShutdown()) {return;}}} catch (Error e) {throw e;} catch (Throwable t) {handleLoopException(t);}}}}
NioEventLoop 不仅负责处理 I/O 事件,还要兼顾执行任务队列中的任务。任务队列遵循 FIFO 规则,可以保证任务执行的公平性。NioEventLoop 处理的任务类型基本可以分为三类。
1、普通任务:通过 NioEventLoop 的 execute() 方法向任务队列 taskQueue 中添加任务。例如 Netty 在写数据时会封装 WriteAndFlushTask 提交给 taskQueue。taskQueue 的实现类是多生产者单消费者队列 MpscChunkedArrayQueue,在多线程并发添加任务时,可以保证线程安全。
2、 定时任务:通过调用 NioEventLoop 的 schedule() 方法向定时任务队列 scheduledTaskQueue 添加一个定时任务,用于周期性执行该任务。例如,心跳消息发送等。定时任务队列 scheduledTaskQueue 采用优先队列 PriorityQueue 实现。
3、尾部队列:tailTasks 相比于普通任务队列优先级较低,在每次执行完 taskQueue 中任务后会去获取尾部队列中任务执行。尾部任务并不常用,主要用于做一些收尾工作,例如统计事件循环的执行时间、监控信息上报等。
Pipeline
整体结构
EventLoop是调度中心,但实际的业务逻辑会交给ChannelPipeline所定义的ChannelHandler完成。
首先ChannelPipeline与ChannelHandler是什么关系呢?
实际上,ChannelPipline可以看作是ChannelHandler 的容器载体,内部通过双向链表将不同的ChannelHandler链接在一起。
当有IO读写事件触发时,ChannelPipeline会依次调用ChannelHandler列表对Channel的数据进行拦截处理。
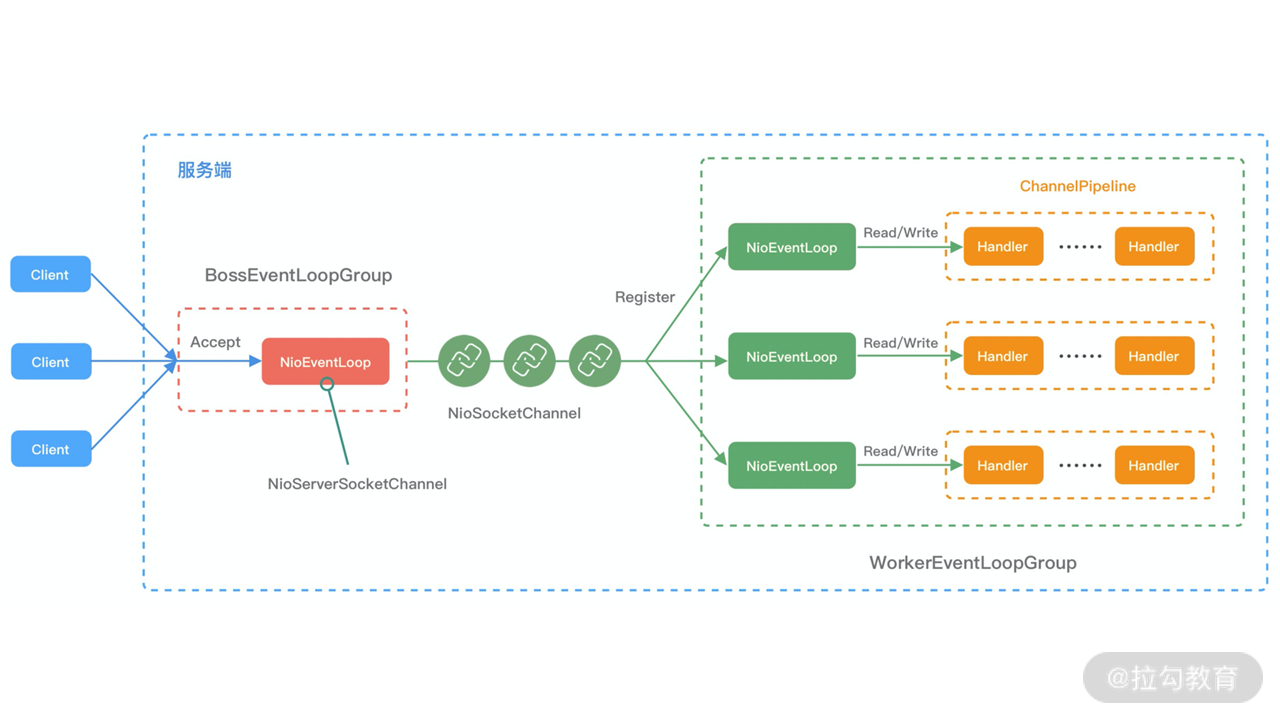
由图可知,每个Chanel会绑定一个ChannelPipeline,每个ChannelPipeline都包含多个ChannelHandlerContext,所有ChannelHandlerContext构成一个双向链表。
ChannelHandlerContext内部封装着ChannelHandler,同时保存着ChannleHandler 的上下文。如 connect、bind、read、flush、write、close 等
根据网络数据的流向,ChannelPipeline 分为入站 ChannelInboundHandler 和出站 ChannelOutboundHandler 两种处理器。
数据先由一系列 InboundHandler 处理后入站,然后再由相反方向的 OutboundHandler 处理完成后出站
ChannelPipeline 的双向链表分别维护了 HeadContext 和 TailContext 的头尾节点。我们自定义的 ChannelHandler 会插入到 Head 和 Tail 之间,这两个节点在 Netty 中已经默认实现了。
HeadContext 既是 Inbound 处理器,也是 Outbound 处理器。它分别实现了 ChannelInboundHandler 和 ChannelOutboundHandler。网络数据写入操作的入口就是由 HeadContext 节点完成的。HeadContext 作为 Pipeline 的头结点负责读取数据并开始传递 InBound 事件,当数据处理完成后,数据会反方向经过 Outbound 处理器,最终传递到 HeadContext,所以 HeadContext 又是处理 Outbound 事件的最后一站。此外 HeadContext 在传递事件之前,还会执行一些前置操作。
TailContext 只实现了 ChannelInboundHandler 接口。它会在 ChannelInboundHandler 调用链路的最后一步执行,主要用于终止 Inbound 事件传播,例如释放 Message 数据资源等。TailContext 节点作为 OutBound 事件传播的第一站,仅仅是将 OutBound 事件传递给上一个节点。
事件传播机制
ChannelPipeline 可分为入站 ChannelInboundHandler 和出站 ChannelOutboundHandler 两种处理器,与此对应传输的事件类型可以分为Inbound 事件和Outbound 事件。
我们通过一个代码示例,一起体验下 ChannelPipeline 的事件传播机制。
serverBootstrap.childHandler(new ChannelInitializer<SocketChannel>() {@Overridepublic void initChannel(SocketChannel ch) {ch.pipeline().addLast(new SampleInBoundHandler("SampleInBoundHandlerA", false)).addLast(new SampleInBoundHandler("SampleInBoundHandlerB", false)).addLast(new SampleInBoundHandler("SampleInBoundHandlerC", true));ch.pipeline().addLast(new SampleOutBoundHandler("SampleOutBoundHandlerA")).addLast(new SampleOutBoundHandler("SampleOutBoundHandlerB")).addLast(new SampleOutBoundHandler("SampleOutBoundHandlerC"));}}public class SampleInBoundHandler extends ChannelInboundHandlerAdapter {private final String name;private final boolean flush;public SampleInBoundHandler(String name, boolean flush) {this.name = name;this.flush = flush;}@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {System.out.println("InBoundHandler: " + name);if (flush) {ctx.channel().writeAndFlush(msg);} else {super.channelRead(ctx, msg);}}}
public class SampleOutBoundHandler extends ChannelOutboundHandlerAdapter {private final String name;public SampleOutBoundHandler(String name) {this.name = name;}@Overridepublic void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {System.out.println("OutBoundHandler: " + name);super.write(ctx, msg, promise);}}
通过 Pipeline 的 addLast 方法分别添加了三个 InboundHandler 和 OutboundHandler,添加顺序都是 A -> B -> C,下图可以表示初始化后 ChannelPipeline 的内部结构。

当客户端向服务端发送请求时,会触发 SampleInBoundHandler 调用链的 channelRead 事件。经过 SampleInBoundHandler 调用链处理完成后,在 SampleInBoundHandlerC 中会调用 writeAndFlush 方法向客户端写回数据,此时会触发 SampleOutBoundHandler 调用链的 write 事件。
由此可见,Inbound 事件和 Outbound 事件的传播方向是不一样的。Inbound 事件的传播方向为 Head -> Tail,而 Outbound 事件传播方向是 Tail -> Head,两者恰恰相反。在 Netty 应用编程中一定要理清楚事件传播的顺序。推荐你在系统设计时模拟客户端和服务端的场景画出 ChannelPipeline 的内部结构图,以避免搞混调用关系。
异常传播机制
ChannelPipeline 事件传播的实现采用了经典的责任链模式,调用链路环环相扣。那么如果有一个节点处理逻辑异常会出现什么现象呢?
异常按顺序从 Head 节点传播到 Tail 节点。如果用户没有对异常进行拦截处理,最后将由 Tail 节点统一处理,在 TailContext 源码中可以找到具体实现:
protected void onUnhandledInboundException(Throwable cause) {try {logger.warn("An exceptionCaught() event was fired, and it reached at the tail of the pipeline. " +"It usually means the last handler in the pipeline did not handle the exception.",cause);} finally {ReferenceCountUtil.release(cause);}}
虽然 Netty 中 TailContext 提供了兜底的异常处理逻辑,但是在很多场景下,并不能满足我们的需求。假如你需要拦截指定的异常类型,并做出相应的异常处理,应该如何实现呢?我们接着往下看。
异常处理的最佳实践
过异常传播机制的学习,我们应该可以想到最好的方法是在 ChannelPipeline 自定义处理器的末端添加统一的异常处理器,此时 ChannelPipeline 的内部结构如下图所示。

用户自定义的异常处理器代码示例如下:
public class ExceptionHandler extends ChannelDuplexHandler {@Overridepublic void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {if (cause instanceof RuntimeException) {System.out.println("Handle Business Exception Success.");}}}
加入统一的异常处理器后,可以看到异常已经被优雅地拦截并处理掉了。这也是 Netty 推荐的最佳异常处理实践。
总结
ChannelPipeline 是双向链表结构,包含 ChannelInboundHandler 和 ChannelOutboundHandler 两种处理器。
ChannelHandlerContext 是对 ChannelHandler 的封装,每个 ChannelHandler 都对应一个 ChannelHandlerContext,实际上 ChannelPipeline 维护的是与 ChannelHandlerContext 的关系。
Inbound 事件和 Outbound 事件的传播方向相反,Inbound 事件的传播方向为 Head -> Tail,而 Outbound 事件传播方向是 Tail -> Head。
异常事件的处理顺序与 ChannelHandler 的添加顺序相同,会依次向后传播,与 Inbound 事件和 Outbound 事件无关。
粘包拆包问题:如何获取一个完整的网络包?
粘包/拆包的物种现象
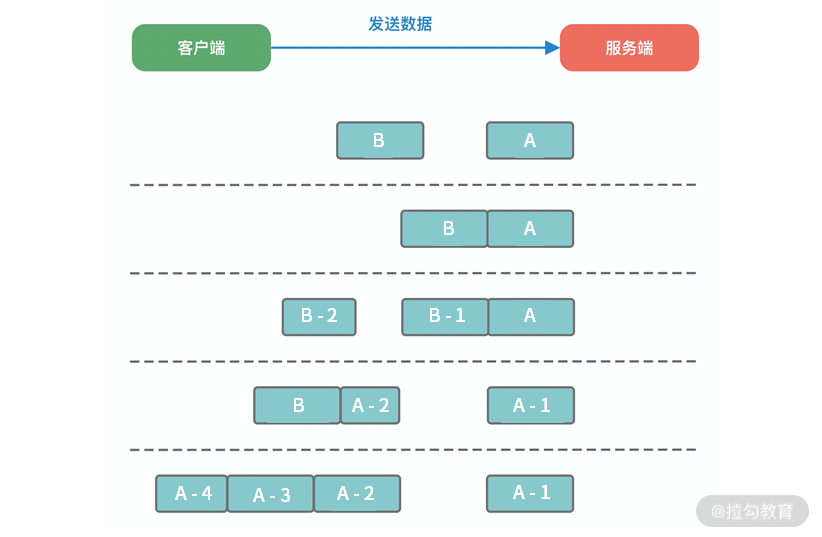
- 服务端恰巧读到了两个完整的数据包 A 和 B,没有出现拆包/粘包问题;
- 服务端接收到 A 和 B 粘在一起的数据包,服务端需要解析出 A 和 B;
- 服务端收到完整的 A 和 B 的一部分数据包 B-1,服务端需要解析出完整的 A,并等待读取完整的 B 数据包;
- 服务端接收到 A 的一部分数据包 A-1,此时需要等待接收到完整的 A 数据包;
- 数据包 A 较大,服务端需要多次才可以接收完数据包 A。
由于拆包/粘包问题的存在,数据接收方很难界定数据包的边界在哪里,很难识别出一个完整的数据包。所以需要提供一种机制来识别数据包的界限,这也是解决拆包/粘包的唯一方法:定义应用层的通信协议。下面我们一起看下主流协议的解决方案。
主流解决方案:
1、消息长度固定
2、特定分隔符 --》Redis采用换行符
3、消息长度 + 消息内容–》主流方案,dubbo,rockerMQ
Netty实现自定义协议
首先我们看下 Netty 中编解码器是如何分类的。
Netty 常用编码器类型:
MessageToByteEncoder 对象编码成字节流;
MessageToMessageEncoder 一种消息类型编码成另外一种消息类型。
Netty 常用解码器类型:
ByteToMessageDecoder/ReplayingDecoder 将字节流解码为消息对象;
MessageToMessageDecoder 将一种消息类型解码为另外一种消息类型。
编解码器可以分为一次解码器和二次解码器,一次解码器用于解决 TCP 拆包/粘包问题,按协议解析后得到的字节数据。如果你需要对解析后的字节数据做对象模型的转换,这时候便需要用到二次解码器,同理编码器的过程是反过来的。
一次编解码器:MessageToByteEncoder/ByteToMessageDecoder。
二次编解码器:MessageToMessageEncoder/MessageToMessageDecoder。
需要编码类实际上再ChannelOutBoundHandler的抽象类实现,具体操作时OutBound出站数据。
同样,解码类是 ChanneInboundHandler 的抽象类实现,操作的是 Inbound 入站数据。解码器实现的难度要远大于编码器,因为解码器需要考虑拆包/粘包问题。由于接收方有可能没有接收到完整的消息,所以解码框架需要对入站的数据做缓冲操作,直至获取到完整的消息。
Netty 提供了很多开箱即用的解码器,这些解码器基本覆盖了 TCP 拆包/粘包的通用解决方案。
固定长度解码器 FixedLengthFrameDecoder
固定长度解码器 FixedLengthFrameDecoder 非常简单,直接通过构造函数设置固定长度的大小 frameLength,无论接收方一次获取多大的数据,都会严格按照 frameLength 进行解码。如果累积读取到长度大小为 frameLength 的消息,那么解码器认为已经获取到了一个完整的消息。如果消息长度小于 frameLength,FixedLengthFrameDecoder 解码器会一直等后续数据包的到达,直至获得完整的消息。
特殊分隔符解码器 DelimiterBasedFrameDecoder
使用特殊分隔符解码器 DelimiterBasedFrameDecoder 之前我们需要了解以下几个属性的作用。
delimiters
delimiters 指定特殊分隔符,通过写入 ByteBuf 作为参数传入。delimiters 的类型是 ByteBuf 数组,所以我们可以同时指定多个分隔符,但是最终会选择长度最短的分隔符进行消息拆分。
maxLength
maxLength 是报文最大长度的限制。如果超过 maxLength 还没有检测到指定分隔符,将会抛出 TooLongFrameException。可以说 maxLength 是对程序在极端情况下的一种保护措施。
failFast
failFast 与 maxLength 需要搭配使用,通过设置 failFast 可以控制抛出 TooLongFrameException 的时机,可以说 Netty 在细节上考虑得面面俱到。如果 failFast=true,那么在超出 maxLength 会立即抛出 TooLongFrameException,不再继续进行解码。如果 failFast=false,那么会等到解码出一个完整的消息后才会抛出 TooLongFrameException。
stripDelimiter
stripDelimiter 的作用是判断解码后得到的消息是否去除分隔符。如果 stripDelimiter=false,特定分隔符为 \n,那么上述数据包解码出的结果为:
长度域解码器 LengthFieldBasedFrameDecoder
长度域解码器 LengthFieldBasedFrameDecoder 是解决 TCP 拆包/粘包问题最常用的解码器。它基本上可以覆盖大部分基于长度拆包场景,开源消息中间件 RocketMQ 就是使用 LengthFieldBasedFrameDecoder 进行解码的。
首先我们同样先了解 LengthFieldBasedFrameDecoder 中的几个重要属性,这里我主要把它们分为两个部分:长度域解码器特有属性以及与其他解码器(如特定分隔符解码器)的相似的属性。
长度域解码器特有属性。
// 长度字段的偏移量,也就是存放长度数据的起始位置
private final int lengthFieldOffset;
// 长度字段所占用的字节数
private final int lengthFieldLength;
/** 消息长度的修正值* 在很多较为复杂一些的协议设计中,长度域不仅仅包含消息的长度,而且包含其他的数据,如版本号、数据类型、数据状态等,那么这时候我们需要使用 lengthAdjustment 进行修正* lengthAdjustment = 包体的长度值 - 长度域的值*/
private final int lengthAdjustment;
// 解码后需要跳过的初始字节数,也就是消息内容字段的起始位置
private final int initialBytesToStrip;
// 长度字段结束的偏移量,lengthFieldEndOffset = lengthFieldOffset + lengthFieldLength
private final int lengthFieldEndOffset;
与固定长度解码器和特定分隔符解码器相似的属性。
private final int maxFrameLength; // 报文最大限制长度
private final boolean failFast; // 是否立即抛出 TooLongFrameException,与 maxFrameLength 搭配使用
private boolean discardingTooLongFrame; // 是否处于丢弃模式
private long tooLongFrameLength; // 需要丢弃的字节数
private long bytesToDiscard; // 累计丢弃的字节数
在 Netty LengthFieldBasedFrameDecoder 源码的注释中已经描述得非常详细,一共给出了 7 个场景示例,理解了这些示例基本上可以真正掌握 LengthFieldBasedFrameDecoder 的参数用法。
数据传输:writeAndFlush 处理流程剖析
源码查看链路:
ctx.channel().writeAndFlush(response);
点进去
DefaultChannelPipeline.java
@Override
public final ChannelFuture writeAndFlush(Object msg) {return tail.writeAndFlush(msg);
}@Overridepublic ChannelFuture writeAndFlush(Object msg, ChannelPromise promise) {write(msg, true, promise);return promise;}next.invokeWriteAndFlush(m, promise);void invokeWriteAndFlush(Object msg, ChannelPromise promise) {if (invokeHandler()) {invokeWrite0(msg, promise);invokeFlush0();} else {writeAndFlush(msg, promise);}}可以总结以下三点:
writeAndFlush 属于出站操作,它是从 Pipeline 的 Tail 节点开始进行事件传播,一直向前传播到 Head 节点。不管在 write 还是 flush 过程,Head 节点都中扮演着重要的角色。
write 方法并没有将数据写入 Socket 缓冲区,只是将数据写入到 ChannelOutboundBuffer 缓存中,ChannelOutboundBuffer 缓存内部是由单向链表实现的。
flush 方法才最终将数据写入到 Socket 缓冲区。
零拷贝技术
发展历程
传统拷贝技术
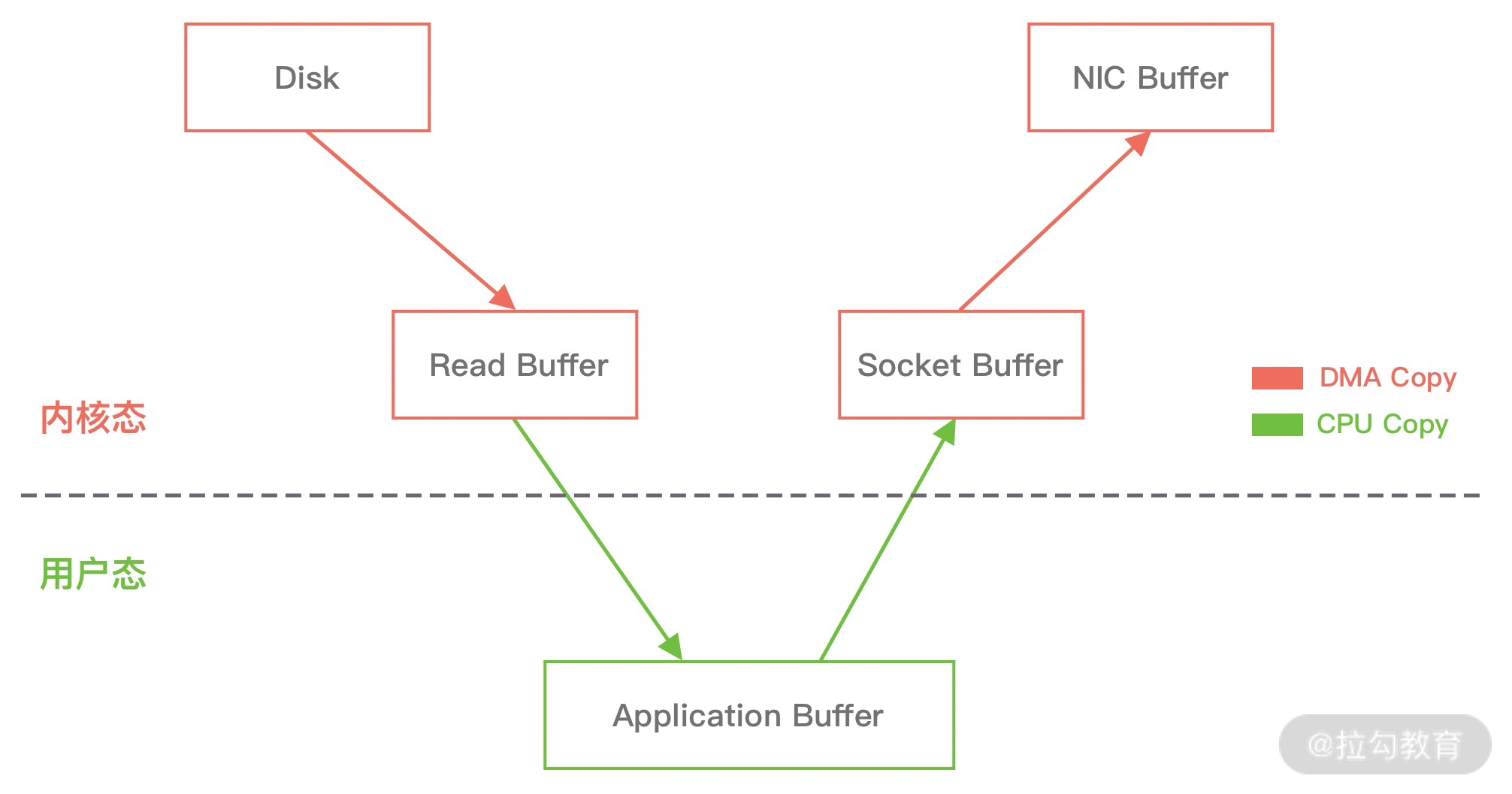
DMA(Direct Memory Access,直接内存存取)是现代大部分硬盘都支持的特性,DMA 接管了数据读写的工作,不需要 CPU 再参与 I/O 中断的处理,从而减轻了 CPU 的负担。
DMA 引擎从文件读取数据后放入到内核缓冲区,然后可以直接从内核缓冲区传输到 Socket 缓冲区,从而减少内存拷贝的次数。
Java 中也使用了零拷贝技术,它就是 NIO FileChannel 类中的 transferTo() 方法,transferTo() 底层就依赖了操作系统零拷贝的机制,它可以将数据从 FileChannel 直接传输到另外一个 Channel。transferTo() 方法的定义如下:
public abstract long transferTo(long position, long count, WritableByteChannel target) throws IOException;
在使用了 FileChannel#transferTo() 传输数据之后,我们看下数据拷贝流程发生了哪些变化,如下图所示:
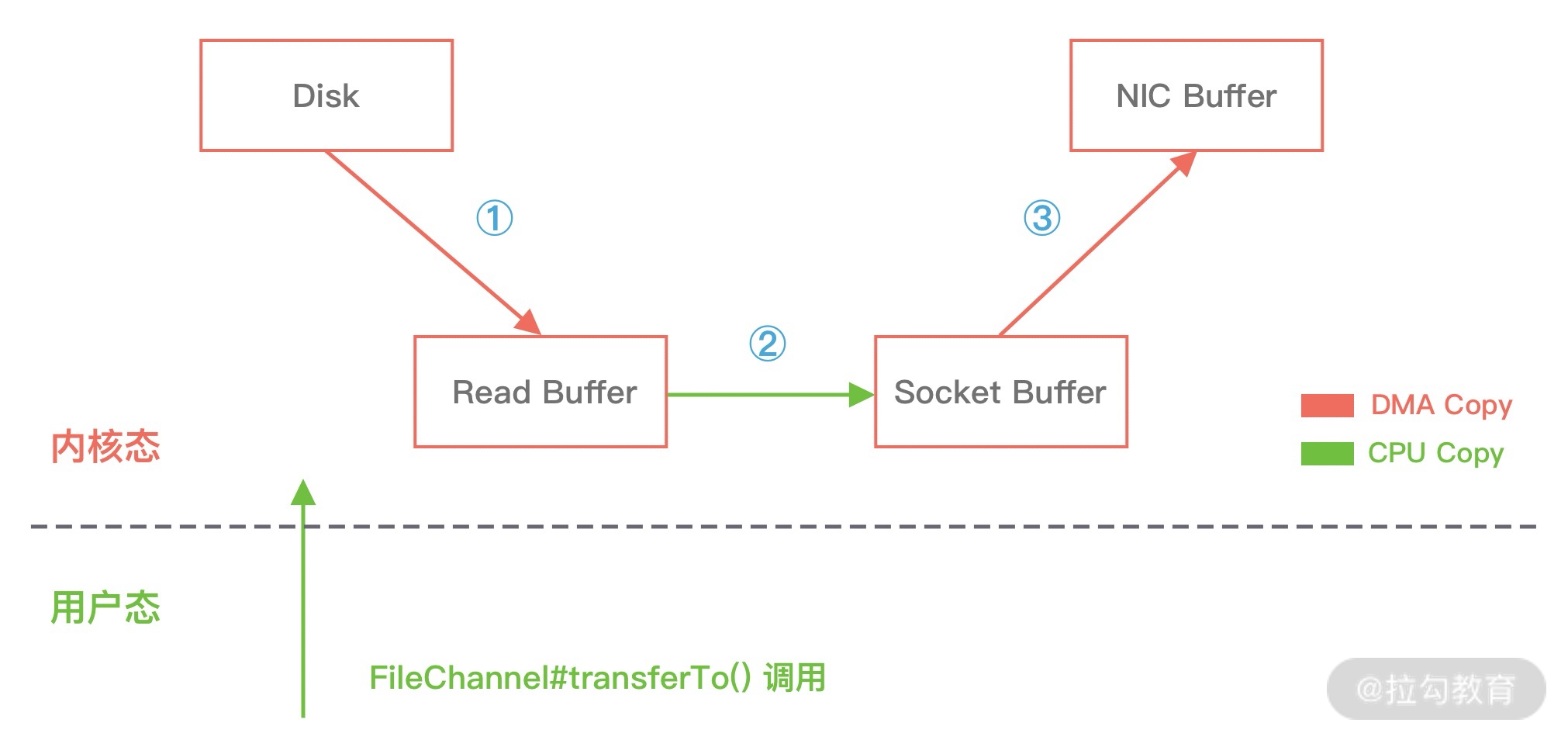
比较大的一个变化是,DMA 引擎从文件中读取数据拷贝到内核态缓冲区之后,由操作系统直接拷贝到 Socket 缓冲区,不再拷贝到用户态缓冲区,所以数据拷贝的次数从之前的 4 次减少到 3 次。
在 Linux 2.4 版本之后,开发者对 Socket Buffer 追加一些 Descriptor 信息来进一步减少内核数据的复制。如下图所示,DMA 引擎读取文件内容并拷贝到内核缓冲区,然后并没有再拷贝到 Socket 缓冲区,只是将数据的长度以及位置信息被追加到 Socket 缓冲区,然后 DMA 引擎根据这些描述信息,直接从内核缓冲区读取数据并传输到协议引擎中,从而消除最后一次 CPU 拷贝。
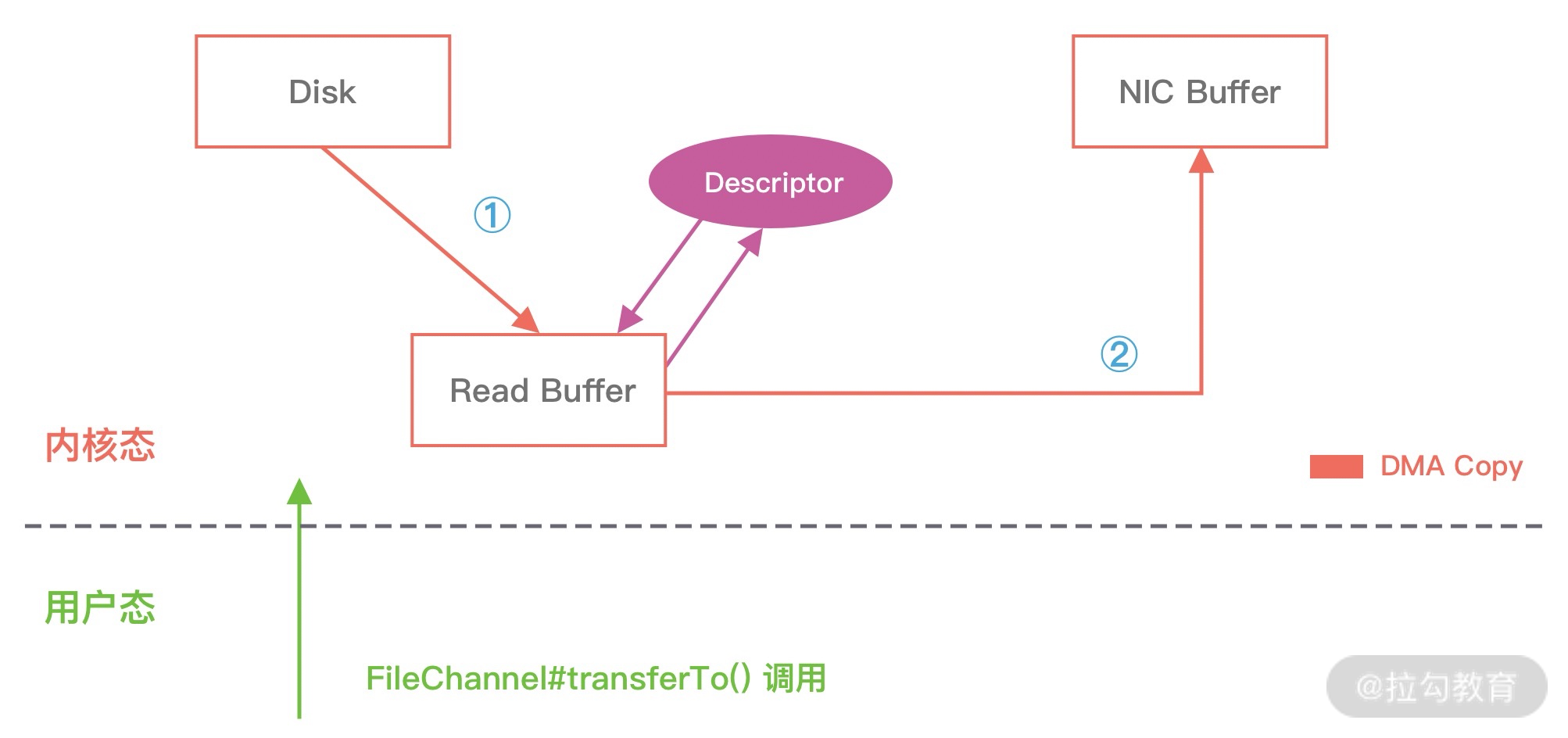
从 Linux 操作系统的角度来说,零拷贝就是为了避免用户态和内存态之间的数据拷贝。无论是传统的数据拷贝还是使用零拷贝技术,其中有 2 次 DMA 的数据拷贝必不可少,只是这 2 次 DMA 拷贝都是依赖硬件来完成,不需要 CPU 参与。所以,在这里我们讨论的零拷贝是个广义的概念,只要能够减少不必要的 CPU 拷贝,都可以被称为零拷贝。
netty的零拷贝技术
Netty 除了支持操作系统级别的零拷贝,更多提供了面向用户态的零拷贝特性,主要体现在 5 个方面:堆外内存、CompositeByteBuf、Unpooled.wrappedBuffer、ByteBuf.slice 以及 FileRegion
堆外内存
堆内内存是受到Java虚拟机管理的内存,JVM有自己的垃圾回收算法,对于使用者来说不必关心对象的内存如何回收。
堆外内存与堆内存相对应,对于整个机器内存而言,除了堆内内存之外的部分即为堆外内存。
申请堆外内存
// 分配 10M 堆外内存long address = unsafe.allocateMemory(10 * 1024 * 1024);
与 DirectByteBuffer 不同的是,Unsafe#allocateMemory 所分配的内存必须自己手动释放,否则会造成内存泄漏,这也是 Unsafe 不安全的体现。Unsafe 同样提供了内存释放的操作:
unsafe.freeMemory(address);
堆外内存的引用关系如下:
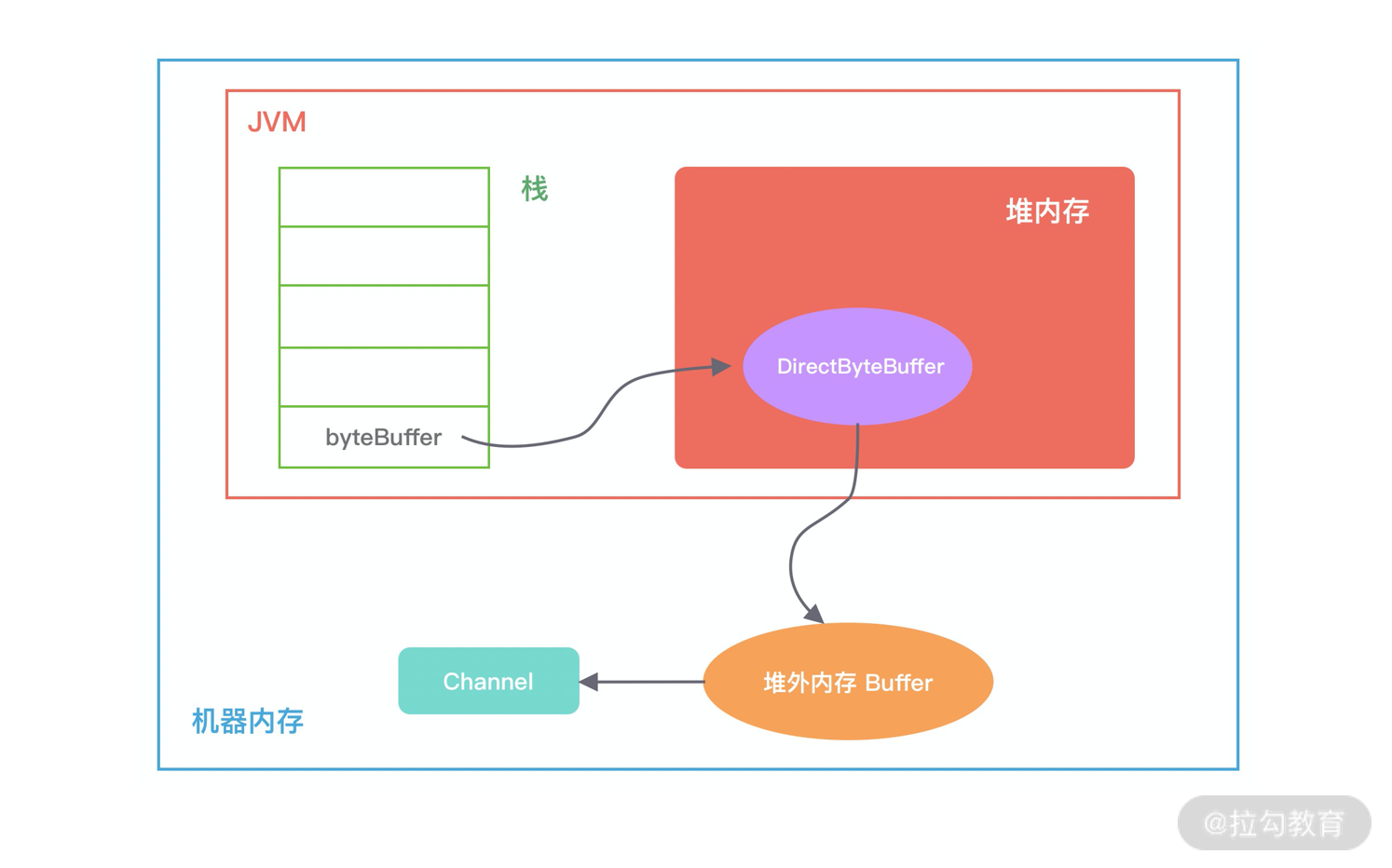
first 是 Cleaner 类中的静态变量,Cleaner 对象在初始化时会加入 Cleaner 链表中。DirectByteBuffer 对象包含堆外内存的地址、大小以及 Cleaner 对象的引用,ReferenceQueue 用于保存需要回收的 Cleaner 对象。
当发生 GC 时,DirectByteBuffer 对象被回收
此时 Cleaner 对象不再有任何引用关系,在下一次 GC 时,该 Cleaner 对象将被添加到 ReferenceQueue 中,并执行 clean() 方法。clean() 方法主要做两件事情:
1、将 Cleaner 对象从 Cleaner 链表中移除;
2、调用 unsafe.freeMemory 方法清理堆外内存。
ByteBuf
ByteBuf 分类
可以划分为三个不同的维度:Heap/Direct、Pooled/Unpooled和Unsafe/非 Unsafe
**Heap/Direct 就是堆内和堆外内存。**Heap 指的是在 JVM 堆内分配,底层依赖的是字节数据;Direct 则是堆外内存,不受 JVM 限制,分配方式依赖 JDK 底层的 ByteBuffer。
**Pooled/Unpooled 表示池化还是非池化内存。**Pooled 是从预先分配好的内存中取出,使用完可以放回 ByteBuf 内存池,等待下一次分配。而 Unpooled 是直接调用系统 API 去申请内存,确保能够被 JVM GC 管理回收。
Unsafe/非 Unsafe 的区别在于操作方式是否安全。 Unsafe 表示每次调用 JDK 的 Unsafe 对象操作物理内存,依赖 offset + index 的方式操作数据。非 Unsafe 则不需要依赖 JDK 的 Unsafe 对象,直接通过数组下标的方式操作数据。
常用API
写入操作:
writeByte(byte b): 向缓冲区中写入一个字节。
writeShort(short s): 向缓冲区中写入一个短整型数据(2 字节)。
writeInt(int i): 向缓冲区中写入一个整型数据(4 字节)。
writeLong(long l): 向缓冲区中写入一个长整型数据(8 字节)。
writeBytes(byte[] src): 将字节数组中的数据写入到缓冲区。
writeBytes(ByteBuf src): 将另一个 ByteBuf 中的数据写入到缓冲区。
读取操作:
readByte(): 从缓冲区中读取一个字节。
readShort(): 从缓冲区中读取一个短整型数据(2 字节)。
readInt(): 从缓冲区中读取一个整型数据(4 字节)。
readLong(): 从缓冲区中读取一个长整型数据(8 字节)。
readBytes(byte[] dst): 从缓冲区中读取数据到字节数组。
readBytes(ByteBuf dst, int length): 从缓冲区中读取指定长度的数据到另一个 ByteBuf 中。
获取和设置操作:
getByte(int index): 获取缓冲区中指定位置的字节值。
setByte(int index, byte b): 设置缓冲区中指定位置的字节值。
getShort(int index): 获取缓冲区中指定位置的短整型数据。
setShort(int index, short s): 设置缓冲区中指定位置的短整型数据。
getInt(int index): 获取缓冲区中指定位置的整型数据。
setInt(int index, int i): 设置缓冲区中指定位置的整型数据。
getLong(int index): 获取缓冲区中指定位置的长整型数据。
setLong(int index, long l): 设置缓冲区中指定位置的长整型数据。
其他操作:
capacity(): 获取缓冲区的容量。
readerIndex() / writerIndex(): 获取读写指针的位置。
readableBytes() / writableBytes(): 获取可读/可写字节数。
clear() / resetReaderIndex() / resetWriterIndex(): 清空缓冲区或重置读写指针。
slice() / duplicate(): 创建缓冲区的切片或复制。
release(): 释放缓冲区。
4.10)

-使用UG NX的开发模板创建项目失败的原因和解决方案)


)
4.9)



)








