🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/

大语言模型在众多应用领域实现了突破性的进步,显著提升了各种任务的完成度。然而,其庞大的规模也带来了高昂的计算成本。这些模型往往包含数十亿甚至上千亿参数,需要巨大的计算资源来运行。特别是,当需要为特定的下游任务定制模型时,尤其是在计算能力有限的硬件平台上,这一挑战尤为突出。
为了提升 LLM 在未见用户数据集和任务上的性能,微调仍是关键。随着模型规模的不断扩大,如从 GPT-2 的 1.5B 参数增长到 GPT-3 的 175B 参数,标准的全微调范式需要成千上万的 GPUs 并行工作,这在效率和可持续性方面表现不佳。此外,它可能损害模型的泛化能力,以及导致灾难性遗忘问题。为解决这一问题,参数高效微调(PEFT) 算法应运而生。该算法通过调整少量参数,在下游任务上实现了优于全面微调的性能。
参数高效微调(PEFT)是一种实用的解决方案,它涉及选择性地调整模型中的少数参数,而保持其他参数不变。调整大语言模型以高效地适应各种下游任务。PEFT 通过最小化新增参数数量或降低计算资源需求来调整预训练模型,这在计算资源受限的情况下尤为重要。在处理参数数量庞大的大语言模型时,这种方法尤为有价值。因为从头开始微调这些模型不仅计算代价高昂,而且资源密集,这给支持系统平台设计带来了相当大的挑战。
我们将 PEFT 算法按照其操作方式分为加法、选择性、重参数化和混合微调四类。如图 3 所示,常见的加法微调算法主要有三种:(1)适配器;(2)软提示;(3)其他。这些算法在附加的可调模块或参数上存在差异。相比之下,选择性微调无需额外参数,它仅从骨干模型中选择部分参数,使这些参数在下游任务微调过程中可调,而保持大多数参数不变。我们根据所选参数的分组将选择性微调分为:(1)非结构化遮罩;(2)结构化遮罩。重参数化则是指在两种等效形式之间转换模型参数。具体而言,重参数化微调在训练过程中引入额外的低秩可训练参数,并在推理时将这些参数与原始模型集成。这种方法主要分为两种策略:(1)低秩分解;(2)LoRA 衍生物。混合微调则探索了不同 PEFT 方法的设计空间,并结合了它们的优点。
自然语言处理目前存在一个重要的范式:大规模预训练一般领域数据,并针对特定任务或领域进行微调(Fine-tuning)。然而,随着预训练语言模型规模的不断扩大,该范式面临以下问题:
-
在微调大语言模型时,由于训练成本高昂,不太可能对所有模型参数进行重新训练。
-
以往的方法都存在不同程度的性能问题。例如,adapter 增加了模型的层数,从而引入了额外的推理延迟;而 Prefix-Tuning 的训练难度较大,效果也不如直接进行微调。
模型通常过参数化,拥有较小的内在维度,并主要依赖这一低内在维度进行任务适配。基于假设,模型在任务适配过程中权重的改变量具有低秩特性,研究者提出了低秩自适应(LoRA)方法。LoRA 允许我们通过优化适应过程中密集层变化的秩分解矩阵来间接训练神经网络中的部分密集层,同时保持预训练权重的稳定。LoRA 的实现思想简洁明了,即通过冻结预训练语言模型的矩阵参数,并选用 A 和 B 矩阵进行替代。在下游任务中,仅更新 A 和 B 矩阵,如图所示。
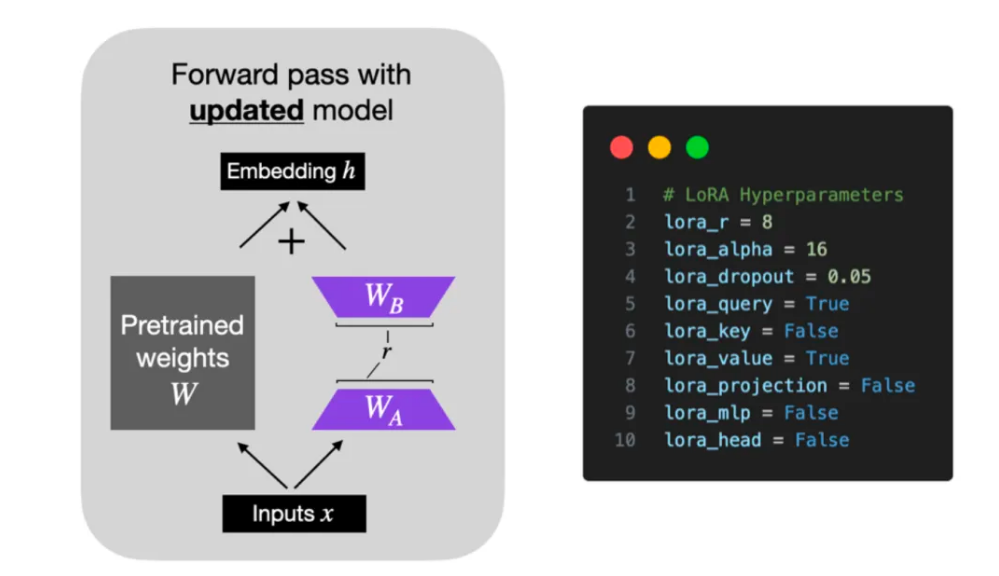
结合图片来看,LoRA 的实现流程如下:
-
在原始预训练语言模型(PLM)的基础上,我们引入了一个旁路,通过降维再升维的操作,来模拟所谓的内在秩。
-
在训练过程中,我们将固定预训练语言模型(PLM)的参数,仅对降维矩阵 A 和升维矩阵 B 进行训练。
-
模型的输入输出维度保持不变,输出时,将 BA 与 PLM 的参数进行叠加。
-
使用随机高斯分布对矩阵 A 进行初始化,同时将矩阵 B 初始化为 0 矩阵,以确保训练开始时,旁路矩阵仍维持为 0 矩阵状态。
具体实现:接下来我们从公式上解释 LoRA 的实现。假设要在下游任务微调一个预训练语言模型(如 GPT-3),则需要更新预训练模型参数,公式表示如下:
h = W 0 x + Δ W x = W 0 x + B A x h=W_{0} x+\Delta W x=W_{0} x+B A x h=W0x+ΔWx=W0x+BAx
W0 是预训练模型的初始化参数,而 ΔW 是需要更新的参数。在全参数微调的情况下,参数量等同于 W0 的参数量。例如,对于 GPT3,ΔW 的参数量约为 175B。由此可见,全参数微调大型语言模型对于资源有限的环境来说是不切实际的。鉴于前人的研究揭示预训练语言模型具有较低的 “内部维度”,这些模型在任务适配过程中即便被随机投影到较小的子空间,也能保持有效的学习。因此,LoRA 引入了一个小参数模块,专门用于学习改变量 ΔW。
在训练过程中,W0 保持不变,而 A 和 B 包含训练参数,会发生变化。在推理阶段,只需将变化量融入原模型,即可实现无延迟操作。若要切换任务,只需在切换过程中减去 BA,并替换为用其他任务训练好的 B’A’ 即可。
总的来说,LoRA 是一种简单而有效的轻量级微调方案,它基于大语言模型的内在低秩特性,通过增加旁路矩阵来模拟全参数微调。目前,LoRA 技术已广泛应用于大语言模型的微调,如 Alpaca 和 Stable Diffusion + LoRA,并能与其他高效的参数微调方法,如最先进的参数高效微调(PEFT)有效结合。
“r” 是 LoRA 中至关重要的参数,它决定了 LoRA 矩阵的秩或维度,对模型的复杂度和容量产生直接影响。当 “r” 值较高时,模型的表达能力增强,但可能引发过拟合问题;相反,降低 “r” 值可以减少过拟合,但相应地,模型的表达能力会有所减弱。在我们保持所有层都启用 LoRA 的前提下,将 “r” 值从 8 提升至 16,以探究其对性能的具体影响。一般来说,微调 LLM 时选择的 alpha 值是秩的两倍。调整 “alpha” 有助于在拟合数据和通过正则化防止过拟合之间保持平衡。
QLoRA,即量化 LoRA 的简称,由 Tim Dettmers 等人提出。它是一种在微调过程中有效降低内存占用的技术。在反向传播阶段,QLoRA 将预训练的权重量化为 4-bit,并采用分页优化器来管理内存峰值。QLo、RA 会增加运行时间成本(因为量化和反量化增加了额外步骤),但它是一种很好的节省内存的方法。此外,AdamW 优化器是 LLM 训练的常用选择。此外,虽然学习率调度器可能有益,但 AdamW 和 SGD 优化器之间几乎没有区别。
LongLoRA:增强大语言模型(LLM)的长上下文处理能力,而无需大量算力资源。LongLoRA 通过使用一种简化的注意力形式和 LoRA 方法来高效扩展上下文长度,成功在 LLaMA2 7B/13B/70B 模型上将上下文长度扩展至 32K、64K、100K,几乎不增加算力消耗。此外,研究还创建了 LongQA 数据集来进一步改进模型的输出能力,并证明了通过增加训练信息量可以获得更好的结果。LongLoRA 不仅兼容现有技术,而且在处理长文本和长对话中寻找特定主题方面表现出色,为大型语言模型领域带来了创新的微调方法。
注意:LoRA 经常与现代的 LLMs 结合使用。尽管如此,众多 LoRA 的变体已经涌现(LoRA+、VeRA、LoRA-FA、LoRa-drop、AdaLoRA、DoRA、Delta-LoRA),它们以不同方式偏离了原始方法,旨在提升速度、性能或两者兼具。
-
LoRA+ 通过为两个矩阵设置不同学习率来提高训练效率;
-
VeRA 减少参数数量,通过训练额外的向量而非直接训练矩阵 A 和 B;
-
LoRA-FA 只训练矩阵 B;
-
LoRA-drop 决定哪些层值得通过 LoRA 增强;
-
AdaLoRA 动态调整矩阵的秩;
-
DoRA分别训练大小和方向;
-
Delta-LoRA 通过 A 和 B 的梯度更新预训练矩阵 W。
这些方法展示了在不牺牲性能的情况下,如何通过创新思路减少训练大语言模型的计算需求。
AdapterFusion 算法,用以实现多个 Adapter 模块间的最大化任务迁移。通过将适配器的训练划分为知识提取和知识组合两个阶段,成功解决了灾难性遗忘、任务间干扰以及训练不稳定的问题。然而,Adapter 模块的引入增加了模型的整体参数量,进而影响了模型在推理时的性能。AdapterFusion 在大多数情况下性能优于全模型微调和 Adapter。
前缀微调(Prefix-Tunning)是一种用于生成任务的轻量级微调方法。它通过向输入添加一个特定的、连续的任务向量序列,即 “前缀”,来实现这一点。这些前缀在图中以红色块表示。与提示(Prompt)不同,前缀完全由自由参数组成,不与真实的 token 相对应。与传统的微调相比,前缀微调仅针对前缀进行优化。因此,我们只需存储一个大型 Transformer 模型和已知任务特定前缀的副本,这使得为每个额外任务产生的开销非常小。
Prompt-tuning 为每个任务定义了独特的 Prompt,并将其与数据拼接作为输入。在此过程中,预训练模型被冻结以进行训练。值得注意的是,随着模型规模的扩大,其效果逐渐提升,并最终与微调效果相当。此外,Prompt-tuning 还引入了 Prompt-ensembling 的概念,即在同一批次中同时训练同一任务的不同 Prompt。这种方法相当于训练了多个不同的「模型,但相较于模型集成,其成本大幅降低。
P-Tuning 方法旨在解决大语言模型中 Prompt 构造方式对下游任务效果的重大影响问题。通过引入连续可微的 virtual token 替代传统的离散 token,实现了模板的自动构建,使得 GPT 在 SuperGLUE 上的成绩首次超过了 BERT 模型,改变了 GPT 不擅长 NLU 的观点。P-Tuning 将 Prompt 转换为可学习的 Embedding 层,通过 MLP+LSTM 处理,提高了模型的适应性和性能。P-Tuning v2 进一步改进,通过在每一层都加入 Prompts tokens 作为输入,不仅增加了可学习的参数,还提高了模型预测的直接影响,显示出跨规模和 NLU 任务的通用性。此外,P-Tuning v2 还引入了多任务学习和回归传统分类标签范式,提高了训练效率和模型的通用性。
📚️ 相关链接:
-
《大型模型的参数高效微调》全面综述
-
LongLoRA:超长上下文,大语言模型高效微调方法
-
腾讯技术工程 - 大模型微调方法总结
-
大规模语言模型高效参数微调:P-Tuning 微调系列
-
LoRA 和 QLoRA 微调语言大模型:数百次实验后的见解
-
不是大模型全局微调不起,只是 LoRA 更有性价比,教程已经准备好了
-
LoRA 家族概述



















