如何解决GPU万卡互联的挑战

近日,字节跳动携手北京大学研究团队发布重磅论文,揭示了一项革命性技术:将大型语言模型训练扩展至超10,000块GPU的生产系统。此系统不仅解决了万卡集群训练大模型时的效率和稳定性难题,更标志着人工智能领域的一大步跨越,为未来的智能世界奠定坚实基础。
本论文详尽阐述了系统的设计、实现与部署流程,并深入探讨了万卡级别集群规模的挑战与应对策略,为相关领域提供了宝贵参考。
01 万卡集群的两大挑战
大模型时代,算力即生产力,模型与数据的大小决定其能力。市场巨头们以数万GPU构建AI集群,以训练LLM。然而,当GPU集群规模达万卡,高效稳定的训练成为挑战。我们深知,在算力与模型的双重考验下,唯有掌握核心技术与创新方法,方能引领大模型时代,实现生产力的飞跃。
大规模高效训练是首要挑战。模型浮点运算利用率(MFU)作为评估训练效率的通用指标,直观反映训练速度。在训练大型语言模型(LLM)时,需将模型分布至多个GPU,并确保GPU间高效通信。然而,通信仅是冰山一角,操作符优化、数据预处理及GPU内存消耗等因素亦对MFU产生深远影响。优化这些因素,方能提升训练效率,迎接大规模高效训练的挑战。
第二个挑战在于确保大规模训练过程中的高稳定性与高效率。在大模型训练中,稳定性至关重要,因为失败和延迟虽然常见,但代价高昂。缩短故障恢复时间刻不容缓,因为一旦有掉队者,不仅影响个人进度,更可能导致数万GPU的整体作业受阻。我们需精心优化,确保训练稳定高效,以应对这一挑战。
面对挑战,字节跳动创新推出MegaScale超大规模系统,并已成功应用于自家数据中心。究竟字节如何攻克难题?揭秘其解决方案,展现技术实力,引领行业新风尚。
02 如何实现大模型的高效训练?
要在保证模型精准度的基础上应对计算需求的激增,需运用尖端算法优化、通信策略、数据流水线管理以及网络性能调优技术。本文深入剖析大型模型训练优化方法,助力实现大规模高效训练,确保性能与效率双赢。
算法优化
经过算法层面的精心优化,我们在确保准确性的基础上,显著提升了训练效率。此次优化涵盖了并行Transformer块、滑动窗口注意力(SWA)以及LAMB优化器等关键技术,为您带来更高效、更稳定的计算体验。
并行Transformer块革新计算模式,摒弃传统序列化公式,实现注意力块与MLP块的并行运算,大幅缩短计算时间。研究表明,此改进不仅未损害数千亿参数模型的质量,反而提升了处理效率。这项创新将引领深度学习领域迈向更高效、更快速的新纪元。
滑动窗口注意力(SWA)是一种高效稀疏注意力机制,通过固定大小窗口聚焦输入序列的每个标记,显著优于全自注意力。堆叠SWA层,模型轻松捕获广泛上下文,构建大感受野,既确保准确性又提升训练速度。SWA,让注意力更集中,训练更高效。
LAMB优化器突破了大规模高效训练中的批量大小限制难题。即便增加批量大小,它也能确保模型收敛不受影响。这一创新使得BERT的训练批量大小能够扩展至惊人的64K,同时维持了训练准确性,为深度学习领域带来了革命性的提升。
3D并行中的通信重叠
3D并行指张量并行、流水线并行和数据并行。
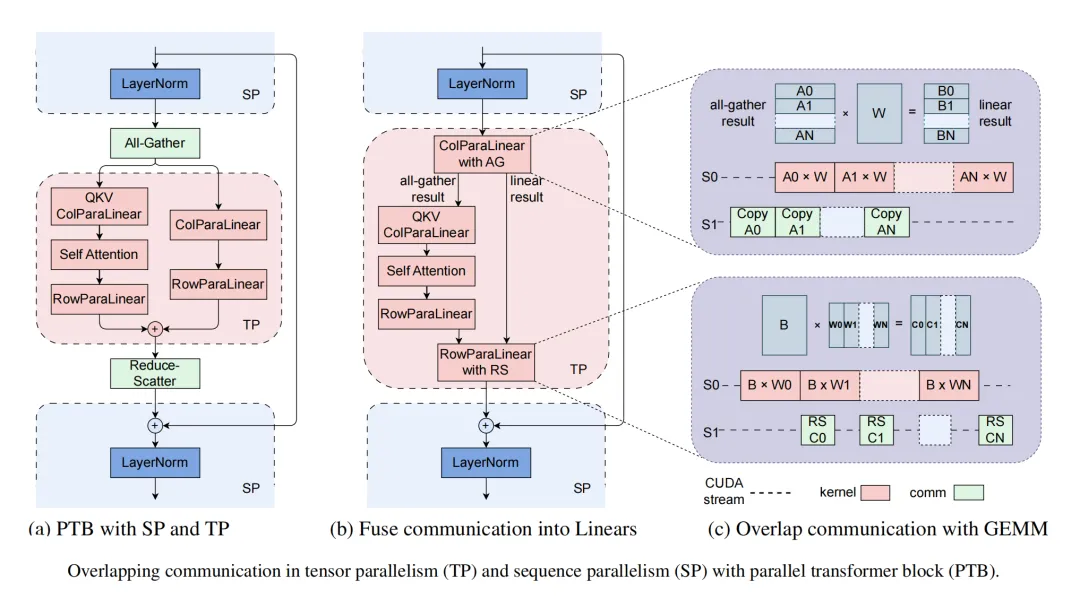
在数据并行中有两个主要通信操作:all-gather操作和reduce-scatter操作。在3D并行中,单个设备可能承载多个模型块。重叠是基于模型块实现的,以最大化带宽利用。all-gather操作在模型块的前向传递之前触发,reduce-scatter操作在它的后向传递之后开始。这导致第一个all-gather操作和最后一个reduce-scatter操作无法隐藏。受到PyTorch FSDP的启发,初始的all-gather操作在每次迭代的开始时被预取,允许它与数据加载操作重叠,有效地将减少了通信时间。
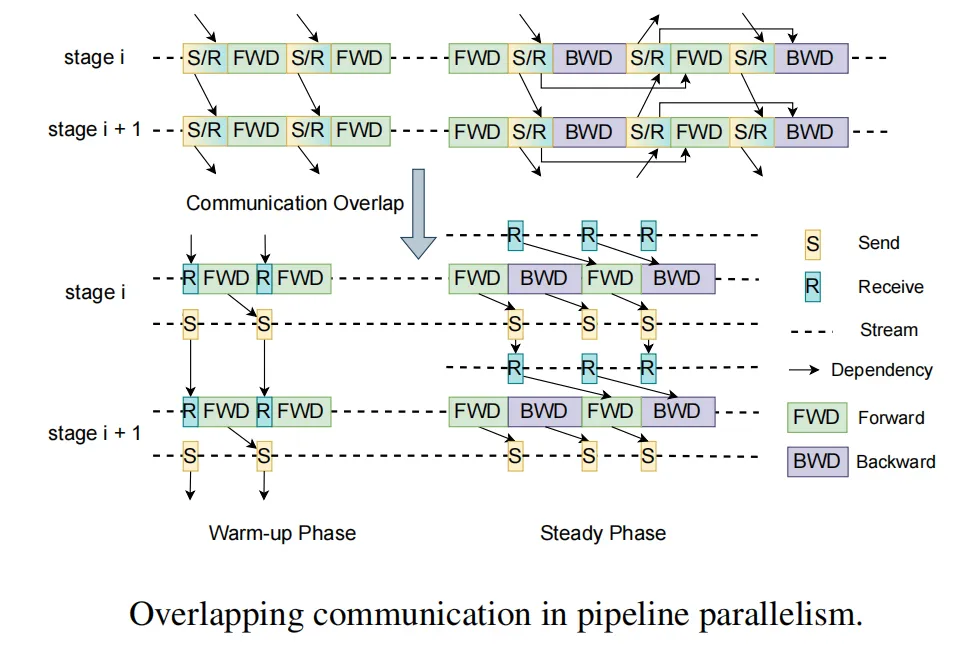
MegaScale在流水线并行中,运用独特的交错1F1B调度方法,有效重叠通信,提升效率。热身阶段,前向传递摆脱了对先前接收的依赖,实现发送与接收的解耦,使发送操作与计算并行进行。在张量/序列并行方面,我们采取融合通信与计算等创新策略,更将GEMM内核精细划分,与通信流程协同流水线执行,最大化提升并行性能。
高效操作符
MegatronLM虽然已优化GEMM操作符,但其他操作符仍有待增强。注意力部分采用FlashAttention-2,优化了线程块和warp间的工作分配。LayerNorm和GeLU由细粒度内核构成,通过融合这些内核,减少了启动多个内核的开销,优化了内存访问模式,从而显著提升性能。我们致力于深入挖掘各操作符的潜力,力求在MegatronLM中实现更出色的整体性能。
数据流水线优化
数据预处理与加载虽常被忽略,却在训练之初引发显著的GPU空闲。优化这些关键步骤,对于提升训练效率至关重要,不容忽视,是确保模型性能优化的关键环节。
异步数据预处理能够优化计算流程,使数据预处理与GPU工作器同步梯度互不干扰。在训练步骤间隙,预处理工作悄然进行,巧妙隐藏了开销,提升了整体训练效率。
消除冗余数据加载器。在分布式训练的典型数据加载阶段,每个GPU工作器都配备了自己的数据加载器,负责将训练数据读入CPU内存,然后转发到GPU。这导致工作线程之间为争夺磁盘读取带宽,因此产生了瓶颈。我们观察到,在LLM训练设置中,同一台机器内的GPU工作器处于相同的张量并行组。因此,它们每次迭代的输入本质上是相同的。基于这一观察,我们采用了两层树状的方法,在每台机器上使用一个专用的数据加载器将训练数据读入共享内存。随后,每个GPU工作器负责将必要的数据复制到自己的GPU内存中。这就消除了冗余读取,并显著提高了数据传输的效率。
集体通信群初始化
在分布式训练中,初始化阶段需构建GPU工作器间的NVIDIA集体通信库(NCCL)通信组。小规模场景下,此开销微不足道,故常选torch.distributed。然而,当GPU数量飙升破万,传统方法的开销骤增,变得不堪重负。因此,高效优化分布式训练初始化阶段,对于大规模GPU集群的性能提升至关重要。
torch.distributed初始化耗时过久,主要有两大原因。其一,同步步骤中的每个进程在完成特定通信组初始化后,均需执行屏障操作,而此操作基于TCPStore,采用单线程、阻塞的读写模式。为解决这一问题,我们可以采用非阻塞、异步的Redis来替代TCPStore。其二,全局屏障的不当使用也是导致耗时过长的因素之一。在初始化通信组后,每个进程均会执行全局屏障操作。为改善此情况,我们优化了通信组的初始化顺序,减少了全局屏障的使用频率,从而大幅降低了初始化时间复杂度。
未经优化的2048张GPU集群初始化需1047秒,经优化后骤减至5秒内;万卡GPU集群的初始化时间更是锐减至30秒以下,显著提升集群性能,加速计算效率。
网络性能调优
经过对3D并行中机器间流量的深入分析,我们精心设计了技术方案,旨在优化网络性能。方案涵盖网络拓扑优化、ECMP哈希冲突减少、高效拥塞控制及重传超时精准设置,全面提升网络效能。
我们的数据中心网络采用了Broadcom Tomahawk 4芯片构建的高性能交换机,每颗芯片总带宽高达25.6Tbps,拥有64×400Gbps端口。通过CLOS类似的三层交换机拓扑连接,轻松驾驭超过10000个GPU的庞大规模。每层交换机实现1:1的下行与上行链路带宽比,即32端口下行,32端口上行,确保数据流畅无阻。该网络设计精巧,直径小,带宽高,每个节点均可在极短的跳数内与其他节点畅通交流,为数据的高效传输提供有力保障。
我们专注于优化网络性能,通过精心设计网络拓扑与精准调度网络流量,显著减少ECMP哈希冲突。创新性地,在机架ToR交换机上将上行与下行链路分离,并将400G下行链路端口巧妙地通过特定AOC电缆划分为两个200G端口,这一举措有效降低了冲突率,提升了网络整体效率。
在分布式训练中,大规模应用默认的DCQCN协议时,all-to-all通信常引发拥塞,导致PFC级别攀升,过度使用更可能诱发头部阻塞(HoL),从而大幅削减网络吞吐量。为解决此问题,我们精心研发了一种融合Swift与DCQCN精髓的算法。该算法巧妙结合往返时间(RTT)的精准测量与显式拥塞通知(ECN)的迅速响应,不仅大幅提升了吞吐量,更是有效降低了与PFC相关的拥塞现象,为分布式训练中的网络通信保驾护航。
重传超时设置是NCCL中的关键参数,能够灵活控制重传定时器和重试次数。我们针对链路抖动,精细调整这些参数,确保快速恢复。同时,NIC上的adap_retrans功能进一步助力,支持更短间隔内的重传,尤其在抖动周期短时,能显著加速传输恢复,保障数据传输的高效稳定。
03 容错性
随着训练集群规模迅速扩大至数万GPU,软硬件故障频发成常态。我们针对LLM训练,精心打造了一个强健的训练框架,可自动识别故障并迅速恢复,实现高效容错,最大程度减少人为干预与对训练任务的影响,确保训练持续稳定进行。
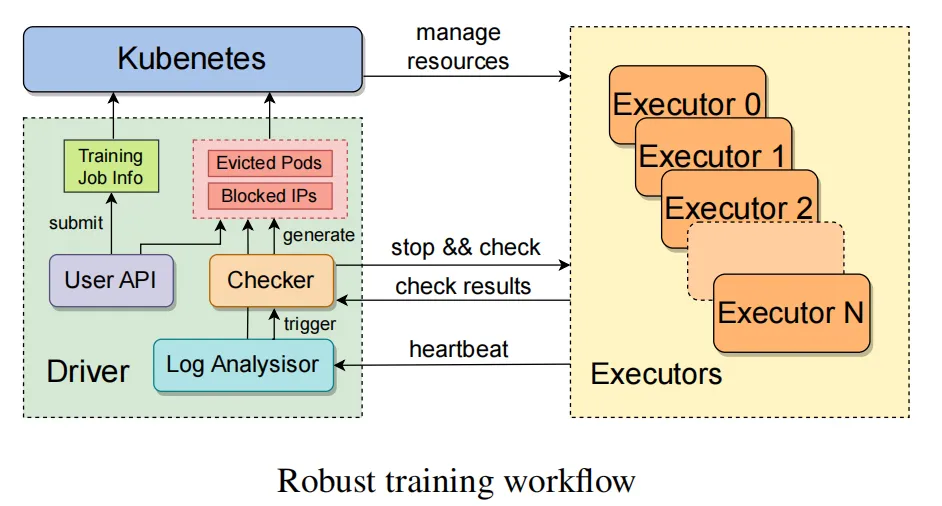
如图所示,一旦接收到训练任务,驱动程序进程便与自定义Kubernetes接口高效互动,精准分配计算资源,并为每个执行器迅速启动相应的Pod。执行器独立管理单个节点,初始化完成后,它会在每个GPU上迅速创建训练进程,并启动一个强大的训练守护进程。该进程定时向驱动程序发送heartbeat,确保实时异常检测与预警。一旦检测到异常或预定时间内未收到状态报告,故障恢复程序将立即启动,暂停所有训练任务,并指令它们进行自我检查诊断,确保系统稳定高效运行。
一旦识别出问题节点,驱动程序会迅速向Kubernetes提交相关IP地址及运行的Pod信息,Kubernetes随即驱逐故障节点,无缝切换至健康节点。同时,我们还提供直观的用户界面,便于手动清除问题节点。训练恢复时,驱动程序从最新checkpoint无缝衔接,我们对此过程进行了深度优化,以最大程度减少训练进度的损失,确保系统稳定高效运行。
为强化训练稳定性与性能监控,我们精心研发毫秒级精度监控系统,通过多级监控精准追踪各项指标。同时,分享checkpoint快速恢复、训练故障排查及MegaScale部署运营的实战经验。渴望深入探索的读者,可下载论文,一窥究竟。诚邀您共襄盛举,共创智能未来!
04 结论
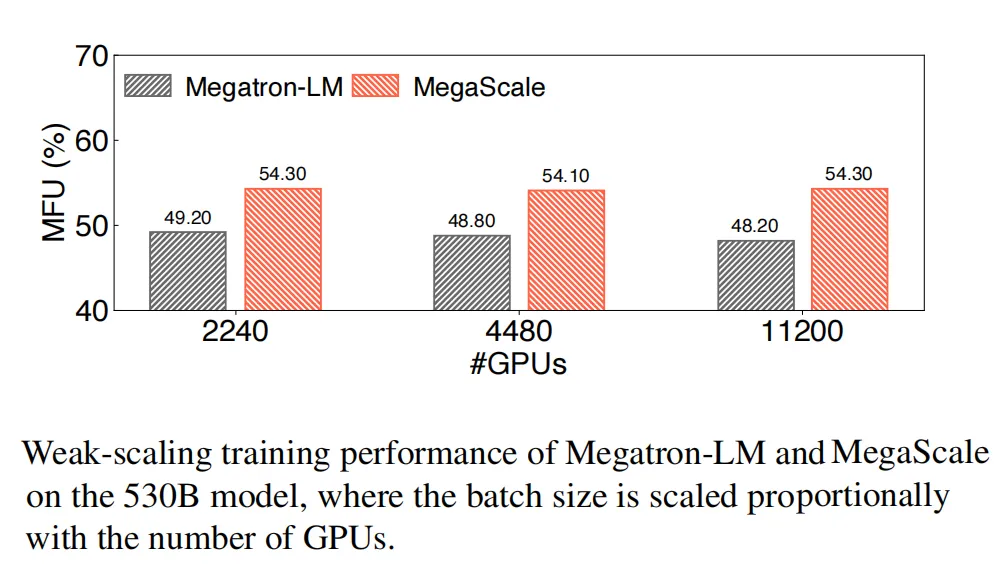
本文深度剖析MegaScale的设计、实现及部署流程。它采用算法与系统协同设计策略,显著提升训练效率。在12288个GPU上训练175B LLM模型时,MegaScale实现了高达55.2%的MFU,相比Megatron-LM,性能提升达1.34倍。MegaScale展现出的卓越性能,无疑将引领大规模模型训练的新篇章。
我们专注于打造具备容错能力的训练流程,特此推出定制的健壮训练框架,能够智能定位并修复故障。同时,我们提供了一套全面的监控工具,深入洞察系统组件与事件,助力精准识别复杂异常的根源。我们的工作旨在为LLM训练者提供宝贵见解,并为这一迅猛发展的领域探索未来研究之路,奠定坚实基础。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-








)

作为开发环境)
 和argMax()函数)


)

)


