在这之前,本书致力于搜索。 通过搜索,如果我们有一个查询并且希望找到匹配这个查询的文档集,就好比在大海捞针。
通过聚合,我们会得到一个数据的概览。我们需要的是分析和总结全套的数据而不是寻找单个文档:
- 在大海里有多少针?
- 针的平均长度是多少?
- 按照针的制造商来划分,针的长度中位值是多少?
- 每月加入到海中的针有多少?
聚合也可以回答更加细微的问题:
- 你最受欢迎的针的制造商是什么?
- 这里面有异常的针么?
聚合允许我们向数据提出一些复杂的问题。虽然功能完全不同于搜索,但它使用相同的数据结构。这意味着聚合的执行速度很快并且就像搜索一样几乎是实时的。
这对报告和仪表盘是非常强大的。你可以实时显示你的数据,让你立即回应,而不是对你的数据进行汇总( 需要一周时间去运行的 Hadoop 任务 ),您的报告随着你的数据变化而变化,而不是预先计算的、过时的和不相关的。
最后,聚合和搜索是一起的。 这意味着你可以在单个请求里同时对相同的数据进行搜索/过滤和分析。并且由于聚合是在用户搜索的上下文里计算的,你不只是显示四星酒店的数量,而是显示匹配查询条件的四星酒店的数量。
聚合是如此强大以至于许多公司已经专门为数据分析建立了大型 Elasticsearch 集群。
高阶概念
类似于 DSL 查询表达式,聚合也有 可组合 的语法:独立单元的功能可以被混合起来提供你需要的自定义行为。这意味着只需要学习很少的基本概念,就可以得到几乎无尽的组合。
要掌握聚合,你只需要明白两个主要的概念:
桶(Buckets)
满足特定条件的文档的集合
指标(Metrics)
对桶内的文档进行统计计算
这就是全部了!每个聚合都是一个或者多个桶和零个或者多个指标的组合。翻译成粗略的SQL语句来解释吧:
SELECT COUNT(color)
FROM table
GROUP BY color
- COUNT(color) 相当于指标。
- GROUP BY color 相当于桶。
桶在概念上类似于 SQL 的分组(GROUP BY),而指标则类似于 COUNT() 、 SUM() 、 MAX() 等统计方法。
让我们深入这两个概念 并且了解和这两个概念相关的东西。
桶
桶 简单来说就是满足特定条件的文档的集合:
- 一个雇员属于 男性 桶或者 女性 桶
- 奥尔巴尼属于 纽约 桶
- 日期2014-10-28属于 十月 桶
当聚合开始被执行,每个文档里面的值通过计算来决定符合哪个桶的条件。如果匹配到,文档将放入相应的桶并接着进行聚合操作。
桶也可以被嵌套在其他桶里面,提供层次化的或者有条件的划分方案。例如,辛辛那提会被放入俄亥俄州这个桶,而 整个 俄亥俄州桶会被放入美国这个桶。
Elasticsearch 有很多种类型的桶,能让你通过很多种方式来划分文档(时间、最受欢迎的词、年龄区间、地理位置等等)。其实根本上都是通过同样的原理进行操作:基于条件来划分文档。
指标
桶能让我们划分文档到有意义的集合,但是最终我们需要的是对这些桶内的文档进行一些指标的计算。分桶是一种达到目的的手段:它提供了一种给文档分组的方法来让我们可以计算感兴趣的指标。
大多数 指标 是简单的数学运算(例如最小值、平均值、最大值,还有汇总),这些是通过文档的值来计算。在实践中,指标能让你计算像平均薪资、最高出售价格、95%的查询延迟这样的数据。
桶和指标的组合
聚合 是由桶和指标组成的。 聚合可能只有一个桶,可能只有一个指标,或者可能两个都有。也有可能有一些桶嵌套在其他桶里面。例如,我们可以通过所属国家来划分文档(桶),然后计算每个国家的平均薪酬(指标)。
由于桶可以被嵌套,我们可以实现非常多并且非常复杂的聚合:
- 通过国家划分文档(桶)
- 然后通过性别划分每个国家(桶)
- 然后通过年龄区间划分每种性别(桶)
- 最后,为每个年龄区间计算平均薪酬(指标)
最后将告诉你每个 <国家, 性别, 年龄> 组合的平均薪酬。所有的这些都在一个请求内完成并且只遍历一次数据!
尝试聚合
我们可以用以下几页定义不同的聚合和它们的语法, 但学习聚合的最佳途径就是用实例来说明。 一旦我们获得了聚合的思想,以及如何合理地嵌套使用它们,那么语法就变得不那么重要了。
聚合的桶操作和度量的完整用法可以在 Elasticsearch 参考 中找到。本章中会涵盖其中很多内容,但在阅读完本章后查看它会有助于我们对它的整体能力有所了解。
所以让我们先看一个例子。我们将会创建一些对汽车经销商有用的聚合,数据是关于汽车交易的信息:车型、制造商、售价、何时被出售等。
首先我们批量索引一些数据:
POST /cars/_bulk
{ "index": {}}
{ "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" }
{ "index": {}}
{ "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" }
{ "index": {}}
{ "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" }
{ "index": {}}
{ "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2014-02-12" }
有了数据,开始构建我们的第一个聚合。汽车经销商可能会想知道哪个颜色的汽车销量最好,用聚合可以轻易得到结果,用 terms 桶操作:
GET /cars/_search
{"size": 0,"aggs": {"popular_colors": {"terms": {"field": "color.keyword"}}}
}
- “size”: 0: 这个参数指示Elasticsearch不返回搜索结果文档,因为我们只对文档进行聚合统计而不需要实际文档内容。因此,将搜索结果的大小设置为0。
- 聚合操作被置于顶层参数 aggs 之下(如果你愿意,完整形式 aggregations 同样有效)。
- 然后,可以为聚合指定一个我们想要名称,本例中是: popular_colors 。
- 最后,定义单个桶的类型 terms 。
- “field”: “color.keyword”: 这里指定了聚合应该基于哪个字段进行。 “.keyword” 是指定的字段类型,它告诉Elasticsearch使用未分词的精确值进行聚合。通常,当您想要对关键字类型的字段执行聚合时,应该使用 “.keyword”。
- 在这个查询中使用了 “terms” 聚合类型,是因为我们想要对指定字段的值进行分桶,以便统计每个唯一值的数量。对于汽车颜色这样的情况,我们希望知道每种颜色出现的次数,而 “terms” 聚合正是用来实现这个目的的。
而不同于其他聚合类型,如 “avg”、“sum”、“min”、“max” 等,它们是用来对数值型数据进行聚合操作的。而 “terms” 聚合则专门用于处理文本类型的字段,将文本字段的值进行分组,统计每个不同值的出现次数。在实际应用中,常常用于分析文本数据的分布情况,比如用户的地理位置、产品的类别、标签等。
聚合是在特定搜索结果背景下执行的, 这也就是说它只是查询请求的另外一个顶层参数(例如,使用 /_search 端点)。 聚合可以与查询结对,但我们会晚些在 限定聚合的范围(Scoping Aggregations) 中来解决这个问题。
然后我们为聚合定义一个名字,名字的选择取决于使用者,响应的结果会以我们定义的名字为标签,这样应用就可以解析得到的结果。
随后我们定义聚合本身,在本例中,我们定义了一个单 terms 桶。 这个 terms 桶会为每个碰到的唯一词项动态创建新的桶。 因为我们告诉它使用 color 字段,所以 terms 桶会为每个颜色动态创建新桶。
让我们运行聚合并查看结果:
{"took": 2,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 8,"relation": "eq"},"max_score": null,"hits": []},"aggregations": {"popular_colors": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": "red","doc_count": 4},{"key": "blue","doc_count": 2},{"key": "green","doc_count": 2}]}}
}
- 因为我们设置了 size 参数,所以不会有 hits 搜索结果返回。
- popular_colors 聚合是作为 aggregations 字段的一部分被返回的。
- 每个桶的 key 都与 color 字段里找到的唯一词对应。它总会包含 doc_count 字段,告诉我们包含该词项的文档数量。
- 每个桶的数量代表该颜色的文档数量。
响应包含多个桶,每个对应一个唯一颜色(例如:红 或 绿)。每个桶也包括 聚合进 该桶的所有文档的数量。例如,有四辆红色的车。
前面的这个例子完全是实时执行的:一旦文档可以被搜到,它就能被聚合。这也就意味着我们可以直接将聚合的结果源源不断的传入图形库,然后生成实时的仪表盘。 不久,你又销售了一辆银色的车,我们的图形就会立即动态更新银色车的统计信息。
瞧!这就是我们的第一个聚合!
添加度量指标
前面的例子告诉我们每个桶里面的文档数量,这很有用。但通常,我们的应用需要提供更复杂的文档度量。 例如,每种颜色汽车的平均价格是多少?
为了获取更多信息,我们需要告诉 Elasticsearch 使用哪个字段,计算何种度量。 这需要将度量 嵌套 在桶内, 度量会基于桶内的文档计算统计结果。
让我们继续为汽车的例子加入 average 平均度量:
GET /cars/_search
{"size": 0,"aggs": {"colors": {"terms": {"field": "color.keyword"},"aggs": {"avg_price": {"avg": {"field": "price"}}}}}
}
- 为度量新增 aggs 层。
- 为度量指定名字: avg_price 。
- 最后,为 price 字段定义 avg 度量。
正如所见,我们用前面的例子加入了新的 aggs 层。这个新的聚合层让我们可以将 avg 度量嵌套置于 terms 桶内。实际上,这就为每个颜色生成了平均价格。
正如 颜色 的例子,我们需要给度量起一个名字( avg_price )这样可以稍后根据名字获取它的值。最后,我们指定度量本身( avg )以及我们想要计算平均值的字段( price ):
{"took": 1,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 8,"relation": "eq"},"max_score": null,"hits": []},"aggregations": {"colors": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": "red","doc_count": 4,"avg_price": {"value": 32500}},{"key": "blue","doc_count": 2,"avg_price": {"value": 20000}},{"key": "green","doc_count": 2,"avg_price": {"value": 21000}}]}}
}
- 响应中的新字段 avg_price 。
尽管响应只发生很小改变,实际上我们获得的数据是增长了。之前,我们知道有四辆红色的车,现在,红色车的平均价格是 $32,500 美元。这个信息可以直接显示在报表或者图形中。
嵌套桶
在我们使用不同的嵌套方案时,聚合的力量才能真正得以显现。 在前例中,我们已经看到如何将一个度量嵌入桶中,它的功能已经十分强大了。
但真正令人激动的分析来自于将桶嵌套进 另外一个桶 所能得到的结果。 现在,我们想知道每个颜色的汽车制造商的分布:
GET /cars/_search
{"size": 0,"aggs": {"colors": {"terms": {"field": "color.keyword"},"aggs": {"avg_price": {"avg": {"field": "price"}},"make": {"terms": {"field": "make.keyword"}}}}}
}
- 注意前例中的 avg_price 度量仍然保持原位。
- 另一个聚合 make 被加入到了 color 颜色桶中。
- 这个聚合是 terms 桶,它会为每个汽车制造商生成唯一的桶。
这里发生了一些有趣的事。 首先,我们可能会观察到之前例子中的 avg_price 度量完全没有变化,还在原来的位置。 一个聚合的每个 层级 都可以有多个度量或桶, avg_price 度量告诉我们每种颜色汽车的平均价格。它与其他的桶和度量相互独立。
这对我们的应用非常重要,因为这里面有很多相互关联,但又完全不同的度量需要收集。聚合使我们能够用一次数据请求获得所有的这些信息。
另外一件值得注意的重要事情是我们新增的这个 make 聚合,它是一个 terms 桶(嵌套在 colors 、 terms 桶内)。这意味着它会为数据集中的每个唯一组合生成( color 、 make )元组。
让我们看看返回的响应(为了简单我们只显示部分结果):
"aggregations": {"colors": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": "red","doc_count": 4,"avg_price": {"value": 32500},"make": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": "honda","doc_count": 3},{"key": "bmw","doc_count": 1}]}},
- 正如期望的那样,新的聚合嵌入在每个颜色桶中。
- 现在我们看见按不同制造商分解的每种颜色下车辆信息。
- 最终,我们看到前例中的 avg_price 度量仍然维持不变。
响应结果告诉我们以下几点:
- 红色车有四辆。
- 红色车的平均售价是 $32,500 美元。
- 其中三辆是 Honda 本田制造,一辆是 BMW 宝马制造。
最后的修改
让我们回到话题的原点,在进入新话题之前,对我们的示例做最后一个修改, 为每个汽车生成商计算最低和最高的价格:
GET /cars/_search
{"size" : 0,"aggs": {"colors": {"terms": {"field": "color.keyword"},"aggs": {"avg_price": { "avg": { "field": "price" }},"make" : {"terms" : {"field" : "make.keyword"},"aggs" : { "min_price" : { "min": { "field": "price"} }, "max_price" : { "max": { "field": "price"} } }}}}}
}
- 我们需要增加另外一个嵌套的 aggs 层级。
- 然后包括 min 最小度量。
- 以及 max 最大度量。
得到以下输出(只显示部分结果):
"aggregations": {"colors": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": "red","doc_count": 4,"avg_price": {"value": 32500},"make": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": "honda","doc_count": 3,"max_price": {"value": 20000},"min_price": {"value": 10000}},{"key": "bmw","doc_count": 1,"max_price": {"value": 80000},"min_price": {"value": 80000}}]}},
- min 和 max 度量现在出现在每个汽车制造商( make )下面。
有了这两个桶,我们可以对查询的结果进行扩展并得到以下信息:
- 有四辆红色车。
- 红色车的平均售价是 $32500 美元。
- 其中三辆红色车是 Honda 本田制造,一辆是 BMW 宝马制造。
- 最便宜的红色本田售价为 $10,000 美元。
- 最贵的红色本田售价为 $20,000 美元。
条形图
聚合还有一个令人激动的特性就是能够十分容易地将它们转换成图表和图形。本章中, 我们正在通过示例数据来完成各种各样的聚合分析,最终,我们将会发现聚合功能是非常强大的。
直方图 histogram 特别有用。 它本质上是一个条形图,如果有创建报表或分析仪表盘的经验,那么我们会毫无疑问的发现里面有一些图表是条形图。 创建直方图需要指定一个区间,如果我们要为售价创建一个直方图,可以将间隔设为 20,000。这样做将会在每个 $20,000 档创建一个新桶,然后文档会被分到对应的桶中。
对于仪表盘来说,我们希望知道每个售价区间内汽车的销量。我们还会想知道每个售价区间内汽车所带来的收入,可以通过对每个区间内已售汽车的售价求和得到。
可以用 histogram 和一个嵌套的 sum 度量得到我们想要的答案:
GET /cars/_search
{"size": 0,"aggs": {"price": {"histogram": {"field": "price","interval": 20000},"aggs": {"revenue": {"sum": {"field": "price"}}}}}
}
- histogram 桶要求两个参数:一个数值字段以及一个定义桶大小间隔。
- sum 度量嵌套在每个售价区间内,用来显示每个区间内的总收入。
如我们所见,查询是围绕 price 聚合构建的,它包含一个 histogram 桶。它要求字段的类型必须是数值型的同时需要设定分组的间隔范围。 间隔设置为 20,000 意味着我们将会得到如 [0-19999, 20000-39999, …] 这样的区间。
接着,我们在直方图内定义嵌套的度量,这个 sum 度量,它会对落入某一具体售价区间的文档中 price 字段的值进行求和。 这可以为我们提供每个售价区间的收入,从而可以发现到底是普通家用车赚钱还是奢侈车赚钱。
响应结果如下:
"aggregations": {"price": {"buckets": [{"key": 0,"doc_count": 3,"revenue": {"value": 37000}},{"key": 20000,"doc_count": 4,"revenue": {"value": 95000}},
- 结果很容易理解,不过应该注意到直方图的键值是区间的下限。键 0 代表区间 0-19,999 ,键 20000 代表区间 20,000-39,999 ,等等。
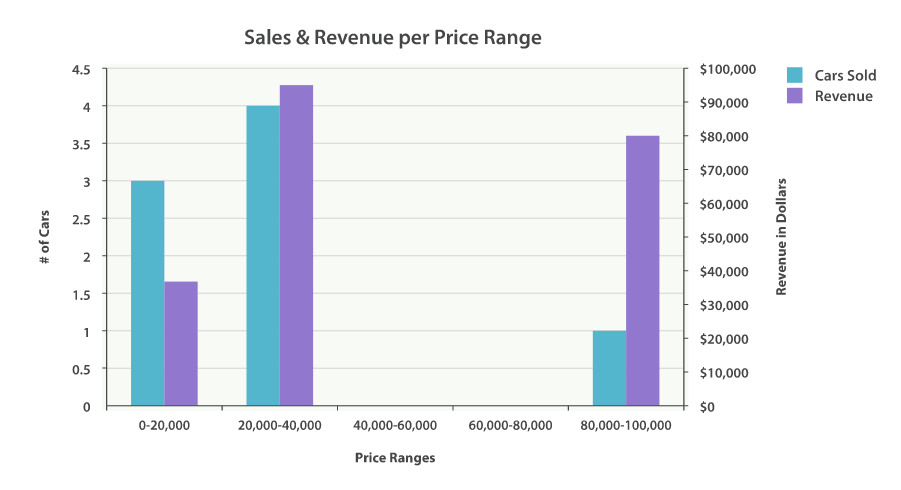
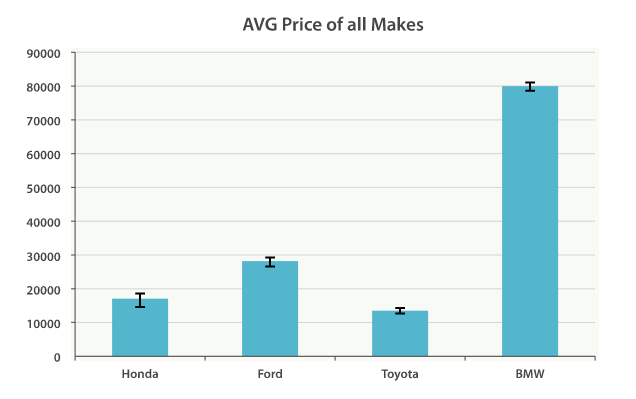
当然,我们可以为任何聚合输出的分类和统计结果创建条形图,而不只是 直方图 桶。让我们以最受欢迎 10 种汽车以及它们的平均售价、标准差这些信息创建一个条形图。 我们会用到 terms 桶和 extended_stats 度量:
GET /cars/_search
{"size": 0,"aggs": {"makes": {"terms": {"field": "make.keyword","size": 10},"aggs": {"stats": {"extended_stats": {"field": "price"}}}}}
}
"aggregations": {"makes": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": "honda","doc_count": 3,"stats": {"count": 3,"min": 10000,"max": 20000,"avg": 16666.666666666668,"sum": 50000,"sum_of_squares": 900000000,"variance": 22222222.22222221,"variance_population": 22222222.22222221,"variance_sampling": 33333333.333333313,"std_deviation": 4714.045207910315,"std_deviation_population": 4714.045207910315,"std_deviation_sampling": 5773.502691896256,"std_deviation_bounds": {"upper": 26094.757082487296,"lower": 7238.5762508460375,"upper_population": 26094.757082487296,"lower_population": 7238.5762508460375,"upper_sampling": 28213.67205045918,"lower_sampling": 5119.661282874156}}},
上述代码会按受欢迎度返回制造商列表以及它们各自的统计信息。我们对其中的 stats.avg 、 stats.count 和 stats.std_deviation 信息特别感兴趣,并用 它们计算出标准差:
std_err = std_deviation / count
创建图表如图 Figure 36, “Average price of all makes, with error bars” 。
按时间统计
如果搜索是在 Elasticsearch 中使用频率最高的,那么构建按时间统计的 date_histogram 紧随其后。 为什么你会想用 date_histogram 呢?
假设你的数据带时间戳。 无论是什么数据(Apache 事件日志、股票买卖交易时间、棒球运动时间)只要带有时间戳都可以进行 date_histogram 分析。当你的数据有时间戳,你总是想在 时间 维度上构建指标分析:
- 今年每月销售多少台汽车?
- 这只股票最近 12 小时的价格是多少?
- 我们网站上周每小时的平均响应延迟时间是多少?
虽然通常的 histogram 都是条形图,但 date_histogram 倾向于转换成线状图以展示时间序列。 许多公司用 Elasticsearch 仅仅 只是为了分析时间序列数据。 date_histogram 分析是它们最基本的需要。
date_histogram 与 通常的 histogram 类似。 但不是在代表数值范围的数值字段上构建 buckets,而是在时间范围上构建 buckets。 因此每一个 bucket 都被定义成一个特定的日期大小 (比如, 1个月 或 2.5 天 )。
可以用通常的 histogram 进行时间分析吗?
从技术上来讲,是可以的。 通常的 histogram bucket(桶)是可以处理日期的。 但是它不能自动识别日期。 而用 date_histogram ,你可以指定时间段如 1 个月 ,它能聪明地知道 2 月的天数比 12 月少。 date_histogram 还具有另外一个优势,即能合理地处理时区,这可以使你用客户端的时区进行图标定制,而不是用服务器端时区。
通常的 histogram 会把日期看做是数字,这意味着你必须以微秒为单位指明时间间隔。另外聚合并不知道日历时间间隔,使得它对于日期而言几乎没什么用处。
我们的第一个例子将构建一个简单的折线图来回答如下问题: 每月销售多少台汽车?
GET /cars/_search
{"size": 0,"aggs": {"sales": {"date_histogram": {"field": "sold","calendar_interval": "month","format": "yyyy-MM-dd"}}}
}
- 时间间隔要求是日历术语 (如每个 bucket 1 个月)。
- 我们提供日期格式以便 buckets 的键值便于阅读。
我们的查询只有一个聚合,每月构建一个 bucket。这样我们可以得到每个月销售的汽车数量。 另外还提供了一个额外的 format 参数以便 buckets 有 “好看的” 键值。 然而在内部,日期仍然是被简单表示成数值。这可能会使得 UI 设计者抱怨,因此可以提供常用的日期格式进行格式化以更方便阅读。
结果既符合预期又有一点出人意料(看看你是否能找到意外之处):
"aggregations": {"sales": {"buckets": [{"key_as_string": "2014-01-01","key": 1388534400000,"doc_count": 1},{"key_as_string": "2014-02-01","key": 1391212800000,"doc_count": 1},{"key_as_string": "2014-03-01","key": 1393632000000,"doc_count": 0},{"key_as_string": "2014-04-01","key": 1396310400000,"doc_count": 0},{"key_as_string": "2014-05-01","key": 1398902400000,"doc_count": 1},{"key_as_string": "2014-06-01","key": 1401580800000,"doc_count": 0},{"key_as_string": "2014-07-01","key": 1404172800000,"doc_count": 1},{"key_as_string": "2014-08-01","key": 1406851200000,"doc_count": 1},{"key_as_string": "2014-09-01","key": 1409529600000,"doc_count": 0},{"key_as_string": "2014-10-01","key": 1412121600000,"doc_count": 1},{"key_as_string": "2014-11-01","key": 1414800000000,"doc_count": 2}]}}
聚合结果已经完全展示了。正如你所见,我们有代表月份的 buckets,每个月的文档数目,以及美化后的 key_as_string 。
返回空 Buckets
注意到结果末尾处的奇怪之处了吗?
是的,结果没错。 我们的结果少了一些月份! date_histogram (和 histogram 一样)默认只会返回文档数目非零的 buckets。
这意味着你的 histogram 总是返回最少结果。通常,你并不想要这样。对于很多应用,你可能想直接把结果导入到图形库中,而不想做任何后期加工。
事实上,即使 buckets 中没有文档我们也想返回。可以通过设置两个额外参数来实现这种效果:
GET /cars/_search
{"size": 0,"aggs": {"sales": {"date_histogram": {"field": "sold","calendar_interval": "month","format": "yyyy-MM-dd","min_doc_count": 1,"extended_bounds": {"min": "2014-01-01","max": "2014-12-31"}}}}
}
- min_doc_count 这个参数如果为0,强制返回空 buckets。如果为1,doc_count小于1的桶就被过滤掉了。
- extended_bounds 这个参数强制返回整年。
"aggregations": {"sales": {"buckets": [{"key_as_string": "2014-01-01","key": 1388534400000,"doc_count": 1},{"key_as_string": "2014-02-01","key": 1391212800000,"doc_count": 1},{"key_as_string": "2014-05-01","key": 1398902400000,"doc_count": 1},{"key_as_string": "2014-07-01","key": 1404172800000,"doc_count": 1},{"key_as_string": "2014-08-01","key": 1406851200000,"doc_count": 1},{"key_as_string": "2014-10-01","key": 1412121600000,"doc_count": 1},{"key_as_string": "2014-11-01","key": 1414800000000,"doc_count": 2}]}}
“min_doc_count”: 0,
“extended_bounds”: {
“min”: “2014-01-01”,
“max”: “2014-12-31”
}
这两个参数会强制返回一年中所有月份的结果,而不考虑结果中的文档数目。 min_doc_count 非常容易理解:它强制返回所有 buckets,即使 buckets 可能为空。
extended_bounds 参数需要一点解释。 min_doc_count 参数强制返回空 buckets,但是 Elasticsearch 默认只返回你的数据中最小值和最大值之间的 buckets。
因此如果你的数据只落在了 4 月和 7 月之间,那么你只能得到这些月份的 buckets(可能为空也可能不为空)。因此为了得到全年数据,我们需要告诉 Elasticsearch 我们想要全部 buckets, 即便那些 buckets 可能落在最小日期 之前 或 最大日期 之后 。没有数据的那些月份也会新增一个doc_count=0的桶。
extended_bounds 参数正是如此。一旦你加上了这两个设置,你可以把得到的结果轻易地直接插入到你的图形库中,从而得到类似 Figure 37, “汽车销售时间图” 的图表。
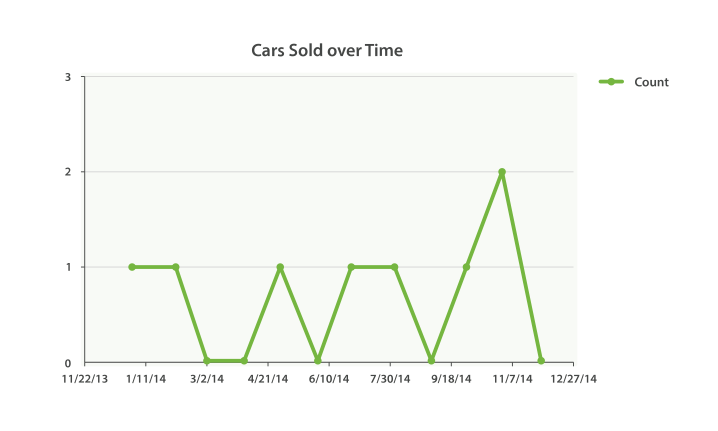
扩展例子
正如我们已经见过很多次,buckets 可以嵌套进 buckets 中从而得到更复杂的分析。 作为例子,我们构建聚合以便按季度展示所有汽车品牌总销售额。同时按季度、按每个汽车品牌计算销售总额,以便可以找出哪种品牌最赚钱:
GET /cars/_search
{"size" : 0,"aggs": {"sales": {"date_histogram": {"field": "sold","calendar_interval": "quarter", "format": "yyyy-MM-dd","min_doc_count" : 0,"extended_bounds" : {"min" : "2014-01-01","max" : "2014-12-31"}},"aggs": {"per_make_sum": {"terms": {"field": "make.keyword"},"aggs": {"sum_price": {"sum": { "field": "price" } }}},"total_sum": {"sum": { "field": "price" } }}}}
}
- 注意我们把时间间隔从 month 改成了 quarter 。
- 计算每种品牌的总销售金额。
- 也计算所有全部品牌的汇总销售金额。
得到的结果(截去了一大部分)如下:
"aggregations": {"sales": {"buckets": [{"key_as_string": "2014-01-01","key": 1388534400000,"doc_count": 2,"per_make_sum": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": "bmw","doc_count": 1,"sum_price": {"value": 80000}},{"key": "ford","doc_count": 1,"sum_price": {"value": 25000}}]},"total_sum": {"value": 105000}},
我们把结果绘成图,得到如 Figure 38, “按品牌分布的每季度销售额” 所示的总销售额的折线图和每个品牌(每季度)的柱状图。
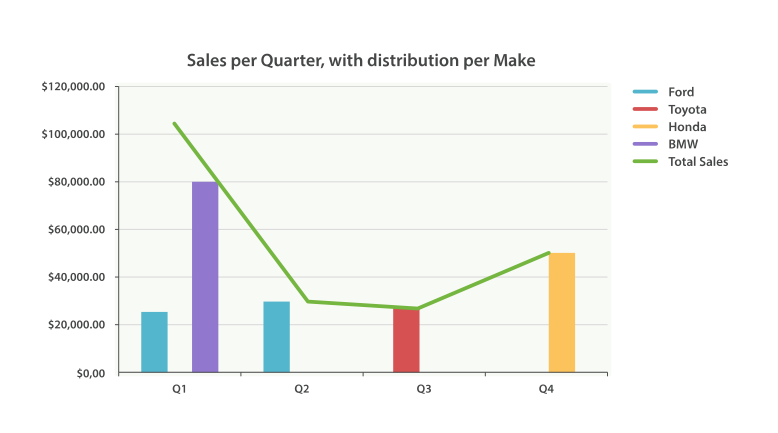
潜力无穷
这些很明显都是简单例子,但图表聚合其实是潜力无穷的。 如 Figure 39, “Kibana—用聚合构建的实时分析面板” 展示了 Kibana 中用各种聚合构建的面板。

因为聚合的实时性,类似这样的面板很容易查询、操作和交互。这使得它们成为需要分析数据又不会构建 Hadoop 作业的非技术人员的理想工具。
当然,为了构建类似 Kibana 这样的强大面板,你可能需要更深的知识,比如基于范围、过滤以及排序的聚合。
范围限定的聚合
所有聚合的例子到目前为止,你可能已经注意到,我们的搜索请求省略了一个 query 。 整个请求只不过是一个聚合。
聚合可以与搜索请求同时执行,但是我们需要理解一个新概念: 范围 。 默认情况下,聚合与查询是对同一范围进行操作的,也就是说,聚合是基于我们查询匹配的文档集合进行计算的。
让我们看看第一个聚合的示例:
GET /cars/_search
{"size" : 0,"aggs" : {"colors" : {"terms" : {"field" : "color.keyword"}}}
}
我们可以看到聚合是隔离的。现实中,Elasticsearch 认为 “没有指定查询” 和 “查询所有文档” 是等价的。前面这个查询内部会转化成下面的这个请求:
GET /cars/_search
{"size": 0,"query": {"match_all": {}},"aggs": {"colors": {"terms": {"field": "color.keyword"}}}
}
因为聚合总是对查询范围内的结果进行操作的,所以一个隔离的聚合实际上是在对 match_all 的结果范围操作,即所有的文档。
一旦有了范围的概念,我们就能更进一步对聚合进行自定义。我们前面所有的示例都是对 所有 数据计算统计信息的:销量最高的汽车,所有汽车的平均售价,最佳销售月份等等。
利用范围,我们可以问“福特在售车有多少种颜色?”诸如此类的问题。可以简单的在请求中加上一个查询(本例中为 match 查询):
GET /cars/_search
{"query": {"match": {"make": "ford"}},"aggs": {"colors": {"terms": {"field": "color.keyword"}}}
}
因为我们没有指定 “size” : 0 ,所以搜索结果和聚合结果都被返回了:
{"took": 0,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 2,"relation": "eq"},"max_score": 1.2809337,"hits": [{"_index": "cars","_id": "WVEUw44BZKfEnzIxjV7V","_score": 1.2809337,"_source": {"price": 30000,"color": "green","make": "ford","sold": "2014-05-18"}},{"_index": "cars","_id": "XlEUw44BZKfEnzIxjV7V","_score": 1.2809337,"_source": {"price": 25000,"color": "blue","make": "ford","sold": "2014-02-12"}}]},"aggregations": {"colors": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": "blue","doc_count": 1},{"key": "green","doc_count": 1}]}}
}
全局桶
通常我们希望聚合是在查询范围内的,但有时我们也想要搜索它的子集,而聚合的对象却是 所有 数据。
例如,比方说我们想知道福特汽车与 所有 汽车平均售价的比较。我们可以用普通的聚合(查询范围内的)得到第一个信息,然后用 全局 桶获得第二个信息。
全局 桶包含 所有 的文档,它无视查询的范围。因为它还是一个桶,我们可以像平常一样将聚合嵌套在内:
GET /cars/_search
{"size": 0,"query": {"match": {"make": "ford"}},"aggs": {"single_avg_price": {"avg": {"field": "price"}},"all": {"global": {},"aggs": {"avg_price": {"avg": {"field": "price"}}}}}
}
- aggs 1 聚合操作在查询范围内(例如:所有文档匹配 ford )
- “global”: {} 全局桶没有参数。
- aggs 2 聚合操作针对所有文档,忽略汽车品牌。
{"took": 2,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 2,"relation": "eq"},"max_score": null,"hits": []},"aggregations": {"all": {"doc_count": 8,"avg_price": {"value": 26500}},"single_avg_price": {"value": 27500}}
}
single_avg_price 度量计算是基于查询范围内所有文档,即所有 福特 汽车。avg_price 度量是嵌套在 全局 桶下的,这意味着它完全忽略了范围并对所有文档进行计算。聚合返回的平均值是所有汽车的平均售价。
如果能一直坚持读到这里,应该知道我们有个真言:尽可能的使用过滤器。它同样可以应用于聚合,在下一章中,我们会展示如何对聚合结果进行过滤而不是仅对查询范围做限定。
过滤和聚合
聚合范围限定还有一个自然的扩展就是过滤。因为聚合是在查询结果范围内操作的,任何可以适用于查询的过滤器也可以应用在聚合上。
过滤
如果我们想找到售价在 $10,000 美元之上的所有汽车同时也为这些车计算平均售价, 可以简单地使用一个 constant_score 查询和 filter 约束:
GET cars/_search
{"size": 0,"query": {"constant_score": {"filter": {"range": {"price": {"gte": 10000}}}}},"aggs": {"single_avg_price": {"avg": {"field": "price"}}}
}
{"took": 0,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 8,"relation": "eq"},"max_score": null,"hits": []},"aggregations": {"single_avg_price": {"value": 26500}}
}
这正如我们在前面章节中讨论过那样,从根本上讲,使用 non-scoring 查询和使用 match 查询没有任何区别。查询(包括了一个过滤器)返回一组文档的子集,聚合正是操作这些文档。使用 filtering query 会忽略评分,并有可能会缓存结果数据等等。
过滤桶
但是如果我们只想对聚合结果过滤怎么办? 假设我们正在为汽车经销商创建一个搜索页面, 我们希望显示用户搜索的结果,但是我们同时也想在页面上提供更丰富的信息,包括(与搜索匹配的)上个月度汽车的平均售价。
这里我们无法简单的做范围限定,因为有两个不同的条件。搜索结果必须是 ford ,但是聚合结果必须满足 ford AND sold > now - 1M 。
为了解决这个问题,我们可以用一种特殊的桶,叫做 filter (注:过滤桶) 。 我们可以指定一个过滤桶,当文档满足过滤桶的条件时,我们将其加入到桶内。
查询结果如下:
GET /cars/_search
{"size" : 0,"query":{"match": {"make": "ford"}},"aggs":{"recent_sales": {"filter": { "range": {"sold": {"from": "now-1M"}}},"aggs": {"average_price":{"avg": {"field": "price" }}}}}
}
- 使用 过滤 桶在 查询 范围基础上应用过滤器。
- avg 度量只会对 ford 和上个月售出的文档计算平均售价。
"aggregations": {"recent_sales": {"doc_count": 1,"average_price": {"value": 30000}}}
因为 filter 桶和其他桶的操作方式一样,所以可以随意将其他桶和度量嵌入其中。所有嵌套的组件都会 “继承” 这个过滤,这使我们可以按需针对聚合过滤出选择部分。
后过滤器
目前为止,我们可以同时对搜索结果和聚合结果进行过滤(不计算得分的 filter 查询),以及针对聚合结果的一部分进行过滤( filter 桶)。
我们可能会想,“只过滤搜索结果,不过滤聚合结果呢?” 答案是使用 post_filter 。
它是接收一个过滤器的顶层搜索请求元素。这个过滤器在查询 之后 执行(这正是该过滤器的名字的由来:它在查询之后 post 执行)。正因为它在查询之后执行,它对查询范围没有任何影响,所以对聚合也不会有任何影响。
我们可以利用这个行为对查询条件应用更多的过滤器,而不会影响其他的操作,就如 UI 上的各个分类面。让我们为汽车经销商设计另外一个搜索页面,这个页面允许用户搜索汽车同时可以根据颜色来过滤。颜色的选项是通过聚合获得的:
GET /cars/_search
{"query": {"match": {"make": "ford"}},"aggs": {"all_colors": {"terms": {"field": "color.keyword"}}},"post_filter": {"term": {"color.keyword": "green"}}
}
- post_filter 元素是 top-level 而且仅对命中结果进行过滤。
{"took": 2,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 2,"relation": "eq"},"max_score": 1.3291358,"hits": [{"_index": "cars","_id": "WVEUw44BZKfEnzIxjV7V","_score": 1.3291358,"_source": {"price": 30000,"color": "green","make": "ford","sold": "2014-05-18"}},{"_index": "cars","_id": "21GFw44BZKfEnzIxPWJm","_score": 1.3291358,"_source": {"price": 30000,"color": "green","make": "ford","sold": "2024-05-18"}}]},"aggregations": {"all_colors": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": "blue","doc_count": 2},{"key": "green","doc_count": 2}]}}
}
- 只对 hits 搜索结果有影响,而对 aggs 聚合结果没有任何影响。
查询 部分找到所有的 ford 汽车,然后用 terms 聚合创建一个颜色列表。因为聚合对查询范围进行操作,颜色列表与福特汽车有的颜色相对应。
最后, post_filter 会过滤搜索结果,只展示绿色 ford 汽车。这在查询执行过 后 发生,所以聚合不受影响。
这通常对 UI 的连贯一致性很重要,可以想象用户在界面商选择了一类颜色(比如:绿色),期望的是搜索结果已经被过滤了,而 不是 过滤界面上的选项。如果我们应用 filter 查询,界面会马上变成 只 显示 绿色 作为选项,这不是用户想要的!
性能考虑(Performance consideration)
当你需要对搜索结果和聚合结果做不同的过滤时,你才应该使用 post_filter , 有时用户会在普通搜索使用 post_filter 。
不要这么做! post_filter 的特性是在查询 之后 执行,任何过滤对性能带来的好处(比如缓存)都会完全失去。
在我们需要不同过滤时, post_filter 只与聚合一起使用。
小结
选择合适类型的过滤(如:搜索命中、聚合或两者兼有)通常和我们期望如何表现用户交互有关。选择合适的过滤器(或组合)取决于我们期望如何将结果呈现给用户。
- 在 filter 过滤中的 non-scoring 查询,同时影响搜索结果和聚合结果。
- filter 桶影响聚合。
- post_filter 只影响搜索结果。
多桶排序
多值桶( terms 、 histogram 和 date_histogram )动态生成很多桶。 Elasticsearch 是如何决定这些桶展示给用户的顺序呢?
内置排序
默认的,桶会根据 doc_count 降序排列。这是一个好的默认行为,因为通常我们想要找到文档中与查询条件相关的最大值:售价、人口数量、频率。但有些时候我们希望能修改这个顺序,不同的桶有着不同的处理方式。
GET /cars/_search
{"size" : 0,"aggs" : {"colors" : {"terms" : {"field" : "color.keyword","order": {"_count" : "asc" }}}}
}
- 用关键字 _count ,我们可以按 doc_count 值的升序排序。
我们为聚合引入了一个 order 对象, 它允许我们可以根据以下几个值中的一个值进行排序:
"aggregations": {"colors": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": "blue","doc_count": 4},{"key": "green","doc_count": 4},{"key": "red","doc_count": 8}]}}
_count
按文档数排序。对 terms 、 histogram 、 date_histogram 有效。
_term
按词项的字符串值的字母顺序排序。只在 terms 内使用。
_key
按每个桶的键值数值排序(理论上与 _term 类似)。 只在 histogram 和 date_histogram 内使用。
按度量排序
有时,我们会想基于度量计算的结果值进行排序。 在我们的汽车销售分析仪表盘中,我们可能想按照汽车颜色创建一个销售条状图表,但按照汽车平均售价的升序进行排序。
我们可以增加一个度量,再指定 order 参数引用这个度量即可:
GET /cars/_search
{"size": 0,"aggs": {"colors": {"terms": {"field": "color.keyword","order": {"avg_price": "asc"}},"aggs": {"avg_price": {"avg": {"field": "price"}}}}}
}
- 计算每个桶的平均售价。
- 桶按照计算平均值的升序排序。
"aggregations": {"colors": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": "blue","doc_count": 4,"avg_price": {"value": 20000}},{"key": "green","doc_count": 4,"avg_price": {"value": 21000}},{"key": "red","doc_count": 8,"avg_price": {"value": 32500}}]}}
我们可以采用这种方式用任何度量排序,只需简单的引用度量的名字。不过有些度量会输出多个值。 extended_stats 度量是一个很好的例子:它输出好几个度量值。
如果我们想使用多值度量进行排序, 我们只需以关心的度量为关键词使用点式路径:
GET /cars/_search
{"size" : 0,"aggs" : {"colors" : {"terms" : {"field" : "color.keyword","order": {"stats.variance" : "asc" }},"aggs": {"stats": {"extended_stats": {"field": "price"}}}}}
}
- 使用 . 符号,根据感兴趣的度量进行排序。
在上面这个例子中,我们按每个桶的方差来排序,所以这种颜色售价方差最小的会排在结果集最前面。
基于“深度”度量排序
在前面的示例中,度量是桶的直接子节点。平均售价是根据每个 term 来计算的。 在一定条件下,我们也有可能对 更深 的度量进行排序,比如孙子桶或从孙桶。
我们可以定义更深的路径,将度量用尖括号( > )嵌套起来,像这样: my_bucket>another_bucket>metric 。
需要提醒的是嵌套路径上的每个桶都必须是 单值 的。 filter 桶生成 一个单值桶:所有与过滤条件匹配的文档都在桶中。 多值桶(如:terms )动态生成许多桶,无法通过指定一个确定路径来识别。
目前,只有三个单值桶: filter 、 global 和 reverse_nested 。让我们快速用示例说明,创建一个汽车售价的直方图,但是按照红色和绿色(不包括蓝色)车各自的方差来排序:
GET /cars/_search
{"size" : 0,"aggs" : {"colors" : {"histogram" : {"field" : "price","interval": 20000,"order": {"red_green_cars>stats.variance" : "asc" }},"aggs": {"red_green_cars": {"filter": { "terms": {"color": ["red", "green"]}}, "aggs": {"stats": {"extended_stats": {"field" : "price"}} }}}}}
}
- 按照嵌套度量的方差对桶的直方图进行排序。
- 因为我们使用单值过滤器 filter ,我们可以使用嵌套排序。
- 按照生成的度量对统计结果进行排序。
本例中,可以看到我们如何访问一个嵌套的度量。 stats 度量是 red_green_cars 聚合的子节点,而 red_green_cars 又是 colors 聚合的子节点。 为了根据这个度量排序,我们定义了路径 red_green_cars>stats.variance 。我们可以这么做,因为 filter 桶是个单值桶。
v-key索引标志)

)












:访问 Prometheus UI界面:Warning: Error fetching server time)



