- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:TensorFlow入门实战|第3周:天气识别
- 🍖 原作者:K同学啊|接辅导、项目定制
一、文本输入人类理解
-
词向量(Embeddings): Transformer模型首先将输入的文本转换为词向量。这些向量是文本数据在模型能够处理的数值形式的表示。每个单词或符号被映射到一个高维空间,在这个空间中,语义相似的单词通常在向量空间中彼此靠近。这种表示法允许模型理解单词的含义以及它们在给定上下文中的关系。
-
位置向量(Positional Encoding): 由于Transformer模型不像RNN那样逐个序列处理单词,它需要另一种方法来理解单词在句子中的位置。位置编码向每个词向量添加信息,以表示单词的顺序。这使模型能够理解语序对意义的影响,如“John loves Mary”与“Mary loves John”在意义上的不同。
二、编码器Encoder
-
Self-Attention层: 编码器中的自注意力层允许模型在处理一个单词时同时考虑到其他所有单词。模型能够根据句子中其他单词的信息来加强或削弱对当前单词的关注。例如,在翻译任务中,这可以帮助模型更好地理解词语之间的复杂关系。
-
多头注意力机制: 多头注意力是自注意力的一个扩展,它允许模型同时从不同的表示子空间中学习信息。通过这种方式,模型可以在不同的层面上捕捉到词语间的关联,比如同时理解同一个词在不同句子中的不同含义。
-
残差连接: 在每一个注意力层和前馈网络层之后,都会有残差连接。这些连接可以帮助模型在深层网络中避免梯度消失问题,使得训练更加稳定,并允许信息直接从一个层传递到另一个较远的层。
三、解码器Decoder
- 编码器-解码器注意力: 在解码器中,这个层允许解码器关注编码器输出的相应部分,这在序列到序列的任务中非常有用,如机器翻译。解码器通过关注输入句子的特定部分来生成正确的翻译。
四、线性层和softmax层
-
线性层: 解码器的每个阶段都包括一个线性层,它是一个全连接层,用于将解码器的输出转换为更大的词汇空间——通常是目标语言的词汇空间大小。
-
Softmax层: 紧接着线性层之后的是softmax层,它将线性层的输出转换成概率分布,表示下一个单词是词汇表中每个单词的概率。这个概率分布随后用于选择最可能的下一个单词。
五、python实现Transformer
import torch
import torch.nn as nn
import math# 指定设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")class MultiHeadAttention(nn.Module):def __init__(self, hid_dim, n_heads):super(MultiHeadAttention, self).__init__()assert hid_dim % n_heads == 0self.hid_dim = hid_dimself.n_heads = n_headsself.w_q = nn.Linear(hid_dim, hid_dim)self.w_k = nn.Linear(hid_dim, hid_dim)self.w_v = nn.Linear(hid_dim, hid_dim)self.fc = nn.Linear(hid_dim, hid_dim)self.scale = torch.sqrt(torch.FloatTensor([hid_dim // n_heads]))def forward(self, query, key, value, mask=None):bsz = query.shape[0]Q = self.w_q(query)K = self.w_k(key)V = self.w_v(value)Q = Q.view(bsz, -1, self.n_heads, self.hid_dim // self.n_heads).permute(0, 2, 1, 3)K = K.view(bsz, -1, self.n_heads, self.hid_dim // self.n_heads).permute(0, 2, 1, 3)V = V.view(bsz, -1, self.n_heads, self.hid_dim // self.n_heads).permute(0, 2, 1, 3)energy = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scaleif mask is not None:energy = energy.masked_fill(mask == 0, -1e10)attention = torch.softmax(energy, dim=-1)x = torch.matmul(attention, V)x = x.permute(0, 2, 1, 3).contiguous()x = x.view(bsz, -1, self.n_heads * (self.hid_dim // self.n_heads))x = self.fc(x)return xclass Feedforward(nn.Module):def __init__(self, d_model, d_ff, dropout=0.1):super(Feedforward, self).__init__()# 两层线性变换和ReLU激活函数self.linear1 = nn.Linear(d_model, d_ff)self.dropout = nn.Dropout(dropout)self.linear2 = nn.Linear(d_ff, d_model)def forward(self, x):x = torch.nn.functional.relu(self.linear1(x))x = self.dropout(x)x = self.linear2(x)return xclass PositionalEncoding(nn.Module):"实现位置编码"def __init__(self, d_model, dropout, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)# 初始化一个Shape为(max_len, d_model)的位置编码矩阵pe = torch.zeros(max_len, d_model).to(device)# 初始化一个tensor [[0, 1, 2, 3, ...]]position = torch.arange(0, max_len).unsqueeze(1)# 这里计算sin和cos中的频率项,通过e的指数进行变换div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term) # 偶数位置填充sinpe[:, 1::2] = torch.cos(position * div_term) # 奇数位置填充cospe = pe.unsqueeze(0) # 为了方便批处理,增加一个可以unsqueeze出一个`batch`# 将pe注册为一个不参与梯度反传,但又希望保存在model的state_dict中的持久化buffer# 这个操作使得pe可以在forward中使用,但是不会被视为模型的一个可训练参数self.register_buffer('pe', pe)def forward(self, x):"""将embedding后的inputs,例如(1, 7, 128),batch size为1, 7个单词,每个单词的嵌入为128"""# 将x与positional encoding相加。x = x + self.pe[:, :x.size(1)].requires_grad_(False)return self.dropout(x)class EncoderLayer(nn.Module):def __init__(self, d_model, n_heads, d_ff, dropout=0.1):super(EncoderLayer, self).__init__()# 自注意力层和前馈神经网络层初始化及残差连接和层归一化self.self_attn = MultiHeadAttention(d_model, n_heads)self.feedforward = Feedforward(d_model, d_ff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, mask):# 自注意力机制attn_output = self.self_attn(x, x, x, mask)x = x + self.dropout(attn_output)x = self.norm1(x)# 前馈神经网络ff_output = self.feedforward(x)x = x + self.dropout(ff_output)x = self.norm2(x)return xclass DecoderLayer(nn.Module):def __init__(self, d_model, n_heads, d_ff, dropout=0.1):super(DecoderLayer, self).__init__()# 自注意力层和前馈神经网络层初始化及残差连接和层归一化self.self_attn = MultiHeadAttention(d_model, n_heads )self.enc_attn = MultiHeadAttention(d_model, n_heads )self.feedforward = Feedforward(d_model, d_ff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, enc_output, self_mask, context_mask):# 自注意力机制attn_output = self.self_attn(x, x, x, self_mask)x = x + self.dropout(attn_output)x = self.norm1(x)# 编码器-解码器注意力机制attn_output = self.enc_attn(x, enc_output, enc_output, context_mask)x = x + self.dropout(attn_output)x = self.norm2(x)# 前馈神经网络ff_output = self.feedforward(x)x = x + self.dropout(ff_output)x = self.norm3(x)return x
class Transformer(nn.Module):def __init__(self, vocab_size, d_model, n_heads, n_encoder_layers, n_decoder_layers, d_ff, dropout=0.1):super(Transformer, self).__init__()# Transformer模型包含嵌入层、位置编码、编码器和解码器层以及输出层self.embedding = nn.Embedding(vocab_size, d_model)self.positional_encoding = PositionalEncoding(d_model, dropout)self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(n_encoder_layers)])self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(n_decoder_layers)])self.fc_out = nn.Linear(d_model, vocab_size)self.dropout = nn.Dropout(dropout)def forward(self, src, trg, src_mask, trg_mask):# 嵌入层和位置编码src = self.embedding(src)src = self.positional_encoding(src)trg = self.embedding(trg)trg = self.positional_encoding(trg)# 编码器层for layer in self.encoder_layers:src = layer(src, src_mask)# 解码器层for layer in self.decoder_layers:trg = layer(trg, src, trg_mask, src_mask)# 输出层output = self.fc_out(trg)return output# 模型示例
vocab_size = 10000 # 假设词汇表大小为10000
d_model = 512
n_heads = 8
n_encoder_layers = 6
n_decoder_layers = 6
d_ff = 2048
dropout = 0.1transformer_model = Transformer(vocab_size, d_model, n_heads, n_encoder_layers, n_decoder_layers, d_ff, dropout)# 生成输入,这里的输入是随机的,需要根据实际情况修改
src = torch.randint(0, vocab_size, (32, 10)) # 假设源序列长度为10
trg = torch.randint(0, vocab_size, (32, 20)) # 假设目标序列长度为20# 生成掩码,用于屏蔽序列中的填充位置
src_mask = (src != 0).unsqueeze(1).unsqueeze(2) # 源序列掩码
trg_mask = (trg != 0).unsqueeze(1).unsqueeze(2) # 目标序列掩码# 模型前向传播
output = transformer_model(src, trg, src_mask, trg_mask)
print(output.shape) 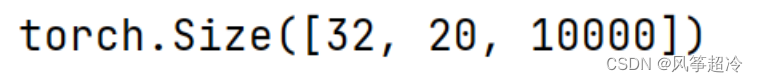





知识点)







:导言)
)


![P8794 [蓝桥杯 2022 国 A] 环境治理](http://pic.xiahunao.cn/P8794 [蓝桥杯 2022 国 A] 环境治理)
)
)