KMP算法
在正式进入
KMP算法之前,不得不先引经据典一番,因为直接去理解KMP,你可能会很痛苦(别问,问就是我也痛苦过)。所以做好前面的预热工作非常非常重要,为了搞明白KMP,在没见到KMP算法的完整代码之前,请耐心的将前面的东西看完。
一些相关的概念
学习KMP算法,得明白它主要得作用是什么,或者说它得出现是为了能更好得解决哪些方面得问题。
- 字符串
字符串这个概念就不过多介绍了,毕竟,相信点开这篇文章的,怎么说也是掌握 了至少一门编程语言的coder了吧,那对于诸如此简单的知识点相信还是没什么大问题的。
- 文本串
也称为主串或者模式串,也就是一串参照字符,可能有些地方叫法不一样,为了统一,以下统称为文本串。
比如:【abaabaabeca】可以看作是一文本串。
- 模式串
可能也有叫匹配串或者模板串啥的,用于在文本串中进行匹配的一行查找字符串,一般会作为被参照的字符串在文本串中逐一匹配,比如:【
abaabe】作为一行【abaabaabeca】的模式串。
- 字符串匹配
换句话说,字符串的匹配可以理解为根据某种规则在一行所给字符串中进行查找的过程。拿上面的示例字符串来讲,我们需要在文本串【
abaabaabeca】中查找模式串【abaabe】是否在其中出现过,返回出现的首索引,显然【abaabe】在【abaabaabeca】中第4(索引为3)个位置开始匹配成功。如上就是一个字符串匹配的过程。那么如何进行匹配?一般都有哪些方法?这个问题,下文即是答案。
问题引入
为了更好的讲解
KMP算法,我们假设有这样的一道题:
给定一个文本串T,以及一个模板串P,所有字符串中只包含大小写英文字母。
模板串 P 在文本串 S中多次作为子串出现。
若该模板串在文本串中出现过,请返回首次出现的下标位置,否则返回**-1**。
问题解决
根据题意,一种比较常见的解法是利用BF算法,也就是直接进行暴力匹配,具体的匹配过程是怎么样的,我们不妨还是以之前的两串为例,即文本串T = 【
abaabaabeca】,模板串P=【abaabe】。暴力匹配过程如下图。
BF匹配过程
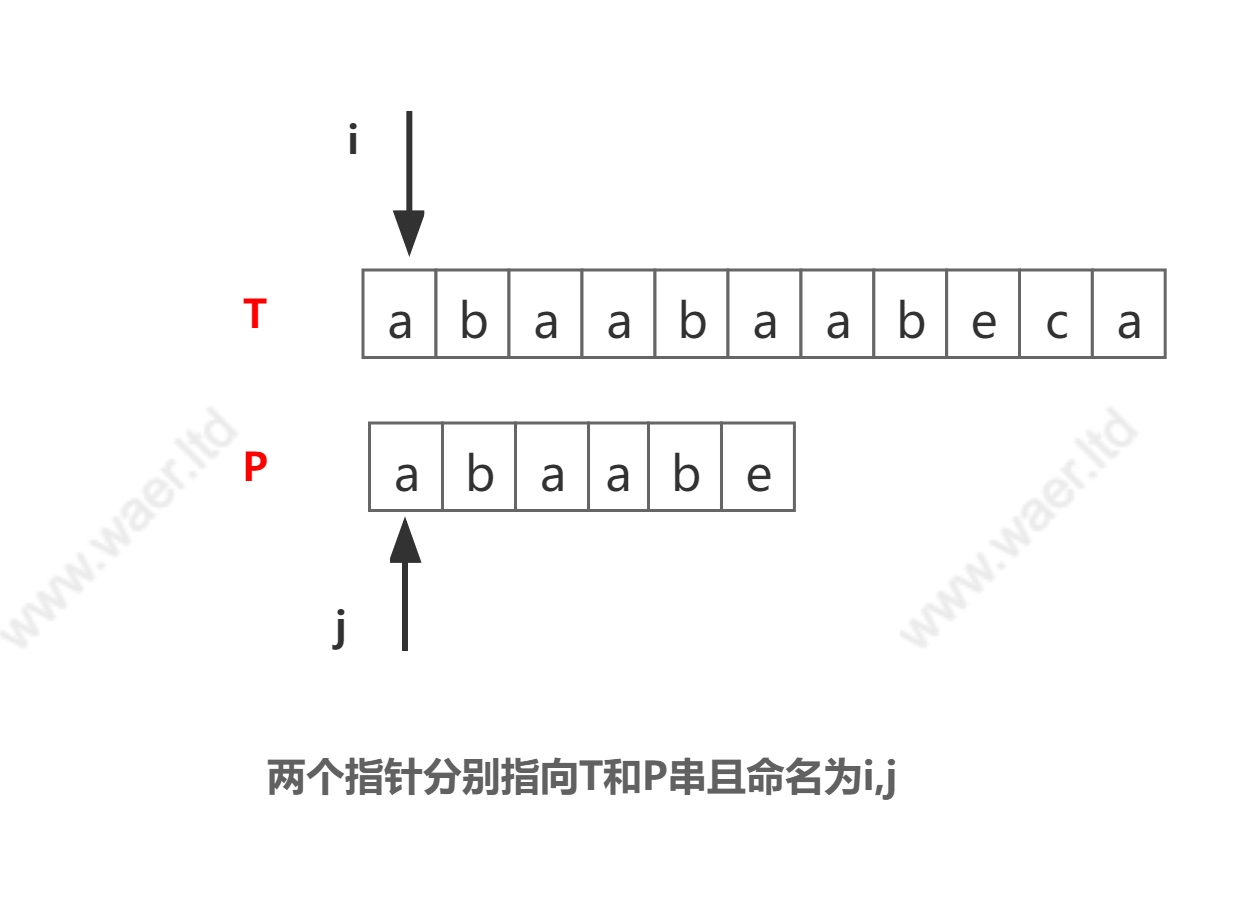
第一步:初始时,
i,j指向两串的第一个字符处,i=1,j=1;此时字符T[a]==P[a]匹配,指针i,j均后移一位,i=2,j=2第二步:
i,j指向两串的第二个字符处,i=2,j=2;此时字符T[b]==P[a]匹配,指针i,j均后移一位,i=3,j=3第三步:
i,j指向两串的第三个字符处,i=3,j=3;此时字符T[a]==P[a]匹配,指针i,j均后移一位,i=4,j=4…跳过第一趟均是匹配的步骤…,此时
i=6,j=6,T[a]!=P[e],显然出现了失配的情况。为了能继续匹配后面的字符,指针i应当回退到T串中第二个位置处,j指针应当回退到P串中第一个位置【即回到模板串的开头】重新开始匹配。如下图:
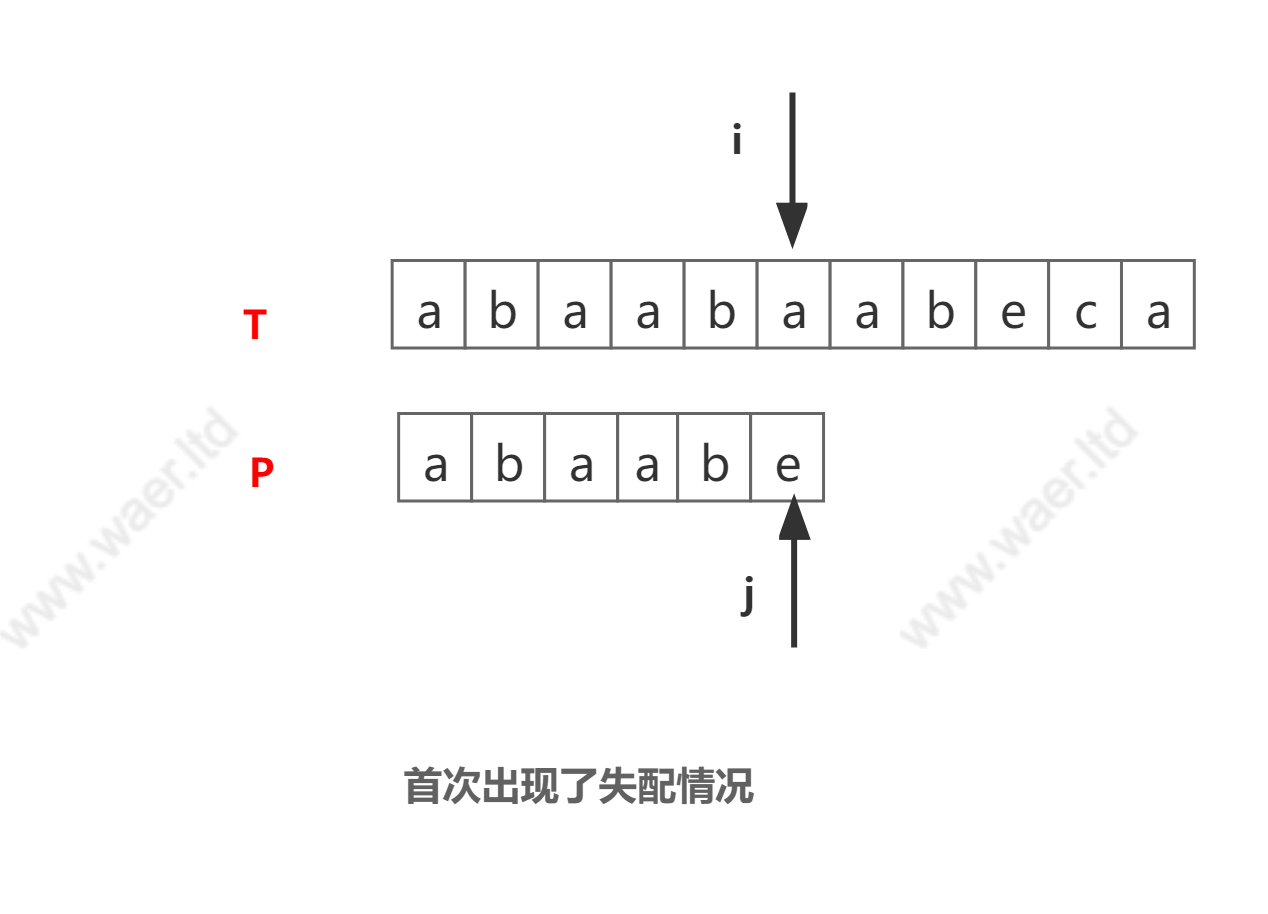
第二趟匹配开始,此时
i=2,j=1,T[b]!=P[a],出现失配情况,i指针继续回退到下一个位置,指针j再次回退到开头。即i回退到i=3的位置,j=1,过程和第一趟匹配是一样的原理。
经过简单的模拟会发现,文本串中的i指针每次回退的位置为i-j+2,而模板串指针j每次均需要回退到串的开头,通过上述匹配过程也发现了,BF算法中各指针j频繁的回退到开头的这个过程其实是真的够暴力。因此,引出了今天的主角KMP算法。
- 通过上面的演示,不难得出BF算法的代码。
//BF算法C++
int BF(char s[],char p[])
{int i=1,j=1;while(i<s[0] && j<p[0]){if(s[0]==p[0]){i++;j++;}else{i = i-j+2;j=1;}}if(j>p[0]){return (i-p[0]);}else{return -1;}
}
C++实现
//BF算法Java
public int BF(String T,String P){int j=0,i=0;int sn = T.length();int pn = P.length();//转字符数组char[] text = T.toCharArray();char[] patt = P.tpCharArray();while(i<sn && j<pn){if(text[i]==patt[j]){j++;i++;}else{i = i-j+1;j=0;}}if(j==pn){return i-j;}else{return -1;}
}
Java实现
KMP匹配过程
在
kmp算法中,相比于BF,一个很大的变化是指针的回退情况,上面也看到了,暴力的解法中,频繁的回退指针严重影响了算法的性能,其实很多匹配过程是多余的,比如BF中首次失配后,指针i和j所指向位置的字符都是第一趟匹配以及匹配过的,而经过第二趟,第三趟,第…趟匹配之后,出现了很多重复匹配的情况,这也是导致暴力解法效率低下的原因。那么找到了原因,是不是可以考虑从指针回退位置入手,有没有一种算法或者技巧,能将指针在字符串中重复匹配的情况尽可能降到最低呢?观察下面两种回退情况。
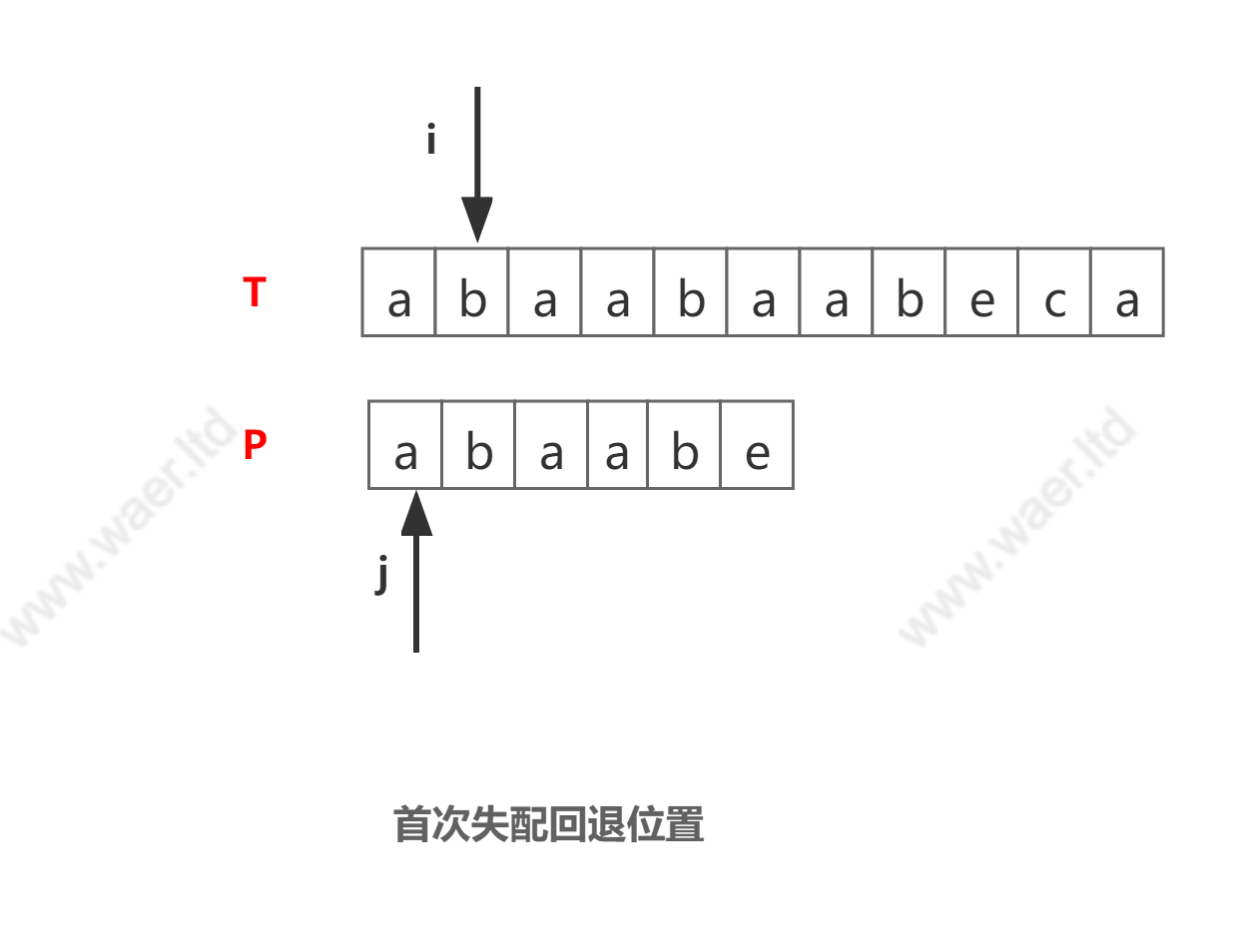
- BF中首次失配回退位置
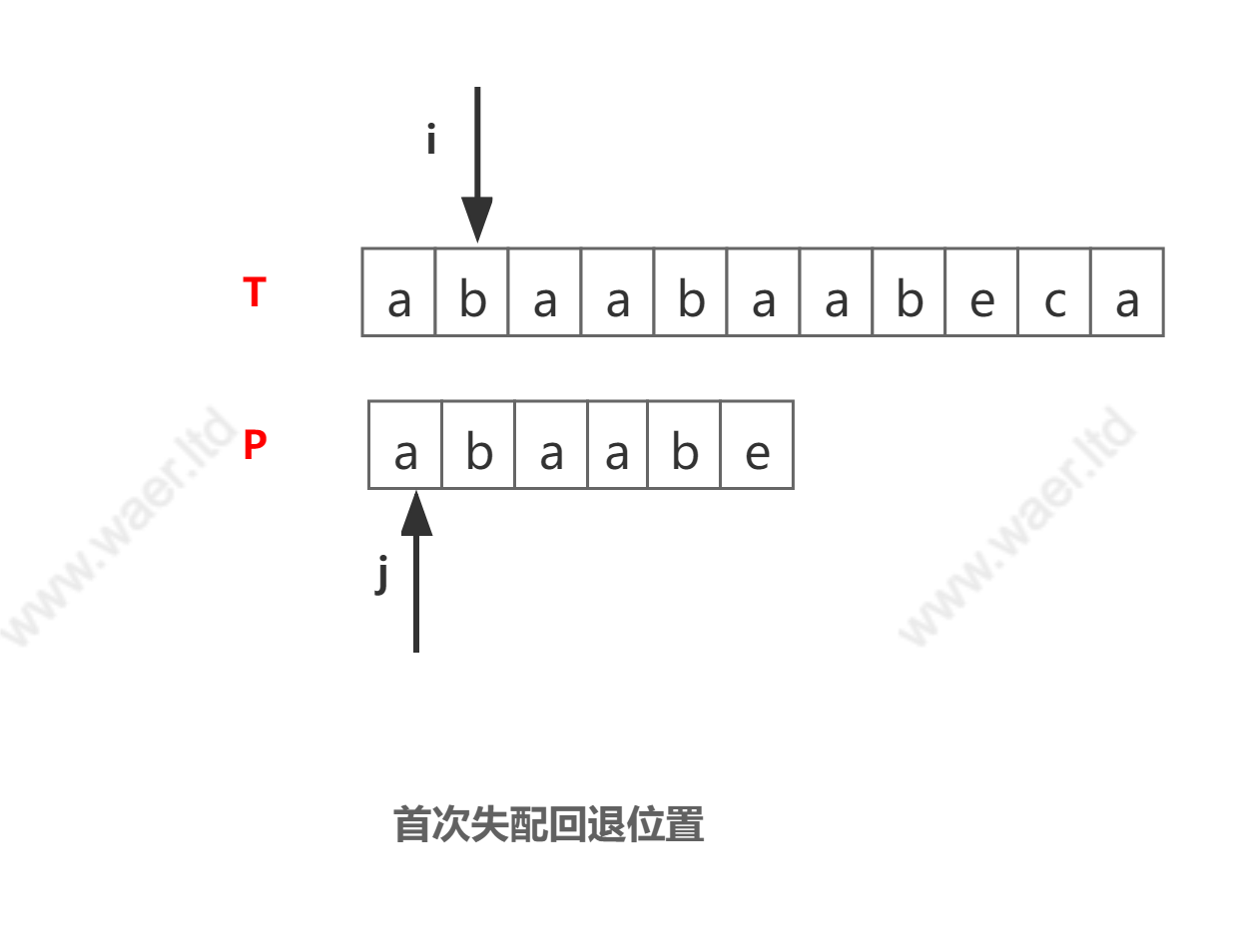
- KMP算法中,首次失配回退位置
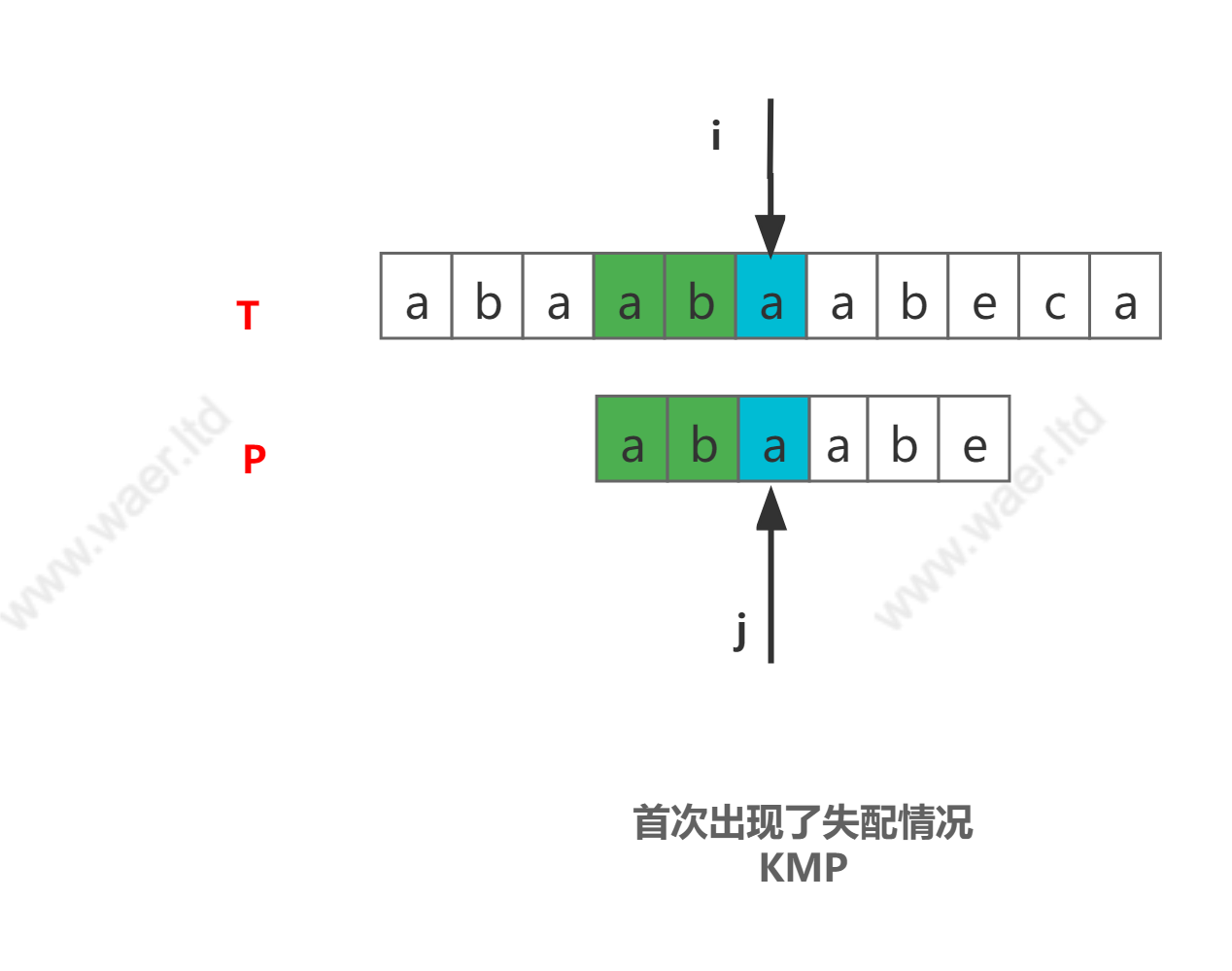
为什么指针
j会回退到P中第三个位置,而不是其他地方?观察匹配情况不难看出,其实在j指针之前的两个字符【a,b】(绿色部分)已经和指针i指向前面两个字符(绿色部分)匹配,所以自然没必要再重复匹配,j也就可以回退到第三个位置继续匹配过程。
- 怎么知道两个指针前面的字符是否一样(匹配)呢?不急,请接着往下看。
回顾上面BF匹配的原理,为什么指针
i,和指针j会同时走到当前位置??是不是只有当前位置前面的字符都匹配成功,i,j指针才会不断后移,以至走到当前位置。否则就会执行回退操作,直到再次匹配。看图:
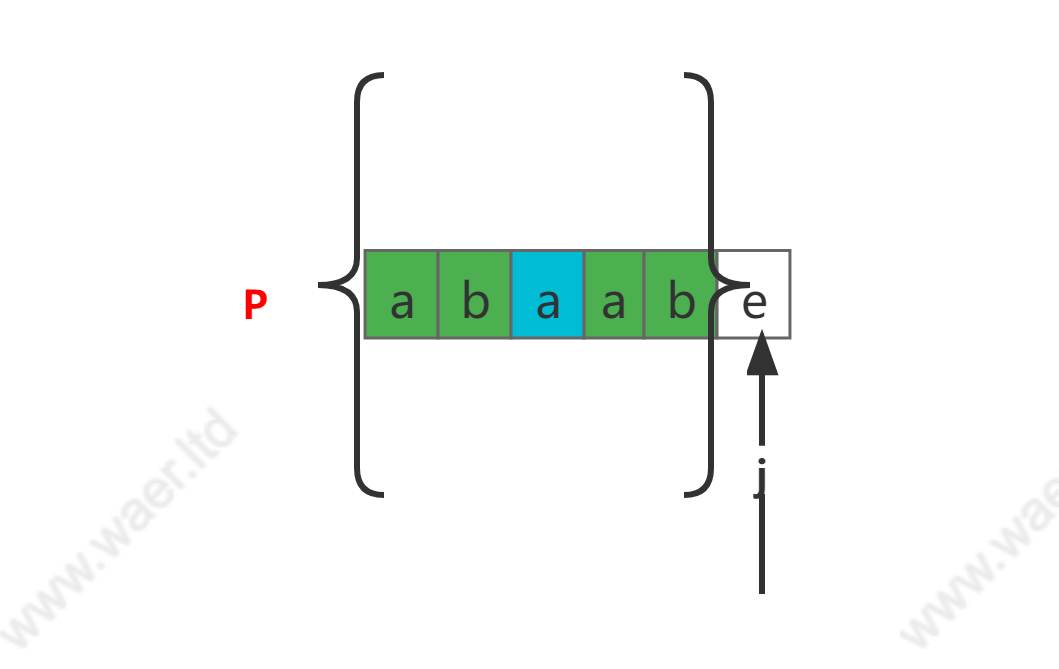
也就是说,我们大可不必在指向文本串T的指针
i和指向模板串P的指针j中判断前面的字符是不是一样,而只需要在模板串中进行比较即可【如果还是不太了解的,建议多画图进行模拟加深印象】。可以看到,上图中蓝色部分字符左右两边绿色部分的串是相等的,而他们都在指针j之前,那么,我们不妨将j指针前面的那部分字符串命为P'【P点撇】,至此,再比较P'的前缀和后缀即可。在本例中,P'=[abaab]。重点关键词【前缀】【后缀】。
- 关于前缀后缀
前缀:从前往后取的若干个字符
后缀:从后往前取的若干个字符
需要注意的是,这里的前缀后缀均不包含当前字符本身。
文字多是晦涩难懂,何不看看下面的这份表格?字符串【
abaab】的前后缀:
| 编号 | 长度 | 前缀 | 后缀 | 前后缀是否相等 |
|---|---|---|---|---|
| 1 | 1 | a | b | 不相等 |
| 2 | 2 | ab | ab | 相等 |
| 3 | 3 | aba | aab | 不相等 |
| 4 | 4 | abaa | baab | 不相等 |
长度表示前缀或者后缀字符的长度。通过上面的表格可以知道字符
e之前字符串的前缀后缀最长为2
则相应的,模板串指针j可以回退到的位置为:2+1=3,即回退到模板串中第三个字符的位置。也就是下图中蓝色格子的a字符位置。注意,这个过程中,文本串的指针是不需要进行任何回退操作的。
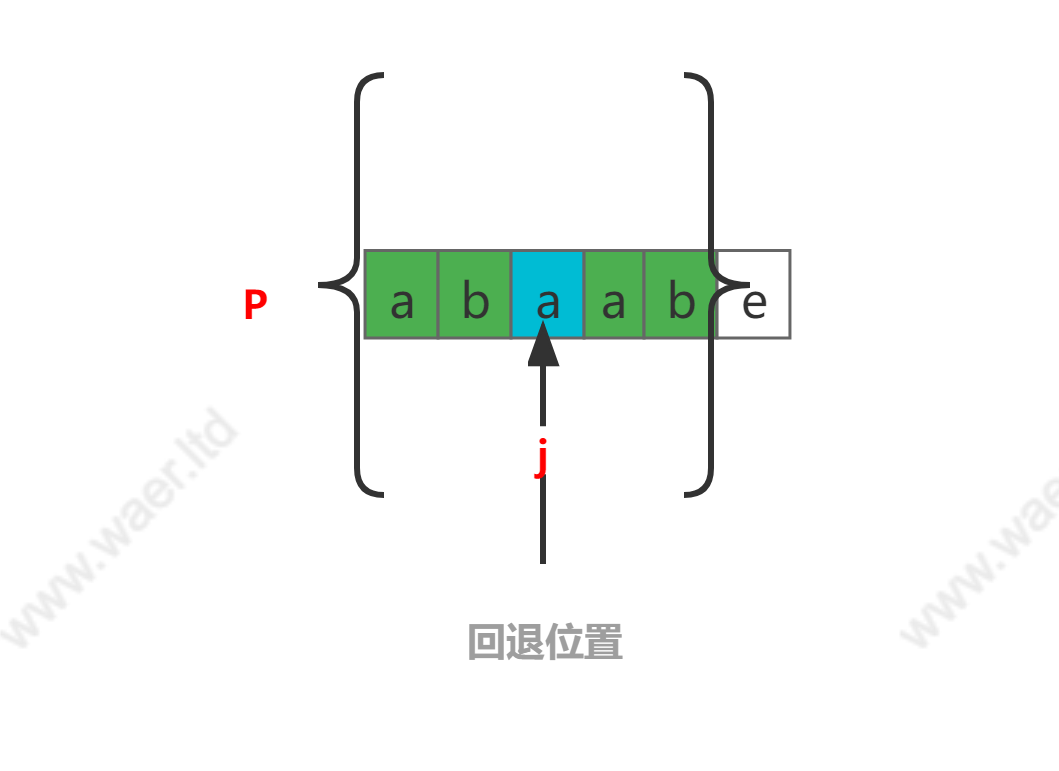
至此,我们将引出在
KMP算法中一个很重要的概念:【next数组】,这个自是个人习惯的叫法,在不同的资料或者文章里面每个人的叫法不一样,所以不必纠结于这种没什么营养的点。知道它的原理才是主要。
kmp算法核心:next数组
就像名称一样,next即下一个之意,通俗一点来说,就是在字符串匹配的过程中的失配情况下,模板串指针需要回退的位置,这个【位置】的值,就是next数组中的值。换句话说,next数组决定了失配时模板串指针的指向,而该指针的指向,直接决定了整个匹配过程的成败,或者说效率!!
- 实例模拟,求解next数组的值’
为了更深刻的理解求解next数组的过程,先放过字符串【
abaab】,我们来一个相对长一点的字符串进行模拟。该字符串为P = 【abaabcac】
| j | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| P | a | b | a | a | b | c | a | c |
| next[j] | 0 | 1 | 1 | 2 | 2 | 3 | 1 | 2 |
具体的推导过程:用
k表示j回退的位置且j=1,k=0,next[1]=0
Ⅰ.j=1,k=0,∵k=0,∴next[2]=1,∴++k=1,++j=2
Ⅱ.j=2,k=1,P[a]!=P[b],∴k = next[k]即k = next[1]=0,j=2不变
Ⅲ.j=2,k=0,∵k=0,∴next[3]=1,∴++k=1,++j=3
Ⅳ.j=3,k=1,P[a]==P[a],∴next[4]=2,++j=4,++k=2
Ⅴ.j=4,k=2,P[b]!=P[a],∴k = next[k]即k = next[2]=1,j=4```不变
省略中间步骤VI到XI【11】(别问为什么,舍友关灯睡觉了)
最后一步.j=7,k=1,∵P[a]==P[a],∴next[8] = 2,匹配结束。
你需要注意的是,上面的过程中,
j的位置是从1开始的,而不是0,因此,k=0表示此时指针仍指向第一个字符,由于一个字符,也就不存在前缀后缀,所以next[1]=0恒成立。也是因为这个起始位置的不同选择,会导致在代码和next数组的求解上有所差异。想把next数组理解的更深刻,还是需要多练,搞清楚前缀和后缀的概念很重要!!!
- 得到next数组的参考代码如下:
public static int[] Next(char[] p) {int pLen = p.length;int[] next = new int[pLen];int k = -1;int j = 0;// next数组中next[0]为-1,注意不是0了哦next[0] = -1;while (j < pLen - 1) {if (k == -1 || p[j] == p[k]) {next[++j] = ++k;} else {k = next[k];}}return next;}
Java版本
int Next(char t[],int next[])
{int i=1,j=0;next[1]=0;//注意这里next[1]=0,不是-1哦while(i<t[0]){if(j==0 || t[i]==t[j]){next[++j] = ++k;}else{j = next[j];}}
}
C++版本
- KMP算法完整代码
搞清楚了next数组的求解,
kmp算法也就是信手拈来的事了。
同样给出Java和C++版本的参考代码。
public static int indexOf(String T, String P) {int i = 0, j = 0;char[] text = source.toCharArray();char[] ptt = pattern.toCharArray();int sLen = text.length;int pLen = ptt.length;int[] next = Next(ptt);while (i < sLen && j < pLen) {//匹配成功if (j == -1 || src[i] == ptn[j]) {i++;j++;} else {j = next[j];}}if (j == pLen) {return i - j+1;}return -1;}
Java版本参考
int KMP(char s[],char t[],int next[])
{int j=1,i=1;while(i<=s[0] && j<=t[0]){if(j==0 || s[i]==t[j]){i++;j++;}else{j = next[j];}}if(j>t[0]){return (i-t[0]);}else{return 0;}
}
一些可能存在的疑惑
看了上面两种代码的实现,可能会疑惑,为什么next[0]的值会有两种情况?什么原因产生的。
其实这个问题的原因很简单,就是下标初值得取值不同导致next数组会不一样,具体得,我们还是用上面得串来看看,下标从0开始的情况下,它对应的next数组是什么样的。
| j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| P | a | b | a | a | b | c | a | c |
| next[j] | -1 | 0 | 0 | 1 | 1 | 2 | 0 | 1 |
初始:next[0]=-1,j=0,k=-1
Ⅰ.
j=0,k=-1,,∴next[++j] = ++k,即next[1]=0
Ⅱ.
j=1,k=0,P[1]!=P[0],且k!=-1,∴k = next[k]==next[0] = -1
Ⅲ.
j=1,k=-1,∴next[++j] = ++k,即next[2] = 0
中间步骤…
最后得到的next数组的值:【
-1,0,0,1,1,2,0,1】。有没有发现,这串next数组的值与前面【0,1,1,2,2,3,1,2】之间有上面关系么,我们可以将【-1,0,0,1,1,2,0,1】的值全部左移一位,你会发现结果就是【0,1,1,2,2,3,1,2】。所以两种写法并没有严格的多错之分,不过需要特别注意在细节上的处理,不然求出的next数组可能会出错,直接导致整个kmp算法错误。
递推证明

为了防止被劝退,特地把数学证明放在了最后。
复杂度分析
- BF算法
$O(mxn)$
- KMP算法
$O(m+n)$
补上八股文
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next()函数实现,函数本身包含了模式串的局部匹配信息。
关于KMP算法的优化
由于是常数上的优化,并不能改变原有的复杂度,所以就不再写了。

















)
)
