目录
一、梯度消失的原因
二、梯度爆炸的原因
三、共同的结构性原因
四、解决办法
五、补充知识
一、梯度消失的原因
梯度消失指的是在反向传播过程中,梯度随着层数的增加指数级减小(趋近于0),导致浅层网络的权重几乎无法更新。
1. 激活函数造成的梯度收缩
比如 sigmoid、tanh 函数在输入过大或过小时,梯度趋近于 0,导致反向传播过程中梯度逐层缩小。例如:Sigmoid的导数 σ′(x)=σ(x)(1−σ(x)),当 σ(x)接近0或1时,导数趋近于0。
2. 权重初始化不当
如果权重初始化得过小,前向传播时值越来越小,反向传播梯度也越来越小。
3. 网络过深与链式法则的连乘效应:
深层网络中梯度在多层链式求导中不断乘以小于1的数,最终导致梯度接近 0。
反向传播时,梯度是各层导数的连乘积
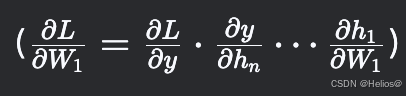 。
。
若每层导数均小于1,多层叠加后梯度会指数级缩小。
二、梯度爆炸的原因
梯度爆炸是指梯度在反向传播过程中指数级增大(趋向无穷大),导致参数更新步长过大,模型无法收敛。
1. 激活函数或权重造成的梯度放大
比如 relu 在某些输入下导数为1,但如果权重过大,前向传播输出和反向传播梯度都可能爆炸。
2. 网络结构太深
多层反向传播中梯度不断相乘,可能快速增长到很大。
3. 学习率过大
会导致更新步长过大,参数急剧变化,引发梯度爆炸。
三、共同的结构性原因
-
深层网络或长依赖路径:
无论是梯度消失还是爆炸,本质都是因为深层网络的梯度需要通过多层反向传播,链式法则的连乘效应被放大。 -
权重矩阵的共享(如RNN):
RNN中同一权重矩阵在时间步间共享,梯度爆炸/消失问题更显著。
四、解决办法
针对梯度消失:
-
使用非饱和激活函数(如ReLU、Leaky ReLU)。
-
残差连接(ResNet中的Skip Connection)打破链式法则的连乘。
-
批归一化(BatchNorm)稳定梯度分布。
-
合理的权重初始化(如He初始化)。
针对梯度爆炸:
-
梯度裁剪(Gradient Clipping)。
-
权重正则化(L2正则化)。
-
使用LSTM/GRU(通过门控机制缓解RNN中的梯度问题)。
通用策略:
-
调整网络深度或使用分阶段训练。
-
监控梯度范数(如
torch.nn.utils.clip_grad_norm_)。
五、补充知识
非饱和激活函数和饱和激活函数有什么区别?
✅ 1、定义对比
| 类型 | 定义 | 特点 | 代表函数 |
|---|---|---|---|
| 饱和激活函数 | 当输入很大或很小时,函数的导数(梯度)接近于 0 | 输出趋于一个上限/下限,梯度变小 | Sigmoid、Tanh |
| 非饱和激活函数 | 输入变大时,导数不会趋近于 0(或只有一边趋近于0) | 不容易造成梯度消失 | ReLU、Leaky ReLU、ELU、Swish |
🧪 2、具体例子对比
🔻 饱和激活函数
(1) Sigmoid:
• 导数为:
• 当 时,
• 结果:反向传播中梯度会越来越小 → 梯度消失
(2) Tanh:
• 输出范围在 [-1, 1]
• 同样导数趋近于 0,容易梯度消失
🔺 非饱和激活函数
(1) ReLU(Rectified Linear Unit):
• x > 0 时导数为 1,不会梯度消失
• 缺点:x < 0 导数为 0,可能导致“神经元死亡”
(2) Leaky ReLU:
• 小于0时也有梯度(通常)
(3) Swish、ELU 等:
• 既平滑又非饱和,近年很多模型喜欢用 Swish 或 GELU(尤其是 Transformer)。
🎯 三、实战中如何选?
| 场景 | 推荐激活函数 |
|---|---|
| 传统全连接网络(不太深) | Tanh / Sigmoid 勉强可用 |
| 卷积神经网络 CNN | ReLU / Leaky ReLU / ELU |
| Transformer 等深层模型 | GELU / Swish |
| 生成式模型(例如 VAE、Flow) | ELU / LeakyReLU / Tanh(输出层) |
🧠 一句话总结:
饱和函数容易梯度消失,不适合深层网络; 非饱和函数传播更稳定,是现代深度网络的标配。




)











:蓝牙面试问题与详解)


