一.单元测试
1.1 go test工具
go语言中的测试依赖go test命令。编写测试代码和编写普通的Go代码过程类似,并不需要学习新的语法,规则和工具。
go test命令是一个按照一定约定和组织的测试代码的驱动程序。在包目录内,所有以_test.go为后缀名的源代码文件都是go test测试的一部分,不会被go build编译到最终可执行文件中。
在*_test.go文件中有三种类型的函数,单元测试函数,基准测试函数和示例函数。

go test命令会遍历所有的*_test.go文件中符合上述命令规则的函数,然后生成一个临时的main包用于调用相应的测试函数,然后构建并运行,报告测试结果,最后清理测试中生成的临时文件。
Golang单元测试对文件名和方法名都有很严格的要求:
- 文件名必须以xx_test.go命名
- 方法必须是Test[^a-z]开头
- 方法参数必须是t *testing.T类型
- 使用go test执行单元测试
go test的参数解读:
- go test是go语言自带的测试工具,其中包含的是两类,单元测试和性能测试
- 通过go help test可以看到go test的使用说明。
格式:
go test [-c] [-i] [build flags] [package] [flags for test binary]
参数解读:
-c:编译go test成为可执行二进制文件,但是不运行测试
-i:安装测试包依赖的package,但是不运行测试
build flags:调用go help build,这些都是编译运行过程中需要使用到的参数,一般设置为空。
packages:调用go help packages,这些事关于包的管理,一般设置为空。
关于flags for test binary,调用go help testflag,这些是go test过程中经常使用到的参数
-test.v:是否输出全部的单元测试用例(不管成功失败),默认没有加上,所以只输出失败的单元测试用例。
-test.run pattern: 只跑哪些单元测试用例-test.bench patten: 只跑那些性能测试用例-test.benchmem : 是否在性能测试的时候输出内存情况-test.benchtime t : 性能测试运行的时间,默认是 1s-test.cpuprofile cpu.out : 是否输出 cpu 性能分析文件-test.memprofile mem.out : 是否输出内存性能分析文件-test.blockprofile block.out : 是否输出内部 goroutine 阻塞的性能分析文件-test.memprofilerate n : 内存性能分析的时候有一个分配了多少的时候才打点记录的问题。这 个参数就是设置打点的内存分配间隔,也就是profile 中一个 sample 代表的内存大小。默认是设置为 512 * 1024的。如果你将它设置为 1 ,则每分配一个内存块就会在 profile 中有个打点,那么生成的 profile的 sample 就会非常多。如果你设置为 0 ,那就是不做打点了。 你可以通过设置memprofilerate=1 和 GOGC=off 来关闭内存回收,并且对每个内存块的分配进行观察。-test.blockprofilerate n: 基本同上,控制的是 goroutine 阻塞时候打点的纳秒数。默认不设 置就相当于-test.blockprofilerate=1 ,每一纳秒都打点记录一下-test.parallel n : 性能测试的程序并行 cpu 数,默认等于 GOMAXPROCS 。-test.timeout t : 如果测试用例运行时间超过 t ,则抛出 panic-test.cpu 1,2,4 : 程序运行在哪些 CPU 上面,使用二进制的 1 所在位代表,和 nginx 的 nginx_worker_cpu_affinity是一个道理-test.short : 将那些运行时间较长的测试用例运行时间缩短
目录结构:

1.2 测试函数
1.2.1 测试函数格式
每个测试函数必须导入testing包,测试函数的基本格式如下:
func TestName(t *testing.T){//...
}测试函数的名字必须以Test开头,可选的后缀名必须以大写字母开头。举几个例子:
func TestAdd(t *testing.T){...}
func TestSum(t *testing.T){...}
func TestLog(t *testing.T){...}其中参数t用于报告测试失败和附加的日志信息。testing.T的拥有的方法如下:
func (c *T) Error(args ...interface{})
func (c *T) Errorf(format string, args ...interface{})
func (c *T) Fail()
func (c *T) FailNow()
func (c *T) Failed() bool
func (c *T) Fatal(args ...interface{})
func (c *T) Fatalf(format string, args ...interface{})
func (c *T) Log(args ...interface{})
func (c *T) Logf(format string, args ...interface{})
func (c *T) Name() string
func (t *T) Parallel()
func (t *T) Run(name string, f func(t *T)) bool
func (c *T) Skip(args ...interface{})
func (c *T) SkipNow()
func (c *T) Skipf(format string, args ...interface{})
func (c *T) Skipped() bool1.2.2 测试函数示例
一个软件程序由很多单元组件构成。单元组件可以是函数,结构体,方法和最终用户可能依赖的东西。总之我们需要确保这些组件是能够正常运行。单元测试是一些利用各种方法测试单元组件的程序,它会将结果与预期输出进行比较。
目录结构:

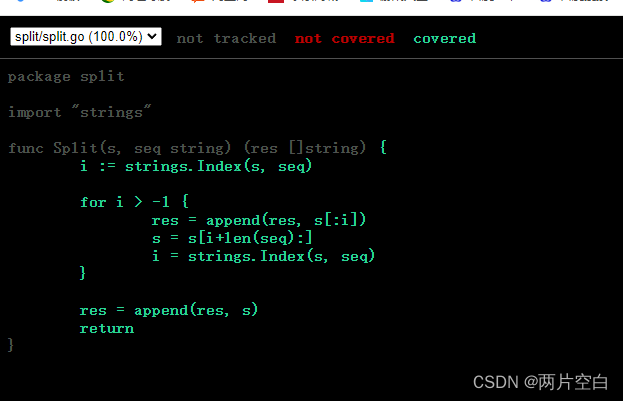
split.go代码:
package splitimport "strings"func Split(s, seq string) (res []string) {i := strings.Index(s, seq)for i > -1 {res = append(res, s[:i])s = s[i+1:]i = strings.Index(s, seq)}res = append(res, s)return
}split_test.go代码:
package splitimport ("reflect""testing"
)func TestSplit(t *testing.T) { //测试函数必须以Test开头,必须接收一个*testing.T的类型参数got := Split("a:b:c", ":") //测试程序的输出want := []string{"a", "b", "c"} //期待的结果if !reflect.DeepEqual(got, want) { //slice不能进行比较,借助反射包中的方法进行比较t.Errorf("excepted:%#v, got:%#v", want, got)}
}执行go test:
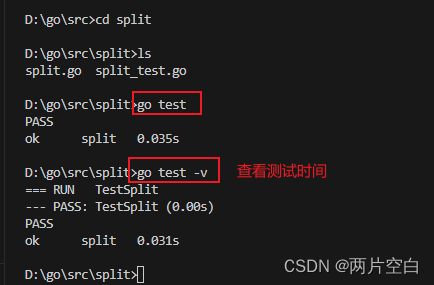
再增加一个测试用例:
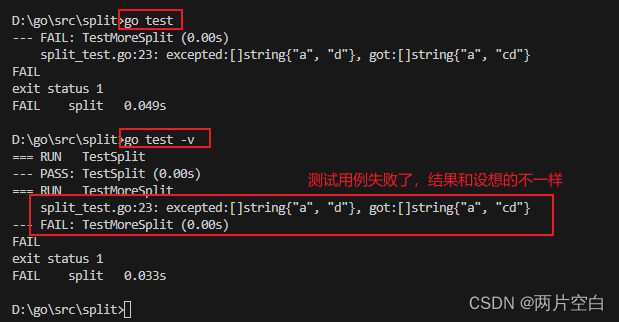
func TestMoreSplit(t *testing.T) {got := Split("abcd", "bc")want := []string{"a", "d"}if !reflect.DeepEqual(got, want) {t.Errorf("excepted:%#v, got:%#v", want, got)}
}输入go test和go test -v查看测试函数和运行时间:
还可以在go test命令后面加-run参数,它对应一个正则表达式,只有函数名匹配上的测试函数才会被go test命令执行。
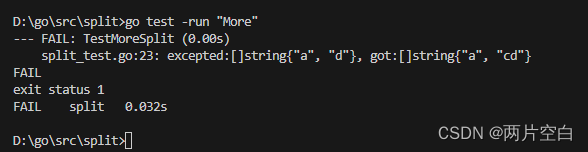
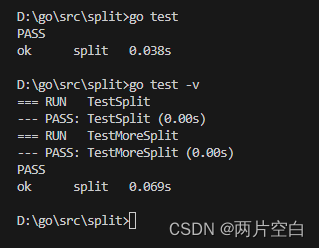
代码中失败的原因是:在Split函数并没有考虑seq为多字符的情况,下面为修复之后的代码:
package splitimport "strings"func Split(s, seq string) (res []string) {i := strings.Index(s, seq)for i > -1 {res = append(res, s[:i])s = s[i+len(seq):]i = strings.Index(s, seq)}res = append(res, s)return
}
1.2.3 测试组
package splitimport ("reflect""testing"
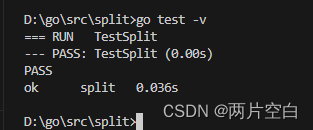
)func TestSplit(t *testing.T) {//定义测试用例类型type test struct {input stringseq stringoutput []string}//定义存储测试用例的切片tests := []test{{"a:b:c", ":", []string{"a", "b", "c"}},{"a:b:c", ",", []string{"a:b:c"}},{"abcd", "bc", []string{"a", "d"}},{"枯藤老树昏鸦", "老", []string{"枯藤", "树昏鸦"}},}//遍历切片,逐一执行测试用例for i, v := range tests {res := Split(v.input, v.seq)if !reflect.DeepEqual(v.output, res) {t.Errorf("index:%#v, excepted:%#v, got:%#v", i, v.output, v.input)}}
}
1.2.4 子测试
如果测试用例比较多的时候,我们没有办法一眼看出具体是哪一个测试用例失败了,我们可以使用下面的解决办法,使用testing.T的Run方法。
package splitimport ("reflect""testing"
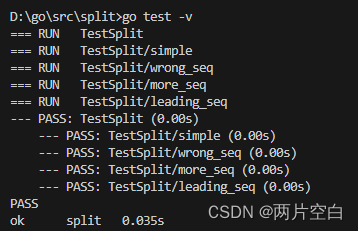
)func TestSplit(t *testing.T) {//定义测试用例类型type test struct {input stringseq stringoutput []string}tests := map[string]test{ //测试用例使用map储存"simple": {"a:b:c", ":", []string{"a", "b", "c"}},"wrong seq": {"a:b:c", ",", []string{"a:b:c"}},"more seq": {"abcd", "bc", []string{"a", "d"}},"leading seq": {"枯藤老树昏鸦", "老", []string{"枯藤", "树昏鸦"}},}for n, v := range tests {t.Run(n, func(t *testing.T) { //使用t.Runc()执行子测试res := Split(v.input, v.seq)if !reflect.DeepEqual(v.output, res) {t.Errorf("excepted:%#v, got:%#v", v.output, v.input)}})}
}
1.2.5 测试覆盖率
测试覆盖率是你的代码被测试套件的百分比,通常我们使用的是语句的覆盖率。也就是在测试中,至少被运行一次的代码占总代码的比例。
Go提供内置功能来检查你的代码的覆盖率。我们可以使用go test -cover来查看测试覆盖率。
例子还是上面的例子:
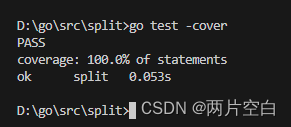
从上面的结果可以看到我们的测试用例覆盖了100%的代码。
Go还提供了一个额外的-coverprofile参数,用来将覆盖率相关的记录信息输出到一个文件。例如:

上面的命令会将覆盖率相关的信息输出到当前文件夹下面的c.out文件中,然后我们执行go tool cover -html=c.out,使用cover工具来处理生成的记录信息,该命令会打开本地的浏览器窗口生成一个HTML报告。
二.压力测试
2.1 基准测试
基准测试就是在一定的工作负载之下检测程序性能的一种方法。基准测试的基本格式如下:
func BenchmarkName(b *testing.B){//...
}基准测试以Benchmark为前缀,需要一个*testing.B类型的参数b,基准测试必须要执行b.N次,这样测试才有对照性,b.N的值是系统根据实际情况去调整的,从而保证测试的稳定性。
testing.B拥有的方法如下:
func (c *B) Error(args ...interface{})
func (c *B) Errorf(format string, args ...interface{})
func (c *B) Fail()
func (c *B) FailNow()
func (c *B) Failed() bool
func (c *B) Fatal(args ...interface{})
func (c *B) Fatalf(format string, args ...interface{})
func (c *B) Log(args ...interface{})
func (c *B) Logf(format string, args ...interface{})
func (c *B) Name() string
func (b *B) ReportAllocs()
func (b *B) ResetTimer()
func (b *B) Run(name string, f func(b *B)) bool
func (b *B) RunParallel(body func(*PB))
func (b *B) SetBytes(n int64)
func (b *B) SetParallelism(p int)
func (c *B) Skip(args ...interface{})
func (c *B) SkipNow()
func (c *B) Skipf(format string, args ...interface{})
func (c *B) Skipped() bool
func (b *B) StartTimer()
func (b *B) StopTimer()2.2 基准测试示例
我们为Split包中的Split函数编写基准测试如下:
func BenchmarkSplit(b *testing.B) {for i := 0; i < b.N; i++ {Split("枯藤老树昏鸦", "老")}
}基准测试并不会默认执行,需要增加-bench参数,所以我们通过执行go test -bench=Split命令执行基准测试:
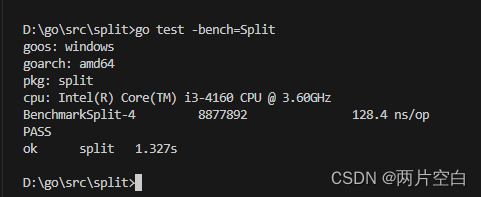
其中BenchmarkSplit-4表示对Split函数进行基准测试,数字4表示GOMAXPROCS的值,这个对于并发基准测试很重要。8877892和128.4ns/op表示每次调用Split函数耗时128.4ns,这个结果是8877892次调用的平均值。
我们也可以加上-banchmem参数,来获取内存分配的统计数据。
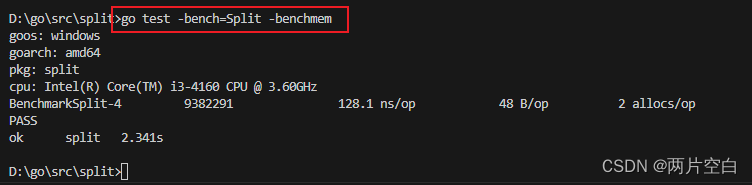
其中,48B/op表示每次操作内存分配了48字节,2allocs/op则表示每次操作进行了2次内存分配。
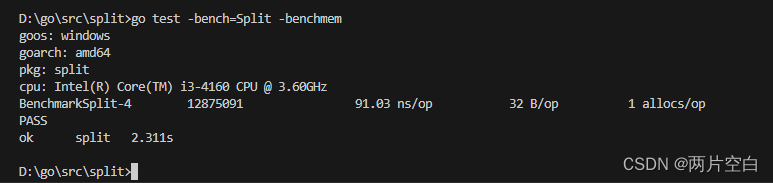
我们将Split函数优化如下: 提前使用make函数将res初始化为一个容量足够大的切片,而不再像之前一样通过调用append函数来追加,append可能会导致扩容,内存重新分配。我们来看一下性能会有多少提升。
func Split(s, seq string) (res []string) {res = make([]string, 0, strings.Count(s, seq)+1) //提前分配好内存i := strings.Index(s, seq)for i > -1 {res = append(res, s[:i])s = s[i+len(seq):]i = strings.Index(s, seq)}res = append(res, s)return
}
2.3 性能比较函数
上面的基准测试只能得到给定操作的绝对耗时,但是在很多性能问题是发生在两个不同的操作之间的相对耗时。比如:同一个函数处理1000个元素的耗时与处理1万甚至100万个元素耗时差别是多少?再或者对于同一个任务究竟使用哪种算法性能最佳?我们通常需要对两个不同的算法的实现使用相同的输入来进行基准比较测试。
性能比较函数通常是一个带有参数的函数,被多个不同的Brenchmark函数传入不同的值来调用。举个例子:
func brenchmark(b *testing.B, size int){/*...*/}
func Brenchmark10(b *testing.B){ brenchmark(b, 10) }
func Brenchmark100(b *testing.B){ brenchmark(b, 100) }
func Brenchmark1000(b *testing.B){ brenchmark(b, 1000) }例如:我们编写一个斐波那契函数:
package fibfunc Fib(n int) int {if n < 2 {return n}return Fib(n-1) + Fib(n-2)
}性能比较函数:
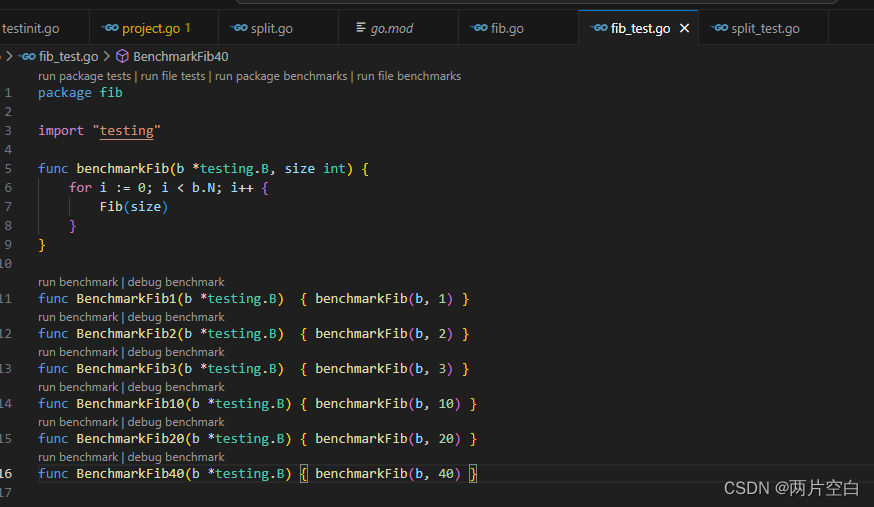
运行基准测试:
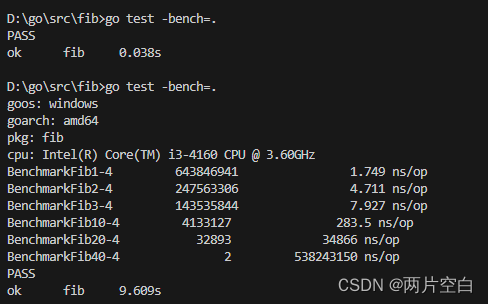
需要注意的是,默认情况下,每个基准测试至少运行一秒(即总共时间得字少大于等于1秒),如果Benchmark函数返回时,没有到1秒,则b.N的值会按1,2,5,10,20...增加,并且函数再次运行。
最终BenchmarkFib40只运行了两次,没运行的平均时间只有不到1秒。像这种情况我们应该使用-brenchtime标志增加最小基准时间,以产生更准确的结果。
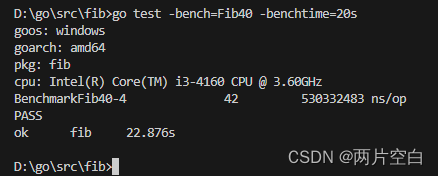
这样次数增加到了42次,结果就会更加准确了。
使用性能比较函数做测试的时候一个容易犯的错误是把b.N作为输入的大小,下面两个例子都是错误示范:
//错误示范1 func BenchmarkFibWrong1(b *testing.B){for i := 0; i < b.N; i++{Fib(i)} }//错误释放2 func BenchmarkFibWrong2(c *testing.B){Fib(b.N) }
2.4 重置时间
b.ResetTimer之前的处理不会放到执行时间里,也不会输出到报告中,所以可以在之前做一些不计划走位测试报告的操作。
func BenchmarkSplit(b *testing.B) {time.Sleep(5 * time.Second) //做一些耗时的无关操作b.ResetTimer() //重置计时器for i := 0; i < b.N; i++ {Split("枯藤老树昏鸦", "老")}
}2.5 并行测试
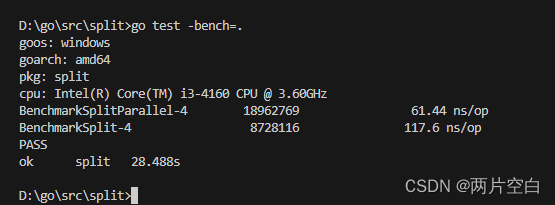
func (b B) RunParallel (body func(PB))会以并行的方式执行给定的基准测试。
RunParallel会创建出多个goroutine,并将b.N分配给这些goroutine执行,其中goroutine数量的默认值为GOMAXPROCS。用户如果想要增加非CPU受限(non-CPU-bound)基准测试的并行性,那么可以在RunParallel之前调用SetParallelism。RunParallel通常会与-cpu标志一同使用。
func BenchmarkSplitParallel(b *testing.B) {//b.SetParallelism(1) 设置使用CPU数量b.RunParallel(func(pb *testing.PB) {for pb.Next() { //Next报告是否还有更多的迭代要执行。Split("枯藤老树昏鸦", "老")}})
}
还可以通过在测试命令后面加-cpu参数如go test -bench=. -cpu 1来指定使用的CPU数量。
2.6 Setup和TearDown
测试程序有时需要在测试之前进行额外的设置(setup)或在测试之后进行拆卸(teardown)。
2.6.1 TestMain
通过在*_test.go文件中定义TestMain函数可以在测试之前进行额外的设置(setup)或在测试之后进行拆卸(teardown)操作。
如果测试文件包含函数:func TestMain(m *testing.M)那么生成测试会先调用TestMain(m),然后再运行具体测试。TestMain运行在主goroutine中,可以在调用m.Run前后做任何设置(setup)和拆卸(teardown)。退出测试的时候应该使用m.Run的返回值作为参数调用的os.Exit。
一个TestMain来设置Setup和TearDown的示例如下:
func TestMain(m *testing.M) {fmt.Println("write setup code here ...") //测试之前做的一些设置//如果TestMain使用了flags,这里应该加上flags.Parse()retCode := m.Run() //执行测试fmt.Println("write teardown code here ...") //测试之后的拆卸工作os.Exit(retCode) //退出测试
}需要注意的是:在调用TestMain时,flag.Parse并没有被调用。所以如果TestMain依赖于(命令行参数)command-line标志(包括testing包的标记),则应该先调用flag.Parse。
2.6.2 子测试的Setup与Teardown
有时我们可能需要为每个测试集设置Setup和Teardown,也有可能需要为每个子测试设置Setup与Teardown。下面我们定义两个工具函数如下:
// 测试集的setup和teardown
func setupTestCase(t *testing.T) func(t *testing.T) {t.Log("如果需要在此执行:测试之前的setup")return func(t *testing.T) {t.Log("如果需要在此执行:测试之前的teardown")}
}// 子测试的setup和teardown
func setupSubTest(t *testing.T) func(t *testing.T) {t.Log("如果需要在此执行:子测试之前的setup")return func(t *testing.T) {t.Log("如果需要在此执行:子测试之前的teardown")}
}使用方式:
func TestSplit(t *testing.T) {//定义测试用例类型type test struct {input stringseq stringoutput []string}tests := map[string]test{ //测试用例使用map储存"simple": {"a:b:c", ":", []string{"a", "b", "c"}},"wrong seq": {"a:b:c", ",", []string{"a:b:c"}},"more seq": {"abcd", "bc", []string{"a", "d"}},"leading seq": {"枯藤老树昏鸦", "老", []string{"枯藤", "树昏鸦"}},}teardownTestCase := setupTestCase(t) //测试之前执行setup操作defer teardownTestCase(t) //测试之后执行testsown操作//遍历切片,逐一执行测试用例for n, v := range tests {teardownSubTest := setupSubTest(t) //子测试之前的setup操作defer teardownSubTest(t) //子测试之后的teardown操作t.Run(n, func(t *testing.T) { //使用t.Runc()执行子测试res := Split(v.input, v.seq)if !reflect.DeepEqual(v.output, res) {t.Errorf("excepted:%#v, got:%#v", v.output, v.input)}})}
}测试结果:
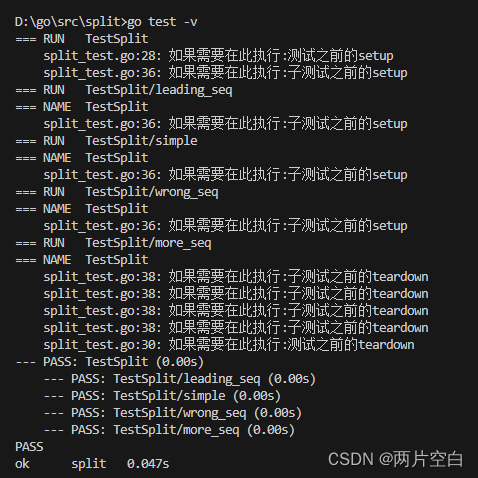
三.示例函数
3.1 示例函数格式
被go test特殊对待的第三中函数就是示例函数,它们的函数名以Example为前缀。既没有参数也没有返回值。格式如下:
func ExampleName(){//...
}3.2 示例函数示例
func ExampleSplit() {fmt.Println(Split("a:b:c", ":"))fmt.Println(Split("枯藤老树昏鸦", "老"))
}为你的代码编写示例函数又下面三个用处:
- 示例函数能够作为文档使用,例如基于web的godoc中能把示例函数与对应的函数或包相关联。
- 示例函数只要包含了,也可以通过go test运行可执行测试。
- go test -run Example
- 示例函数提供了可以直接运行的示例代码,可以直接在golang.org的godoc文档服务器上使用GoPlayground运行实例代码。下图为string.ToUpper函数在Playground的实例函数效果。


介绍、JVM组成、堆、栈、方法区/元空间、直接内存)






:2024.03.31-2024.04.05)
面向对象进阶)








