<!--爬虫仅支持1.8版本的jdk--> <!-- 爬虫需要的依赖--> <dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.2</version> </dependency><!-- 爬虫需要的日志依赖--> <dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.25</version> </dependency>
爬虫配置文件位置及存放位置
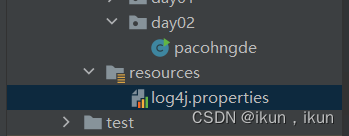
#爬虫日志配置文件 不写就报错
log4j.rootLogger=DEBUG,A1
log4j.logger.cn.itcast = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss, SSS} 【%t】 【%c】-【%p】 %m%n
实例代码
package day02;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;import java.io.IOException;public class pacohngde {public static void main(String[] args) throws IOException {//注意这个方法是爬取网址所有位置//1.打开浏览器,创建Httpclient对象// CloseableHttpclient httpclient = Httpclients.createDefault();CloseableHttpClient aDefault = HttpClients.createDefault();//2.输入网址,发起get请求创建HttpGet对象 输入你需要爬取的网址Httppost httpGet = new Httppost("https://zhuanlan.zhihu.com/p/98346518");//3.按回车,发起请求,返回响应,使用httpclient对象发起请求CloseableHttpResponse response = aDefault.execute(httpGet);//4.解析响应,获取数据//判断状态码是否是200 200为正常型号 其他为异常if(response.getStatusLine().getStatusCode()== 200){//获取爬取数据HttpEntity httpEntity =response.getEntity();//将爬取数据解析为utf-8格式String content = EntityUtils.toString(httpEntity,"utf-8");//打印System.out.println(content);
}
//释放资源 response.close(); //关闭网页 aDefault.close();} }