简介
2020新冠爆发以来,疫情牵动着全国人民的心,一线医护工作者在最前线抗击疫情的同时,我们也可以看到很多科技行业和人工智能领域的从业者,也在贡献着他们的力量。近些天来,旷视、商汤、海康、百度都多家科技公司研发出了带有AI人脸检测算法的红外测温、口罩佩戴检测等设备,依图、阿里也研发出了通过深度学习来自动诊断新冠肺炎的医疗算法。
🔥 优质竞赛项目系列,今天要分享的是
图像口罩识别
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
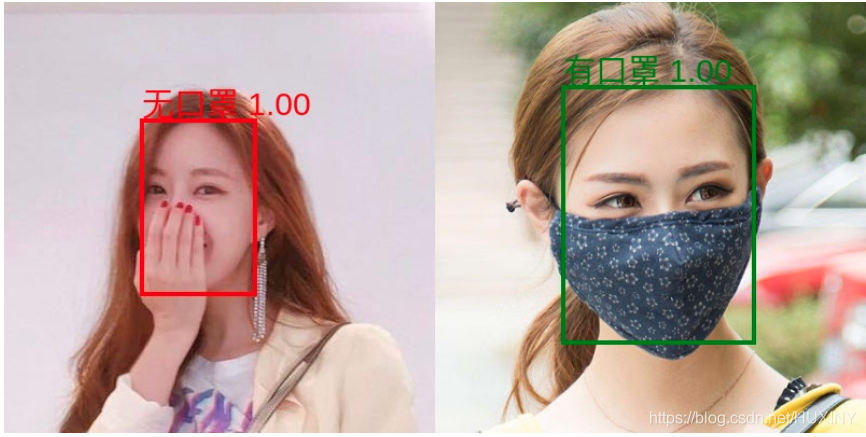
效果展示
不多说, 先上效果

实现方法
模型介绍
在深度学习时代之前,人脸检测一般采用传统的、基于手动设计特征的方法,其中最知名的莫过于Viola-
Jones算法,至今部分手机和数码相机内置的人脸检测算法,仍旧采用Viola-
Jones算法。然而,随着深度学习技术的蓬勃发展,基于深度学习的人脸检测算法逐步取代了传统的计算机视觉算法。
在人脸检测最常用的数据集——WIDER Face数据集的评估结果上来看,使用深度学习的模型在准确率和召回率上极大的超过了传统算法。下图的青线是Viola-
Jones的Precision-Recall图。

下图是众多基于深度学习的人脸检测算法的性能评估PR曲线。可以看到基于深度学习的人脸检测算法的性能,大幅超过了VJ算法(曲线越靠右越好)。近两年来,人脸检测算法在WIDER
Face的简单测试集(easy 部分)上可以达到95%召回率下,准确率也高达90%,作为对比,VJ算法在40%召回率下,准确率只有75%左右。

其实,基于深度学习的人脸检测算法,多数都是基于深度学习目标检测算法进行的改进,或者说是把通用的目标检测模型,为适应人脸检测任务而进行的特定配置。而众多的目标检测模型(Faster
RCNN、SSD、YOLO)中,人脸检测算法最常用的是SSD算法,例如知名的SSH模型、S3FD模型、RetinaFace算法,都是受SSD算法的启发,或者基于SSD进行的任务定制化改进,
例如将定位层提到更靠前的位置,Anchor大小调整、Anchor标签分配规则的调整,在SSD基础上加入FPN等。
在我个人看来,SSD是最优雅、简洁的目标检测模型,因此,我们实现的人脸口罩检测模型,也是采用SSD的思想,限于篇幅原因
在本项目中,我们使用的是SSD架构的人脸检测算法,相比于普通的人脸检测模型只有人脸一个类别,而人脸口罩检测,只不过是增加了一个类别,变成戴口罩人脸和不戴口罩的人脸两个类别而已。
我们开源的模型是一个非常小的模型,输入是260x260大小,主干网络只有8层,有五个定位和分类层,一共只有28个卷积层。而每个卷积层的通道数,是32、64、128这三种,所有这个模型总的参数量只有101.5万个参数。下图是网络的结构图。

其中,上面八个卷积层是主干网络,也就是特征提取层,下面20层是定位和分类层(注意,为了方便显示,我们没有画出BN层)。
训练目标检测模型,最重要的合理的设置anchor的大小和宽高比,笔者个人在做项目时,一般会统计数据集的目标物体的宽高比和大小来设置anchor的大小和宽高比。例如,在我们标注的口罩人脸数据集上,我们读取了所有人脸的标注信息,并计算每个人脸高度与宽度的比值,统计得到高度与宽比的分布直方图,如下:

因为人脸的一般是长方形的,而很多图片是比较宽的,例如16:9的图片,人脸的宽度和高度归一化后,有很多图片的高度是宽度的2倍甚至更大。从上图也可以看出,归一化后的人脸高宽比集中在1~2.5之间。所以,根据数据的分布,我们将五个定位层的anchor的宽高比统一设置为1,0.62,
0.42。(转换为高宽比,也就是约1,1.6:1,2.4:1)
五个定位层的配置信息如下表所示:

笔者使用基于Keras实现的目标检测微框架训练的人脸口罩检测模型,为了避免一些网友提到的使用手挡住嘴巴就会欺骗部分口罩检测系统的情况,我们在数据集中加入了部分嘴巴被手捂住的数据,另外,我们还在训练的过程中,随机的往嘴巴部分粘贴一些其他物体的图片,从而避免模型认为只要露出嘴巴的就是没戴口罩,没露出嘴巴的就是带口罩这个问题,通过这两个规避方法,我们很好的解决了这个问题,大家可以在aizoo.com体验我们的模型效果。
后处理部分主要就是非最大抑制(NMS),我们使用了单类的NMS,也就是戴口罩人脸和不戴口罩人脸两个类别一起做NMS,从而提高速度。
获取数据集
人脸口罩数据集下载
下载人脸口罩数据集的目的是利用OpenCV进行模型训练,这里采用口罩数据集的正负比列为1:3,即500张戴口罩的人脸图片和1500张不戴口罩的人脸图片。
数据集获取:联系博主获取
解压之后,将压缩包中的mask文件自行选择文件夹放置,以便之后的操作。
如下:

上面带口罩的人脸图像我们命名为正样本,相反,没带口罩的数据集合命名为负样本, 如下:

由于数据集解压后样本图像命名是乱序的,我们要进行重命名,上面两幅图是已经处理好的, 下面给出示例代码
#对数据集重命名#coding:utf-8import ospath = "E:\\facemask\\mask\\have_mask" #人脸口罩数据集正样本的路径filelist = os.listdir(path)count=1000 #开始文件名1000.jpgfor file in filelist: Olddir=os.path.join(path,file) if os.path.isdir(Olddir): continuefilename=os.path.splitext(file)[0] filetype=os.path.splitext(file)[1]Newdir=os.path.join(path,str(count)+filetype) os.rename(Olddir,Newdir)count+=1#对数据集重命名#coding:utf-8import ospath = "E:\\facemask\\mask\\no_mask" #人脸口罩数据集的路径filelist = os.listdir(path)count=10000 #开始文件名1000.jpgfor file in filelist: Olddir=os.path.join(path,file) if os.path.isdir(Olddir): continuefilename=os.path.splitext(file)[0] filetype=os.path.splitext(file)[1]Newdir=os.path.join(path,str(count)+filetype) os.rename(Olddir,Newdir)count+=1最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate




)



)
(详细解释+详细演示))



)
)




