暑期实习面试在即,这几天八股和算法轮扁我>_
八股部分打算先找学习视屏跟着画下思维导图,然后看详细的面试知识点,最后刷题
其中导图包含的是常考的题,按照思维导图形式整理,会在复盘后更新
细节研究侧重补全,会收集不会的偏怪点
最后刷题部分记录自己不会的错题
导图
首先梳理总结过了一遍
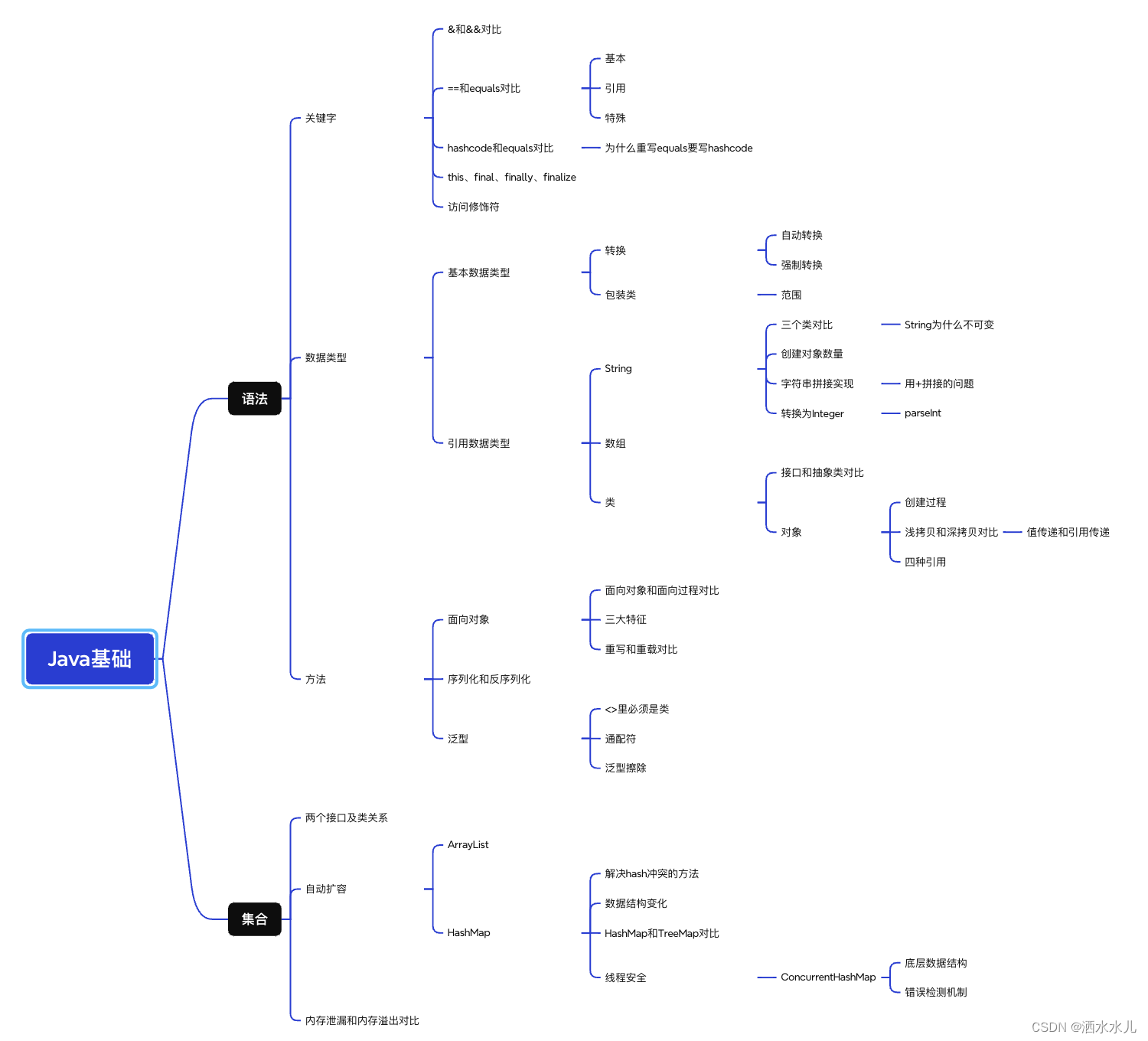
细节研究
JDK和JRE
JDK(Java Development Kit),它是功能齐全的 Java SDK,是提供给开发者使用,能够创建和编译 Java 程序的开发套件。它包含了 JRE,同时还包含了编译 java 源码的编译器 javac 以及一些其他工具比如 javadoc(文档注释工具)、jdb(调试器)、jconsole(基于 JMX 的可视化监控⼯具)、javap(反编译工具)等等。
JRE(Java Runtime Environment) 是 Java 运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,主要包括 Java 虚拟机(JVM)、Java 基础类库(Class Library)。
不过,从 JDK 9 开始,就不需要区分 JDK 和 JRE 的关系了,取而代之的是模块系统(JDK 被重新组织成 94 个模块)+ jlinkopen in new window 工具 (随 Java 9 一起发布的新命令行工具,用于生成自定义 Java 运行时映像,该映像仅包含给定应用程序所需的模块) 。并且,从 JDK 11 开始,Oracle 不再提供单独的 JRE 下载。
编译型和解释型
我们可以将高级编程语言按照程序的执行方式分为两种:
- 编译型: 会通过编译器open in new window将源代码一次性翻译成可被该平台执行的机器码。一般情况下,编译语言的执行速度比较快,开发效率比较低。常见的编译性语言有 C、C++、Go、Rust 等等。
- 解释型:解释型语言open in new window会通过解释器open in new window一句一句的将代码解释(interpret)为机器代码后再执行。解释型语言开发效率比较快,执行速度比较慢。常见的解释性语言有 Python、JavaScript、PHP 等等。
Java 语言既具有编译型语言的特征,也具有解释型语言的特征。因为 Java 程序要经过先编译,后解释两个步骤,由 Java 编写的程序需要先经过编译步骤,生成字节码(.class 文件),这种字节码必须由 Java 解释器来解释执行。
JDK 9 引入了一种新的编译模式 AOT(Ahead of Time Compilation) 。和 JIT 不同的是,这种编译模式会在程序被执行前就将其编译成机器码,属于静态编译(C、 C++,Rust,Go 等语言就是静态编译)。AOT 避免了 JIT 预热等各方面的开销,可以提高 Java 程序的启动速度,避免预热时间长。并且,AOT 还能减少内存占用和增强 Java 程序的安全性(AOT 编译后的代码不容易被反编译和修改),特别适合云原生场景。
关键字
default 这个关键字很特殊,既属于程序控制,也属于类,方法和变量修饰符,还属于访问控制。
- 在程序控制中,当在
switch中匹配不到任何情况时,可以使用default来编写默认匹配的情况。 - 在类,方法和变量修饰符中,从 JDK8 开始引入了默认方法,可以使用
default关键字来定义一个方法的默认实现。实际主要用于接口中。它允许在接口中定义具有实现体的方法,即默认方法。这样,实现接口的类可以不用实现这些默认方法。
interface MyInterface {// 默认方法default void defaultMethod() {System.out.println("这是一个默认方法");}// 抽象方法void regularMethod();
}class MyClass implements MyInterface {// 实现抽象方法public void regularMethod() {System.out.println("实现了抽象方法");}
}- 在访问控制中,如果一个方法前没有任何修饰符,则默认会有一个修饰符
default,但是这个修饰符加上了就会报错。
native关键字用于表示一个方法的实现是由本地(Native)代码提供的,而不是由Java代码实现的。当一个方法被声明为native时,它的实现将由外部的非Java代码提供。
通常情况下,native方法是用来调用底层操作系统或其他外部库的功能。这样的方法可以让Java程序与底层系统进行交互,执行一些特定的操作,比如访问硬件设备、调用C/C++编写的库等。要声明一个native方法,只需在方法定义中使用native关键字,不需要提供具体的实现。
public class NativeExample {// 声明一个native方法public native void nativeMethod();
}
然后,需要使用Java Native Interface(JNI)来提供这个native方法的实现。JNI允许Java代码与本地代码(如C或C++代码)进行交互,使得Java程序可以调用本地方法并获得本地方法的返回值。要使用JNI,需要在本地代码中实现native方法,并将其编译成与Java程序兼容的动态链接库(.dll文件或.so文件)。然后,通过Java代码加载本地库,并调用其中的native方法。
需要注意的是,使用native方法会牺牲一些Java的特性,比如跨平台性和安全性,因为本地方法的行为取决于底层操作系统和硬件平台。因此,应该谨慎使用native方法,并确保在必要时进行适当的安全性和跨平台性检查。
strictfp关键字用于声明在类、接口或方法中的浮点运算采用严格的浮点计算规则。这个关键字主要用于确保浮点运算在不同的平台上产生相同的结果,以保证Java程序的可移植性。
当一个类被声明为strictfp时,该类中所有的方法以及其中的内部类都将使用严格的浮点计算规则执行。如果一个方法被声明为strictfp,那么该方法中所有的浮点运算都会使用严格的浮点计算规则。
strictfp关键字通常用于确保在进行浮点计算时,不会因为底层硬件或编译器的不同而导致结果不一致。这对于需要高精度计算或涉及金融、科学计算等领域的程序特别重要。
transient关键字用于修饰类的成员变量。当一个成员变量被声明为transient时,它表示该变量不参与序列化过程。
在Java中,序列化是将对象转换为字节流的过程,以便将其保存到文件、数据库或通过网络传输。而反序列化则是将字节流重新转换为对象的过程。通过序列化和反序列化,可以在不同的Java虚拟机之间或不同的应用程序之间传输对象。
然而,并非所有的成员变量都适合被序列化。例如,一些敏感信息(如密码)、临时数据(如计算结果)、线程相关数据等,可能不希望被序列化和传输。在这种情况下,可以使用transient关键字来标记这些变量,使其在序列化过程中被忽略。
import java.io.*;class MyClass implements Serializable {// 使用transient关键字声明不希望被序列化的成员变量transient int sensitiveData;int normalData;public MyClass(int sensitiveData, int normalData) {this.sensitiveData = sensitiveData;this.normalData = normalData;}
}public class Main {public static void main(String[] args) throws Exception {MyClass obj = new MyClass(10, 20);// 将对象序列化到文件ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("data.ser"));out.writeObject(obj);out.close();// 从文件中反序列化对象ObjectInputStream in = new ObjectInputStream(new FileInputStream("data.ser"));MyClass newObj = (MyClass) in.readObject();in.close();// 输出结果System.out.println("Sensitive Data: " + newObj.sensitiveData); // 序列化时被忽略System.out.println("Normal Data: " + newObj.normalData);}
}
在这个例子中,sensitiveData被声明为transient,因此它在序列化过程中将被忽略。只有normalData会被序列化和反序列化。
synchronized关键字,用于实现线程同步,确保多个线程之间对共享资源的访问是安全的。
synchronized关键字可以用来修饰方法或代码块,其作用的范围可以是一个方法,一个对象或者一个类。它有以下几个主要特点:
-
互斥性(Mutual Exclusion):
synchronized确保了同一时间只有一个线程可以执行被synchronized修饰的代码块或方法。当一个线程获得了某个对象的锁之后,其他线程必须等待该线程释放锁之后才能继续执行。 -
可重入性(Reentrancy):Java中的锁是可重入的,即同一个线程可以多次获得同一个锁,而不会发生死锁。这种机制可以避免在同一个线程中调用被
synchronized修饰的方法或代码块时发生阻塞。 -
内存可见性(Memory Visibility):
synchronized关键字不仅保证了代码的互斥执行,还保证了共享变量的修改对所有线程的可见性。即当一个线程释放锁时,它所做的修改将对其他线程可见。
使用synchronized的两种方式:
- 同步方法(Synchronized Method):在方法声明中使用
synchronized关键字修饰,确保整个方法的执行是线程安全的。
public synchronized void synchronizedMethod() {// 该方法的代码块是线程安全的
}
- 同步代码块(Synchronized Block):在代码块内部使用
synchronized关键字,指定一个对象作为锁,确保只有持有该锁的线程才能执行该代码块。
public void someMethod() {synchronized (lockObject) {// 该代码块是线程安全的}
}
需要注意的是,过度使用synchronized可能会造成性能问题,因为每次都要获取锁可能会导致线程竞争和线程阻塞。在Java 5之后,Java提供了更加灵活高效的并发工具,如ReentrantLock、ReadWriteLock和Semaphore等,可以更好地管理并发访问。
volatile是Java中的一个关键字。当一个变量被volatile修饰时,表示这个变量可能会被多个线程同时修改,因此在进行读取和写入操作时,会有特殊的内存语义。
具体来说,volatile有以下特性:
-
可见性(Visibility):
volatile保证了变量的修改对所有线程可见。当一个线程修改了volatile变量的值后,这个新值会立即被其他线程看到,即使这些线程使用的是不同的CPU缓存。 -
禁止指令重排序(Prevents Reordering):
volatile变量的读写操作禁止了指令重排序,这意味着volatile修饰的变量的赋值操作总是发生在任何后续的读操作之前。 -
不保证原子性(No Atomicity Guarantee):
volatile修饰的变量并不具备原子性。如果多个线程同时对一个volatile变量进行写操作,最终结果可能与预期不符。
volatile关键字通常用于两种情况:
-
状态标记(Status Flags):当一个变量用于标记程序的状态(例如线程是否终止、任务是否完成等),并且多个线程需要协调执行的时候,可以使用
volatile来确保状态的可见性。 -
双重检查锁(Double-Checked Locking):在单例模式等场景下,为了确保线程安全且避免不必要的同步开销,可以使用双重检查锁定模式(Double-Checked Locking Pattern),在其中的单例对象引用上使用
volatile关键字。
需要注意的是,虽然volatile能够确保变量的可见性,但它并不能替代synchronized关键字,因为volatile并不能保证复合操作的原子性。在需要进行复合操作的情况下,仍然需要考虑使用synchronized关键字或者java.util.concurrent包提供的原子类。
instanceof是Java中的一个关键字,用于检查对象是否是特定类的实例,或者是否实现了特定接口。
instanceof的语法形式为:
object instanceof ClassName
assert用于在代码中添加断言。它通常用于在开发和测试阶段验证程序的假设,帮助检测错误和调试程序。
assert语句的语法形式为:
assert condition : expression;其中,condition是一个布尔表达式,如果为true,则程序继续执行;如果为false,则抛出AssertionError异常。可选的expression用于在抛出异常时提供详细的错误信息。
在Java中,默认情况下,断言是禁用的。要启用断言,可以使用-ea或-enableassertions选项运行Java程序。
public void process(int value) {assert value > 0 : "Value must be positive";// 继续执行方法
}
在这个例子中,如果传入的value不大于0,断言条件将失败,并抛出一个带有指定错误消息的AssertionError异常。
包装类
对于基本数据类型来说,== 比较的是值。对于包装数据类型来说,== 比较的是对象的内存地址。所有整型包装类对象之间值的比较,全部使用 equals() 方法。
在Java中,为了提高性能和节省内存,一些包装类实现了缓存机制。具体来说,对于Boolean、Byte、Character、Short和Integer这几个包装类,Java在内部维护了一个缓存池,用于存储在特定范围内的对象实例。这个范围通常是在-128到127之间(可以通过Java虚拟机参数进行调整),对于Boolean类型则是true和false两个实例。
当使用自动装箱时,如果装箱的值在缓存范围内,Java将返回缓存中的实例,而不是创建一个新的对象。这样可以节省内存并提高性能,因为不需要为常见的数值频繁创建新的对象。
两种浮点数类型的包装类 Float,Double 并没有实现缓存机制。
变量
成员变量和局部变量对比
- 语法形式:从语法形式上看,成员变量是属于类的,而局部变量是在代码块或方法中定义的变量或是方法的参数;成员变量可以被
public,private,static等修饰符所修饰,而局部变量不能被访问控制修饰符及static所修饰;但是,成员变量和局部变量都能被final所修饰。 - 存储方式:从变量在内存中的存储方式来看,如果成员变量是使用
static修饰的,那么这个成员变量是属于类的,如果没有使用static修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。 - 生存时间:从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动生成,随着方法的调用结束而消亡。
- 默认值:从变量是否有默认值来看,成员变量如果没有被赋初始值,则会自动以类型的默认值而赋值(一种情况例外:被
final修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。
为什么成员变量有默认值?
-
先不考虑变量类型,如果没有默认值会怎样?变量存储的是内存地址对应的任意随机值,程序读取该值运行会出现意外。
-
默认值有两种设置方式:手动和自动,根据第一点,没有手动赋值一定要自动赋值。成员变量在运行时可借助反射等方法手动赋值,而局部变量不行。
-
对于编译器(javac)来说,局部变量没赋值很好判断,可以直接报错。而成员变量可能是运行时赋值,无法判断,误报“没默认值”又会影响用户体验,所以采用自动赋默认值。
静态变量
静态变量也就是被 static 关键字修饰的变量。它可以被类的所有实例共享,无论一个类创建了多少个对象,它们都共享同一份静态变量。也就是说,静态变量只会被分配一次内存,即使创建多个对象,这样可以节省内存。
静态变量是通过类名来访问的,例如StaticVariableExample.staticVar(如果被 private关键字修饰就无法这样访问了)
通常情况下,静态变量会被 final 关键字修饰成为常量。
方法
静态方法不能调用非静态成员,这个需要结合 JVM 的相关知识,主要原因如下:
- 静态方法是属于类的,在类加载的时候就会分配内存,可以通过类名直接访问。而非静态成员属于实例对象,只有在对象实例化之后才存在,需要通过类的实例对象去访问。
- 在类的非静态成员不存在的时候静态方法就已经存在了,此时调用在内存中还不存在的非静态成员,属于非法操作。
重载和重写:
重载就是同样的一个方法能够根据输入数据的不同,做出不同的处理
重写就是当子类继承自父类的相同方法,输入数据一样,但要做出有别于父类的响应时,你就要覆盖父类方法
方法的重写要遵循“两同两小一大”
- “两同”即方法名相同、形参列表相同;
- “两小”指的是子类方法返回值类型应比父类方法返回值类型更小或相等,子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等;
- “一大”指的是子类方法的访问权限应比父类方法的访问权限更大或相等。
面向对象
new 运算符,new 创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象引用存放在栈内存中)。
- 一个对象引用可以指向 0 个或 1 个对象(一根绳子可以不系气球,也可以系一个气球);
- 一个对象可以有 n 个引用指向它(可以用 n 条绳子系住一个气球)。
关于继承如下 3 点请记住:
- 子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,只是拥有。
- 子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
- 子类可以用自己的方式实现父类的方法。
多态的特点:
- 对象类型和引用类型之间具有继承(类)/实现(接口)的关系;
- 引用类型变量发出的方法调用的到底是哪个类中的方法,必须在程序运行期间才能确定;
- 多态不能调用“只在子类存在但在父类不存在”的方法;
- 如果子类重写了父类的方法,真正执行的是子类覆盖的方法,如果子类没有覆盖父类的方法,执行的是父类的方法。
深拷贝和浅拷贝区别:
- 浅拷贝:浅拷贝会在堆上创建一个新的对象(区别于引用拷贝的一点),不过,如果原对象内部的属性是引用类型的话,浅拷贝会直接复制内部对象的引用地址,也就是说拷贝对象和原对象共用同一个内部对象。
- 深拷贝:深拷贝会完全复制整个对象,包括这个对象所包含的内部对象。
==和equals区别:
== 对于基本类型和引用类型的作用效果是不同的:
- 对于基本数据类型来说,
==比较的是值。 - 对于引用数据类型来说,
==比较的是对象的内存地址。
因为 Java 只有值传递,所以,对于 == 来说,不管是比较基本数据类型,还是引用数据类型的变量,其本质比较的都是值,只是引用类型变量存的值是对象的地址。
equals() 方法存在两种使用情况:
- 类没有重写
equals()方法:通过equals()比较该类的两个对象时,等价于通过“==”比较这两个对象,使用的默认是Object类equals()方法。 - 类重写了
equals()方法:一般我们都重写equals()方法来比较两个对象中的属性是否相等;若它们的属性相等,则返回 true(即,认为这两个对象相等)。
为什么重写 equals() 时必须重写 hashCode() 方法?
因为两个相等的对象的 hashCode 值必须是相等。也就是说如果 equals 方法判断两个对象是相等的,那这两个对象的 hashCode 值也要相等。
如果重写 equals() 时没有重写 hashCode() 方法的话就可能会导致 equals 方法判断是相等的两个对象,hashCode 值却不相等。
三个字符串类
线程安全性
String 中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
性能
每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
对于三者使用的总结:
- 操作少量的数据: 适用
String - 单线程操作字符串缓冲区下操作大量数据: 适用
StringBuilder - 多线程操作字符串缓冲区下操作大量数据: 适用
StringBuffer
异常
不要在 finally 语句块中使用 return! 当 try 语句和 finally 语句中都有 return 语句时,try 语句块中的 return 语句会被忽略。这是因为 try 语句中的 return 返回值会先被暂存在一个本地变量中,当执行到 finally 语句中的 return 之后,这个本地变量的值就变为了 finally 语句中的 return 返回值。
面对必须要关闭的资源,我们总是应该优先使用
try-with-resources而不是try-finally。随之产生的代码更简短,更清晰,产生的异常对我们也更有用。try-with-resources语句让我们更容易编写必须要关闭的资源的代码,若采用try-finally则几乎做不到这点。
Java 中类似于InputStream、OutputStream、Scanner、PrintWriter等的资源都需要我们调用close()方法来手动关闭,一般情况下我们都是通过try-catch-finally语句来实现这个需求,如下:
//读取文本文件的内容
Scanner scanner = null;
try {scanner = new Scanner(new File("D://read.txt"));while (scanner.hasNext()) {System.out.println(scanner.nextLine());}
} catch (FileNotFoundException e) {e.printStackTrace();
} finally {if (scanner != null) {scanner.close();}
}








--创建新主题)



)






