opencv介绍
OpenCV的全称是Open Source Computer Vision Library,是一个跨平台的计算机视觉库。OpenCV是由英特尔公司发起并参与开发,以BSD许可证授权发行,可以在商业和研究领域中免费使用。OpenCV可用于开发实时的图像处理、计算机视觉以及模式识别程序。该程序库也可以使用英特尔公司的IPP进行加速处理。
读取图片
opoencv提供相应的函数方便我们读取相关图片,打开并展示他
#导入cv模块
import cv2 as cv
#读取图片
img = cv.imread('face1.jpg')
#显示图片
cv.imshow('read_img',img)
#等待
cv.waitKey(0)
#释放内存
cv.destroyAllWindows()
灰度转换
首先我们介绍一下灰度图像,看看他的定义:
在电子计算机领域中,灰度(Gray scale)数字图像是每个像素只有一个采样颜色的图像。这类图像通常显示为从最暗黑色到最亮的白色的灰度,尽管理论上这个采样可以是任何颜色的不同深浅,甚至可以是不同亮度上的不同颜色。灰度图像与黑白图像不同,在计算机图像领域中黑白图像只有黑白两种颜色,灰度图像在黑色与白色之间还有许多级的颜色深度。
通俗的讲灰度图像就是把每个像素只有一个颜色的图像,一般来讲都是黑白;那么我们为什么需要将普通图像转化为灰度图像呢?
因为彩色图像中的每个像素颜色由R、G、B三个分量来决定,而每个分量的取值范围都在0-255之间,这样对计算机来说,彩色图像的一个像素点就会有256256256=16777216种颜色的变化范围;而灰度图像是R、G、B分量相同的一种特殊彩色图像,对计算机来说,一个像素点的变化范围只有0-255这256种。彩色图片的信息含量过大,而进行图片识别时,其实只需要使用灰度图像里的信息就足够了,所以图像灰度化的目的就是为了提高运算速度。
当然,有时图片进行了灰度处理后还是很大,也有可能会采用二值化图像(即像素值只能为0或1)。
我们可以通过调用opencv的函数库来实现灰度的转化
#导入cv模块
import cv2 as cv
#读取图片
img = cv.imread('face1.jpg')
#灰度转换
gray_img = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
#显示灰度图片
cv.imshow('gray',gray_img)
#保存灰度图片
cv.imwrite('gray_face1.jpg',gray_img)
#显示图片
cv.imshow('read_img',img)
#等待
cv.waitKey(0)
#释放内存
cv.destroyAllWindows()
修改尺寸
除了灰度转化的函数,opencv还为我们提供了图像修改相关的函数,这里简单介绍下
#导入cv模块
import cv2 as cv
#读取图片
img = cv.imread('face1.jpg')
#修改尺寸
resize_img = cv.resize(img,dsize=(200,200))
#显示原图
cv.imshow('img',img)
#显示修改后的
cv.imshow('resize_img',resize_img)
#打印原图尺寸大小
print('未修改:',img.shape)
#打印修改后的大小
print('修改后:',resize_img.shape)
#等待
while True:if ord('q') == cv.waitKey(0):break
#释放内存
cv.destroyAllWindows()
绘制矩形
在识别到我们想识别的物体后,需要用矩形将他绘制出来,我们这里提供一下相关的函数接口
#导入cv模块
import cv2 as cv
#读取图片
img = cv.imread('face1.jpg')
#坐标
x,y,w,h = 100,100,100,100
#绘制矩形
cv.rectangle(img,(x,y,x+w,y+h),color=(0,0,255),thickness=1)
#绘制圆形
cv.circle(img,center=(x+w,y+h),radius=100,color=(255,0,0),thickness=5)
#显示
cv.imshow('re_img',img)
while True:if ord('q') == cv.waitKey(0):break
#释放内存
cv.destroyAllWindows()
猫脸检测
我们这里用到opencv自带的文件来构建我们的检测模型,从而从图像上迅速识别到猫脸,以下代码是用的人脸识别的文件,如果要做测试可以把 haarcascade_frontalface_alt2.xml 换成猫脸相关的xml文件
#导入cv模块
import cv2 as cv
#检测函数
def face_detect_demo():gary = cv.cvtColor(img,cv.COLOR_BGR2GRAY)face_detect = cv.CascadeClassifier(r'C:\Users\33718\Desktop\face\opencv\data\haarcascades\haarcascade_frontalface_alt2.xml')face = face_detect.detectMultiScale(gary,1.01,5,0,(100,100),(300,300))for x,y,w,h in face:cv.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)cv.imshow('result',img)#读取图像
img = cv.imread(r'C:\Users\33718\Desktop\face\opencv\data\jm\1.lena.jpg')
#检测函数
face_detect_demo()
#等待
while True:if ord('q') == cv.waitKey(0):break
#释放内存
cv.destroyAllWindows()
训练数据
我们事先准备数据,并且按照如下格式命名:
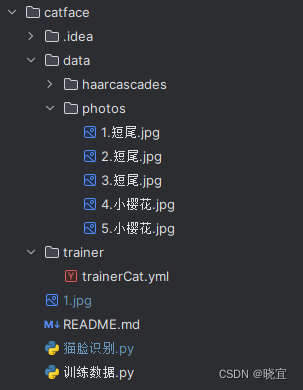
然后我们运行以下代码,就能获得一个训练好的yml文件
import os
import cv2
import sys
from PIL import Image
import numpy as npdef getImageAndLabels(path):facesSamples=[]ids=[]imagePaths=[os.path.join(path,f) for f in os.listdir(path)]#检测猫脸face_detector = cv2.CascadeClassifier('C:/Users/33718/Desktop/face/catface/data/haarcascades/haarcascade_frontalcatface_extended.xml')#打印数组imagePathsprint('数据排列:',imagePaths)#遍历列表中的图片for imagePath in imagePaths:#打开图片,黑白化PIL_img=Image.open(imagePath).convert('L')#将图像转换为数组,以黑白深浅# PIL_img = cv2.resize(PIL_img, dsize=(400, 400))img_numpy=np.array(PIL_img,'uint8')#获取图片人脸特征faces = face_detector.detectMultiScale(img_numpy)#获取每张图片的id和姓名id = int(os.path.split(imagePath)[1].split('.')[0])#预防无面容照片for x,y,w,h in faces:ids.append(id)facesSamples.append(img_numpy[y:y+h,x:x+w])#打印脸部特征和id#print('fs:', facesSamples)print('id:', id)# print('fs:', facesSamples[id])print('fs:', facesSamples)#print('脸部例子:',facesSamples[0])#print('身份信息:',ids[0])return facesSamples,idsif __name__ == '__main__':#图片路径path='./data/photos/'#获取图像数组和id标签数组和姓名faces,ids=getImageAndLabels(path)#获取训练对象recognizer=cv2.face.LBPHFaceRecognizer_create()#recognizer.train(faces,names)#np.array(ids)recognizer.train(faces,np.array(ids))#保存文件recognizer.write('trainer/trainerCat.yml')#save_to_file('names.txt',names)
猫脸检测
最后我们就可以检测猫猫的图像了,以下是效果图:

import cv2
import numpy as np
import os
# coding=utf-8
import urllib
import urllib.request
import hashlib#加载训练数据集文件
recogizer=cv2.face.LBPHFaceRecognizer_create()
recogizer.read('trainer/trainerCat.yml')
names=[]
warningtime = 0from PIL import Image, ImageDraw, ImageFont
def cv2ImgAddText(img, text, left, top, textColor=(0, 255, 0), textSize=20):if (isinstance(img, np.ndarray)): # 判断是否OpenCV图片类型img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))# 创建一个可以在给定图像上绘图的对象draw = ImageDraw.Draw(img)# 字体的格式fontStyle = ImageFont.truetype("STSONG.TTF", textSize, encoding="utf-8")# 绘制文本draw.text((left, top), text, textColor, font=fontStyle)# 转换回OpenCV格式return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)#准备识别的图片
def face_detect_demo(img):gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#转换为灰度# 这里要写绝对路径face_detector=cv2.CascadeClassifier('C:/Users/33718/Desktop/face/catface/data/haarcascades/haarcascade_frontalcatface_extended.xml')# face=face_detector.detectMultiScale(gray,1.1,5,cv2.CASCADE_SCALE_IMAGE,(100,100),(300,300))face=face_detector.detectMultiScale(gray,1.1,5,cv2.CASCADE_SCALE_IMAGE,)#face=face_detector.detectMultiScale(gray)for x,y,w,h in face:cv2.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)cv2.circle(img,center=(x+w//2,y+h//2),radius=w//2,color=(0,255,0),thickness=1)# 人脸识别ids, confidence = recogizer.predict(gray[y:y + h, x:x + w])#print('标签id:',ids,'置信评分:', confidence)if confidence < 60:global warningtimewarningtime += 1if warningtime > 100:# warning()warningtime = 0cv2.putText(img, 'unkonw', (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)else:img = cv2ImgAddText(img, str(names[ids-1]), x + 10, y - 10, (255, 0, 0), 30)# cv2.putText(img,str(names[ids-1]), (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)cv2.imshow('result',img)#print('bug:',ids)def name():path = './data/photos/'#names = []imagePaths=[os.path.join(path,f) for f in os.listdir(path)]for imagePath in imagePaths:name = str(os.path.split(imagePath)[1].split('.',2)[1])names.append(name)name()# 摄像头检测
# cap=cv2.VideoCapture(0)
# cap = cv2.VideoCapture('1.mp4')
# while True:
# flag,frame=cap.read()
# if not flag:
# break
# face_detect_demo(frame)
# if ord(' ') == cv2.waitKey(10):
# breakframe = cv2.imread('1.jpg')
while True:# 调用人脸检测函数face_detect_demo(frame)# 等待按键或者一段时间后继续下一次循环if cv2.waitKey(1) & 0xFF == ord('q'):break
源码链接
GitHub
Gitee
🌈🌈🌈
如果对各位看官有帮助,还请看官们点个关注,阿里嘎多~
🌙🌙🌙
代码的路径要换成你自己的绝对路径,opencv的函数只能识别绝对路径,起码我的版本是这样。





)












)
![2024-04-03-代码随想录算法训练营第一天[LeetCode704二分查找、LeetCode27移除元素]](http://pic.xiahunao.cn/2024-04-03-代码随想录算法训练营第一天[LeetCode704二分查找、LeetCode27移除元素])