文章目录
- 1、网卡接受数据
- 2、网络设备层接收数据
- 3、ip层接受数据
- 4、tcp层接受数据
- 5、上层应用读取数据
- 6、数据从网卡到应用层的整体流程
1、网卡接受数据
当网卡收到数据时,会触发一个中断,然后就会调用对应的中断处理函数,再做进一步处理。
以DM9000驱动为例
static irqreturn_t dm9000_interrupt(int irq, void *dev_id)
{struct net_device *dev = dev_id;struct board_info *db = netdev_priv(dev);int int_status;unsigned long flags;u8 reg_save;dm9000_dbg(db, 3, "entering %s\n", __func__);/* 1. 开启自旋锁 */spin_lock_irqsave(&db->lock, flags);/* 2. 保存当前中断寄存器的值 */reg_save = readb(db->io_addr);/* 3. 中断屏蔽(操作DM9000的IMR寄存器,屏蔽所有中断) */dm9000_mask_interrupts(db);/* 4. 获取dm9000的中断状态寄存器(ISR),判断是什么操作触发了中断 */int_status = ior(db, DM9000_ISR); iow(db, DM9000_ISR, int_status); if (netif_msg_intr(db))dev_dbg(db->dev, "interrupt status %02x\n", int_status);/* 检测是否是接收数据时的中断 */if (int_status & ISR_PRS)dm9000_rx(dev);/* 检测是否数据包发送完成的中断 */if (int_status & ISR_PTS)dm9000_tx_done(dev, db);/* 检测是否连接状态发生的中断 */if (db->type != TYPE_DM9000E){if (int_status & ISR_LNKCHNG){schedule_delayed_work(&db->phy_poll, 1); // 启动网卡连接检测}}/* 5. 解除中断屏蔽 */dm9000_unmask_interrupts(db);/* 6. 恢复中断处理前中断寄存器的值 */writeb(reg_save, db->io_addr);/* 7. 解除自旋锁 */spin_unlock_irqrestore(&db->lock, flags);return IRQ_HANDLED;
}
如果有数据到来,就会调用dm9000_rx函数
static void
dm9000_rx(struct net_device *dev)
{struct board_info *db = netdev_priv(dev);struct dm9000_rxhdr rxhdr;//用于描述DM9000数据包结构体,即包头结构体struct sk_buff *skb;u8 rxbyte, *rdptr;//rxbyte存放网络控制器状态,rdptr存放读取数据包bool GoodPacket;int RxLen;//存放接收数据包的长度//该循环会读取DM9000的DM9000_PKT_RDY,检测是否还有准备读取的数据包,如果没有则循环结束do {/* 1. 先读取第一个字节,如果不为DM9000_PKT_RDY,则说明数据包未准备好,则跳出循环 */ior(db, DM9000_MRCMDX); /* Get most updated data *//* 2. 读取网络控制器状态 */rxbyte = readb(db->io_data);/* 3. 判断状态是否正确 */if (rxbyte & DM9000_PKT_ERR) {dev_warn(db->dev, "status check fail: %d\n", rxbyte);iow(db, DM9000_RCR, 0x00); /* Stop Device */return;}/* 4. 检测是否有数据需要读取 */if (!(rxbyte & DM9000_PKT_RDY))return;GoodPacket = true;/* 5. 向控制器发起读命令 */writeb(DM9000_MRCMD, db->io_addr);/* 6.读取包头,网卡数据包的前四个字节(有效标志、接收状态、数据长度。 把他们存在结构体rxhdr中) */(db->inblk)(db->io_data, &rxhdr, sizeof(rxhdr));RxLen = le16_to_cpu(rxhdr.RxLen);if (netif_msg_rx_status(db))dev_dbg(db->dev, "RX: status %02x, length %04x\n",rxhdr.RxStatus, RxLen);/* 7. 判断数据包是否小于64字节,正常情况小于64字节会填充到64字节,小于则是损坏的包 */if (RxLen < 0x40) {GoodPacket = false;if (netif_msg_rx_err(db))dev_dbg(db->dev, "RX: Bad Packet (runt)\n");}/* 8. 判断数据包是否超过1536字节,不能超过RAM大小 */if (RxLen > DM9000_PKT_MAX) {dev_dbg(db->dev, "RST: RX Len:%x\n", RxLen);}/* 9. 检查接收状态是否出错 *//** RSR_FOE: 表示接收时发生了帧溢出错误。* RSR_CE: 表示接收时发生了 CRC 错误。* RSR_AE: 表示接收时发生了地址错误。* RSR_PLE: 表示接收时发生了数据包长度错误。* RSR_RWTO: 表示接收时发生了读等待超时错误。* RSR_LCS: 表示链路状态改变。* RSR_RF: 表示接收到了数据帧*/if (rxhdr.RxStatus & (RSR_FOE | RSR_CE | RSR_AE |RSR_PLE | RSR_RWTO |RSR_LCS | RSR_RF)) {GoodPacket = false;//FIFO 错误if (rxhdr.RxStatus & RSR_FOE) {if (netif_msg_rx_err(db))dev_dbg(db->dev, "fifo error\n");dev->stats.rx_fifo_errors++;}//CRC 错误if (rxhdr.RxStatus & RSR_CE) {if (netif_msg_rx_err(db))dev_dbg(db->dev, "crc error\n");dev->stats.rx_crc_errors++;}//包长度错误if (rxhdr.RxStatus & RSR_RF) {if (netif_msg_rx_err(db))dev_dbg(db->dev, "length error\n");dev->stats.rx_length_errors++;}}/* 10.如果条件都满足,将网卡的RAM中数据包,拷到SK_BUFFER中,并通知上层协议栈取走SKB *//* 如果是一个好的数据包则分配skb内存,并且缓存足够时,将数据读入SK_BUFFER缓存中 */if (GoodPacket &&((skb = netdev_alloc_skb(dev, RxLen + 4)) != NULL)) {skb_reserve(skb, 2);rdptr = (u8 *) skb_put(skb, RxLen - 4);/* 从RX SRAM中读取接收到的数据包 */(db->inblk)(db->io_data, rdptr, RxLen);// 将网卡内部RAM的数据包读取到SKB中dev->stats.rx_bytes += RxLen;// 更新接收字节数统计/* 传递给上层协议栈 */skb->protocol = eth_type_trans(skb, dev);//把SKB数据包丢给上层协议栈if (dev->features & NETIF_F_RXCSUM) {if ((((rxbyte & 0x1c) << 3) & rxbyte) == 0)skb->ip_summed = CHECKSUM_UNNECESSARY;elseskb_checksum_none_assert(skb);}/* 这里通知上层协议栈取走解析后的SKB数据包 */netif_rx(skb);dev->stats.rx_packets++;} else {/* 需要丢弃数据包的数据 */(db->dumpblk)(db->io_data, RxLen);// 调用函数将数据包的数据从网卡内部RAM中丢弃}} while (rxbyte & DM9000_PKT_RDY);
}
2、网络设备层接收数据
netif_rx函数由常规非NAPI网络设备驱动程序在接受中断将数据包从设备缓冲区拷贝到内核空间后调用,他的主要任务是把数据帧添加到CPU的输入队列input_pkt_queue中。随后标记软中断来处理后续上传数据帧给TCP/IP协议栈
netif_rx实际调用netif_rx_internal
int netif_rx(struct sk_buff *skb)
{trace_netif_rx_entry(skb);return netif_rx_internal(skb);
}
netif_rx_internal的输入参数只有一个:存放网络设备接受到的数据帧Socket Buffer。如果数据帧成功放入到CPU的输入队列就返回NET_RX_SUCCESS;如果数据帧被扔掉就返回NET_RX_DROP
static int netif_rx_internal(struct sk_buff *skb)
{int ret;net_timestamp_check(netdev_tstamp_prequeue, skb);//设置数据包的时间trace_netif_rx(skb);
#ifdef CONFIG_RPS //RPS允许入栈的网络数据包分发给不同的cpu核心做处理,以提高网络吞吐量和并发处理能力//如果内核配置选项配置了 RPS,并且 开启了RPS,则通过get_rps_cpu获取合适的cpu,否则使用本地cpuif (static_key_false(&rps_needed)) {struct rps_dev_flow voidflow, *rflow = &voidflow;int cpu;preempt_disable();rcu_read_lock();//获取合适的cpucpu = get_rps_cpu(skb->dev, skb, &rflow);if (cpu < 0)cpu = smp_processor_id();ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail);rcu_read_unlock();preempt_enable();} else
#endif{unsigned int qtail;//无论是前一种方式还是这种方式,都会调用该函数做进一步处理ret = enqueue_to_backlog(skb, get_cpu(), &qtail);put_cpu();}return ret;
}
enueue_to_backlog主要做以下事情:
- 获取CPU的softnet_data
- 保存本地中断信息,并禁止本地中断
- 将skb添加到CPU的输入队列input_pkt_queue
- 恢复本地中断
- 如果CPU的输入队列input_pkt_queu为空,说明当前时收到第一个数据帧,应该标记软件中断,并且将backlog添加到poll_list中,backlog也就是初始化的process_backlog。如果CPU输入队列不为空说明当前已经标记过软件中断,只需要将数据帧加入到CPU的输入队列中
- 如果当前CPU输入队列已经满了,那么netif_rx就会扔掉数据帧,释放缓冲区只能用的内存空间,更行CPU的扔包统计信息
static int enqueue_to_backlog(struct sk_buff *skb, int cpu,unsigned int *qtail)
{struct softnet_data *sd;unsigned long flags;unsigned int qlen;//获取cpu的softnet_datasd = &per_cpu(softnet_data, cpu);//禁止本地CPU中断,并保存本地中断信息local_irq_save(flags);rps_lock(sd);//如果网卡不是running状态,直接丢掉if (!netif_running(skb->dev))goto drop;//如果队列中skb个数小于netdev_max_backlog(默认值//1000,可以通过sysctl修改netdev_max_backlog值),//并且 skb_flow_limit (为了防止large flow占用太多cpu,small //flow得不到处理。代码实现没看明白)返回false,则skb可以//继续入队,否则drop skb//获取cpu的struct softnet_data中的input_pkt_queue的大小,表示有多少个数据包qlen = skb_queue_len(&sd->input_pkt_queue);//如果队列中skb个数小于netdev_max_backlog(默认值1000,可以通过sysctl修改netdev_max_backlog值)//并且 skb_flow_limit返回false,则skb可以继续入队,否则drop skbif (qlen <= netdev_max_backlog && !skb_flow_limit(skb, qlen)) {//qlen不为0,表示input_pkt_queue中有数据,直接将skb入队列if (qlen) {
enqueue:__skb_queue_tail(&sd->input_pkt_queue, skb);input_queue_tail_incr_save(sd, qtail);rps_unlock(sd);local_irq_restore(flags);return NET_RX_SUCCESS;}//input_pkt_queue为空,即skb是第一个入队元素,则将state设置为 NAPI_STATE_SCHED(软中断处理函数//rx_net_action会检查此标志),表示软中断可以处理此if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) {//if返回0的情况下,需要将sd->backlog挂到sd->poll_list上,并激活软中断if (!rps_ipi_queued(sd))____napi_schedule(sd, &sd->backlog);}goto enqueue;}drop://丢弃的数据包数量加一sd->dropped++;rps_unlock(sd);local_irq_restore(flags);atomic_long_inc(&skb->dev->rx_dropped);//释放skb的内存kfree_skb(skb);return NET_RX_DROP;
}static inline void ____napi_schedule(struct softnet_data *sd,struct napi_struct *napi)
{//将struct napi_struct的poll_list添加到CPU的poll_list,cpu在调用数据接收软中断的处理函数net_rx_action,就会遍历poll_list,做对应的处理list_add_tail(&napi->poll_list, &sd->poll_list);__raise_softirq_irqoff(NET_RX_SOFTIRQ);//标记软件中断
}struct napi_struct {struct list_head poll_list;//双向链表头,用于将NAPI结构链接到CPU的轮询列表中unsigned long state;//这个字段存储了NAPI的状态信息。例如,它可以用来表示NAPI是否正在被轮询,或者是否有待处理的数据包。int weight;//用于NAPI轮询的权重unsigned int gro_count;//用于统计GRO处理的数据包数量int (*poll)(struct napi_struct *, int);//指向轮询函数的指针。这个函数会被调用来接收和处理数据包
#ifdef CONFIG_NETPOLLspinlock_t poll_lock;int poll_owner;
#endifstruct net_device *dev;//指向网络设备的指针,表示这个NAPI结构关联的设备struct sk_buff *gro_list;struct sk_buff *skb;//一个指向当前正在处理的数据包的指针struct hrtimer timer;//定时器,可以用于NAPI的定时轮询或超时处理struct list_head dev_list;//用于将NAPI结构链接到设备的NAPI列表中struct hlist_node napi_hash_node;unsigned int napi_id;
};
软中断激活后,cpu就会处理对应的软中断,数据接收软中断的处理函数net_rx_action
static __latent_entropy void net_rx_action(struct softirq_action *h)
{//获取percpu的softnet_datastruct softnet_data *sd = this_cpu_ptr(&softnet_data);//设置软中断处理程序一次允许的最大执行时间为2个jiffies(2个时钟中断时间)unsigned long time_limit = jiffies + 2;//设置软中断接收函数一次最多处理的报文(skb)个数为 300(netdev_budget为300)int budget = netdev_budget;LIST_HEAD(list);LIST_HEAD(repoll);//关闭本地cpu的中断,防止在初始化list时被硬中断抢占local_irq_disable();//将sd的poll_list迁移到list中list_splice_init(&sd->poll_list, &list);//打开本地cpu的中断local_irq_enable();//循环处理list(pool_list) 链表上的等待处理的napifor (;;) {struct napi_struct *n;//如果list为空,就返回if (list_empty(&list)) {if (!sd_has_rps_ipi_waiting(sd) && list_empty(&repoll))return;break;}//从list中获取struct napi_structn = list_first_entry(&list, struct napi_struct, poll_list);//调用napi_poll,内部会调用poll函数处理一定数量的skb,并且budeget需要减去这个数量//repoll就是还没处理的poll_listbudget -= napi_poll(n, &repoll);//如果读取的数量超过300,或则处理时间大于2 jiffies,则终止中断处理if (unlikely(budget <= 0 ||time_after_eq(jiffies, time_limit))) {sd->time_squeeze++;break;}}__kfree_skb_flush();local_irq_disable();//在处理软中断的时,可能会产生新的poll_list,因此需要将poll_list放到list中list_splice_tail_init(&sd->poll_list, &list);//再将repoll放到list中list_splice_tail(&repoll, &list);//最终再将list,放到struct softnet_data的poll_listlist_splice(&list, &sd->poll_list);if (!list_empty(&sd->poll_list))//如果poll list中不为空,表示还有skb没有读取完成,需要再次标记中断,下一次触发中断再处理这些数据__raise_softirq_irqoff(NET_RX_SOFTIRQ);net_rps_action_and_irq_enable(sd);
}
在napi_poll内部设置希望本次处理多少的skb数量,接着调用poll函数,从网卡驱动中读取一定数量的skb
static int napi_poll(struct napi_struct *n, struct list_head *repoll)
{void *have;int work, weight;//先将napi->poll_list删除list_del_init(&n->poll_list);have = netpoll_poll_lock(n);//希望本次处理的多少的skb数量weight = n->weight;//work表示实际处理的skb数量work = 0;if (test_bit(NAPI_STATE_SCHED, &n->state)) {work = n->poll(n, weight);//在这里调用驱动的poll函数,如果驱动有支持NAPI,会定义并初始化这个poll函数,默认的poll函数是process_backlogtrace_napi_poll(n, work, weight);}WARN_ON_ONCE(work > weight);//实际处理的skb数量<希望处理的skb数量,进入下一循环if (likely(work < weight))goto out_unlock;if (unlikely(napi_disable_pending(n))) {napi_complete(n);goto out_unlock;}//将希望处理的skb数量处理完成,将gro链表的age超过一个tick周期的skb上送协议栈if (n->gro_list) {napi_gro_flush(n, HZ >= 1000);}if (unlikely(!list_empty(&n->poll_list))) {pr_warn_once("%s: Budget exhausted after napi rescheduled\n",n->dev ? n->dev->name : "backlog");goto out_unlock;}//将希望处理的skb数量处理完成,如果还想处理,还需要继续poll,则将napi->poll_list重新加会到repolllist_add_tail(&n->poll_list, repoll);out_unlock:netpoll_poll_unlock(have);return work;
}
这里的poll函数是在内核初始化网路设备子系统时就将poll初始化好了
static int __init net_dev_init(void)
{int i, rc = -ENOMEM;BUG_ON(!dev_boot_phase);//初始化统计信息的proc文件if (dev_proc_init())goto out;//初始化kobjectif (netdev_kobject_init())goto out;//初始化协议类型链表INIT_LIST_HEAD(&ptype_all);//初始化协议类型hash表for (i = 0; i < PTYPE_HASH_SIZE; i++)INIT_LIST_HEAD(&ptype_base[i]);//初始化offload列表INIT_LIST_HEAD(&offload_base);//注册网络命名空间子系统if (register_pernet_subsys(&netdev_net_ops))goto out;//初始化每个cpu的数据包接收队列for_each_possible_cpu(i) {struct work_struct *flush = per_cpu_ptr(&flush_works, i);struct softnet_data *sd = &per_cpu(softnet_data, i);//初始化清理backlog队列INIT_WORK(flush, flush_backlog);//初始化非napi接口层的缓存队列skb_queue_head_init(&sd->input_pkt_queue);//初始化数据包处理队列skb_queue_head_init(&sd->process_queue);//初始化网络设备轮询队列INIT_LIST_HEAD(&sd->poll_list);//初始化输出队列尾部sd->output_queue_tailp = &sd->output_queue;
#ifdef CONFIG_RPSsd->csd.func = rps_trigger_softirq;sd->csd.info = sd;sd->cpu = i;
#endif//支持非napi虚拟设备的回调和配额设置sd->backlog.poll = process_backlog;sd->backlog.weight = weight_p;//64}dev_boot_phase = 0;//注册回环设备if (register_pernet_device(&loopback_net_ops))goto out;if (register_pernet_device(&default_device_ops))goto out;//注册发送软中断open_softirq(NET_TX_SOFTIRQ, net_tx_action);//注册接收软中断open_softirq(NET_RX_SOFTIRQ, net_rx_action);//向支持热拔插类型的CPU注册CPU改变通知链,当CPU被移除时,将被移除的CPU上//待处理的收发包队列转移到当前正在使用的CPU上工作 hotcpu_notifier(dev_cpu_callback, 0);//注册响应网络状态变化的回调dst_subsys_init();rc = 0;
out:return rc;
}
process_backlog函数内,会从缓冲队列读取skb,并交给上层协议栈进行处理
static int process_backlog(struct napi_struct *napi, int quota)
{struct softnet_data *sd = container_of(napi, struct softnet_data, backlog);bool again = true;int work = 0;//是否有rps ipi等待,如果是需要发送ipi中断给其他CPUif (sd_has_rps_ipi_waiting(sd)) {local_irq_disable();net_rps_action_and_irq_enable(sd);}napi->weight = weight_p;//设置每次处理的最大数据包数,默认为64while (again) {struct sk_buff *skb;//从缓存队列(process_queue)中取skb向上层输入,直到process队列处理完或者设备配额用完。while ((skb = __skb_dequeue(&sd->process_queue))) {rcu_read_lock();__netif_receive_skb(skb);//交给协议栈处理rcu_read_unlock();input_queue_head_incr(sd);if (++work >= quota)//如果处理报文数超过设备配额,则退出。 return work;//返回处理报文数量}local_irq_disable();rps_lock(sd);//input_pkt_queue为空,表示没有数据,again置为false,退出循环if (skb_queue_empty(&sd->input_pkt_queue)) {napi->state = 0;again = false;} else {//input_pkt_queue不为空,将input_pkt_queue移到process_queue中,而input_pkt_queue就为空了skb_queue_splice_tail_init(&sd->input_pkt_queue,&sd->process_queue);}rps_unlock(sd);local_irq_enable();}return work;
}
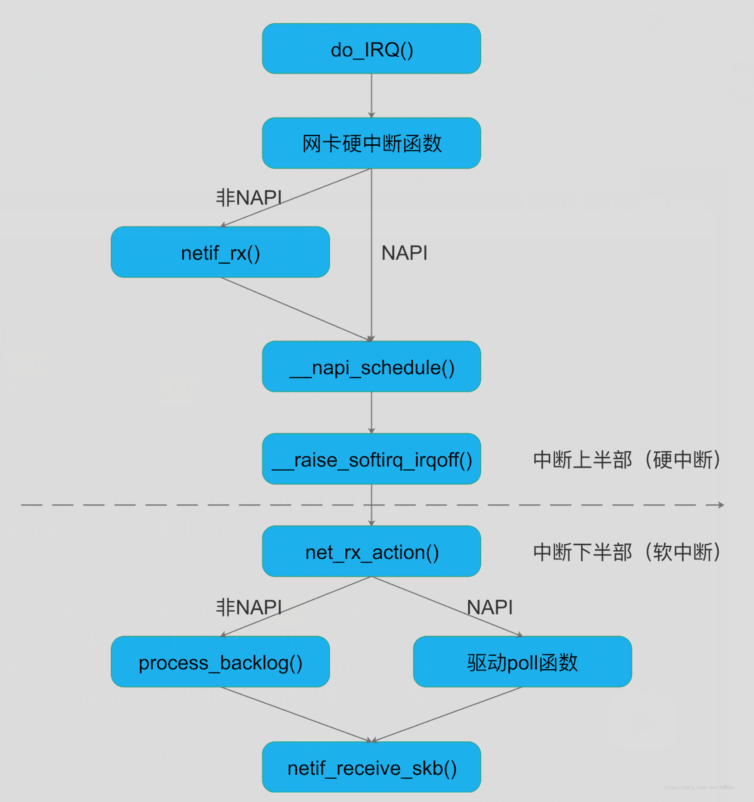
中断上半部做的事情非常简单,将数据读取出来,构建成一个skb,将skb放到cpu对应的struct softnet_data中的input_pkt_queue中,设置对应的软中断
而中断下半部做的事情就有些复杂了,因为它会将input_pkt_queue中的skb交给上层协议栈处理
接着分析__netif_receive_skb函数,它会将input_pkt_queue中的skb交给上层协议栈处理
static int __netif_receive_skb(struct sk_buff *skb)
{int ret;//检查当前系统的内存分配状态以及数据包是否标记为PF_MEMALLOCif (sk_memalloc_socks() && skb_pfmemalloc(skb)) {unsigned long pflags = current->flags;//PF_MEMALLOC是一个进程标志,它指示进程是否可以在内存紧张的情况下进行内存分配current->flags |= PF_MEMALLOC;ret = __netif_receive_skb_core(skb, true);tsk_restore_flags(current, pflags, PF_MEMALLOC);} elseret = __netif_receive_skb_core(skb, false);return ret;
}
无论是内存紧张还是不紧张,都会调用__netif_receive_skb_core函数
static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc)
{struct packet_type *ptype, *pt_prev;rx_handler_func_t *rx_handler;struct net_device *orig_dev;bool deliver_exact = false;int ret = NET_RX_DROP;__be16 type;//记录收包时间,netdev_tstamp_prequeue为0,表示可能有包延迟net_timestamp_check(!netdev_tstamp_prequeue, skb);trace_netif_receive_skb(skb);orig_dev = skb->dev;//重置network header,此时skb指向IP头skb_reset_network_header(skb);if (!skb_transport_header_was_set(skb))skb_reset_transport_header(skb);skb_reset_mac_len(skb);//skb->mac_header由驱动在调用eth_type_trans时设置pt_prev = NULL;another_round:skb->skb_iif = skb->dev->ifindex;//设置接收设备索引号 __this_cpu_inc(softnet_data.processed);//收包统计,可以通过/proc/net/softnet_stat查看//VLAN 报文处理if (skb->protocol == cpu_to_be16(ETH_P_8021Q) ||skb->protocol == cpu_to_be16(ETH_P_8021AD)) {skb = skb_vlan_untag(skb);if (unlikely(!skb))goto out;}#ifdef CONFIG_NET_CLS_ACTif (skb->tc_verd & TC_NCLS) {skb->tc_verd = CLR_TC_NCLS(skb->tc_verd);goto ncls;}
#endif//此类报文不允许ptype_all处理,即tcpdump也抓不到if (pfmemalloc)goto skip_taps;//适用于所有协议的特定于设备的数据包处理程序,paket_type.type 为 ETH_P_ALL,如tcpdump抓包list_for_each_entry_rcu(ptype, &ptype_all, list) {if (pt_prev)ret = deliver_skb(skb, pt_prev, orig_dev);pt_prev = ptype;}list_for_each_entry_rcu(ptype, &skb->dev->ptype_all, list) {if (pt_prev)ret = deliver_skb(skb, pt_prev, orig_dev);pt_prev = ptype;}skip_taps:
#ifdef CONFIG_NET_INGRESSif (static_key_false(&ingress_needed)) {skb = sch_handle_ingress(skb, &pt_prev, &ret, orig_dev);if (!skb)goto out;if (nf_ingress(skb, &pt_prev, &ret, orig_dev) < 0)goto out;}
#endif
#ifdef CONFIG_NET_CLS_ACTskb->tc_verd = 0;
ncls:
#endifif (pfmemalloc && !skb_pfmemalloc_protocol(skb))//不支持使用pfmemallocgoto drop;// 如果是vlan数据if (skb_vlan_tag_present(skb)) {if (pt_prev) {ret = deliver_skb(skb, pt_prev, orig_dev);pt_prev = NULL;}if (vlan_do_receive(&skb))goto another_round;else if (unlikely(!skb))goto out;}//如果一个dev被添加到一个bridge(做为bridge的一个接口),这个接口设备的rx_handler将被设置为br_handle_frame函数//这是在br_add_if函数中设置的,而br_add_if (net/bridge/br_if.c)是在向网桥设备上添加接口时设置的。进入br_handle_frame也就进入了bridge的逻辑代码rx_handler = rcu_dereference(skb->dev->rx_handler);//如果有注册handler,那么调用,比如网桥模块if (rx_handler) {if (pt_prev) {ret = deliver_skb(skb, pt_prev, orig_dev);pt_prev = NULL;}switch (rx_handler(&skb)) {//被rx_handler处理,不用在处理case RX_HANDLER_CONSUMED:ret = NET_RX_SUCCESS;goto out;//重新走一轮,skb->dev被rx_handler修改了case RX_HANDLER_ANOTHER:goto another_round;//精确传递:ptype->dev == skb->devcase RX_HANDLER_EXACT:deliver_exact = true;//什么都不做,就像没有调用rx_handler一样传递skbcase RX_HANDLER_PASS:break;default:BUG();}}//还有vlan标记,说明找不到vlanid对应的设备if (unlikely(skb_vlan_tag_present(skb))) {if (skb_vlan_tag_get_id(skb))skb->pkt_type = PACKET_OTHERHOST;/* 如果获取到vid,则将pkt_type设置为PACKET_OTHERHOST * PACKET_OTHERHOST:该帧目的地址不属于与该接口相匹配的地址,如果开启转发则转发,* 否则丢弃。vlan_tci值为0。*/skb->vlan_tci = 0;}//设置三层协议,下面提交都是按照三层协议提交的type = skb->protocol;//rx_handler没有设置精确处理if (likely(!deliver_exact)) {deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type,&ptype_base[ntohs(type) &PTYPE_HASH_MASK]);}//特定于设备、特定于协议的数据包处理程序deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type,&orig_dev->ptype_specific);//入口记录的skb_dev发生改变 if (unlikely(skb->dev != orig_dev)) {deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type,&skb->dev->ptype_specific);}if (pt_prev) {if (unlikely(skb_orphan_frags(skb, GFP_ATOMIC)))goto drop;else//向上层传递 ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev);} else {
drop:if (!deliver_exact)//统计网卡丢弃的数据包数atomic_long_inc(&skb->dev->rx_dropped);elseatomic_long_inc(&skb->dev->rx_nohandler);kfree_skb(skb);ret = NET_RX_DROP;}out:return ret;
}
3、ip层接受数据
最终根据不同的协议调用不同的函数做处理,例如以ipv4为例,pt_prev->func就会调用到ip_rcv
static struct packet_type ip_packet_type __read_mostly = {.type = cpu_to_be16(ETH_P_IP),.func = ip_rcv,
};int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{const struct iphdr *iph;struct net *net;u32 len;//丢弃掉不是发往本机的报文,网卡在混杂模式下会接收一切到达网卡的数据,不管目的地mac是否是本网卡if (skb->pkt_type == PACKET_OTHERHOST)goto drop;net = dev_net(dev);//该宏用于内核做一些统计,关于网络层snmp统计的信息,也可以通过netstat 指令看到这些统计值__IP_UPD_PO_STATS(net, IPSTATS_MIB_IN, skb->len);//检查是否skb为share,是 则克隆报文skb = skb_share_check(skb, GFP_ATOMIC);if (!skb) {__IP_INC_STATS(net, IPSTATS_MIB_INDISCARDS);goto out;}//pskb_may_pull确保skb->data指向的内存包含的数据至少为IP头部大小,由于每个//IP数据包包括IP分片必须包含一个完整的IP头部。如果小于IP头部大小,则缺失、//的部分将从数据分片中拷贝。这些分片保存在skb_shinfo(skb)->frags[]中if (!pskb_may_pull(skb, sizeof(struct iphdr)))goto inhdr_error;//pskb_may_pull可能会调整skb中的指针,所以需要重新定义IP头部,获取IP头部iph = ip_hdr(skb);//检测ip首部长度及协议版本if (iph->ihl < 5 || iph->version != 4)goto inhdr_error;BUILD_BUG_ON(IPSTATS_MIB_ECT1PKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_ECT_1);BUILD_BUG_ON(IPSTATS_MIB_ECT0PKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_ECT_0);BUILD_BUG_ON(IPSTATS_MIB_CEPKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_CE);__IP_ADD_STATS(net,IPSTATS_MIB_NOECTPKTS + (iph->tos & INET_ECN_MASK),max_t(unsigned short, 1, skb_shinfo(skb)->gso_segs));//确保skb还可以容纳实际的报头(ihl*4)if (!pskb_may_pull(skb, iph->ihl*4))goto inhdr_error;iph = ip_hdr(skb);//验证IP头部的校验和if (unlikely(ip_fast_csum((u8 *)iph, iph->ihl)))goto csum_error;len = ntohs(iph->tot_len);//获取ip分组总长,即ip首部加数据的长度if (skb->len < len) {//skb的实际总长度小于ip分组总长,则drop__IP_INC_STATS(net, IPSTATS_MIB_INTRUNCATEDPKTS);goto drop;} else if (len < (iph->ihl*4))//ip头记录的分组长度就大于数据总长,则出错goto inhdr_error;if (pskb_trim_rcsum(skb, len)) {__IP_INC_STATS(net, IPSTATS_MIB_INDISCARDS);goto drop;}//设置tcp报头指针skb->transport_header = skb->network_header + iph->ihl*4;//删除任何套接字控制块碎片memset(IPCB(skb), 0, sizeof(struct inet_skb_parm));IPCB(skb)->iif = skb->skb_iif;/* Must drop socket now because of tproxy. */skb_orphan(skb);//在做完基本的头校验等工作后,就交由NF_HOOK管理了//(调用netfilter,实现iptables功能)NF_HOOK在做完PRE_ROUTING的筛选后,PRE_ROUTING点上注册的所有钩子都//返回NF_ACCEPT才会执行后面的ip_rcv_finish函数 ,然后继续执行路由等处理//如果是本地的就会交给更高层的协议进行处理,如果不是交由本地的就执行FORWARDreturn NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,net, NULL, skb, dev, NULL,ip_rcv_finish);csum_error:__IP_INC_STATS(net, IPSTATS_MIB_CSUMERRORS);
inhdr_error:__IP_INC_STATS(net, IPSTATS_MIB_INHDRERRORS);
drop:kfree_skb(skb);
out:return NET_RX_DROP;
}
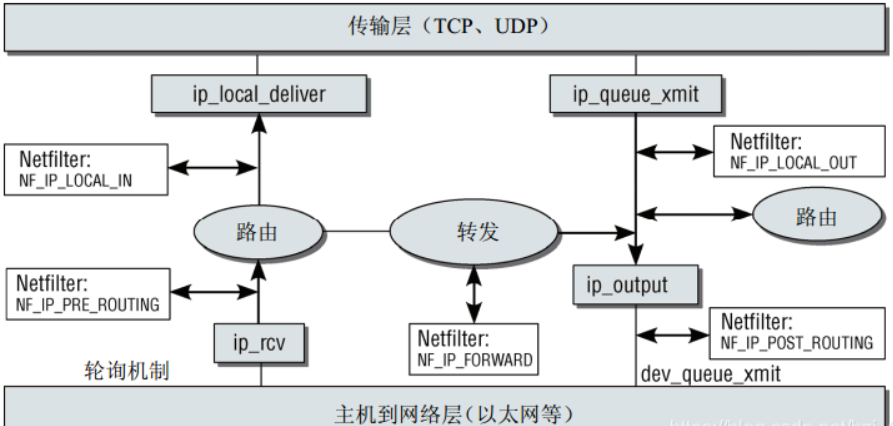
ip_rcv完成基本的校验( 主要检查计算的校验和与首部中存储的校验和是否一致)和处理工作后,经过PRE_ROUTING钩子之后,调用ip_rcv_finish完成数据包接收,包括选项处理,路由查询,并且根据路由决定数据包是发往本机还是转发
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{const struct iphdr *iph = ip_hdr(skb);struct rtable *rt;struct net_device *dev = skb->dev;skb = l3mdev_ip_rcv(skb);if (!skb)return NET_RX_SUCCESS;//启用了early_demux,skb路由缓存为空,skb的sock为空,不是分片包if (net->ipv4.sysctl_ip_early_demux &&!skb_dst(skb) &&!skb->sk &&!ip_is_fragment(iph)) {const struct net_protocol *ipprot;int protocol = iph->protocol;//得到传输层协议//获取协议对应的protipprot = rcu_dereference(inet_protos[protocol]);if (ipprot && ipprot->early_demux) {//对于socket报文,可以通过socket快速获取路由表ipprot->early_demux(skb);//调用该函数,将路由信息缓存到_skb->refdst/* must reload iph, skb->head might have changed *///重新取ip头iph = ip_hdr(skb);}}//通常从外界接收的数据包,skb->dst不会包含路由信息//skb->dst该数据域包含了如何到达目的地址的路由信息,如果该数据域是NULL,//就通过路由子系统函数ip_route_input_noref路由//ip_route_input_noref的输入参数有源IP地址、目的IP地址、服务类型、接受数据包的网络设备,根据这5个参数决策路由if (!skb_valid_dst(skb)) {//会根据路由表设置路由信息int err = ip_route_input_noref(skb, iph->daddr, iph->saddr,iph->tos, dev);if (unlikely(err)) {if (err == -EXDEV)__NET_INC_STATS(net, LINUX_MIB_IPRPFILTER);goto drop;}}//更新统计数据
#ifdef CONFIG_IP_ROUTE_CLASSIDif (unlikely(skb_dst(skb)->tclassid)) {struct ip_rt_acct *st = this_cpu_ptr(ip_rt_acct);u32 idx = skb_dst(skb)->tclassid;st[idx&0xFF].o_packets++;st[idx&0xFF].o_bytes += skb->len;st[(idx>>16)&0xFF].i_packets++;st[(idx>>16)&0xFF].i_bytes += skb->len;}
#endif//如果IP头部大于20字节,则表示IP头部包含IP选项,需要进行选项处理if (iph->ihl > 5 && ip_rcv_options(skb))goto drop;//skb_rtable函数等同于skb_dst函数,获取skb->dstrt = skb_rtable(skb);if (rt->rt_type == RTN_MULTICAST) {__IP_UPD_PO_STATS(net, IPSTATS_MIB_INMCAST, skb->len);} else if (rt->rt_type == RTN_BROADCAST) {__IP_UPD_PO_STATS(net, IPSTATS_MIB_INBCAST, skb->len);} else if (skb->pkt_type == PACKET_BROADCAST ||skb->pkt_type == PACKET_MULTICAST) {struct in_device *in_dev = __in_dev_get_rcu(dev);if (in_dev &&IN_DEV_ORCONF(in_dev, DROP_UNICAST_IN_L2_MULTICAST))goto drop;}//dst_input实际上会调用skb->dst->input(skb).input函数会根据路由信息设置为合适的//函数指针,如果是递交到本地的则为ip_local_deliver,若是转发则为ip_forwardreturn dst_input(skb);drop:kfree_skb(skb);return NET_RX_DROP;
}static inline int dst_input(struct sk_buff *skb)
{ //返回的是一个dst_entry,dst_entry里面有一个名为input的函数指针return skb_dst(skb)->input(skb);
}
这个skb_dst中的input函数是在申请一个新的路由项时进行初始化的
struct rtable *rt_dst_alloc(struct net_device *dev,unsigned int flags, u16 type,bool nopolicy, bool noxfrm, bool will_cache)
{struct rtable *rt;//申请空间rt = dst_alloc(&ipv4_dst_ops, dev, 1, DST_OBSOLETE_FORCE_CHK,(will_cache ? 0 : (DST_HOST | DST_NOCACHE)) |(nopolicy ? DST_NOPOLICY : 0) |(noxfrm ? DST_NOXFRM : 0));//进行相应的初始化if (rt) {rt->rt_genid = rt_genid_ipv4(dev_net(dev));rt->rt_flags = flags;rt->rt_type = type;rt->rt_is_input = 0;rt->rt_iif = 0;rt->rt_pmtu = 0;rt->rt_mtu_locked = 0;rt->rt_gateway = 0;rt->rt_uses_gateway = 0;rt->rt_table_id = 0;INIT_LIST_HEAD(&rt->rt_uncached);rt->dst.output = ip_output; //如果分包的目的ip地址是本机if (flags & RTCF_LOCAL)//ip_local_deliver会把数据包交给本机协议栈的上一层(例如tcp或者udp+)做处理rt->dst.input = ip_local_deliver;}return rt;
}
如果数据包的ip是本地ip的话,则会交给ip_local_deliver处理
int ip_local_deliver(struct sk_buff *skb)
{struct net *net = dev_net(skb->dev);//如果IP数据报有被分片,则在这里进行组装还原if (ip_is_fragment(ip_hdr(skb))) {if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER))return 0;}//调用netfilter的NF_INET_LOCAL_IN的钩子函数,如果此数据包被钩子函数放行,则调用ip_local_deliver_finish()继续处理return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN,net, NULL, skb, skb->dev, NULL,ip_local_deliver_finish);
}
static int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{//把skb->data指向L4协议头(相当于去掉ip头部),更新skb->len__skb_pull(skb, skb_network_header_len(skb));rcu_read_lock();{ //获取传输层的协议int protocol = ip_hdr(skb)->protocol;const struct net_protocol *ipprot;int raw;resubmit://若是raw socket发送的,需要做相应的处理,clone数据包raw = raw_local_deliver(skb, protocol);//通过查找inet_portos数组,确定是否注册了与IP首部中传输层协议号一致的传输层协议//若查找命中,则进行相关传输层协议的处理。ipprot = rcu_dereference(inet_protos[protocol]);if (ipprot) {int ret;if (!ipprot->no_policy) {if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {kfree_skb(skb);goto out;}nf_reset(skb);}ret = ipprot->handler(skb);//交给上层传输层处理if (ret < 0) {protocol = -ret;goto resubmit;}__IP_INC_STATS(net, IPSTATS_MIB_INDELIVERS);} else {/* 如果没有响应的协议传输层接收该数据包,* 则释放该数据包。在释放前,如果是RAW* 套接字没有接收或接收异常,则还需产生* 一个目的不可达ICMP报文给发送方。表示该包raw没有接收并且inet_protos中没有注册该协议*/if (!raw) {if (xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {__IP_INC_STATS(net, IPSTATS_MIB_INUNKNOWNPROTOS);icmp_send(skb, ICMP_DEST_UNREACH,ICMP_PROT_UNREACH, 0);}kfree_skb(skb);} else {__IP_INC_STATS(net, IPSTATS_MIB_INDELIVERS);consume_skb(skb);}}}out:rcu_read_unlock();return 0;
}
在af_inet.c中
static const struct net_protocol tcp_protocol = {.early_demux = tcp_v4_early_demux,.handler = tcp_v4_rcv,.err_handler = tcp_v4_err,.no_policy = 1,.netns_ok = 1,.icmp_strict_tag_validation = 1,
};
4、tcp层接受数据
所以ipprot->handler(skb)调用的就是tcp_v4_rcv函数
int tcp_v4_rcv(struct sk_buff *skb)
{struct net *net = dev_net(skb->dev);const struct iphdr *iph;const struct tcphdr *th;bool refcounted;struct sock *sk;int ret;//如果不是发往本机的就直接丢弃if (skb->pkt_type != PACKET_HOST)goto discard_it;__TCP_INC_STATS(net, TCP_MIB_INSEGS);/*如果一个TCP段在传输过程中被网络层分片,那么在目的端的网络层会重新组包,这会导致传给TCP的skb的分片结构中包含多个skb,这种情况下,该函数会将分片结构重组到线性数据区。如果发生异常,则丢弃该报文*/if (!pskb_may_pull(skb, sizeof(struct tcphdr)))goto discard_it;//获得tcp头th = (const struct tcphdr *)skb->data;//如果 TCP 的首部长度小于不带数据的 TCP 的首部长度,则说明 TCP 数据异常。//统计相关信息后,丢弃。if (unlikely(th->doff < sizeof(struct tcphdr) / 4))goto bad_packet;//保证skb的线性区域至少包括实际的TCP首部if (!pskb_may_pull(skb, th->doff * 4))goto discard_it;//验证 TCP 首部中的校验和,如校验和有误,则说明报文已损坏,统计相关信息后丢弃if (skb_checksum_init(skb, IPPROTO_TCP, inet_compute_pseudo))goto csum_error;//tcp头th = (const struct tcphdr *)skb->data;iph = ip_hdr(skb);//ip头 skb->head(整个skb的起始位置) + skb->network_header(起始位置到ip头部的偏移量)memmove(&TCP_SKB_CB(skb)->header.h4, IPCB(skb),sizeof(struct inet_skb_parm));barrier();//初始化skb中的控制块TCP_SKB_CB(skb)->seq = ntohl(th->seq);TCP_SKB_CB(skb)->end_seq = (TCP_SKB_CB(skb)->seq + th->syn + th->fin +skb->len - th->doff * 4);TCP_SKB_CB(skb)->ack_seq = ntohl(th->ack_seq);TCP_SKB_CB(skb)->tcp_flags = tcp_flag_byte(th);TCP_SKB_CB(skb)->tcp_tw_isn = 0;TCP_SKB_CB(skb)->ip_dsfield = ipv4_get_dsfield(iph);TCP_SKB_CB(skb)->sacked = 0;lookup:/* 在 ehash散列表中根据端口来查找传sock。如果在 ehash 中找到,则表示已经经历了三次握手并且已建立了连接,可以进行正常的通信。如果找不到就去listening_hash(监听的套接字)中找。如果在两个散列表中都查找不到,说明没有对应的socket,跳转到no_tcp_socket 处理。*/sk = __inet_lookup_skb(&tcp_hashinfo, skb, __tcp_hdrlen(th), th->source,th->dest, &refcounted);if (!sk)goto no_tcp_socket;process://TCP_TIME_WAIT需要做特殊处理,这里先不关注if (sk->sk_state == TCP_TIME_WAIT)goto do_time_wait;//如果服务端已经收到过客服端发的syn包if (sk->sk_state == TCP_NEW_SYN_RECV) {struct request_sock *req = inet_reqsk(sk);struct sock *nsk;sk = req->rsk_listener;if (unlikely(tcp_v4_inbound_md5_hash(sk, skb))) {sk_drops_add(sk, skb);reqsk_put(req);goto discard_it;}//检查TCP数据包的校验和是否正确if (tcp_checksum_complete(skb)) {reqsk_put(req);goto csum_error;}if (unlikely(sk->sk_state != TCP_LISTEN)) {inet_csk_reqsk_queue_drop_and_put(sk, req);goto lookup;}sock_hold(sk);refcounted = true;nsk = tcp_check_req(sk, skb, req, false);if (!nsk) {reqsk_put(req);goto discard_and_relse;}if (nsk == sk) {reqsk_put(req);} else if (tcp_child_process(sk, nsk, skb)) {//没有打开的套接字就发送一个复位请求来告诉对端关闭连接tcp_v4_send_reset(nsk, skb);goto discard_and_relse;} else {sock_put(sk);return 0;}}//ttl 小于给定的最小的 ttlif (unlikely(iph->ttl < inet_sk(sk)->min_ttl)) {__NET_INC_STATS(net, LINUX_MIB_TCPMINTTLDROP);goto discard_and_relse;}//查找 IPsec 数据库,如果查找失败,进行相应处理if (!xfrm4_policy_check(sk, XFRM_POLICY_IN, skb))goto discard_and_relse;//md5 相关if (tcp_v4_inbound_md5_hash(sk, skb))goto discard_and_relse;nf_reset(skb);//TCP套接字过滤器,如果数据包被过滤掉了,结束处理过程if (tcp_filter(sk, skb))goto discard_and_relse;th = (const struct tcphdr *)skb->data;iph = ip_hdr(skb);//到了传输层,该字段已经没有意义,将其置为空skb->dev = NULL;//LISTEN 状态if (sk->sk_state == TCP_LISTEN) {ret = tcp_v4_do_rcv(sk, skb); //交由tcp_v4_do_rcv()处理goto put_and_return;}//先持锁,这样进程上下文和其它软中断则无法操作该TCBsk_incoming_cpu_update(sk);bh_lock_sock_nested(sk);tcp_segs_in(tcp_sk(sk), skb);ret = 0;if (!sock_owned_by_user(sk)) {//如果当前套接字没有被进程占有if (!tcp_prequeue(sk, skb))//尝试把skb放入tcp的prequeue队列中//如果skb没有加入到prequeue队列,则调用tcp_v4_do_rcv()//tcp_v4_do_rcv会把skb加入到sk_receive_queue队列ret = tcp_v4_do_rcv(sk, skb);//如果套接字正在被进程占用,则调用tcp_add_backlog把skb添加到sk_backlog队列中} else if (tcp_add_backlog(sk, skb)) {goto discard_and_relse;}bh_unlock_sock(sk);//释放锁put_and_return:if (refcounted)sock_put(sk);//释放TCB引用计数,当计数为 0 的时候,使用 sk_free 释放传输控制块return ret;//返回处理结果//处理没有创建传输控制块收到报文,校验错误,坏包的情况,给对端发送 RST 报文。
no_tcp_socket://查找 IPsec 数据库,如果查找失败,进行相应处理if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb))goto discard_it;if (tcp_checksum_complete(skb)) {
csum_error:__TCP_INC_STATS(net, TCP_MIB_CSUMERRORS);
bad_packet:__TCP_INC_STATS(net, TCP_MIB_INERRS);} else {tcp_v4_send_reset(NULL, skb);}discard_it://丢弃帧kfree_skb(skb);return 0;discard_and_relse:sk_drops_add(sk, skb);if (refcounted)sock_put(sk);goto discard_it;
//处理TIME_WAIT状态
do_time_wait:if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {inet_twsk_put(inet_twsk(sk));goto discard_it;}if (tcp_checksum_complete(skb)) {inet_twsk_put(inet_twsk(sk));goto csum_error;}//根据返回值进行相应处理switch (tcp_timewait_state_process(inet_twsk(sk), skb, th)) {case TCP_TW_SYN: {struct sock *sk2 = inet_lookup_listener(dev_net(skb->dev),&tcp_hashinfo, skb,__tcp_hdrlen(th),iph->saddr, th->source,iph->daddr, th->dest,inet_iif(skb));if (sk2) {inet_twsk_deschedule_put(inet_twsk(sk));sk = sk2;refcounted = false;goto process;}}case TCP_TW_ACK:tcp_v4_timewait_ack(sk, skb);break;case TCP_TW_RST:tcp_v4_send_reset(sk, skb);inet_twsk_deschedule_put(inet_twsk(sk));goto discard_it;case TCP_TW_SUCCESS:;}goto discard_it;
}
如果当前套接字没有被进程占有,调用tcp_prequeue函数尝试把skb放入tcp的prequeue队列中,如果skb没有加入到prequeue队列,则调用tcp_v4_do_rcv函数把skb加入到sk_receive_queue队列
如果套接字正在被进程占用,则调用tcp_add_backlog函数把skb添加到sk_backlog队列中
接下来我们来就看看这三个函数分别做了哪些事
tcp_prequeue函数
bool tcp_prequeue(struct sock *sk, struct sk_buff *skb)
{struct tcp_sock *tp = tcp_sk(sk);//sysctl_tcp_low_latency(/proc/net/ipv4/tcp_low_latency)系统参数的含义是//“是否启动tcp低时延”,如果启用则为1,否则为0(默认)//tp->ucopy.task不为空,表示有进程正阻塞到该套接字上等待数据可用//所以,下面这两个条件表示如果启动TCP低时或者没有对应的用户进程,直接返回falseif (sysctl_tcp_low_latency || !tp->ucopy.task)return false;//如果数据包的长度小于或等于TCP头部长度并且prequeue队列为空,返回falseif (skb->len <= tcp_hdrlen(skb) &&skb_queue_len(&tp->ucopy.prequeue) == 0)return false;if (likely(sk->sk_rx_dst))skb_dst_drop(skb);elseskb_dst_force_safe(skb);//将skb加入到prequeue队列后面__skb_queue_tail(&tp->ucopy.prequeue, skb);tp->ucopy.memory += skb->truesize;//如果prequeue队列的大小>=32或者prequeue使用的内存加上套接字接收缓冲区中已分配的内存超过套接字的接收缓冲区大小if (skb_queue_len(&tp->ucopy.prequeue) >= 32 ||tp->ucopy.memory + atomic_read(&sk->sk_rmem_alloc) > sk->sk_rcvbuf) {struct sk_buff *skb1;BUG_ON(sock_owned_by_user(sk));__NET_ADD_STATS(sock_net(sk), LINUX_MIB_TCPPREQUEUEDROPPED,skb_queue_len(&tp->ucopy.prequeue));//取出prequeue列中的所有数据包,并将它们放入套接字的backlog队列中while ((skb1 = __skb_dequeue(&tp->ucopy.prequeue)) != NULL)sk_backlog_rcv(sk, skb1);//prequeue使用的内存设置为0tp->ucopy.memory = 0;//prequeue列中只有一个数据包,则唤醒等待在套接字上的进程,并考虑是否需要重置TCP的延迟ACK定时器} else if (skb_queue_len(&tp->ucopy.prequeue) == 1) {wake_up_interruptible_sync_poll(sk_sleep(sk),POLLIN | POLLRDNORM | POLLRDBAND);if (!inet_csk_ack_scheduled(sk))inet_csk_reset_xmit_timer(sk, ICSK_TIME_DACK,(3 * tcp_rto_min(sk)) / 4,TCP_RTO_MAX);}return true;
}
tcp_add_backlog函数
bool tcp_add_backlog(struct sock *sk, struct sk_buff *skb)
{u32 limit = sk->sk_rcvbuf + sk->sk_sndbuf;limit += 64*1024;if (!skb->data_len)skb->truesize = SKB_TRUESIZE(skb_end_offset(skb));if (unlikely(sk_add_backlog(sk, skb, limit))) {bh_unlock_sock(sk);__NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPBACKLOGDROP);return true;}return false;
}static inline __must_check int sk_add_backlog(struct sock *sk, struct sk_buff *skb,unsigned int limit)
{if (sk_rcvqueues_full(sk, limit))return -ENOBUFS;if (skb_pfmemalloc(skb) && !sock_flag(sk, SOCK_MEMALLOC))return -ENOMEM;__sk_add_backlog(sk, skb);sk->sk_backlog.len += skb->truesize;return 0;
}static inline void __sk_add_backlog(struct sock *sk, struct sk_buff *skb)
{skb_dst_force_safe(skb);if (!sk->sk_backlog.tail)sk->sk_backlog.head = skb;elsesk->sk_backlog.tail->next = skb;sk->sk_backlog.tail = skb;skb->next = NULL;
}
sk_add_backlog就是直接将数据包加入到传输控制块的backlog队列中,是简单的双向循环链表插入操作
tcp_v4_do_rcv函数
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{struct sock *rsk;//当状态为ESTABLISHED时,用tcp_rcv_established()接收处理if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */struct dst_entry *dst = sk->sk_rx_dst;sock_rps_save_rxhash(sk, skb);sk_mark_napi_id(sk, skb);if (dst) {if (inet_sk(sk)->rx_dst_ifindex != skb->skb_iif ||!dst->ops->check(dst, 0)) {dst_release(dst);sk->sk_rx_dst = NULL;}}//连接已建立时的处理路径tcp_rcv_established(sk, skb, tcp_hdr(skb), skb->len);return 0;}//...
}
接着会调用tcp_rcv_established函数
void tcp_rcv_established(struct sock *sk, struct sk_buff *skb,const struct tcphdr *th, unsigned int len)
{struct tcp_sock *tp = tcp_sk(sk);if (unlikely(!sk->sk_rx_dst))inet_csk(sk)->icsk_af_ops->sk_rx_dst_set(sk, skb);tp->rx_opt.saw_tstamp = 0;//预定向标志和输入数据段的标志比较//数据段序列号是否正确if ((tcp_flag_word(th) & TCP_HP_BITS) == tp->pred_flags &&TCP_SKB_CB(skb)->seq == tp->rcv_nxt &&!after(TCP_SKB_CB(skb)->ack_seq, tp->snd_nxt)) {int tcp_header_len = tp->tcp_header_len;//时间戳选项之外如果还有别的选项就送给Slow Path处理if (tcp_header_len == sizeof(struct tcphdr) + TCPOLEN_TSTAMP_ALIGNED) {/* No? Slow path! */if (!tcp_parse_aligned_timestamp(tp, th))goto slow_path;//对数据包做PAWS快速检查,如果检查走Slow Path处理if ((s32)(tp->rx_opt.rcv_tsval - tp->rx_opt.ts_recent) < 0)goto slow_path;}//数据包长度太小if (len <= tcp_header_len) {/* Bulk data transfer: sender */if (len == tcp_header_len) {if (tcp_header_len ==(sizeof(struct tcphdr) + TCPOLEN_TSTAMP_ALIGNED) &&tp->rcv_nxt == tp->rcv_wup)tcp_store_ts_recent(tp);tcp_ack(sk, skb, 0);__kfree_skb(skb);tcp_data_snd_check(sk);return;} else { /* Header too small */TCP_INC_STATS(sock_net(sk), TCP_MIB_INERRS);goto discard;}} else {int eaten = 0;bool fragstolen = false;//当前进程的全局指针current//tp->rcv_nxt表示下一个期望读取的数据包序列号//tp->ucopy.task指针是否等于当前进程 且 copied_seq是下一个期望读取的数据包序列号//且 len-tcp_header_len小于tp->ucpoy.len表示数据包还没有复制完if (tp->ucopy.task == current &&tp->copied_seq == tp->rcv_nxt &&len - tcp_header_len <= tp->ucopy.len &&sock_owned_by_user(sk)) {__set_current_state(TASK_RUNNING);//将数据包复制到应用层空间if (!tcp_copy_to_iovec(sk, skb, tcp_header_len)) {if (tcp_header_len ==(sizeof(struct tcphdr) +TCPOLEN_TSTAMP_ALIGNED) &&tp->rcv_nxt == tp->rcv_wup)tcp_store_ts_recent(tp);tcp_rcv_rtt_measure_ts(sk, skb);__skb_pull(skb, tcp_header_len);//更新下一个期望读取的数据包序列号tcp_rcv_nxt_update(tp, TCP_SKB_CB(skb)->end_seq);NET_INC_STATS(sock_net(sk),LINUX_MIB_TCPHPHITSTOUSER);eaten = 1;}}//复制不成功if (!eaten) {//从新计算校验和if (tcp_checksum_complete(skb))goto csum_error;if ((int)skb->truesize > sk->sk_forward_alloc)goto step5;if (tcp_header_len ==(sizeof(struct tcphdr) + TCPOLEN_TSTAMP_ALIGNED) &&tp->rcv_nxt == tp->rcv_wup)tcp_store_ts_recent(tp);tcp_rcv_rtt_measure_ts(sk, skb);NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPHPHITS);eaten = tcp_queue_rcv(sk, skb, tcp_header_len,&fragstolen);}//在内部会发送ack,检测拥塞控制,更新最近一次接收数据的时间等。。tcp_event_data_recv(sk, skb);if (TCP_SKB_CB(skb)->ack_seq != tp->snd_una) {tcp_ack(sk, skb, FLAG_DATA);tcp_data_snd_check(sk);if (!inet_csk_ack_scheduled(sk))goto no_ack;}//收到数据后回复ack确认__tcp_ack_snd_check(sk, 0);
no_ack:if (eaten)kfree_skb_partial(skb, fragstolen);sk->sk_data_ready(sk);return;}}slow_path:if (len < (th->doff << 2) || tcp_checksum_complete(skb))goto csum_error;if (!th->ack && !th->rst && !th->syn)goto discard;if (!tcp_validate_incoming(sk, skb, th, 1))return;step5:if (tcp_ack(sk, skb, FLAG_SLOWPATH | FLAG_UPDATE_TS_RECENT) < 0)goto discard;tcp_rcv_rtt_measure_ts(sk, skb);//紧急数据段处理tcp_urg(sk, skb, th);//将数据加入sk_receive_queue队列中tcp_data_queue(sk, skb);tcp_data_snd_check(sk);tcp_ack_snd_check(sk);return;csum_error:TCP_INC_STATS(sock_net(sk), TCP_MIB_CSUMERRORS);TCP_INC_STATS(sock_net(sk), TCP_MIB_INERRS);discard:tcp_drop(sk, skb);
}
查看当前应用进程是否是等待数据的进程,如果是,则调用tcp_copy_to_iovec将数据包直接复制到应用层,否则调用tcp_data_queue函数将数据加入sk_receive_queue队列中
具体看看tcp_data_queue做了哪些事
static void tcp_data_queue(struct sock *sk, struct sk_buff *skb)
{struct tcp_sock *tp = tcp_sk(sk);bool fragstolen = false;int eaten = -1;//所以如果数据数据段没有数据部分,直接丢弃if (TCP_SKB_CB(skb)->seq == TCP_SKB_CB(skb)->end_seq) {__kfree_skb(skb);return;}//删除路由信息skb_dst_drop(skb);//调整data指针指向数据部分__skb_pull(skb, tcp_hdr(skb)->doff * 4);//ECN相关处理tcp_ecn_accept_cwr(tp, skb);tp->rx_opt.dsack = 0;//收到的数据包的序号是否等于期望的序号if (TCP_SKB_CB(skb)->seq == tp->rcv_nxt) {//接收窗口为0,表示本端没有空间接收数据了,所以立马给对端发送零窗口通告if (tcp_receive_window(tp) == 0)goto out_of_window;//如果用户空间程序正在等待数据,并且数据正好是要读取的,直接拷贝给用户空间if (tp->ucopy.task == current &&tp->copied_seq == tp->rcv_nxt && tp->ucopy.len &&sock_owned_by_user(sk) && !tp->urg_data) {int chunk = min_t(unsigned int, skb->len,tp->ucopy.len);__set_current_state(TASK_RUNNING);//将skb拷贝到用户空间if (!skb_copy_datagram_msg(skb, 0, tp->ucopy.msg, chunk)) {tp->ucopy.len -= chunk;tp->copied_seq += chunk;eaten = (chunk == skb->len);tcp_rcv_space_adjust(sk);}}//如果没有拷贝成功(内存受限,或者没有进程在等待等原因)if (eaten <= 0) {
queue_and_out://内存不足,丢掉数据包if (eaten < 0) {if (skb_queue_len(&sk->sk_receive_queue) == 0)sk_forced_mem_schedule(sk, skb->truesize);else if (tcp_try_rmem_schedule(sk, skb, skb->truesize))goto drop;}//将数据包放入receive队列中eaten = tcp_queue_rcv(sk, skb, 0, &fragstolen);}//更新rcv_nxt(期望下一个收到的数据包的序号)为end_seqtcp_rcv_nxt_update(tp, TCP_SKB_CB(skb)->end_seq);if (skb->len)//在内部会发送ack,检测拥塞控制,更新最近一次接收数据的时间等。。tcp_event_data_recv(sk, skb);//输入数据包中携带了FIN标记,做断开连接处理if (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN)tcp_fin(sk);//如果乱序队列不为空,那么因为来了新数据,所以乱序队列中可能有些数据变为连续的//所以需要将这些数据移到receive队列中//例如乱序队列中有序号为7和9的数据包,我们期望收到序号为6的数据包,此时数据包到来,6和7就连续了,//所以需要将序号为7的数据包从乱序队列(out_of_order_queue)中移到receive队列中//乱序队列(out_of_order_queue)底层由红黑树实现if (!RB_EMPTY_ROOT(&tp->out_of_order_queue)) {//处理乱序队列tcp_ofo_queue(sk);if (RB_EMPTY_ROOT(&tp->out_of_order_queue))inet_csk(sk)->icsk_ack.pingpong = 0;}//SACK相关处理if (tp->rx_opt.num_sacks)tcp_sack_remove(tp);//重新设置首部预测标记tcp_fast_path_check(sk);//如果数据已经拷贝给了用户空间程序,那么释放skb,否则通知用户空间程序数据可读if (eaten > 0)kfree_skb_partial(skb, fragstolen);if (!sock_flag(sk, SOCK_DEAD))sk->sk_data_ready(sk);return;}//输入数据段的end_seq都小于rcv_nxt,所以数据段一定是重复段,例如期望的序号是7,却收到了序号为5的数据包,那么这个包一定是重复的//因此就需要发送一个ack,并把这个数据包丢掉if (!after(TCP_SKB_CB(skb)->end_seq, tp->rcv_nxt)) {/* A retransmit, 2nd most common case. Force an immediate ack. */NET_INC_STATS(sock_net(sk), LINUX_MIB_DELAYEDACKLOST);tcp_dsack_set(sk, TCP_SKB_CB(skb)->seq, TCP_SKB_CB(skb)->end_seq);out_of_window://将tcp链接切换到快速确认模式,因为只有发送了ack进行确认,才能增加接收方的窗口大小tcp_enter_quickack_mode(sk, TCP_MAX_QUICKACKS);//发送ackinet_csk_schedule_ack(sk);
drop: //丢掉接受到的tcp数据包tcp_drop(sk, skb);return;}//输入数据段超过了接收窗口的右边界,直接丢掉数据包if (!before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt + tcp_receive_window(tp)))goto out_of_window;//到这里,输入段在接收窗口内,但是一定是乱序报文//这个条件成立,说明输入段的一部分数据在接收窗口内if (before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt)) {SOCK_DEBUG(sk, "partial packet: rcv_next %X seq %X - %X\n",tp->rcv_nxt, TCP_SKB_CB(skb)->seq,TCP_SKB_CB(skb)->end_seq);tcp_dsack_set(sk, TCP_SKB_CB(skb)->seq, tp->rcv_nxt);//如果窗口大小为0,丢掉数据包if (!tcp_receive_window(tp))goto out_of_window;//如果窗口大小不为0,将数据包放入receive队列中goto queue_and_out;}//走到这里,收到的一定是一个乱序的分包,则调用该函数进行乱序处理tcp_data_queue_ofo(sk, skb);
}
为什么需要prequeue队列和backlog队列两个队列呢?
因为软中断和进程上下文都会访问这个几个队列,所有就存在资源同步的问题,prequeue队列和backlog队列存放的是未被处理的skb,使用这个两个队列就可以避免软中断上下文和进程上下文在处理数据时造成的资源冲突。
假设我们只有一个未处理的队列,并且这个队列被进程占有(加锁),软中断接受到了数据,那么就需要等待进程释放这个锁,这样就跟软中断需要快速处理分包的初衷不符,也会影响软中断的接受性能,因此使用两个未处理队列,就可以实现在软中断和进程上下文错开处理,减少资源冲突,提高软中断的接受性能。
如果sk被软中断占用时,那么数据可能被放置到receive_queue或者prequeue,数据优先放置到prequeue中,如果prequeue满了则会放置到receive_queue中,理论上这里有一个队列就行了,但是TCP协议栈为什么要设计两个呢?其实是为了快点结束软中断数据处理流程,软中断处理函数中禁止了进程抢占和其他软中断发生,效率应该是很低下的,如果数据被放置到prequeue中,那么软中断流程很快就结束了,如果放置到receive_queue那么会有很复杂的逻辑需要处理。receive_queue队列的处理在软中断中,prequeue队列的处理则是在进程上下文中。
5、上层应用读取数据
当数据到来时,是通过软中断的方式,将数据放置到receive_queue、prequeue和backlog队列中的其中一个,此过程在软中断的上下文进行,那么上层是如何获取到数据呢?当然是通过read系统调用
read——>vfs-read——>sock_read_iter——>sock_recvmsg——>tcp_recvmsg
最终会调用到tcp_recvmsg从上述的三个队列中读取数据
int tcp_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, int nonblock,int flags, int *addr_len)
{struct tcp_sock *tp = tcp_sk(sk);int copied = 0;//实际拷贝的字节数u32 peek_seq;u32 *seq;//指向待拷贝的sequnsigned long used;//需要从skb中拷贝的字节数int err;int target;//本次需要拷贝的字节数 /* Read at least this many bytes */long timeo;struct task_struct *user_recv = NULL;struct sk_buff *skb, *last;u32 urg_hole = 0;if (unlikely(flags & MSG_ERRQUEUE))return inet_recv_error(sk, msg, len, addr_len);if (sk_can_busy_loop(sk) && skb_queue_empty(&sk->sk_receive_queue) &&(sk->sk_state == TCP_ESTABLISHED))sk_busy_loop(sk, nonblock);//功能:“锁住sk”,并不是真正的加锁,而是运行sk->sk_lock.owned = 1 //目的:这样软中断上下文可以通过owned 。推断该sk是否处于进程上下文。//提供一种同步机制。lock_sock(sk);err = -ENOTCONN;if (sk->sk_state == TCP_LISTEN)goto out;//获取超时时间,如果是非阻塞模式就为0timeo = sock_rcvtimeo(sk, nonblock);if (flags & MSG_OOB)goto recv_urg;if (unlikely(tp->repair)) {err = -EPERM;if (!(flags & MSG_PEEK))goto out;if (tp->repair_queue == TCP_SEND_QUEUE)goto recv_sndq;err = -EINVAL;if (tp->repair_queue == TCP_NO_QUEUE)goto out;}//待拷贝的下一个序列号seq = &tp->copied_seq;//设置了MSG_PEEK,表示不让数据从缓冲区移除,目的是下一次调用recv函数//仍然能够读到相同数据if (flags & MSG_PEEK) {peek_seq = tp->copied_seq;seq = &peek_seq;}//取len和sk->rcvlowat中的最小值//MSG_WAITALL标志是判断是否要接受完整的数据包后再拷贝复制数据包target = sock_rcvlowat(sk, flags & MSG_WAITALL, len);//主循环,复制数据到用户地址空间直到target为0do {//offest表示读取数据的偏移u32 offset;//遇到紧急数据停止处理跳出循环if (tp->urg_data && tp->urg_seq == *seq) {if (copied)break;//检测套接字上是否有信号等待处理,确保能处理SIGUSR信号if (signal_pending(current)) {//检查是否超时copied = timeo ? sock_intr_errno(timeo) : -EAGAIN;break;}}//获取sk_receive_queue中的最后一个数据包(序号最小的)last = skb_peek_tail(&sk->sk_receive_queue);skb_queue_walk(&sk->sk_receive_queue, skb) {last = skb;//待拷贝的数据的序号小于序号最小的数据包,则表明出错//例如我希望拷贝序号为5,结果收到序号最小的数据包的序号为7,说明序号为5的数据包还没到if (WARN(before(*seq, TCP_SKB_CB(skb)->seq),"TCP recvmsg seq # bug: copied %X, seq %X, rcvnxt %X, fl %X\n",*seq, TCP_SKB_CB(skb)->seq, tp->rcv_nxt,flags))break;//如果用户的缓冲区(即用户malloc的buf)长度够大,offset一般是0。//即 “下次准备拷贝数据的序列号”==此时获取报文的起始序列号//什么情况下offset >0呢?很简答,如果用户缓冲区12字节,而这个skb有120字节//那么一次recv系统调用,只能获取skb中的前12个字节,下一次执行recv系统调用//offset就是12了,offset表示从第12个字节开始读取数据,前12个字节已经读取了。//那这个"已经读取12字节"这个消息,存在哪呢?//在*seq = &tp->copied_seq;中offset = *seq - TCP_SKB_CB(skb)->seq;if (unlikely(TCP_SKB_CB(skb)->tcp_flags & TCPHDR_SYN)) {pr_err_once("%s: found a SYN, please report !\n", __func__);offset--;}//找到了skb,跳转到found_ok_skb处完成复制工作if (offset < skb->len)goto found_ok_skb;//发现是fin包调转到fin处理标签处if (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN)goto found_fin_ok;WARN(!(flags & MSG_PEEK),"TCP recvmsg seq # bug 2: copied %X, seq %X, rcvnxt %X, fl %X\n",*seq, TCP_SKB_CB(skb)->seq, tp->rcv_nxt, flags);}//缓冲区recieve_queue队列中已经没有数据//而且backlog_queue队列中也没有数据了就跳出循环if (copied >= target && !sk->sk_backlog.tail)break;if (copied) {//检查套接字的状态是否是关闭//或者收到远端的断开请求,则要跳出复制循环if (sk->sk_err ||sk->sk_state == TCP_CLOSE ||(sk->sk_shutdown & RCV_SHUTDOWN) ||!timeo ||signal_pending(current))break;} else {//copied为0表示应用层没有复制到数据,没有复制到数据有三种可能//第一是套接字已经关闭了,第二是缓冲区根本没有数据 //第三是其他错误if (sock_flag(sk, SOCK_DONE))break;if (sk->sk_err) {copied = sock_error(sk);break;}if (sk->sk_shutdown & RCV_SHUTDOWN)break;if (sk->sk_state == TCP_CLOSE) {//当用户关闭套接字会设置SOCK_DON标志//连接状态是TCP_CLOSE,SOCK_DONE标志就不会if (!sock_flag(sk, SOCK_DONE)) {copied = -ENOTCONN;break;}break;}//查看是否阻塞,不阻塞直接返回//返回的错误标志是EAGAINif (!timeo) {copied = -EAGAIN;break;}//读取数据失败可能是其他错误//返回错误原因if (signal_pending(current)) {copied = sock_intr_errno(timeo);break;}}//根据已经复制数据长度copied清除recieve_queue队列//并且回复对端ack包tcp_cleanup_rbuf(sk, copied);//sk_recieve_queue队列中已无数据需要处理就处理preueue队列上的数据//prequeue队列的处理现场是用户进程if (!sysctl_tcp_low_latency && tp->ucopy.task == user_recv) {/* Install new reader */if (!user_recv && !(flags & (MSG_TRUNC | MSG_PEEK))) {//复制pre_queue队列的进程是当前进程user_recv = current;//处理数据的用户进程tp->ucopy.task = user_recv;//应用层接受数据的缓冲区地址tp->ucopy.msg = msg;}//拷贝数据长度tp->ucopy.len = len;WARN_ON(tp->copied_seq != tp->rcv_nxt &&!(flags & (MSG_PEEK | MSG_TRUNC)));// prequeu队列不为空,必须在释放套接字之前处理这些数据包// 如果这个处理没有完成则数据段顺序将会被破坏,接受段处理顺序是// flight中的数据、backlog队列、prequeue队列、sk_receive_queue队列,只有当前队列 // 处理完成了才会去处理下一个队列。prequeue队列可能在循环结束套接字释放前又// 加入数据包,则要调转到do_prequeue标签处理if (!skb_queue_empty(&tp->ucopy.prequeue))goto do_prequeue;}//数据包复制完毕if (copied >= target) {/* Do not sleep, just process backlog. *///从backlog队列中复制数据包到receive_queue队列release_sock(sk);lock_sock(sk);} else {//已经没有数据要处理,但是还需要拷贝数据到应用层,//此时将套接字放入等待状态,进程进入睡眠//如果有数据段来了tcp_prequeue会唤醒进程,软中断会判断用户进程睡眠//如果睡眠就会把数据放到prequeue队列中sk_wait_data(sk, &timeo, last);}if (user_recv) {int chunk;chunk = len - tp->ucopy.len;if (chunk != 0) {NET_ADD_STATS(sock_net(sk), LINUX_MIB_TCPDIRECTCOPYFROMBACKLOG, chunk);len -= chunk;copied += chunk;}if (tp->rcv_nxt == tp->copied_seq &&!skb_queue_empty(&tp->ucopy.prequeue)) {
do_prequeue://处理prequeue队列//tcp_prequeue_process会遍历prequeue队列调用sk_backlog_rcv将数据包复制到receive_queue队列,实际是调用tcp_rcv_establishedtcp_prequeue_process(sk);chunk = len - tp->ucopy.len;if (chunk != 0) {NET_ADD_STATS(sock_net(sk), LINUX_MIB_TCPDIRECTCOPYFROMPREQUEUE, chunk);//更新剩余需要复制数据长度len -= chunk;//更新复制的数据copiedcopied += chunk;}}}if ((flags & MSG_PEEK) &&(peek_seq - copied - urg_hole != tp->copied_seq)) {net_dbg_ratelimited("TCP(%s:%d): Application bug, race in MSG_PEEK\n",current->comm,task_pid_nr(current));peek_seq = tp->copied_seq;}continue;//found_ok_skb标签处是处理sk_receive_queue队列中的数据包,//调用skb_copy_datagram_msg函数将复制到应用层地址空间,然后调整tcp接受窗口found_ok_skb://需要从当前这个skb中拷贝多少字节used = skb->len - offset;//取上层希望拷贝的字节数和used的最小值if (len < used)used = len;//首先查看是否有紧急数据需要处理//如果设置套接字选项设置了SO_OOBINLINE就不需要处理紧急数据//因为有单独处理if (tp->urg_data) {u32 urg_offset = tp->urg_seq - *seq;if (urg_offset < used) {if (!urg_offset) {if (!sock_flag(sk, SOCK_URGINLINE)) {++*seq;urg_hole++;offset++;used--;if (!used)goto skip_copy;}} elseused = urg_offset;}}if (!(flags & MSG_TRUNC)) {//将数据包从内核地址空间复制到用户地址空间//从skb中偏移量为offset的位置开始拷贝,拷贝大小为used字节,拷贝到msg中(用户缓冲区)err = skb_copy_datagram_msg(skb, offset, msg, used);if (err) {if (!copied)copied = -EFAULT;break;}}//更新下一个需要拷贝的序列号*seq += used;//更新已复制的数据长度copied += used;//更新剩下需要复制的数据长度len -= used;//重新调整tcp接受窗口tcp_rcv_space_adjust(sk);skip_copy:if (tp->urg_data && after(tp->copied_seq, tp->urg_seq)) {tp->urg_data = 0;//处理完了紧急数据,调转到Fast Path处理tcp_fast_path_check(sk);}if (used + offset < skb->len)continue;if (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN)goto found_fin_ok;if (!(flags & MSG_PEEK))sk_eat_skb(sk, skb);continue;//套接字状态是Finfound_fin_ok:++*seq;if (!(flags & MSG_PEEK))//重新计算tcp窗口sk_eat_skb(sk, skb);break;//如果还没拷贝完,循环再次拷贝,直到len为0,或者三个队列中都没有数据} while (len > 0);//主循环处理结束后,prequeue队列中还有数据则必须继续处理if (user_recv) {if (!skb_queue_empty(&tp->ucopy.prequeue)) {int chunk;tp->ucopy.len = copied > 0 ? len : 0;tcp_prequeue_process(sk);if (copied > 0 && (chunk = len - tp->ucopy.len) != 0) {NET_ADD_STATS(sock_net(sk), LINUX_MIB_TCPDIRECTCOPYFROMPREQUEUE, chunk);len -= chunk;copied += chunk;}}tp->ucopy.task = NULL;tp->ucopy.len = 0;}tcp_cleanup_rbuf(sk, copied);release_sock(sk);return copied;out:release_sock(sk);return err;recv_urg://紧急数据处理,复制紧急数据到用户地址空间err = tcp_recv_urg(sk, msg, len, flags);goto out;recv_sndq:err = tcp_peek_sndq(sk, msg, len);goto out;
}
tcp_recvmsg的整体流程就是先处理sk_receive_queue队列,将数据拷贝到用户层,如果达不到用户拷贝的要求,就prequeue队列中的数据包转移到sk_receive_queue队列中(会进行乱序处理),再将sk_receive_queue队列中的数据拷贝到用户层,如果此时还达不到用户拷贝的要求并且prequeue队列为空,就会将backlog队列中数据包转移到sk_receive_queue队列中(会进行乱序处理),再将sk_receive_queue队列中的数据拷贝到用户层。如果还是达不到用户拷贝的要求,如果用户层设置了套接字为阻塞状态,那么此时该进程就会睡眠,直到有数据到来才被唤醒,或者超时时间到达也会返回用户态。如果该套接字为非阻塞,直接返回到用户态。
6、数据从网卡到应用层的整体流程
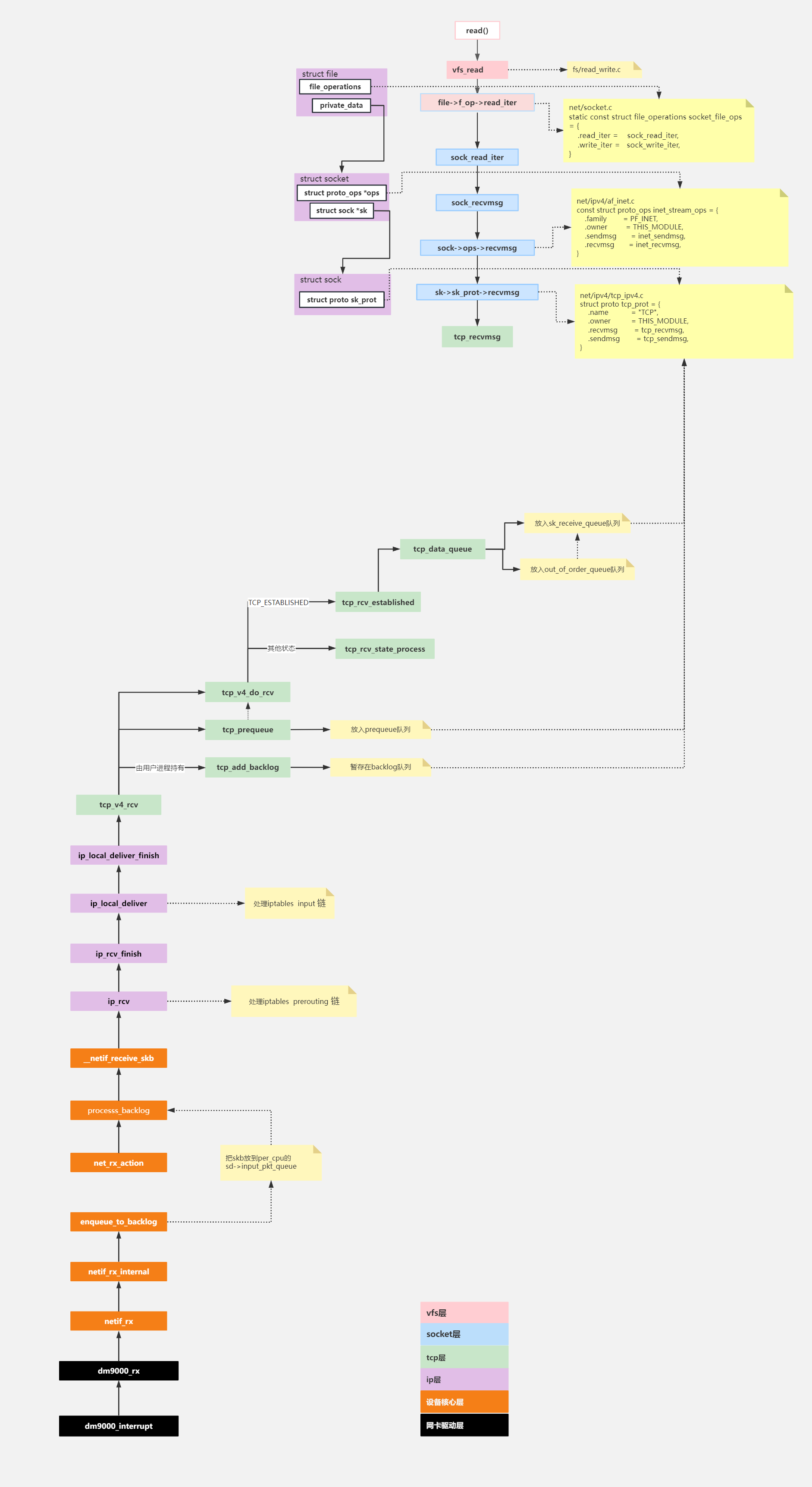









)


--fsee -- ftell -- rewind -- feof函数 -- ferror函数)






(栈溢出的处理办法))