之前的文章中,我们学习了如何在spark中使用RDD方法的flatMap,take,union。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。
Spark-Scala语言实战(8)-CSDN博客文章浏览阅读675次,点赞16次,收藏10次。今天开始的文章,我会带给大家如何在spark的中使用我们的RDD方法,今天学习RDD方法中的flatMap,take,union三种方法。希望我的文章能帮助到大家,也欢迎大家来我的文章下交流讨论,共同进步。https://blog.csdn.net/qq_49513817/article/details/137157697?今天的文章,我会继续带着大家如何在spark的中使用我们的RDD方法。今天学习RDD方法中的filter,distinct,intersection三种方法,并做一道相关例题。
一、知识回顾
昨天我们学习了RDD的三种方法,分别是flatMap,take,union。
flatMap的一般作用是用来切分我们的单词
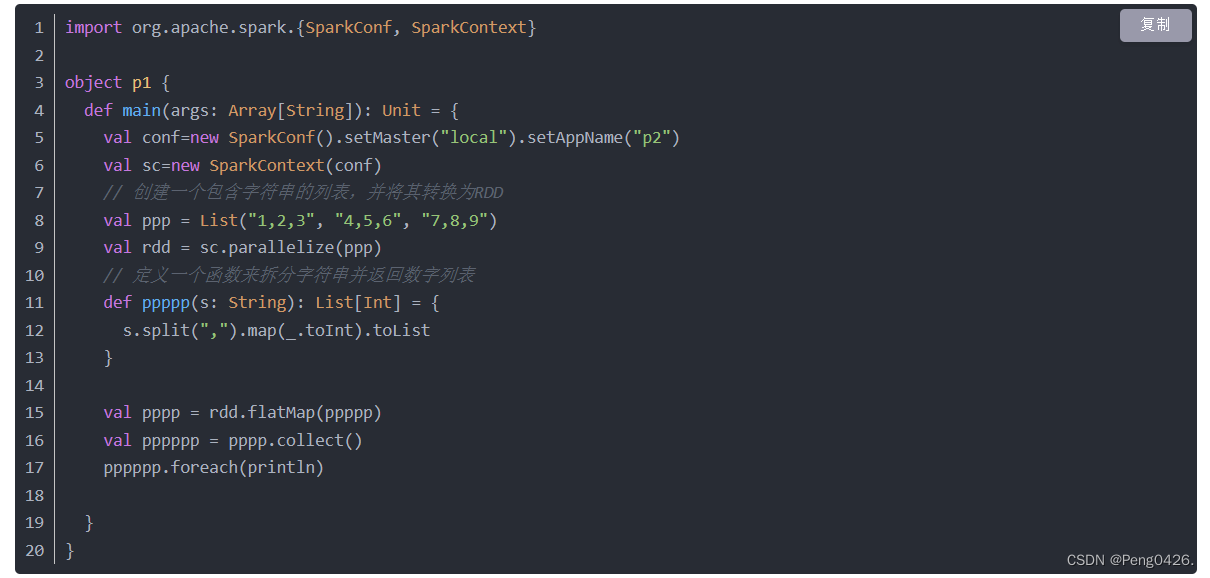
它会构建一个新的RDD
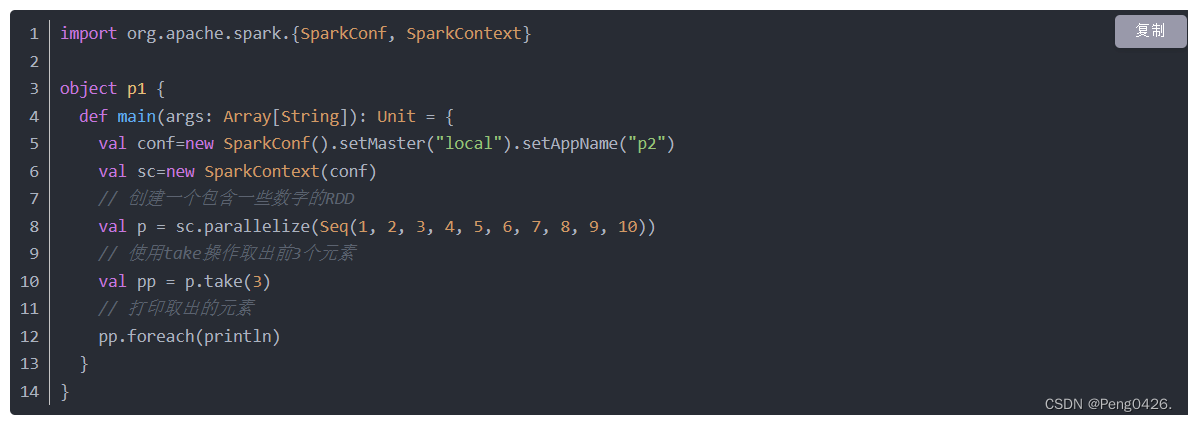
take方法是用来获取我们RDD中前n个元素,n可以自行设置
union可以将我们的两个RDD进行合并操作
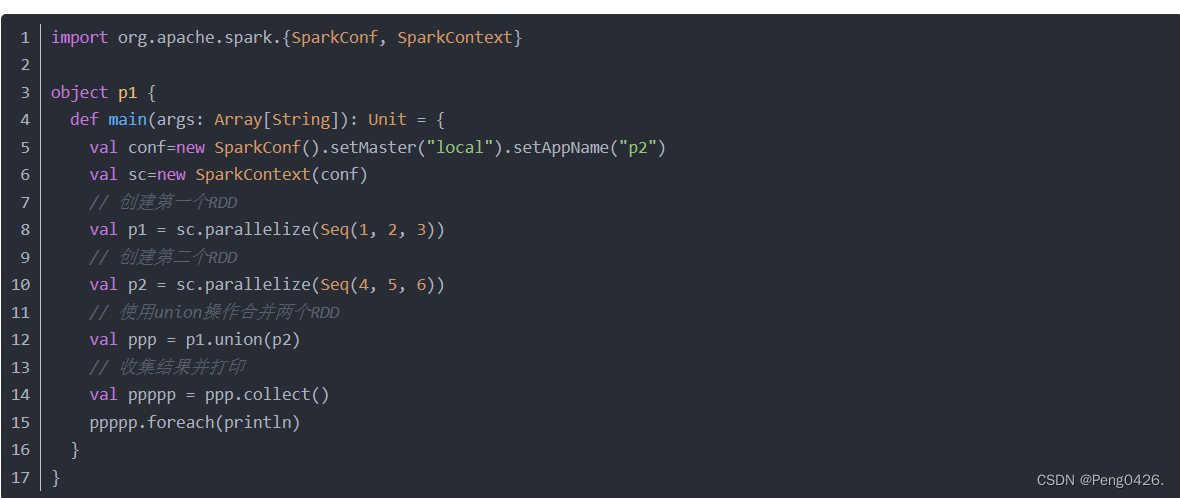
但使用我们的union方法时,需保证两个RDD的数据类型相同,否则无法运行。
现在,开始今天的学习吧。
二、RDD方法
1.filter
- filter()方法是一种转换操作,用于过滤RDD中的元素。
- filter()方法需要一个参数,这个参数是一个用于过滤的函数,该函数的返回值为Boolean类型。
- filter()方法将返回值为true的元素保留,将返回值为false的元素过滤掉,最后返回一个存储符合过滤条件的所有元素的新RDD。
import org.apache.spark.{SparkConf, SparkContext}object p1 {def main(args: Array[String]): Unit = {val conf=new SparkConf().setMaster("local").setAppName("p2")val sc=new SparkContext(conf)val p = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)val rdd = sc.parallelize(p)// 使用filter操作过滤出所有偶数val pp = rdd.filter(x => x % 2 == 0)// 收集结果并打印val ppp = pp.collect()ppp.foreach(println)}
}可以看到我们的代码创建了一个1到10的数组,也可以看到注释中我们的需求是筛出里面包括的偶数,那么我们运行代码得到的就应该是2,4,6,8,10,现在,运行我们的代码看看是否得到预期的值吧。
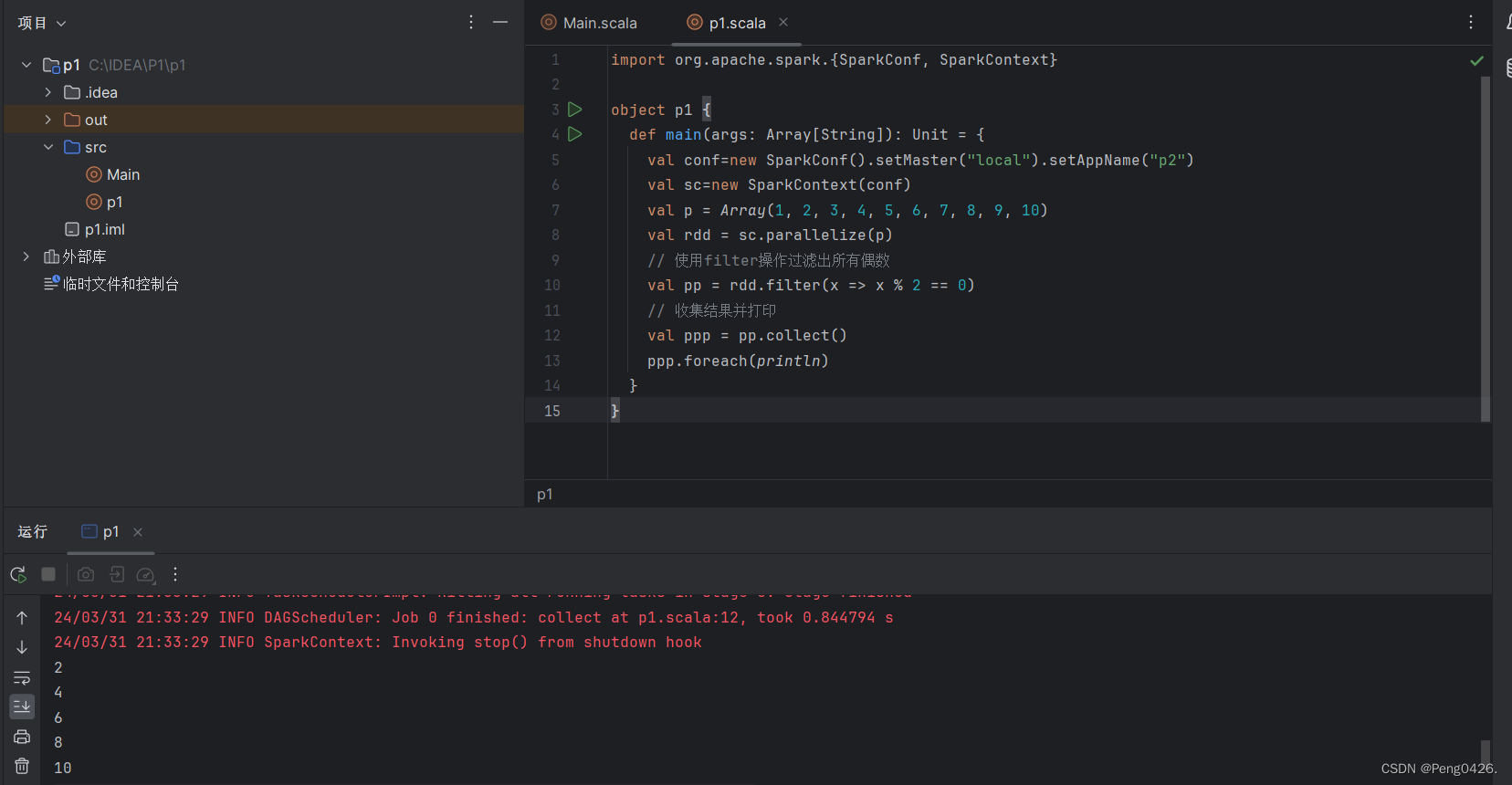
可以看到左下角成功输出代码预期值。
2.distinct
- distinct()方法是一种转换操作,用于RDD的数据去重,去除两个完全相同的元素,没有参数。
import org.apache.spark.{SparkConf, SparkContext}object p1 {def main(args: Array[String]): Unit = {val conf=new SparkConf().setMaster("local").setAppName("p2")val sc=new SparkContext(conf)val p = Array(1, 2, 2, 3, 4, 4, 5, 5, 5)val pp = sc.parallelize(p)// 使用distinct操作去除重复元素val ppp = pp.distinct()// 收集结果并打印val pppp = ppp.collect()pppp.foreach(println)}
}可以看到我们的代码给了一组重复数据特别多的数组,那么我们的distinct方法肯定就是要将它进行降重操作了,那么我们现在运行代码来看一下。
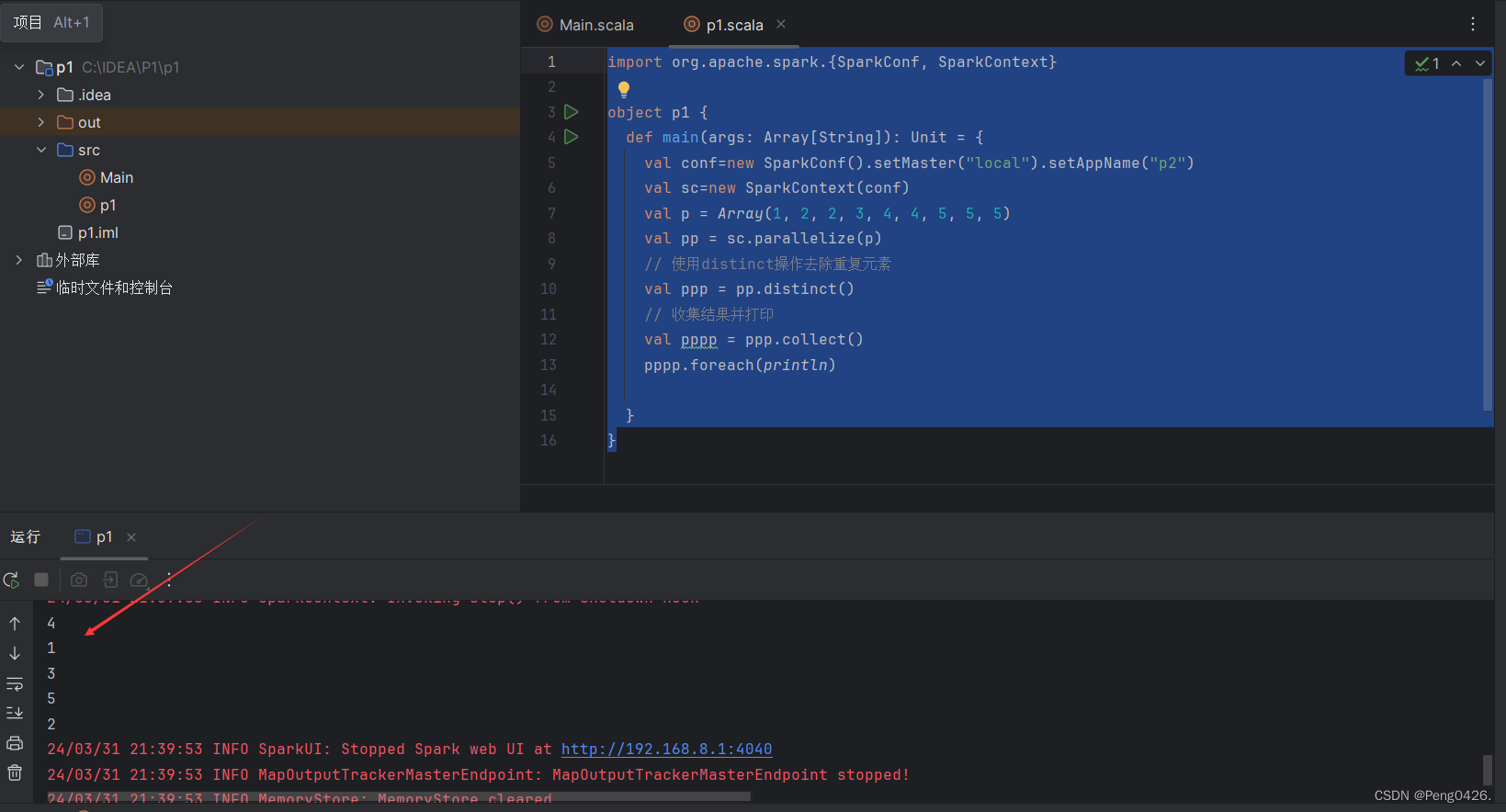
可以看到我们预期的降重实现了,但是它的输出顺序特别混乱,这是因为Spark 的分布式计算模型决定了数据在不同分区之间可能会被打乱,并且在执行 distinct 操作时可能会进行重分区。因此,即使你的输入数组 是有序的,经过 distinct 处理后的输出数组很可能不是有序的。
那么要解决这个问题,我们肯定需要手动排序了
在这里我们就可以使用到sorted进行排序。
val ppppp=pppp.sortedppppp.foreach(println)把这两行代码加到末尾,运行代码

可以看到输出预期中降重并排序的结果了。
3.intersection
- intersection()方法用于求出两个RDD的共同元素,即找出两个RDD的交集,参数是另一个RDD,先后顺序与结果无关。
import org.apache.spark.{SparkConf, SparkContext}object p1 {def main(args: Array[String]): Unit = {val conf=new SparkConf().setMaster("local").setAppName("p2")val sc=new SparkContext(conf)val p1 = sc.parallelize(Array(1, 2, 3, 4, 5))val p2 = sc.parallelize(Array(4, 5, 6, 7, 8))// 计算两个RDD的交集val ppp = p1.intersection(p2)// 收集结果并打印val ppppp = ppp.collect()ppppp.foreach(println)}
} 看代码,我们定义了两个数组,那么既然intersection是求交集,那么运行代码输出的肯定是两个数组中的共同元素,即4,5。运行代码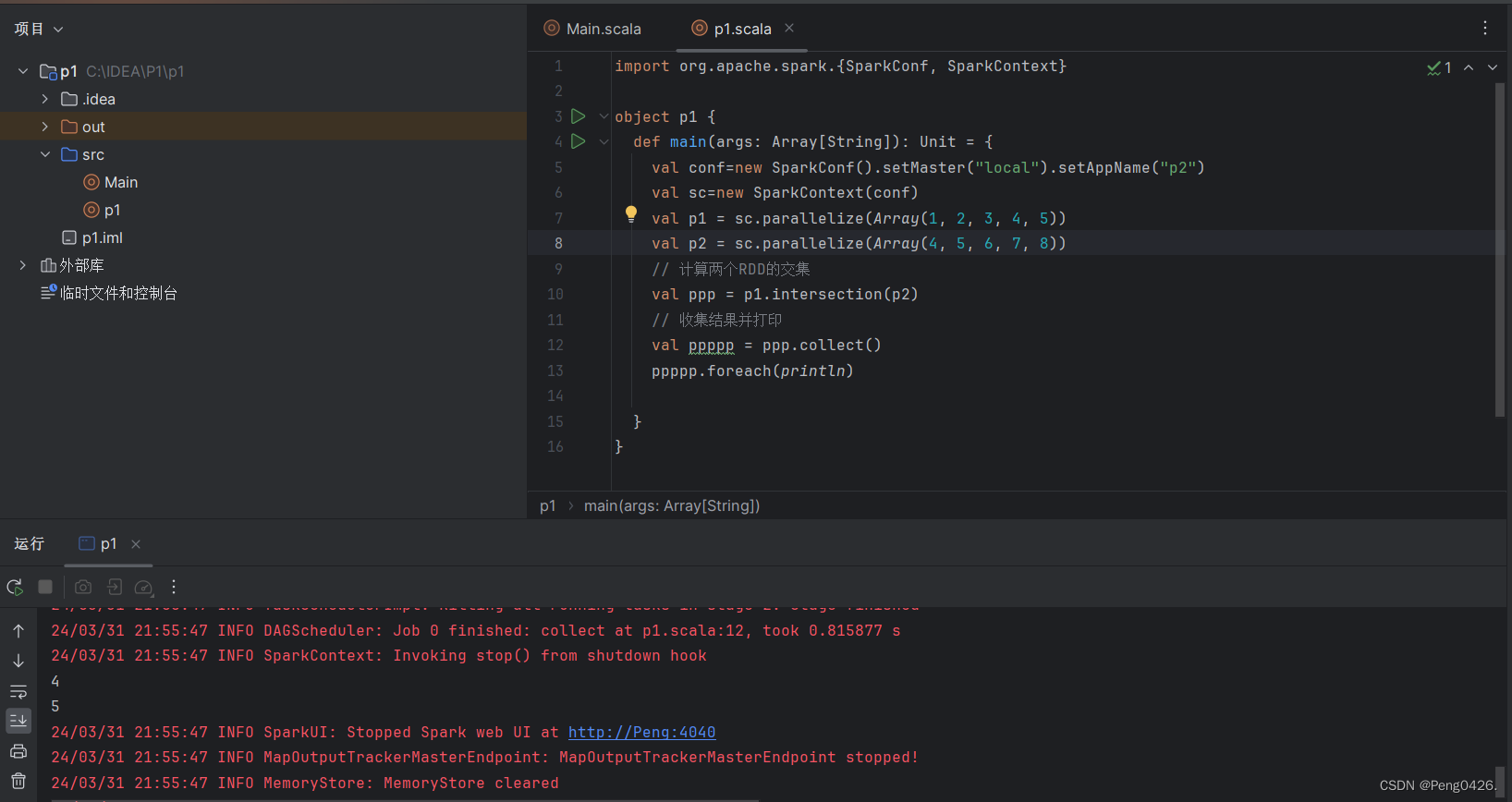
可以看到成功输出我们交集4与5
三、任务实现
现在,我们有两个csv文件,里面有我们大量的薪资信息,我们现在需要做的事情如下:
- 输出上半年或下半年实际薪资大于20万元的员工姓名。
- 首先需要过滤出两个RDD中实际薪资大于20万元的员工姓名。
- 再将两个RDD得到的员工姓名合并到一个RDD中,对员工姓名进行去重。
- 即可得到上半年或下半年实际薪资大于20万元的员工姓名。
想要完成它,并不困难,现在我们把文件放在C盘的根目录下,方便寻找,当然这个位置可以自己随便放。
然后编写我们的代码:
import org.apache.spark.{SparkConf, SparkContext}object p1 {def main(args: Array[String]): Unit = {val conf=new SparkConf().setMaster("local").setAppName("p2")val sc=new SparkContext(conf)// 从C盘根目录读取第一个CSV文件val p1 = sc.textFile("C:\\Employee_salary_first_half.csv")// 从C盘根目录读取第二个CSV文件val p2 = sc.textFile("C:\\Employee_salary_second_half.csv")// 使用mapPartitionsWithIndex方法跳过CSV文件的标题行val pp1 = p1.mapPartitionsWithIndex((ix,it) => {if (ix ==0) it.drop(1)it})val pp2 = p2.mapPartitionsWithIndex((ix, it) => {if (ix == 0) it.drop(1)it})// 将pp1中的每一行转换为(员工名, 工资)元组val ppp1 = pp1.map(Line => {val data = Line.split(",");(data(1),data(6).toInt)})//使用逗号分割每行数据, 提取第二列和第七列数据,并将第七列转换为整数val ppp2 = pp2.map(Line => {val data = Line.split(",");(data(1),data(6).toInt)})val pppp1=ppp1.filter(x => x._2 > 200000).map(x => x._1)// 找出ppp1中工资超过200,000的元组,并只保留员工名val pppp2=ppp2.filter(x => x._2 > 200000).map(x => x._1)//x._n,n即使你要找的元素,通过 ._1 来访问第一个元素 a,通过 ._2 来访问第二个元素 b。val ppppp=pppp1.union(pppp2).distinct()//合并并降重ppppp.collect().foreach(println)//逐行打印}
}我们先读取了两个文件,在将文件的标题行进行跳过,再分割数据找出需要的两行,最后找出工资大于200000的数据打印
来看看运行效果
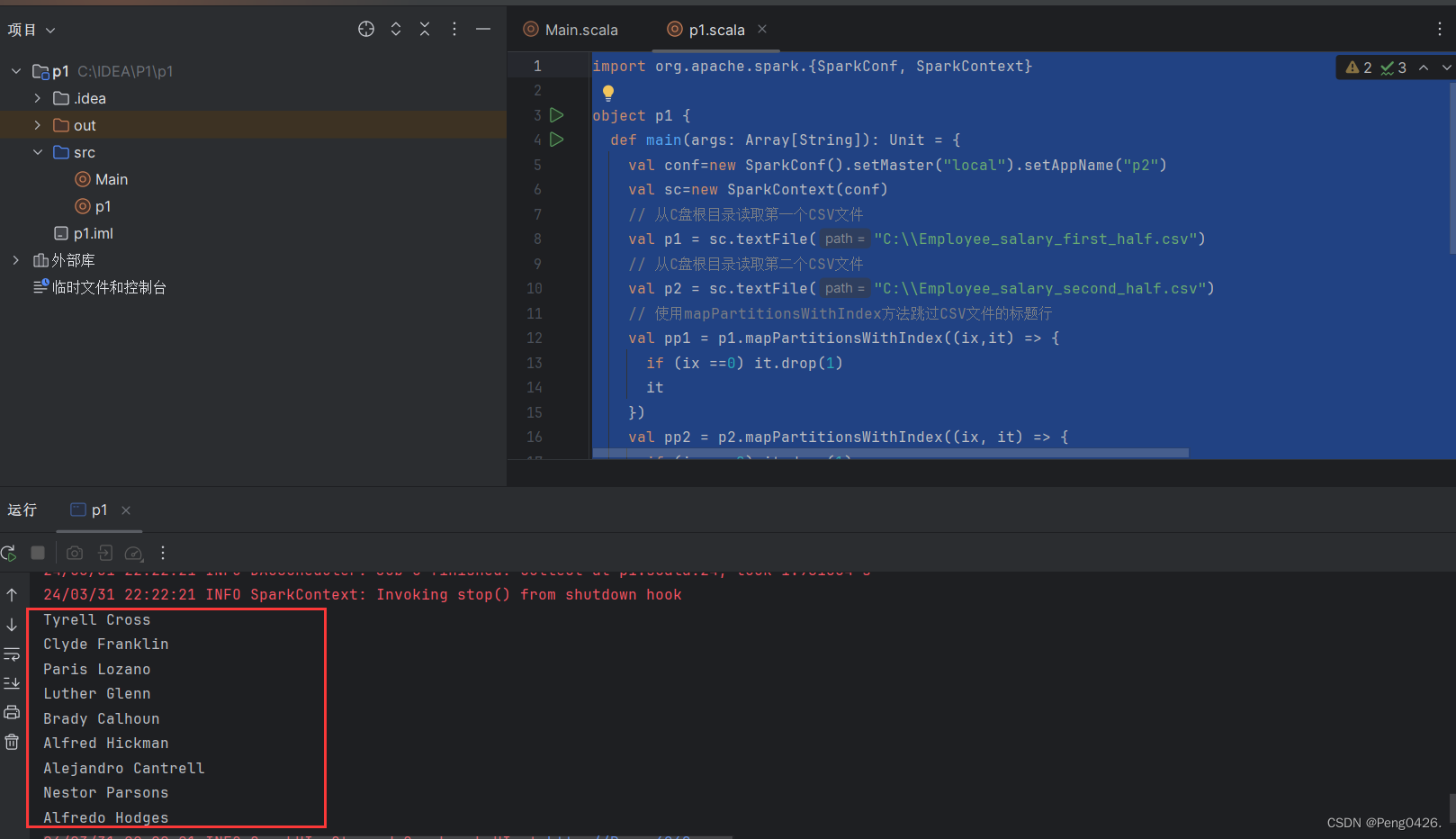
可以看到我们预期的输出效果达到了。
拓展-方法参数设置
| 方法 | 参数 | 描述 | 使用例子 | 不同参数/效果 |
|---|---|---|---|---|
| filter | func | 对RDD中的每个元素应用函数func,返回True的元素保留,返回False的元素被过滤掉 | rdd.filter(lambda x: x > 3) | 通过修改func,可以定义不同的过滤条件,从而保留或过滤掉不同的元素。例如,lambda x: x % 2 == 0会保留偶数。 |
| distinct | 无 | 返回一个包含RDD中所有不同元素的新RDD,去重 | rdd.distinct() | 此方法没有参数,它直接返回一个新的RDD,其中包含了原始RDD中的所有不同元素。这对于去除重复项非常有用。 |
| intersection | other | 返回当前RDD与另一个RDDother的交集,结果中不包含重复元素 | rdd1.intersection(rdd2) | other参数指定了另一个RDD,该方法将返回两个RDD中共有的元素。改变other的值将会影响交集的结果。 |






)






)


)
|491. 非递减子序列、46. 全排列、47. 全排列 II(JAVA))

