文章目录
- 前言
- 补充:各种门电路符号
- 一、半加器
- 二、全加器
- 三、串行进位加法器
- 3.1、verilog代码设计
- 四、超前进位加法器
- 4.1、verilog代码设计
- 五、进位链CARRY4
前言
在之前一篇介绍7系列FPGA底层资源的时候,我们提到过每一个slice当中有一个CARRY4,CARRY4本质上就是用来实现最基本的加、减法运算的,在了解CARRY4之前,我们需要对1bit以及多bit的二进制加法及其FPGA实现做一个了解。
1bit的二进制加法可以分为两类:无底层进位的半加器与有底层进位的全加器。减法运算本质上仍是一种加法运算,在二进制电路中采用加上负数的补码实现。
补充:各种门电路符号
图片来自:https://blog.csdn.net/qq_36001281/article/details/126831226

一、半加器
半加器电路是指对两个输入数据位相加,输出一个结果位和进位,没有进位输入的加法器电路。

结果 S = A ^ B;
进位 C = AB;
VIVADO当中的RTL电路图:

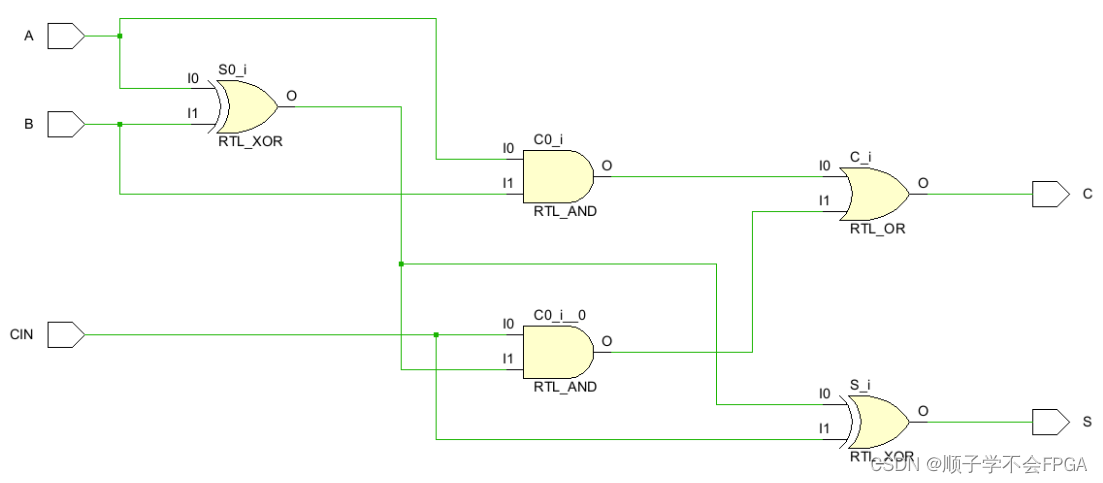
二、全加器
全加器是在半加器的基础上的升级版,除了加数和被加数加和外还要加上前上一级传进来的进位信号。

结果 S= A ^ B ^ Cin;
进位 C = (A&B) | (Cin & (A^B) ;
三、串行进位加法器
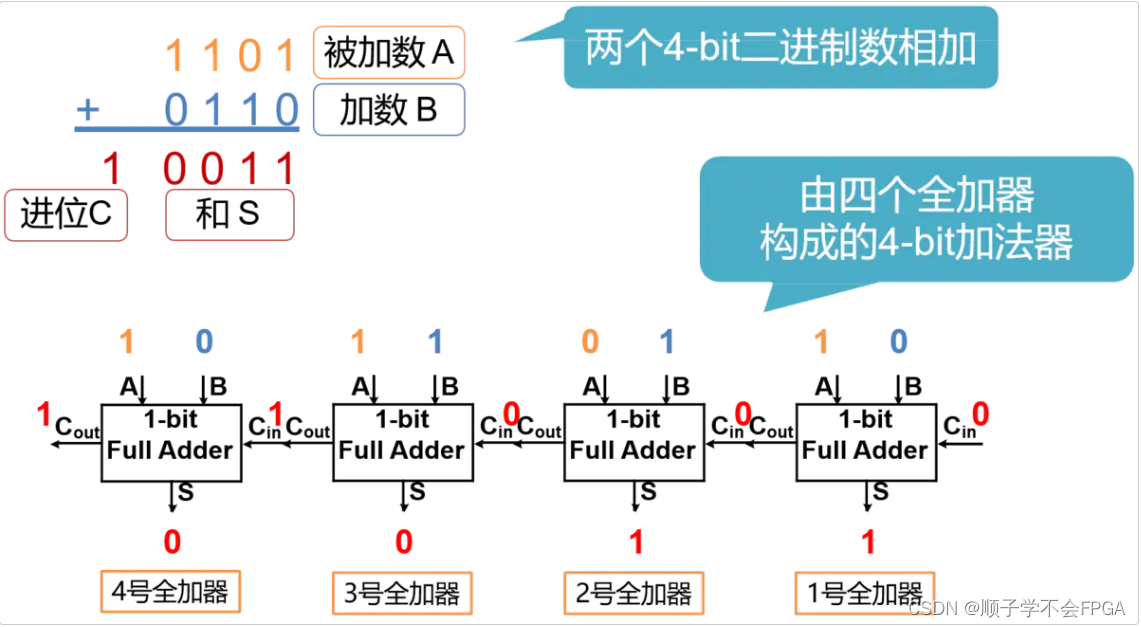
多bit加法(以4bit为例)
有了单个bit的二进制加法电路(全加器)后,我们就可以通过级联来实现多bit的二进制加法了,但是多个全加器如何级联则是一个需要考虑的问题。
参考链接:https://cloud.tencent.com/developer/article/2097257
进行两个4bit的二进制数相加,就要用到4个全加器。那么在进行加法运算时,首先准备好的是1号全加器的3个input。而2、3、4号全加器的Cin全部来自前一个全加器的Cout,只有等到1号全加器运算完毕,2、3、4号全加器才能依次进行进位运算,最终得到结果。 这样进位输出,像波浪一样,依次从低位到高位传递, 最终产生结果的加法器,也因此得名为行波进位加法器(Ripple-Carry Adder,RCA)。
RCA的优点是电路布局简单,设计方便, 我们只要设计好了全加器,连接起来就构成了多位的加法器。 但是缺点也很明显,也就是高位的运算必须等待低位的运算完成, 这样造成了整个加法器的延迟时间很长。要对一个电路的性能进行分析,我们就要找出其中的最长路径。 也就是找出所有的从输入到输出的电路连接中,经过的门数最多的那一条,也称为关键路径。
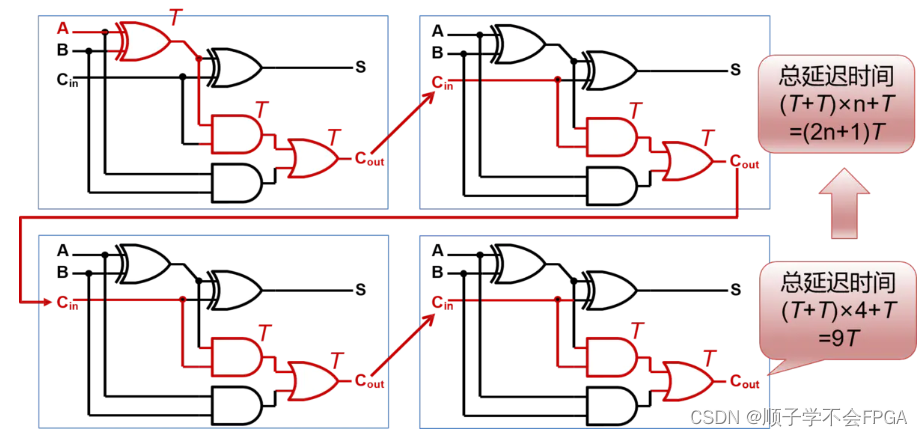
从第一个全加器的A-S这条通路来看,产生第一个S输出,需要通过两个门的延迟。 所以它显然不是最长的路径,当然,从A出发或着从B出发都是一样的, 所以对于第一个全加器,它的最长路径,是红色线标记的那条,后面的全加器关键路径同理可得。那么,假设经过一个门电路的延迟时间为T,那么经过4个全加器所需要的总延迟时间就是:2T x 4 + T(第一个全加器产生3个T) = 9T。所以推出,经过n个全加器所产生的总延迟时间为2T x n + T = (2n+1)T。
对于一个32bit的RCA,有总延迟时间:(2n+1)T =(2×32+1)×T =65T,这是什么概念呢?举个例子,iPhone 5s的A7 SoC处理器采用28nm制造工艺,主频1.3GHz(0.66ns)。按照这个工艺水平,门延迟T设为0.02ns,那么32-bit RCA的延迟时间为1.3ns ,时钟频率为769MHz,远超A7处理器的主频延迟时间,更别说这个32bit的RCA只是一个加法运算器,更更别说,我们在计算过程中只考虑了门延迟,还有线延迟等各种延迟没有加入计算……
3.1、verilog代码设计
4bit行波进位加法器
module RCA_4(input [3:0] A_in ,input [3:0] B_in ,input C_1 ,output wire CO ,output wire [3:0] S
);
//RCA
wire [3+1 :0] C;
assign C[0] = C_1;
assign CO = C[3+1];genvar i;
generate
for(i = 0; i < 4; i = i + 1)beginfull_adder full_adder_u(.a (A_in[i]),.b (B_in[i]),.ci (C[i]),.s (S[i]),.co (C[i+1]));end
endgenerateendmodule//1bit全加器是行波进位加法器的基础
module full_adder(input a,input b,input ci,//进位输入output s,output co//进位输出
);assign s = a ^ b ^ ci;
assign co = a & b | (ci & (a^b));endmodule
四、超前进位加法器
对于RCA,上一位的进位输出需要作为下一位的进位输入,因此,随着加法器位宽的增大,加法器的延时也会线性增大,究其原因,就是下一个比特位对上一个比特位的依赖造成的,超前进位加法器就是解决了这个问题,而实现低延时的效果。那我们的优化思路就是‘能否提前计算出“进位输出信号”
首先根据进位 Ci= (A&B) | (Ci-1 & (A^B) ;我们可以知道该了第i+1位的进位输出和第i位的进位输出之间的关系,如果我们用Ci-1代替上式中的Ci,则可以得到Ci+1和Ci-1之间的关系,进一步将Ci-1用Ci-2表示,一直迭代到C0,即Cin,我们发现,此时进位输出不再依赖于前面任何一级加法器的结果,因此也就达到了我们要的效果。
图片来源:https://cloud.tencent.com/developer/article/2097257



4.1、verilog代码设计
module lca_4(input [3:0] A_in ,input [3:0] B_in ,input C_1 ,output wire CO ,output wire [3:0] S
);//LCA
wire [3 :0] G;
wire [3 :0] P;
wire [3+1 :0] C;assign C[0] = C_1;
assign C[1] = G[0] || (C[0] & P[0]);
assign C[2] = G[1] || ((G[0] || (C[0] & P[0])) & P[1]);
assign C[3] = G[2] || ((G[1] || ((G[0] || (C[0] & P[0])) & P[1])) & P[2]);
assign C[4] = G[3] || ((G[2] || ((G[1] || ((G[0] || (C[0] & P[0])) & P[1])) & P[2])) & P[3]);assign CO = C[4];genvar i;
for( i=0; i<4; i=i+1) beginpg_gen u_pg_gen(.A( A_in[i]),.B( B_in[i]),.G( G[i] ),.P( P[i] ));
endgenvar k;
for( k=0; k<4; k=k+1) beginassign S[k] = P[k] ^ C[k];
endendmodule
//生成信号G与传播信号P生成模块
module pg_gen(input A,input B,output G,output P
);assign G = A & B;assign P = A ^ B;
endmodule
五、进位链CARRY4
Xilinx 7系列FPGA底层的加法器(进位链)CARRY4是一种超前进位的加法器(U+系列为CARRY8),但是为了面积与普适性其实现原理与上述的CLA电路还是有一点区别。每个SLICE中都有1个(每个CLB则有2个)CARRY4用来实现进位逻辑,不同的进位链可级联以形成更宽的加/减逻辑:


)
,CPO-RF-Adaboost,CPO优化随机森林RF-Adaboost回归预测-附代码)

![[lesson01]学习C++的意义](http://pic.xiahunao.cn/[lesson01]学习C++的意义)


)


)





)

:模板方法模式)
