SQL,group by分组后分别计算组内不同值的数量
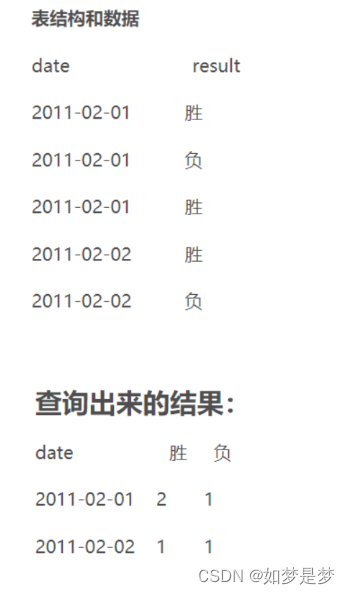
如现有一张购物表shopping

先要求小明和小红分别买了多少笔和多少橡皮,形成以下格式

SELECT 'name',COUNT(*)
FROM 'shopping'
GROUP BY 'name';SELECT name AS 姓名,SUM( CASE WHEN cargo = '笔' THEN 1 ELSE 0 END) AS 笔, SUM(CASE WHEN cargo = '橡皮' THEN 1 ELSE 0 END) AS 橡皮 FROM shopping GROUP BY name;注:这里不能用count计算行数,count只是分组后每组有行的数目
MySQL中case when then else end 的用法
语法:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
END;
SElECT
CASE ----------------------------如果
WHEN sex = '1' THEN '男' ----------------------------Sex=‘1’,则返回值‘男’
WHEN sex = '2' THEN '女' ----------------------------Sex=‘2’,则返回值‘女’
ELSE 0 ----------------------------其他的返回‘其他’
ND ----------------------------结束
from user ----------------------------整体理解:在user表中如果 sex=‘1’,则返回值‘男’;如果
sex=‘2’,则返回值‘女
----用法一:
SELECT
CASE
WHEN STATE = '1' THEN '成功'
WHEN STATE = '2' THEN '失败'
ELSE '其他'
END
FROM TABLE
---用法二:
SELECT STATE
CASE
WHEN '1' THEN '成功'
WHEN '2' THEN '失败'
ELSE '其他'
END
FROM table

案例:有员工表empinfo employee(员工)
CREATE TABLE 'EMPINFO' ('id' INT(11) NOT NULL AUTO_INCREMENT,'name' VARCHAR(10) NOT NULL,'age' INT(11) NOT NULL,'SALARY' INT(11) NOT NULL,PRIMARY KEY('id')
)假如数据量很大约1000万条;写一个你认为最高效的SQL,用一个SQL计算以下四种人:
salary>9999 and age>35
salary>9999 and age<35
salary<9999 and age>35
salary<9999 and age<35
每种员工的数量;
SELECT SUM(CASE WHEN salary>9999 AND age>35 THEN 1 ELSE 0 END) AS 'salary>9999 age>35',SUM(CASE WHEN salary>9999 AND age<35 THEN 1 ELSE 0 END) AS 'salary>9999 age<35',SUM(CASE WHEN salary<9999 AND age>35 THEN 1 ELSE 0 END) AS 'salary<9999 age>35',SUM(CASE WHEN salary<9999 AND age<35 THEN 1 ELSE 0 END) AS 'salary<9999 age<35'
FROM empinfo; 
练习:用一个sql语句完成下面不同条件的分组
有如下数据:

按照国家和性别进行分组,得出如下结果:
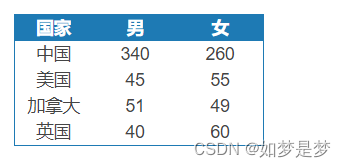
SELECT country,
SUM ( CASE WHEN sex = '1' THEN
population ELSE 0 END),
SUM ( CASE WHEN sex = '2' THEN
popution ELSE 0 END)
FROM Table_A
GROUP BY country;
根据条件有选择的UPDATE。
例,有如下更新条件
工资5000以上的员工,工资减少10%
工资在2000到4600之间的员工,工资增加15%
很容易考虑的是选择执行两次UPDATE语句,如下所示
----条件一:
UPDATE Personnel
SET salary = salary * 0.9
WHERE salary >= 5000;
----条件二:
UPDATE Personnel
SET salary = salary*1.15
WHERE salary >= 2000 AND salary < 4600;
但是事情没有想象的那么简单,假设有个人工资5000块。首先,按照条件1,工资减少10%,变成工资4500.接下来运行第二个SQL的时候,因为这个人的工资是4500在2000到4600的范围之内,需要增加15%,最后这个人的工资结果是5175,不但没有减少,反而还增加了。如果反过来执行,那么工资4600的人相反会变成减少工资。暂且不管这个规章是多么荒诞,如果想要一个SQL语句实现这个功能的话,我们需要用到Case函数。代码如下:
UPDATE PersonnelSET salary = CASE WHEN salary >= 5000 THEN salary * 0.9WHEN salary >= 2000 AND salary < 4600 THEN salary * 1.15ELSE salary END;这里要注意一点,最后一行的ELSE salary 是必须的,要是没有这行,不符合这两个条件的人的工资将会被写成NULL,那可就大事不妙了。在Case函数中Else部分的默认值是NULL,这点是需要注意的地方。

update T
set A = casewhen A > 100 then A = A-100when A < 100 then A = A+100else A end;
SELECT courseid, coursename,score,(CASE WHEN score < 60 THEN 'fail' ELSE 'pass' END) AS mark FROM course
SELECT DISTINCT 工单,制令号 FROM gomgdan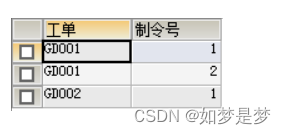
要求统计表gongdan中:工单·+制令号不重复的所有记录的数量
把中间查询到的结果当成一张表使用
SELECT COUNT(*) FROM (SELECT DISTINCT 工单,制令号 FROM gongdan) AS B
SELECT salary FROM employee GROUP BY salary DESC LIMIT 1, 1;SELECT IFNULL
((SELECT salary FROM employee GROUP BY salary DESC LIMIT 1,1),NULL)
AS SecondHighestSalary;IFNULL(expr1,expr2)
如果expr1不是NULL,IFNULL()返回expr1,否则它返回expr2
拷贝表(拷贝数据,源表名:a 目标表名:b)
SQL:insert into b(a,b,c) select d, e, f from a;
insert into b(a,b,c) select a,b,c from b;

)





)










18V/2A同步降压芯片快速瞬态响应逐周期限流保护)
