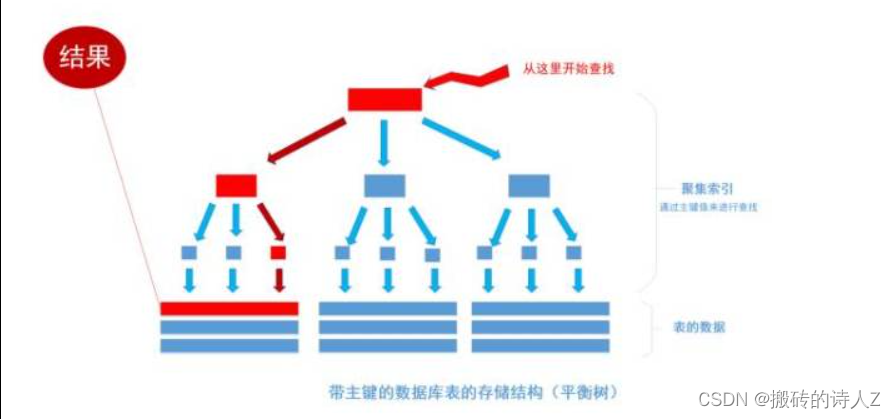
聚簇索引(Clustered Index)和非聚簇索引(Non-clustered Index)是数据库中两种不同的索引类型,它们的主要区别在于数据的存储方式和索引的结构:
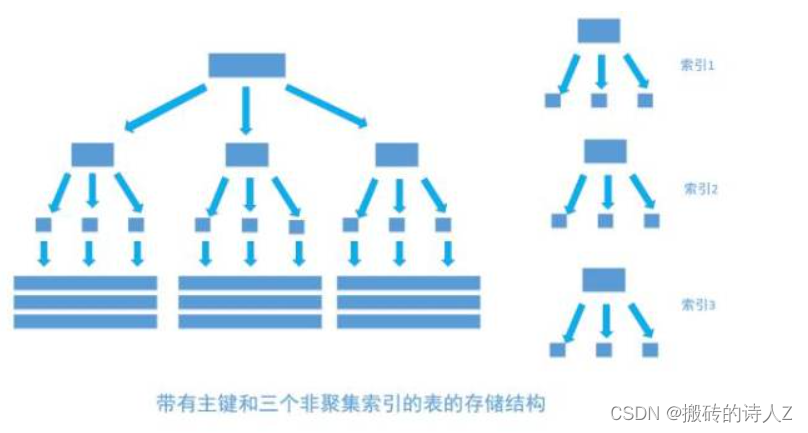
数据存储方式:
聚簇索引:索引的叶子节点存储的是数据行本身,而不是指向数据行的指针。换句话说,聚簇索引决定了数据的物理存储顺序,因此表中的数据行实际上是按照聚簇索引的顺序存储的。
非聚簇索引:索引的叶子节点存储的是指向数据行的指针,而不是数据行本身。这意味着索引和数据的物理存储顺序是分开的,索引仅提供了一种查找数据行的途径,而不决定数据的实际存储顺序。
适用场景:
聚簇索引:适合经常需要范围查询或顺序访问的列,因为相关的数据行在物理上是相邻存储的,这样可以提高范围查询的性能。一张表只能有一个聚簇索引,通常是主键索引。
非聚簇索引:适合经常需要单值查找或跳跃式访问的列,因为索引存储的是指向数据行的指针,可以快速定位到需要的数据行。一张表可以有多个非聚簇索引。
维护成本:
聚簇索引:由于数据行的物理存储顺序和索引的顺序是一致的,因此插入、更新和删除操作可能需要重新组织数据行的存储顺序,这可能会导致性能损失。
非聚簇索引:插入、更新和删除操作通常只需要


 4.1 梯度下降)







从零基础入门到精通,看完这一篇就够了)
:求解整数规划的切平面法(cutting plane method))




)


)