训练集、测试集和验证集是在机器学习和数据科学中常用的术语,用于评估和验证模型的性能。它们通常用于监督学习任务中。
1. 训练集(Training Set):训练集是用于训练机器学习模型的数据集。在训练期间,模型使用训练集中的样本来学习特征和模式,以便做出预测或分类。
2. 测试集(Test Set):测试集是用于评估训练好的模型性能的数据集。在模型训练完成后,测试集被用来验证模型对未知数据的泛化能力。模型在测试集上的表现可以帮助评估模型的准确性和性能。
3. 验证集(Validation Set):验证集是用于调整模型超参数和评估模型性能的数据集。在训练过程中,验证集用来调整模型的参数,以防止模型在训练集上过拟合。验证集的表现可以帮助选择最佳的模型参数。
这些数据集的使用可以帮助确保模型在真实数据上的准确性和泛化能力。在实际应用中,通常会将原始数据分成训练集、测试集和验证集,通常的划分比例是70%的数据用于训练,20%的数据用于测试,10%的数据用于验证。
//有些项目当中存在只有训练集和测试集情况,或是数据量较小,不便细分;又或是项目验证是通过加载训练过程保存的最后一个模型。
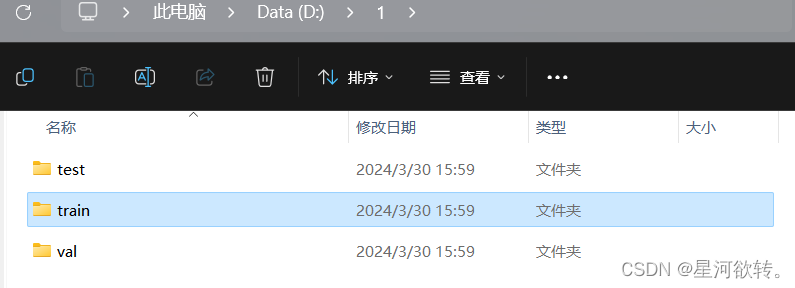
//这里我们有两种划分数据集的方式,第一种是把原有的数据划分到三个文件夹里面,第二种是划分为.txt文件目录形式。
第一种:
import os
import random
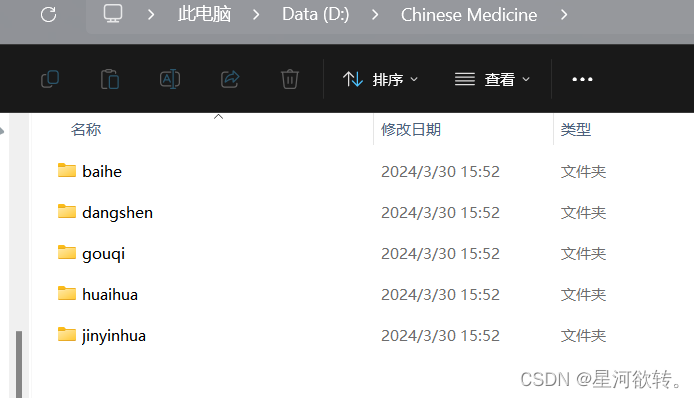
from shutil import copy2def data_set_split(src_data_folder, target_data_folder, train_scale=0.8, val_scale=0.0, test_scale=0.2):'''读取源数据文件夹,生成划分好的文件夹,分为trian、val、test三个文件夹进行:param src_data_folder: 源文件夹 E:/biye/gogogo[表情]te_book/torch_note/data/utils_test/data_split[表情]c_data:param target_data_folder: 目标文件夹 E:/biye/gogogo[表情]te_book/torch_note/data/utils_test/data_split/target_data:param train_scale: 训练集比例:param val_scale: 验证集比例:param test_scale: 测试集比例:return:'''print("开始数据集划分")class_names = os.listdir(src_data_folder)# 在目标目录下创建文件夹split_names = ['train', 'val', 'test']for split_name in split_names:split_path = os.path.join(target_data_folder, split_name)if os.path.isdir(split_path):passelse:os.mkdir(split_path)# 然后在split_path的目录下创建类别文件夹for class_name in class_names:class_split_path = os.path.join(split_path, class_name)if os.path.isdir(class_split_path):passelse:os.mkdir(class_split_path)# 按照比例划分数据集,并进行数据图片的复制# 首先进行分类遍历for class_name in class_names:current_class_data_path = os.path.join(src_data_folder, class_name)current_all_data = os.listdir(current_class_data_path)current_data_length = len(current_all_data)current_data_index_list = list(range(current_data_length))random.shuffle(current_data_index_list)train_folder = os.path.join(os.path.join(target_data_folder, 'train'), class_name)val_folder = os.path.join(os.path.join(target_data_folder, 'val'), class_name)test_folder = os.path.join(os.path.join(target_data_folder, 'test'), class_name)train_stop_flag = current_data_length * train_scaleval_stop_flag = current_data_length * (train_scale + val_scale)current_idx = 0train_num = 0val_num = 0test_num = 0for i in current_data_index_list:src_img_path = os.path.join(current_class_data_path, current_all_data[i])if current_idx <= train_stop_flag:copy2(src_img_path, train_folder)# print("{}复制到了{}".format(src_img_path, train_folder))train_num = train_num + 1elif (current_idx > train_stop_flag) and (current_idx <= val_stop_flag):copy2(src_img_path, val_folder)# print("{}复制到了{}".format(src_img_path, val_folder))val_num = val_num + 1else:copy2(src_img_path, test_folder)# print("{}复制到了{}".format(src_img_path, test_folder))test_num = test_num + 1current_idx = current_idx + 1print("*********************************{}*************************************".format(class_name))print("{}类按照{}:{}:{}的比例划分完成,一共{}张图片".format(class_name, train_scale, val_scale, test_scale, current_data_length))print("训练集{}:{}张".format(train_folder, train_num))print("验证集{}:{}张".format(val_folder, val_num))print("测试集{}:{}张".format(test_folder, test_num))if __name__ == '__main__':src_data_folder = r"D:\Chinese Medicine" # todo 原始数据集目录target_data_folder = r"D:\1" # todo 数据集分割之后存放的目录data_set_split(src_data_folder, target_data_folder)
手把手教你用tensorflow2.3训练自己的分类数据集_tensorflow训练自己的数据集-CSDN博客
第二种:
#划分训练集和测试集并生成数据列表
def get_data_list(target_path,train_list_path,eval_list_path):trainer_list=[]eval_list=[]class_detail = [] #存放所有类别的信息data_list_path=target_path+"Chinese Medicine/" #获取所有类别保存的文件夹名称class_dirs = os.listdir(data_list_path) all_class_images = 0class_label=0 #存放类别标签class_num = 0#读取每个类别for class_dir in class_dirs:if class_dir != ".DS_Store":class_num += 1class_detail_list = {}eval_sum = 0trainer_sum = 0class_sum = 0path = data_list_path + class_dir #获取类别路径 # 获取所有图片img_paths = os.listdir(path)# 遍历文件夹下的每个图片for img_path in img_paths: name_path = path + '/' + img_path if class_sum % 8 == 0: # 每8张图片取一个做验证数据eval_sum += 1 eval_list.append(name_path + "\t%d" % class_label + "\n")else:trainer_sum += 1 trainer_list.append(name_path + "\t%d" % class_label + "\n")class_sum += 1 all_class_images += 1 class_detail_list['class_name'] = class_dirclass_detail_list['class_all_images'] = trainer_sum + eval_sum class_detail_list['class_label'] = class_label class_detail_list['class_trainer_images'] = trainer_sumclass_detail_list['class_eval_images'] = eval_sum class_detail.append(class_detail_list) #初始化标签列表train_parameters['label_dict'][str(class_label)] = class_dirclass_label += 1 #初始化分类数train_parameters['class_num'] = class_num#乱序 random.shuffle(eval_list)with open(eval_list_path, 'a') as f:for eval_image in eval_list:f.write(eval_image) random.shuffle(trainer_list)with open(train_list_path, 'a') as f2:for train_image in trainer_list:f2.write(train_image) # 说明的json文件信息readjson = {}readjson['all_class_name'] = data_list_path #文件父目录readjson['all_class_images'] = all_class_imagesreadjson['class_detail'] = class_detailjsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(',', ': '))with open(train_parameters['readme_path'],'w') as f:f.write(jsons)
print ('已生成数据列表')#相关路径的定义
train_parameters = {"target_path":r"D:\\2\\", "train_list_path": r"D:\\2\\train.txt", "eval_list_path": r"D:\\2\\eval.txt", "label_dict":{}, "readme_path": r"D:\\2\\readme.json", "class_num": -1,
}import os
import random
import jsontarget_path=train_parameters['target_path']
train_list_path=train_parameters['train_list_path']
eval_list_path=train_parameters['eval_list_path']#读取文件时初始化
with open(train_list_path, 'w') as f: f.seek(0)f.truncate()
with open(eval_list_path, 'w') as f: f.seek(0)f.truncate() #生成数据列表
get_data_list(target_path,train_list_path,eval_list_path) 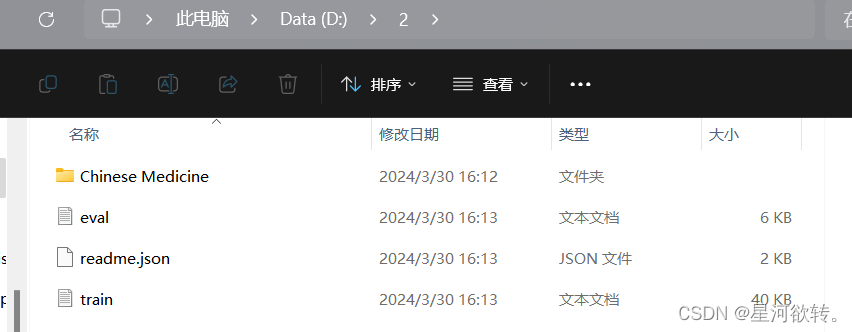




)
)



)

)
 (47))






)