1、总体概述
基于深度学习的目标检测在常规条件的数据集可以获得不错的结果,但是在环境、场景、天气、照度、雾霾等自然条件的综合干扰下,深度学习模型的适应程度变低,检测结果也随之下降,因此研究在复杂气象条件下的目标检测方法就显得尤为重要。现有的方法在增强图像和目标检测之间很难做到平衡,有的甚至忽略有利于检测的信息。
本文为了解决上述问题,提出了IA-YOLO架构,该架构可以自适应的增强图像,以获得更好的检测结果。文中提出一个可微分的图像处理模块DIP,DIP使用轻量级的深度学习网络(CNN-PP)学习其参数,用以提高复杂天气状况下的目标检测性能。将DIP插入YOLOV3中,直接使用原有检测模型的分类和回归损失来弱监督DIP模块的参数,进而可以使用DIP模块进行图像增强。IA-YOLO代码tensorflow版本链接
2、IA-YOLO整体架构
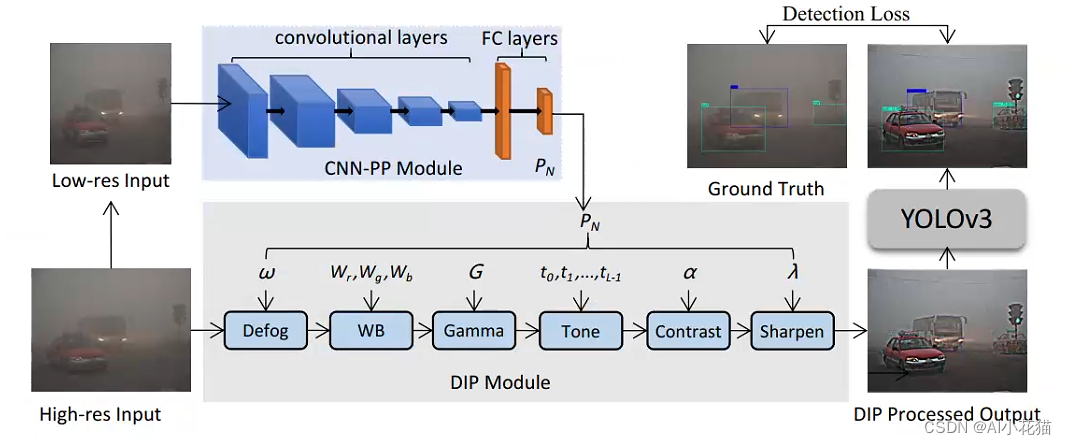
高分辨率的图像(如1920*1080),缩放到低分辨率的图像(256*256),低分辨率的图像通过一个轻量级的CNN-PP模块,学习一组参数,文中在去雾过程中参数为15个,因此输出为【N,15】;高分辨率的图像,依次通过去雾、白平衡、Gamma增强、Tone、对比度Contrast、锐化Sharpen进行图像的增强操作,这个过程可以看作是图像的预处理阶段,预处理增强过后的图片,送入传统的YOLOV3检测器进行目标物体的检测,使用预测框和GT框的之间的分类和回归损失进行整个网络结构的监督,进而使得DIP模块学到自适应的参数。
3、可微过滤器介绍
3.1 Pixel-wise Filters
像素级的过滤器实际上就是对输入图像每个像素R、G、B三个通道的数值通过一定的映射,输出相对应的R、G、B三个通道的数值。文中提到四个Pixel-wise Filters,它们的映射关系函数如表所示。

由表可知,WB和Gamma都是通过简单的乘法以及幂指数变化来进行像素值的转换,因此,它们对于输入图像和需要学习的参数来说都是可微分的。
对于contrast的可微分设计,作者采用如下三个公式完成:
对于Tone滤波器,作者将其设计成为一个单调分段函数,学习Tone filter需要使用L个参数,参数分别为,tone曲线的点可表示为
,其中
。最终的映射函数为:
3.2 Sharpen Filter
图像锐化可以凸显图像的细节信息,作者使用如下公式进行图像的锐化:
其中,是输入图像,
是对图像进行高斯变换,
是一个大于0的缩放比例系数。
3.3 Defog Filter
去雾模型主要就是使用了大气散射模型,结合暗通道先验进行推算初来的结果,其中大气散射模型公式如下所示:
其中A是全球大气光值,t(x)是转换参数,其定义如下:
去雾模型的具体过程参考之前的文章:Single Image Haze Removal Using Dark Channel Prior(暗通道先验)
4、CNN-PP模块
由前述网络的整体框架可知,CNN-PP是一个轻量级的全卷积网络,其输入是一个低分辨率的256*256图像,输出是一个【N,15】的向量,网络的具体结构可以看文中具体描述:

作者使用tensorflow实现的具体代码如下:
def extract_parameters(net, cfg, trainable):output_dim = cfg.num_filter_parameters# net = net - 0.5min_feature_map_size = 4print('extract_parameters CNN:')channels = cfg.base_channelsprint(' ', str(net.get_shape()))net = convolutional(net, filters_shape=(3, 3, 3, channels), trainable=trainable, name='ex_conv0',downsample=True, activate=True, bn=False)net = convolutional(net, filters_shape=(3, 3, channels, 2*channels), trainable=trainable, name='ex_conv1',downsample=True, activate=True, bn=False)net = convolutional(net, filters_shape=(3, 3, 2*channels, 2*channels), trainable=trainable, name='ex_conv2',downsample=True, activate=True, bn=False)net = convolutional(net, filters_shape=(3, 3, 2*channels, 2*channels), trainable=trainable, name='ex_conv3',downsample=True, activate=True, bn=False)net = convolutional(net, filters_shape=(3, 3, 2*channels, 2*channels), trainable=trainable, name='ex_conv4',downsample=True, activate=True, bn=False)net = tf.reshape(net, [-1, 4096])features = ly.fully_connected(net,cfg.fc1_size,scope='fc1',activation_fn=lrelu,weights_initializer=tf.contrib.layers.xavier_initializer())filter_features = ly.fully_connected(features,output_dim,scope='fc2',activation_fn=None,weights_initializer=tf.contrib.layers.xavier_initializer())return filter_features5、训练流程
作者在构建数据集的时候需要区分是雾天数据还是低照度数据,训练的每一个batch数据,其中的每一张图片有的几率随机加上随机雾或者随机亮度变化,这样可以使得模型对于雾天或者低照度环境有更大的适应性。由于在训练过程中随机生成雾天图像会让整个训练时长成倍增加,因此,作者在线下完成雾天图像的生成。

其中雾天生成数据的主要代码如下所示:存疑的点是td = math.exp(-beta * d)这个公式,按照公式和自身理解,感觉应该是td = math.exp(-beta )d
def AddHaz_loop(img_f, center, size, beta, A):(row, col, chs) = img_f.shapefor j in range(row):for l in range(col):d = -0.04 * math.sqrt((j - center[0]) ** 2 + (l - center[1]) ** 2) + sizetd = math.exp(-beta * d)img_f[j][l][:] = img_f[j][l][:] * td + A * (1 - td)return img_f6、实验结果
雾天检测效果:

低照度检测结果:

消融试验针对不同的filter进行的对比,可以看到具体结果如下:
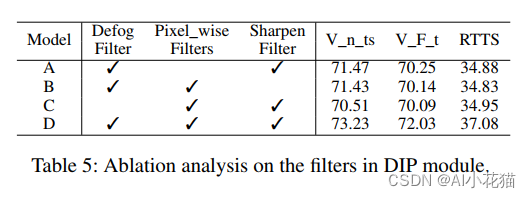
总体来说,IA-YOLO使用可微分的filter,使得图像在进入目标检测器之前进行增强操作,有效提高了最终的目标检出性能。
——END——





。Javaee项目。ssm项目。)
使用)




)







