mysql安装
到官网www.mysql.com下载源码版本
实验室使用5.7.40版本

tar xf mysql-boost-5.7.40.tar.gz
#解压
cd mysql-boost-5.7.40/
yum install -y cmake gcc-c++ bison
#安装依赖性
cmake -DCMAKE_INSTALL_PREFIX=/usr/local/mysql -DMYSQL_DATADIR=/data/mysql -DMYSQL_UNIX_ADDR=/data/mysql/mysql.sock -DWITH_INNOBASE_STORAGE_ENGINE=1 -DWITH_EXTRA_CHARSETS=all -DDEFAULT_CHARSET=utf8mb4 -DDEFAULT_COLLATION=utf8mb4_unicode_ci -DWITH_BOOST=/root/mysql-5.7.40/boost/boost_1_59_0
#配置

make
#编译
make install
#安装
cd /usr/local/mysql/
cd support-files/
cp mysql.server /etc/init.d/mysqld
#拷贝启动脚本

vim /etc/my.cnf


初始化数据库
mkdir /data/mysql -p
创建数据目录
useradd -M -d /data/mysql/ -s /sbin/nologin mysql
#-M不创建用户主目录,-d指定主目录为/data/mysql/,非交互式shell,用户无法直接登陆系统,只能用于运行数据库服务
chown mysql.mysql /data/mysql/
#将目录/data/mysql/所有人设为mysql,所属组也设为mysql
vim ~/.bash_profile
#编辑用户环境变量

source ~/.bash_profile
#重新加载配置

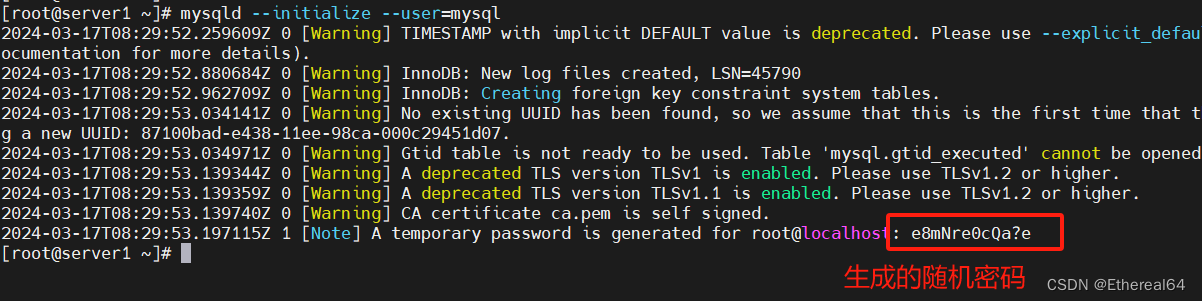
mysqld --initialize --user=mysql
#初始化mysql,--initialize表示初始化数据库,--user=mysql指定以mysql用户身份运行
/etc/init.d/mysqld start
#启动mysql
netstat -antlp |grep 3306
#默认端口为3306

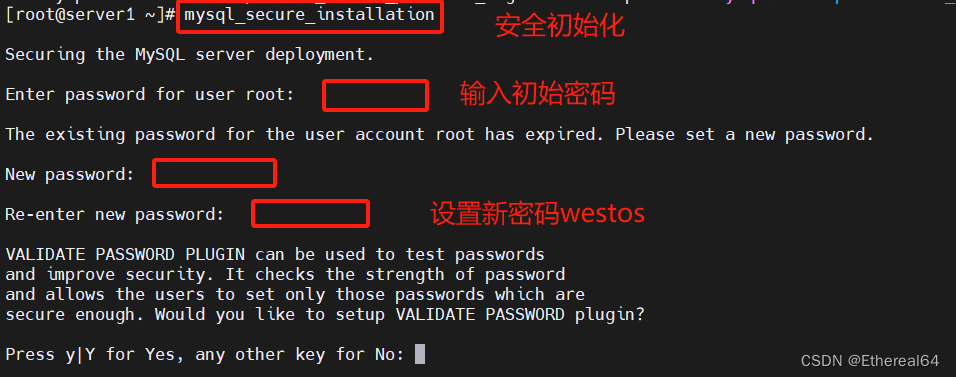
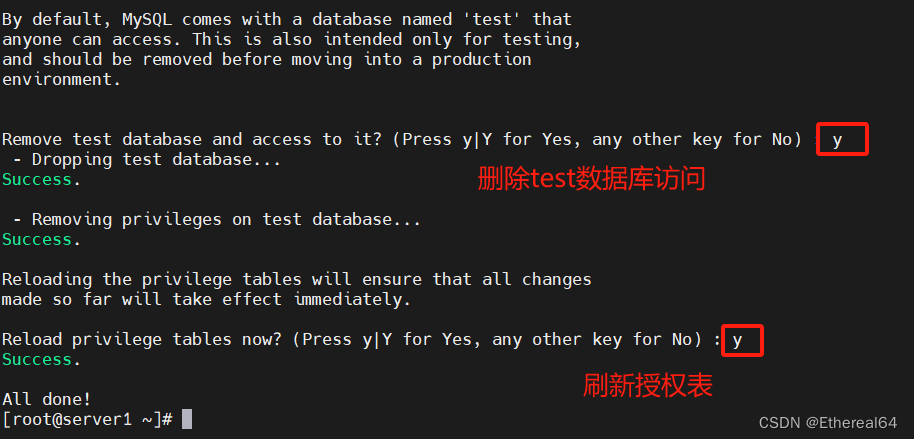
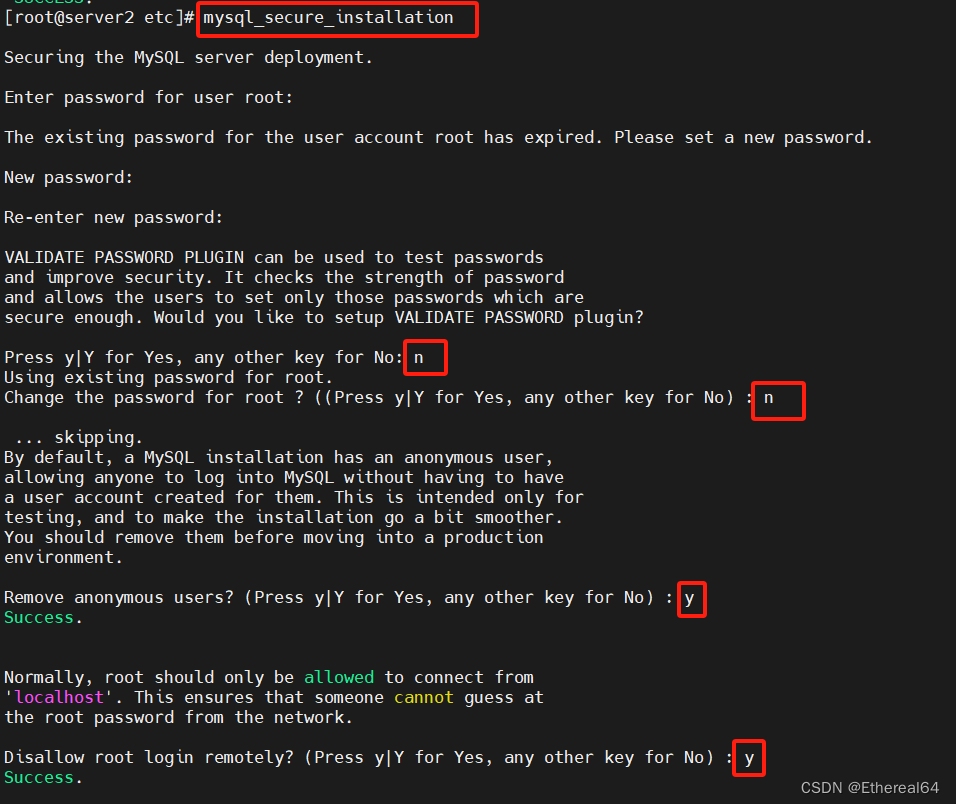
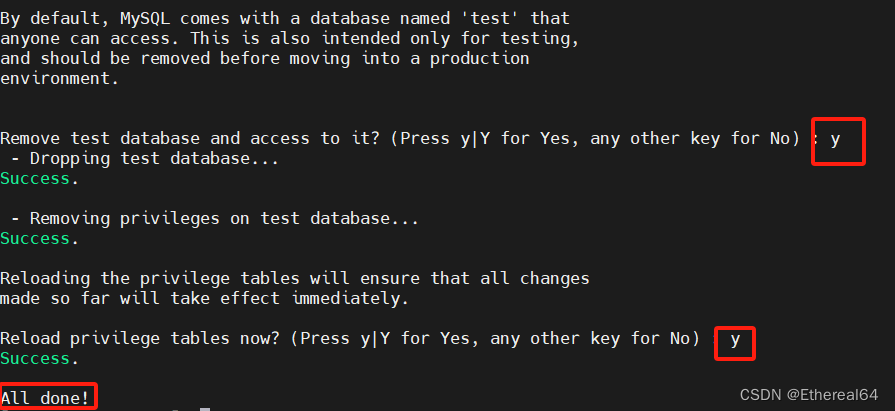
安全初始化
mysql_secure_installation
#安全初始化脚本

登录数据库
mysql -p
#登录mysql数据库

主从复制
MySQL 主从复制是一种常见的数据库复制技术,用于将一个 MySQL 主服务器上的数据实时复制到一个或多个 MySQL 从服务器上。主从复制通常用于提高系统的可用性、数据备份、负载均衡和故障恢复。
以下配置方法都可在mysql官网www.mysql.com查看
1.master配置
vim /etc/my.cnf

/etc/init.d/mysqld restart
#重启服务

在生产环境中一般不会随意重启服务,热生效的方法比较常见
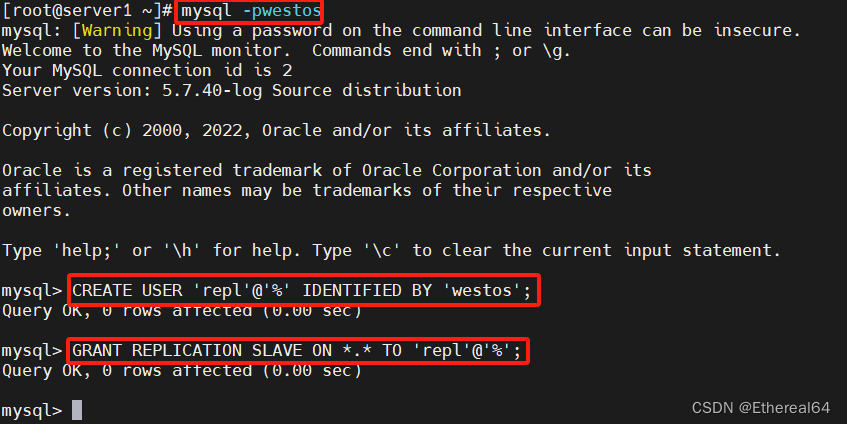
CREATE USER 'repl'@'%' IDENTIFIED BY 'westos';
#创建一个名为 'repl' 的用户,该用户可以从任何主机('%'通配符表示所有主机)连接到数据库,并使用 "westos" 作为密码进行身份验证
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
#授予 'repl' 用户在所有数据库上进行复制操作的权限
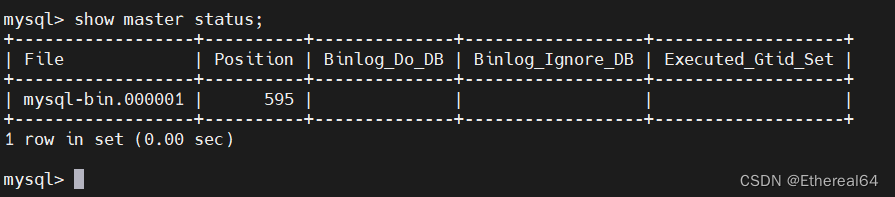
show master status;
#查看master状态

mysqlbinlog mysql-bin.000001
#查看二进制日志

mysqlbinlog mysql-bin.000001 -vv
#查看详细信息

2.slave配置
server2:
从server1中将编译好的mysql目录拷贝到server2
scp -r /usr/local/mysql/ server2:/usr/local/


只需重新初始化即可

source .bash_profile
#重新读取配置

scp server1:/etc/my.cnf /etc/


cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
#拷贝启动脚本
创建用户和数据目录,修改数据目录所有人所有组

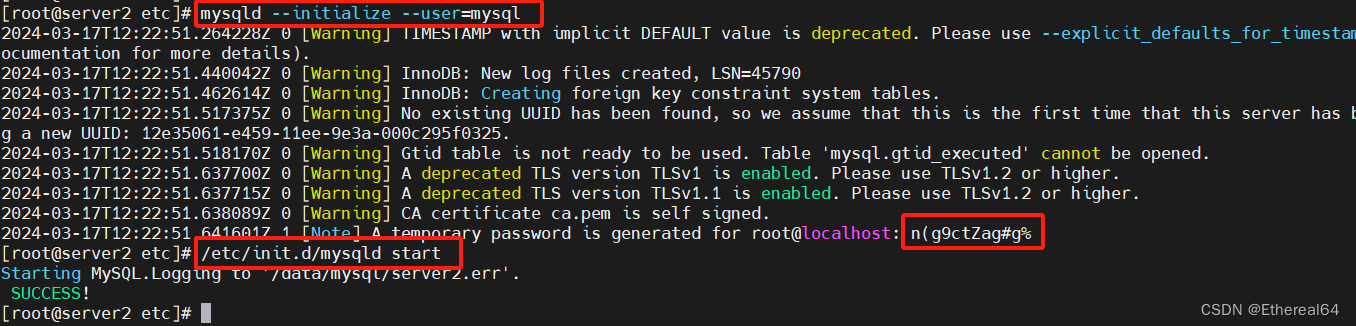
mysqld --initialize --user=mysql
#初始化mysql,生成初始密码
/etc/init.d/mysqld start
#启动服务
mysql_secure_installation
#运行安全初始化脚本

mysql> CHANGE MASTER TO MASTER_HOST='192.168.145.11', MASTER_USER='repl', MASTER_PASSWORD='westos', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=595;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
#从服务器要连接到名为 '192.168.145.11' 的主服务器,并使用用户名为 'repl'、密码为 'westos' 进行身份验证
MASTER_LOG_FILE='mysql-bin.000001'指定主服务器上二进制文件的文件名
MASTER_LOG_POS=595 指定了从服务器开始读取主服务器二进制日志的位置,595是目前最新位置
start slave;
show slave status\G;
#加\G可以使输出以更易读的方式呈现,每个状态变量单独显示在一行上


3.测试数据同步
server1(master):
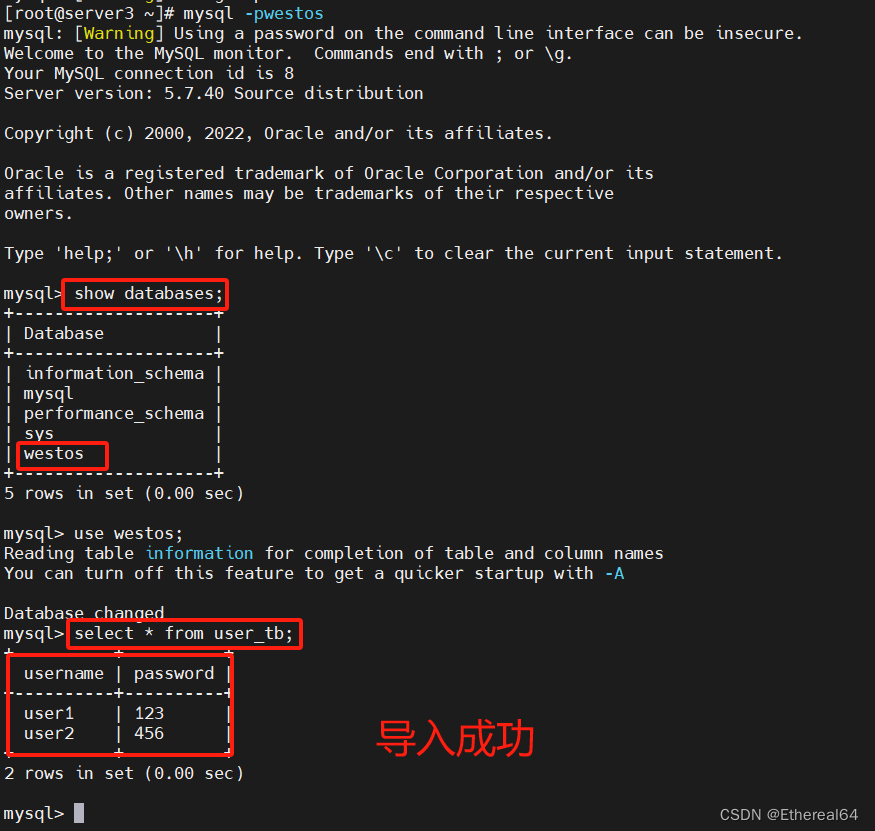
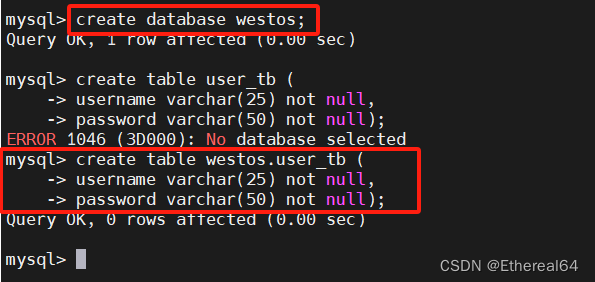
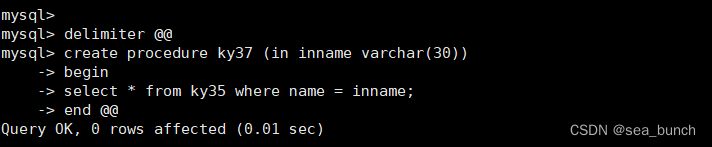
mysql> create database westos;
#创建westos库

server2(slave):
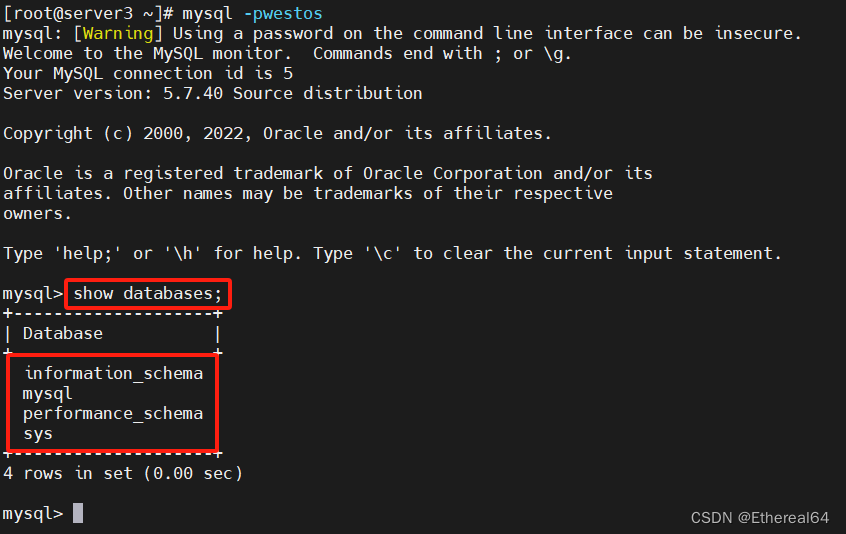
mysql> show databases;
#查看数据库

server1(master):

进入westos库,创建表user_tb
username varchar(25) not null,
#定义了一个名为username的字段,类型为varchar(可变长度字符串),最大长度为25个字符,并且指定该字段不允许为空(not null)
password varchar(50) not null
#定义了一个名为password的字段,类型为varchar,最大长度 50 个字符,并且该字段不允许为空
mysql>desc user_tb;

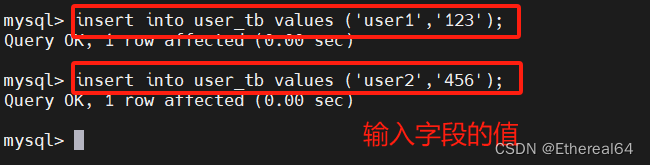
insert into user_tb values ('user1','123');
insert into user_tb values ('user2','456');
server2(slave):
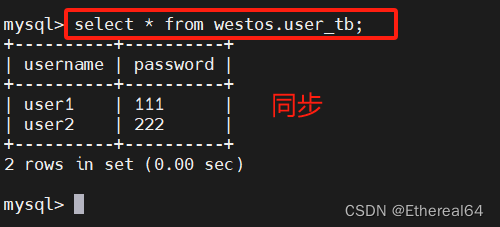
select * from user_tb;
#查询表user_tb中所有数据

复制成功
4.再添加一个slave server3
安全初始化及之前的操作和server2相同,设置server-id=3即可
server3:
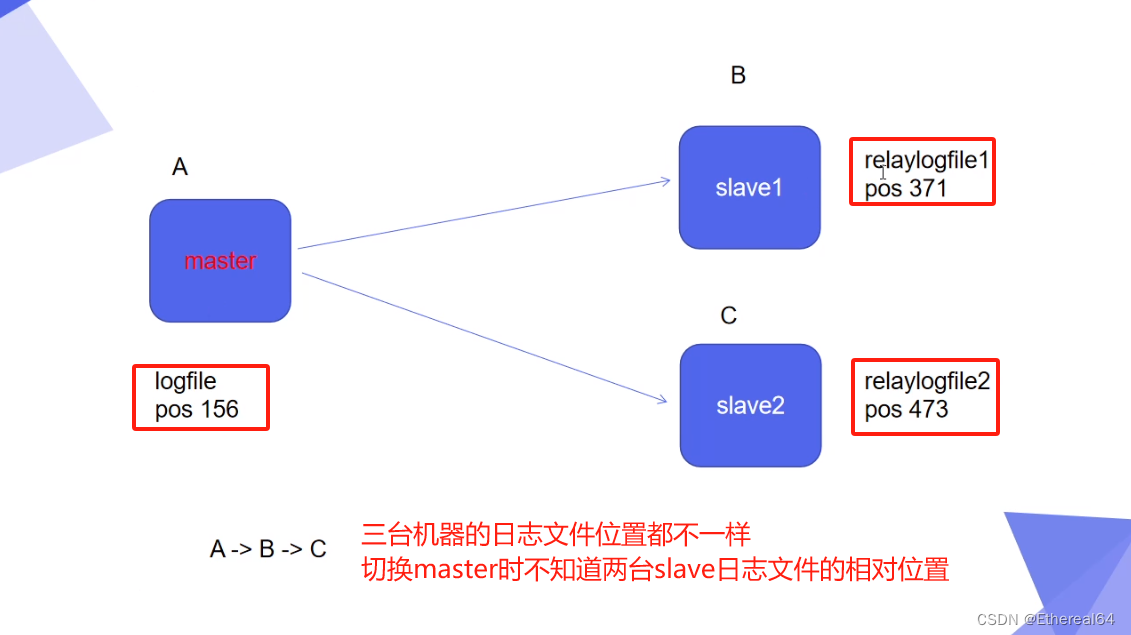
此时master上已经有了数据,在不知道初始二进制日志位置的情况下如何同步

server1:
mysqldump -pwestos westos > dump.sql
#备份westos库,导出到名为dump.sql的sql文件中

scp dump.sql server3:
#将dump.sql拷贝到server3

注意:
生产环境中备份时需要锁表,保证备份前后的数据一致
mysql> FLUSH TABLES WITH READ LOCK;
备份后再解锁
mysql> UNLOCK TABLES;
注意:
mysqldump命令备份的数据文件,在还原时会先DROP TABLE,合并数据时要删除此语句

server3:
mysqladmin -pwestos create westos
#无需登录数据库直接创建westos库,为非交互式方式
mysql -pwestos westos < dump.sql
#导入,仍是非交互式

合并:
mysql> CHANGE MASTER TO MASTER_HOST='192.168.145.11', MASTER_USER='repl', MASTER_PASSWORD='westos', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=1533;
#设置主服务器,MASTER_LOG_POS=1533设为当前的号1533
mysql> start slave;
mysql> show slave status\G;

测试主从同步:
server1(master):
mysql> insert into westos.user_tb values ('user3','666');
#在表中再输入一组值

server2(slave):

server3(slave):

主从复制是单向的,只能在master操作,一旦在slave操作,就会导致主从复制不一致
IO线程负责与主服务器建立连接,读取主服务器的二进制日志(binary log)内容,并将这些日志写入到从服务器的中继日志(relay log)中
SQL线程负责读取中继日志中的二进制日志文件(binary log events),即在从服务器上执行这些事件,从而将主服务上的操作在从服务器上进行重放/回放
读操作远远高于写操作时,使用一主多从架构,数据库外层要接入负载均衡层。能够做同样操作,主和从的主机硬件也基本相同
binlogdump复制二进制日志时属于异步复制

异步复制的优点在于主服务器不需要等待所有从服务器都处理了相同的更改之后才能继续执行事务,这样可以减少对主服务器性能的影响。但是,由于异步复制的特性,从服务器上的数据可能无法立即与主服务器保持完全同步,因此在某些情况下可能会发生数据延迟,若此时主服务器挂掉,那么将会有数据丢失。
尽管异步复制提供了较好的性能和可伸缩性,但在某些应用场景下,对数据一致性要求较高的系统,如金融级的数据库,要求零数据丢失,可能会选择使用同步复制或半同步复制来确保数据的及时性和一致性
半同步模式

"after_commit" 意味着在数据库事务成功提交后触发的事件。这表示当事务成功提交到数据库后,相关的操作或触发器将会被执行,通常情况下,这是在主服务器上的操作,表示事务已经成功应用到主数据库上,关注于主服务器上事务提交后的操作,确保主服务器上的数据变更被成功提交。但从服务器的数据不一定已经复制完成。

"after_sync" 则涉及到数据库复制的过程。它表示在从服务器上的数据已经与主服务器同步完成后触发的事件,这意味着从服务器已经成功接收、应用并同步了来自主服务器的所有更改,从而保证了从服务器上的数据与主服务器保持一致,关注于从服务器上数据与主服务器数据的同步,确保从服务器上的数据与主服务器保持一致。

5.延迟复制
核心思想:一个事务在主库执行后,会等待若干秒才在从库上执行
常见使用场景:
①应对主库的误操作,尤其是DROP TABLE操作
②查看数据库的历史状态
③人为模拟主从延迟
开启延迟复制:
mysql> stop slave;
#停止从服务器
mysql> change master to master_delay = 60;
#将主服务器上的复制延迟设置为60秒
mysql> start slave;
#重启从服务器
此时在主库新增记录,查询从库不会出现变化,60秒后才会同步




延迟复制在本质上是暂停SQL线程的应用,并不影响IO线程接受主库的binlog
gtid模式
server1(master):
vim /etc/my.cnf
#编辑mysql配置文件

gtid_mode=ON
#启用gtid模式,每个事务都会被分配一个全局唯一的gtid,用于标识事务在复制拓扑结构中的位置
#启用GTID模式可以简化主从复制配置,减少因为二进制日志文件名和位置的变化而带来的复杂性,同时提高了复制的可靠性和容错性
启用gtid模式之前:
gtid模式:

enforce-gtid-consistency=ON
#强制执行GTID一致性
#MySQL服务器将会检查所有进入的事务,确保它们的GTID在整个复制拓扑结构中是唯一且连续的,强制执行GTID一致性可以防止数据不一致的情况发生,确保各个服务器之间的数据同步是正确的
/etc/init.d/mysqld restart
#重启服务

server2,server3(slave):
vim /etc/my.cnf
#编辑mysql配置文件

/etc/init.d/mysqld restart
#重启服务
mysql -pwestos
#登录数据库
mysql> stop slave;
#停止slave

mysql> CHANGE MASTER TO MASTER_HOST='192.168.145.11', MASTER_USER='repl', MASTER_PASSWORD='westos', MASTER_AUTO_POSITION = 1;
#重新配置
#MASTER_AUTO_POSITION = 1 启用基于GTID的复制,并且自动获取主服务器的最新GTID位置
mysql> start slave;
#启动slave
mysql> show slave status\G;
#查看slave状态

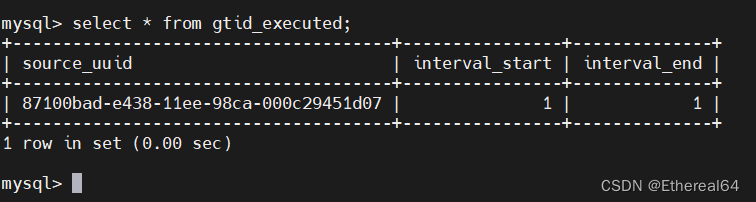
在master端表中插入一条信息
insert into westos.user_tb values ('user4','666');

server2(slave):
mysql> select * from mysql.gtid_executed;
#查看mysql中已经执行的gtid
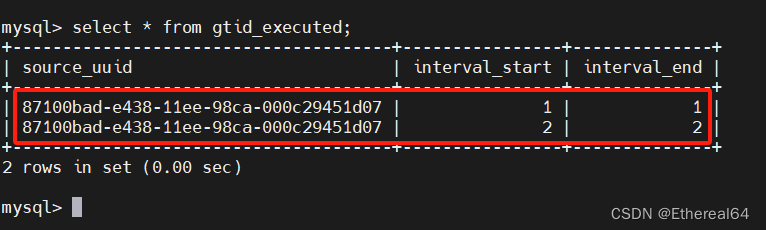
insert into westos.user_tb values ('user5','666');
#再插入一条

mysql> select * from mysql.gtid_executed;
#查询
半同步模式

在切换到半同步模式之前,必须先切换到gtid模式

server1(master):
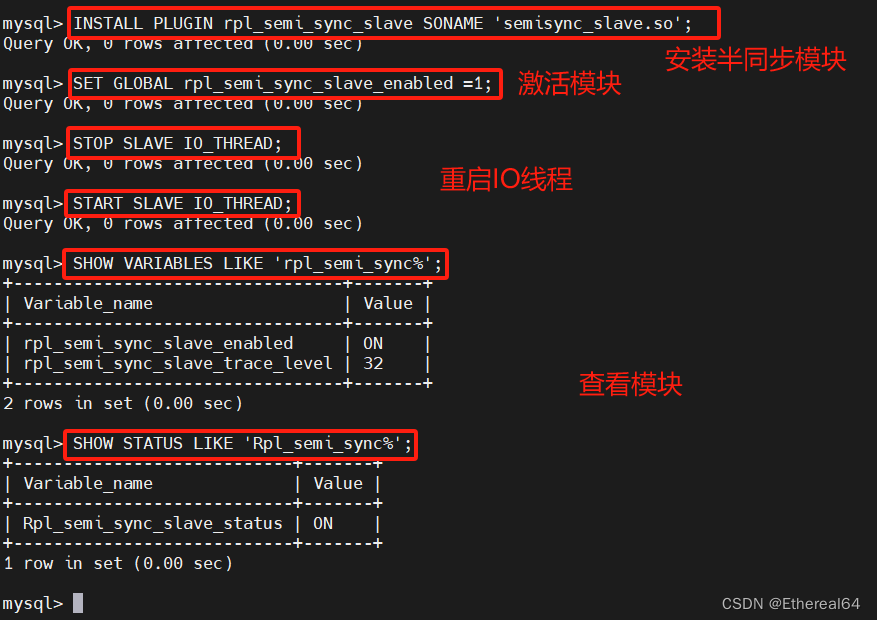
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
#安装半同步模块

mysql> SELECT PLUGIN_NAME, PLUGIN_STATUS
-> FROM INFORMATION_SCHEMA.PLUGINS
-> WHERE PLUGIN_NAME LIKE '%semi%';
#查看与半同步复制相关的插件在MySQL中的安装状态

mysql> SET GLOBAL rpl_semi_sync_master_enabled = 1;
#激活半同步模式
SHOW VARIABLES LIKE 'rpl_semi_sync%';
#查看半同步参数,显示所有以 rpl_semi_sync 开头的MySQL系统变量及其对应的取值
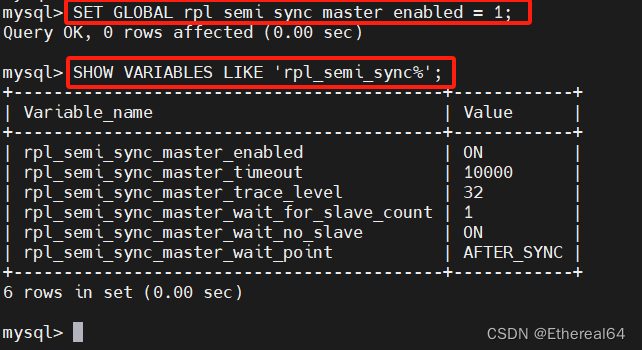
#rpl_semi_sync_master_wait_for_slave_count=1 表示主服务器在提交事务前等待至少一台从服务器确认,根据实际需求,可以调整这个值来优化半同步复制的性能和可靠性
#rpl_semi_sync_master_timeout=10000 主服务器等待从服务器确认的超时时间为10000ms,即10s
SHOW STATUS LIKE 'Rpl_semi_sync%';
#查看半同步状态

vim /etc/my.cnf
#编辑mysql配置文件
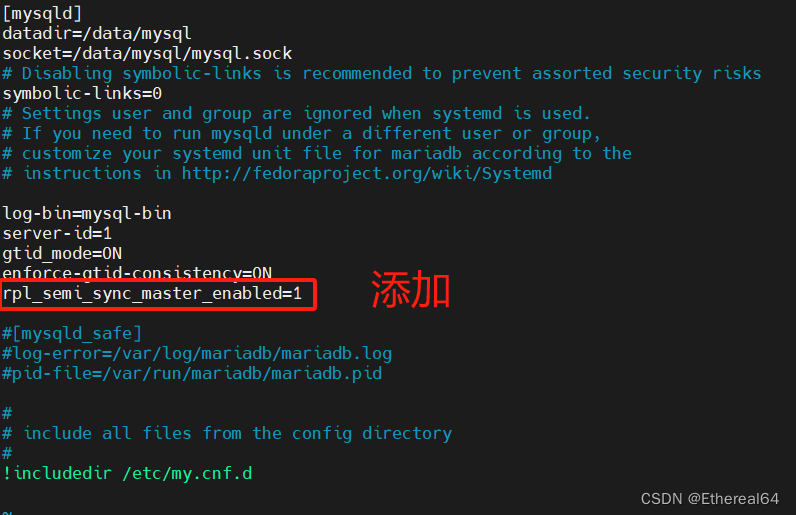
#rpl_semi_sync_master_enabled=1 表示已启用主服务器上的半同步复制功能
#这意味着主服务器将等待至少一个从服务器确认接收到事务日志后才会认为事务提交成功
server2,server3(slave):
vim /etc/my.cnf
#将半同步参数写入配置文件

mysql> SHOW STATUS LIKE 'Rpl_semi_sync%';
#在server1再次查看半同步状态,未配置slave时都为0,现在可以看到有两个从服务器已连接
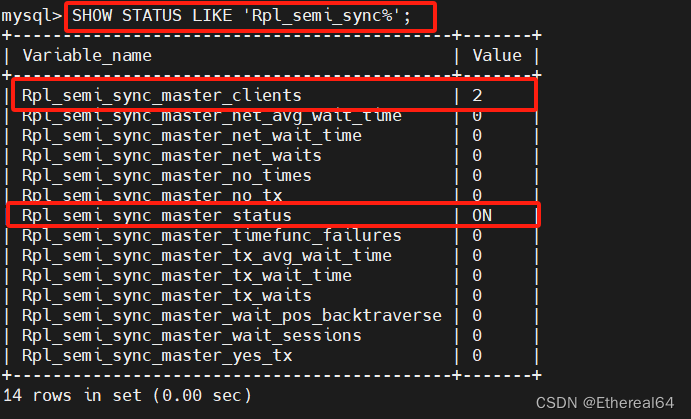
测试:
server1(master):
mysql> insert into westos.user_tb values ('user6','666');
#再插入一组数据
mysql> SHOW STATUS LIKE 'Rpl_semi_sync%';
#查看状态

停止所有slave节点的IO线程
mysql> STOP SLAVE IO_THREAD;

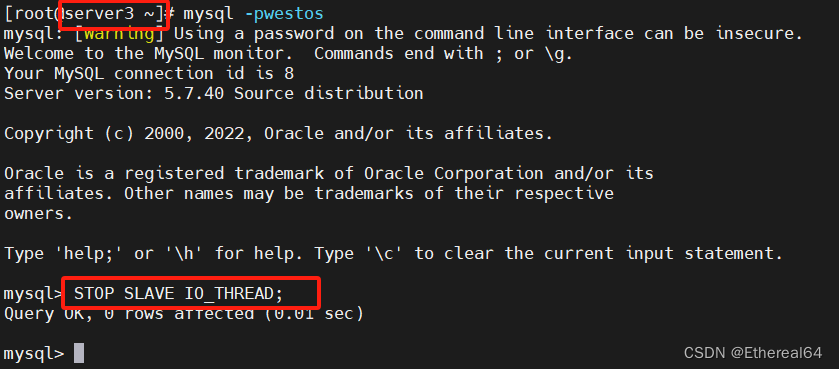
master节点再次写入数据
mysql> insert into westos.user_tb values ('user7','666');


默认等待时间超过10s,自动切换为异步模式
mysql> SHOW STATUS LIKE 'Rpl_semi_sync%';
#查看状态

在生产环境中,要想实现数据无损,要把超时时间设置为无穷大
金融级数据库的要求更高,不接受数据不一致,例如:查询存款时若没接收到从服务器的响应,master将不会显示结果。如果显示必须显示准确结果
并行复制
默认slave节点sql线程是单线程回放,会造成数据同步延时较高
使用并行复制:
server2,server3(slave):

#slave-parallel-type=LOGICAL_CLOCK 这个配置指定了从库并行复制的方式,使用逻辑时钟来进行并行复制。逻辑时钟是一种用于并行系统中事件排序的方法,可以用于协调并行复制操作,以提高性能和效率
#slave-parallel-workers=16 指定了从库并行复制时使用的并行工作者线程数为16,这意味着在并行复制过程中可以同时处理多个事务,提高了复制性能
#master_info_repository=TABLE 这个配置指定了主服务器的信息存储方式,设置为 TABLE 表示主服务器的信息将存储在一个表中。这种方式相对于文件存储有一定的优势,比如更好的可维护性和可查询性
#relay_log_info_repository=TABLE 类似于上面的配置,这个参数指定了中继日志信息的存储方式,设置为 TABLE 表示中继日志的信息将存储在一个表中
#relay_log_recovery=ON 这个配置指示在数据库重启时自动进行中继日志的恢复操作,以确保数据的完整性和一致性
/etc/init.d/mysqld restart
#重启服务
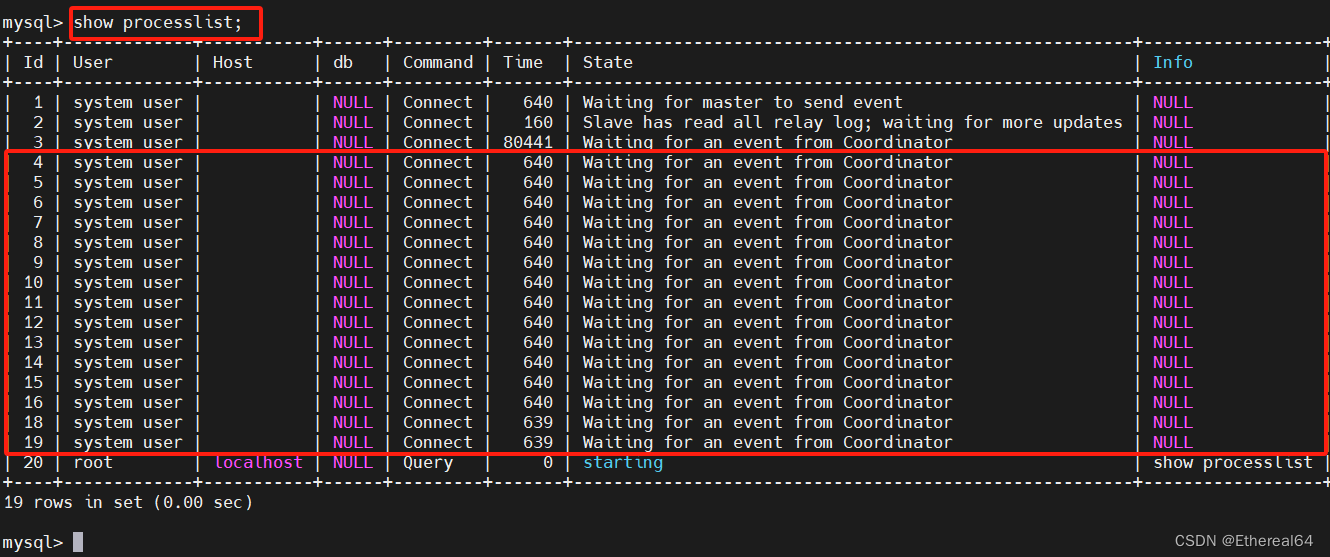
mysql -p
mysql> show processlist;
#查看活动的线程
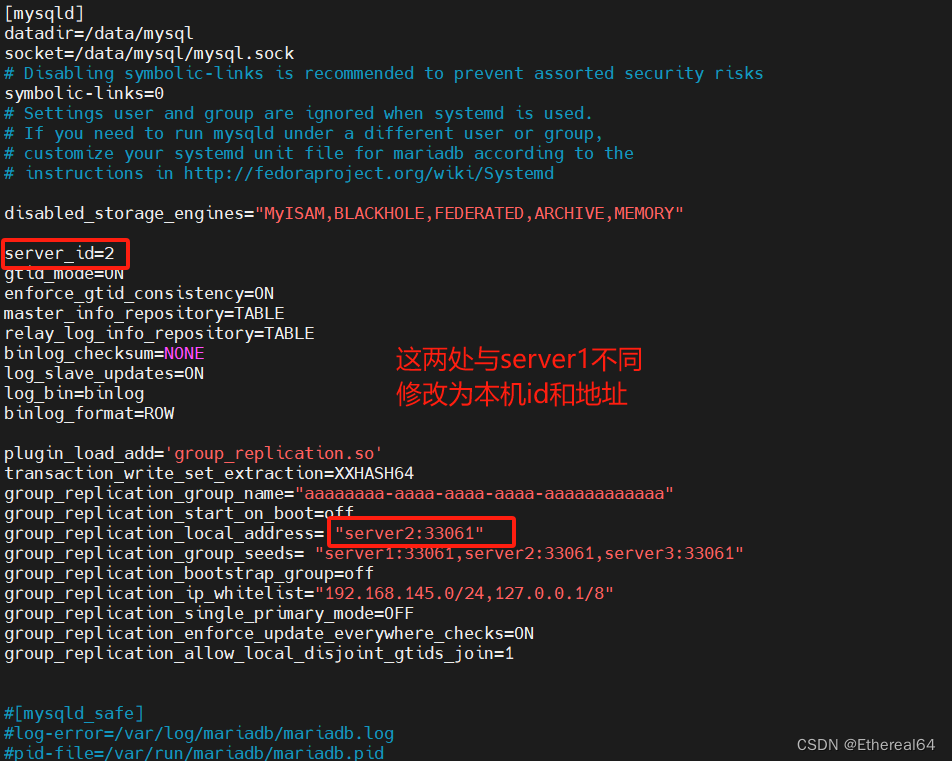
mysql组复制
大部分互联网公司使用的是分布式数据库



配置多主模式,所有节点都是Primary节点
确保所有节点数据一致:
1.server1配置
/etc/init.d/mysqld stop
#关闭数据库
cd /data/mysql
rm -rf *
#清除数据
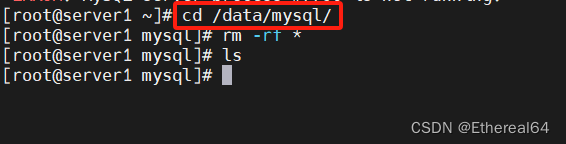
vim /etc/my.cnf
#编辑mysql配置文件

#disabled_storage_engines="MyISAM,BLACKHOLE,FEDERATED,ARCHIVE,MEMORY"



mysqld --initialize --user=mysql
#初始化

/etc/init.d/mysqld start
#启动服务
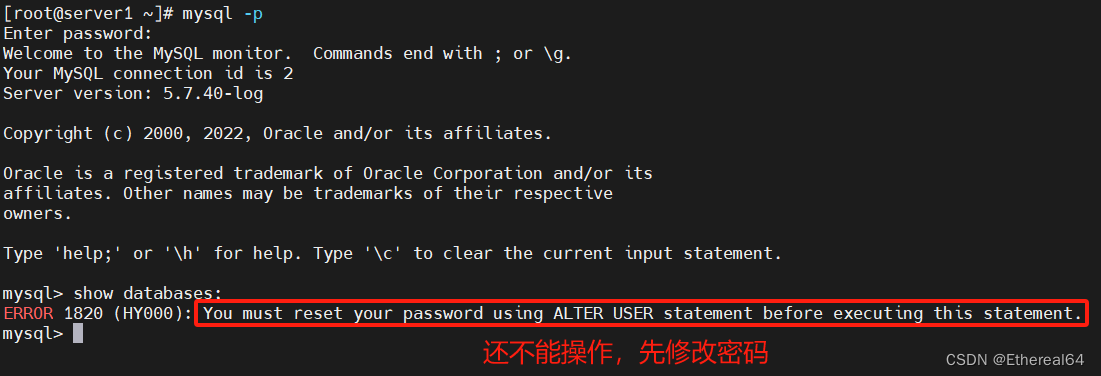
#alter user root@localhost identified by 'westos';
修改root在本机的mysql密码为westos
#SET SQL_LOG_BIN=0;
在当前会话中禁止生成二进制日志
#CREATE USER rpl_user@'%' IDENTIFIED BY 'westos';
创建一个名为 "rpl_user" 的用户,并允许该用户从任何主机 '%' 连接到数据库 指定了用户的密码为 'westos'
#GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';
授予rpl_user用户在任何数据库中作为复制从库的权限
#FLUSH PRIVILEGES;
重新加载授权表
#SET SQL_LOG_BIN=1;
启用生成二进制日志
#CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='westos' FOR CHANNEL 'group_replication_recovery';
指定用于复制的用户rpl_user,密码westos
这些参数适用于名为 "group_replication_recovery" 的复制通道
#SET GLOBAL group_replication_bootstrap_group=ON;
启动组复制引导过程,在引导过程中,这个节点将扮演重要的角色,协调其他节点的加入,并确保组复制的正确启动(只在server1上执行)
#START GROUP_REPLICATION;
启动组复制
#SET GLOBAL group_replication_bootstrap_group=OFF;
关闭组复制引导过程(只在server1上执行)
#SELECT * FROM performance_schema.replication_group_members;
查询 MySQL 中复制组成员信息

2.server2配置
/etc/init.d/mysqld stop
#停止数据库

vim /etc/my.cnf
#编辑配置文件
mysqld --initialize --user=mysql
#初始化
/etc/init.d/mysqld start
#启动

在server1查看成员:

3.server3配置
与server2同理

启动组复制完成后在server1查看成员

测试:
一主多从适用于读的请求远高于写的场景
多主模式所有节点都可以读写数据,适用于对读写需求都很大的场景
在server1(master):

CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 TEXT NOT NULL);
#创建名为 "t1" 的表,列 c1 被定义为 INT 类型,并设置为主键(PRIMARY KEY),列 c2 被定义为 TEXT 类型并设置为非空(NOT NULL)
"PRIMARY KEY" 是用来定义表中的主键的关键字。主键是用来唯一标识表中每一行数据的一列或一组列。具体来说,主键具有以下特性:
- 唯一性:主键列的值必须是唯一的,不允许出现重复的值。
- 非空性:主键列的值不能为 NULL,即不能为空值。
"c1 INT PRIMARY KEY" 就是用来定义列 c1 作为表 t1 的主键。这意味着 c1 列的值将唯一标识表中的每一行,并且不允许出现重复值或者空值。
在实际的数据库设计中,主键经常被用于加速查询、确保数据完整性以及与其他表之间建立关联关系。当你需要在表中唯一标识每一行数据时,就可以考虑使用主键。
server2(slave):

server3(slave):
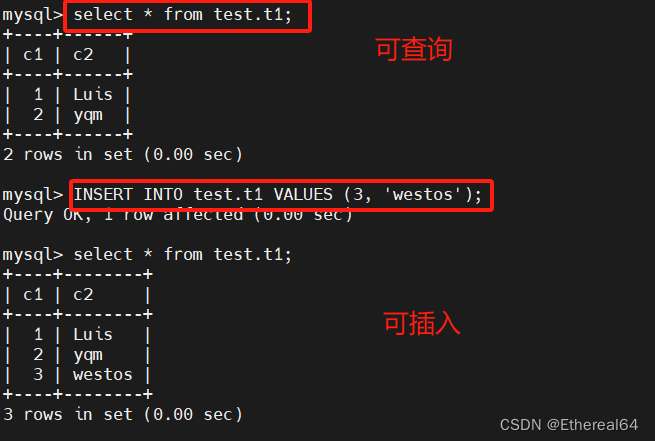
mysql路由器
rpm -ivh mysql-router-community-8.0.21-1.el7.x86_64.rpm
#安装软件
cd /etc/mysqlrouter/
vim mysqlrouter.conf
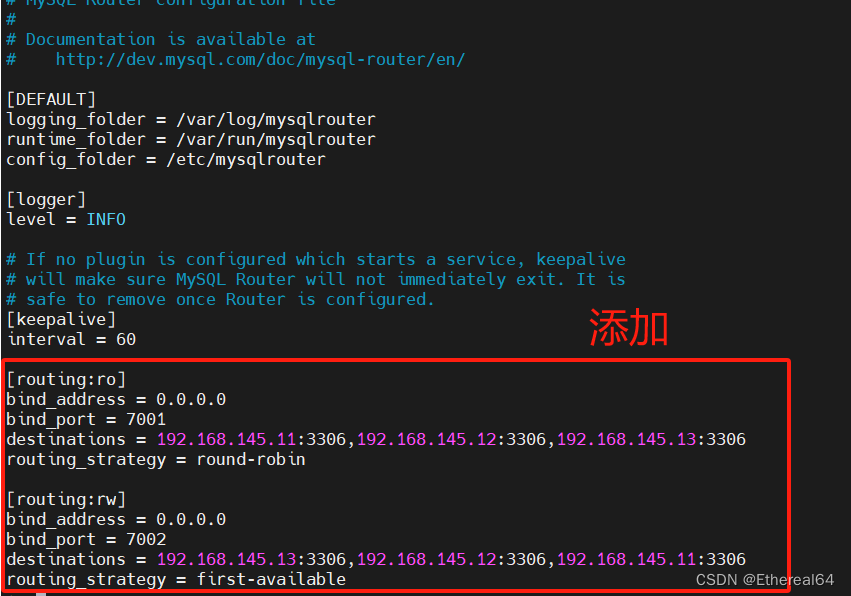
routing_strategy = round-robin
#路由策略轮询 依次将请求分配给多个服务器,实现请求在各个服务器之间的均衡分配
routing_strategy = first-available
#指定首选可用服务器的方式,系统会检查服务器列表中的每台服务器,然后选择第一个被标记为"可用"的服务器,将请求发送到该服务器上。这样可以确保请求尽快得到响应,并且可以有效利用可用服务器资源
systemctl enable --now mysqlrouter.service
#启动服务

yum install -y mariadb
#安装mysql客户端工具
server1:
mysql> grant all on test.* to 'yqm'@'%' identified by 'westos';
#在mysql集群中创建远程测试用户
授予用户yqm在任何主机上('%' 表示所有主机)对test数据库的全部权限,并设置密码为 "westos"
其他集群也已同步
server4:
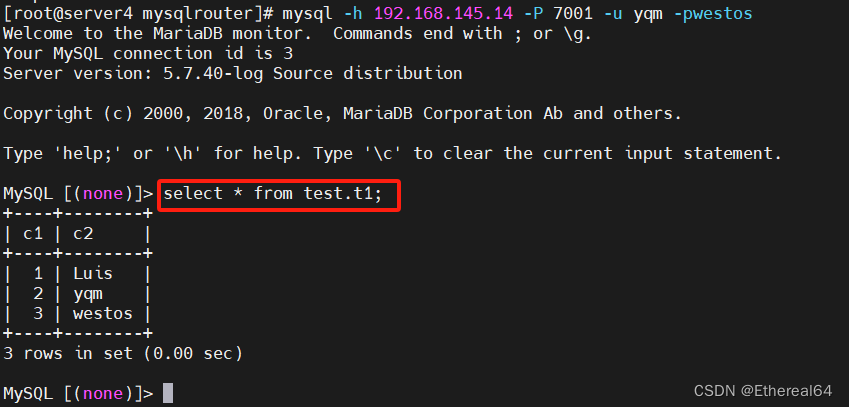
mysql -h 192.168.145.14 -P 7001 -u yqm -pwestos
#连接mysql路由器 -P 指定连接的端口号
server1:
yum install -y lsof
#lsof用于显示系统当前打开的文件(包括网络连接、管道等)的工具

再次连接路由器

在server1查看网络连接:

在server2查看:

第三次连接:

在server3查看:

再次用端口7002连接:

仍然连接的是server3

停用server3:

再次用端口7002连接:
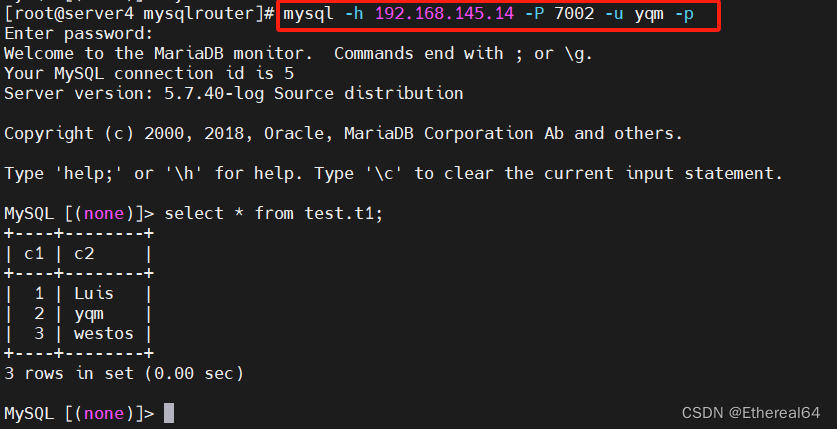
此时连接上了server2

应用时可以直接用mysqlrouter连接数据库集群,实现了负载均衡和高可用
msyql MHA高可用
1.创建一主两从集群
server1(master):
rm -rf /data/mysql/*
#清除数据
vim /etc/my.cnf
#编辑配置文件
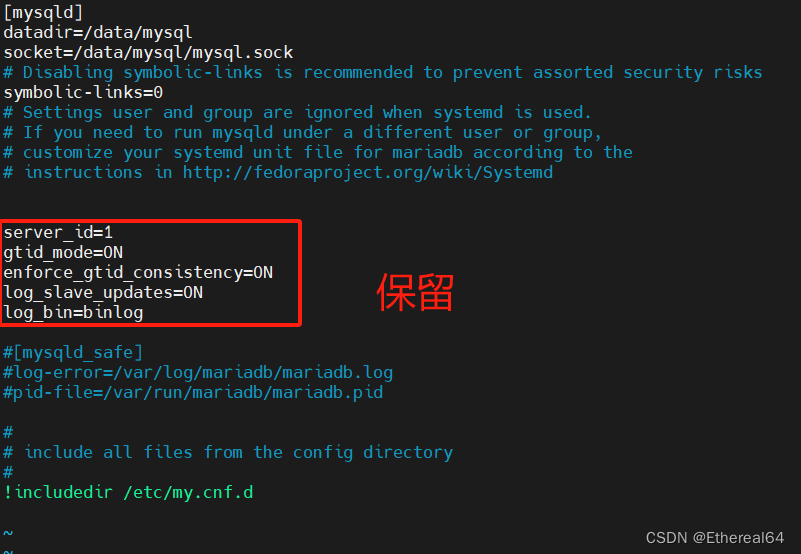
mysqld --initialize --user=mysql
#初始化生成密码
/etc/init.d/mysqld start
#启动服务
mysql -p
#登录

server2(slave):
rm -rf /data/mysql/*
vim /etc/my.cnf

mysqld --initialize --user=mysql
#初始化
/etc/init.d/mysqld start
#启动服务

server3配置同理

测试:
master:

slave:
2.MHA部署

将server4作为管理端(MHA Manager)

yum install -y *.rpm
#安装管理端软件及依赖性
ssh-keygen
#生成ssh密钥对
ssh-copy-id server4
#将公钥放到本地authorized_keys文件中
scp -r .ssh/ server1:
scp -r .ssh/ server2:
scp -r .ssh/ server3:
#直接将.ssh/目录全部复制到server1,server2,server3中,此时可以实现互相免密

复制客户端软件
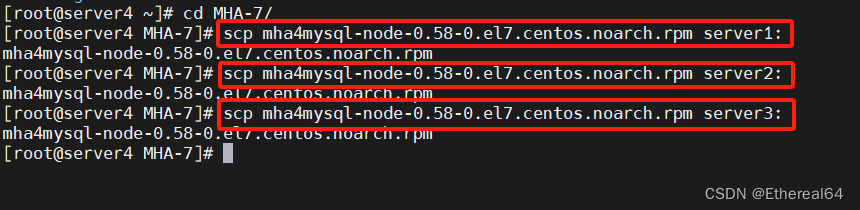
yum install -y mha4mysql-node-0.58-0.el7.centos.noarch.rpm
#server1,server2,server3上安装客户端软件
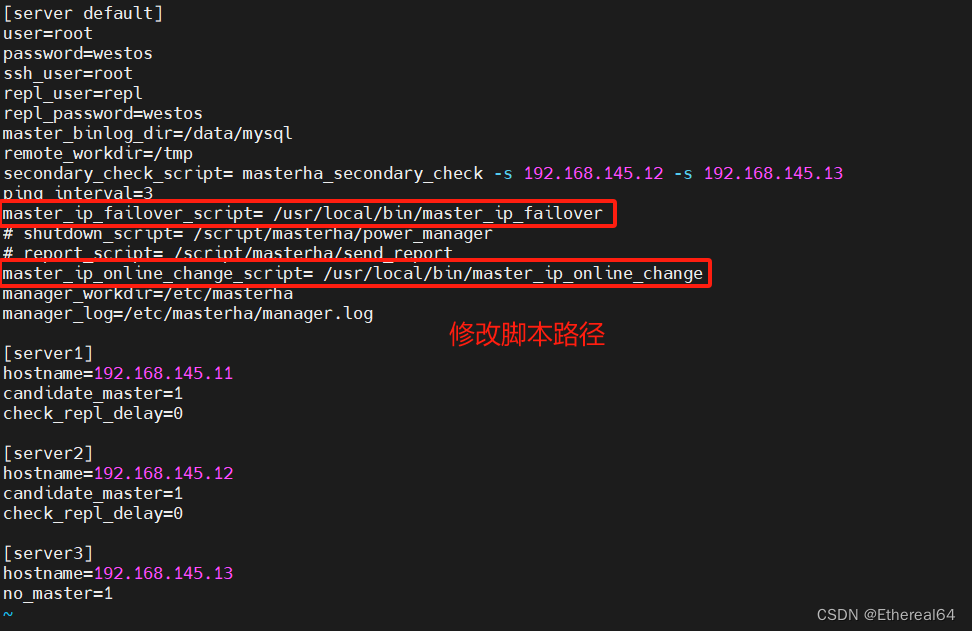
MHA配置
mkdir /etc/masterha
vim /etc/masterha/app1.cnf
cd MHA-7/
tar zxf mha4mysql-manager-0.58.tar.gz
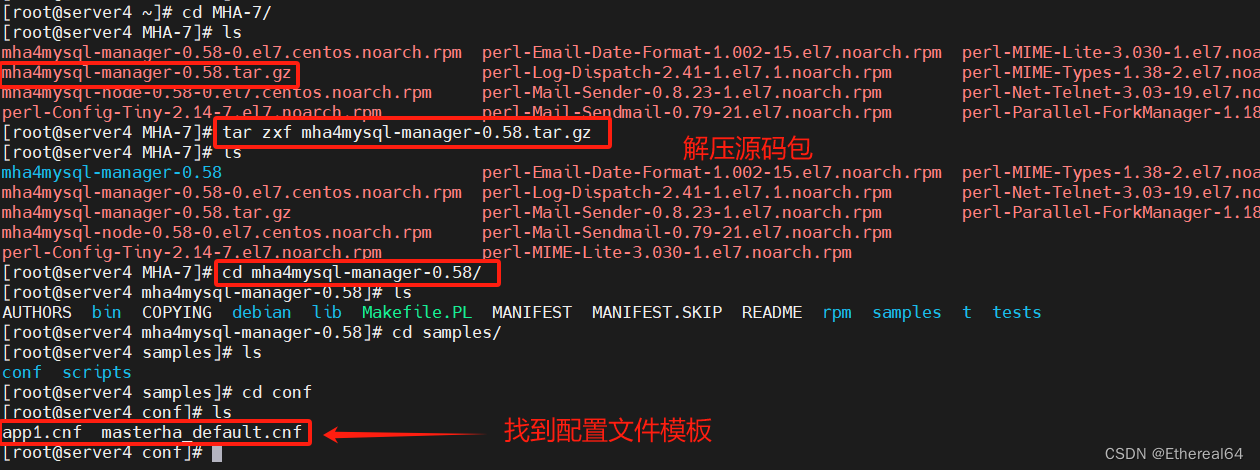
cat masterha_default.cnf app1.cnf > /etc/masterha/app1.cnf
#利用模板生成配置文件
修改:

no_master=1
#server3指定不允许成为主服务器

mysql> grant all on *.* to root@'%' identified by 'westos';
#在master上设置mysql管理员权限,slave节点会自动同步
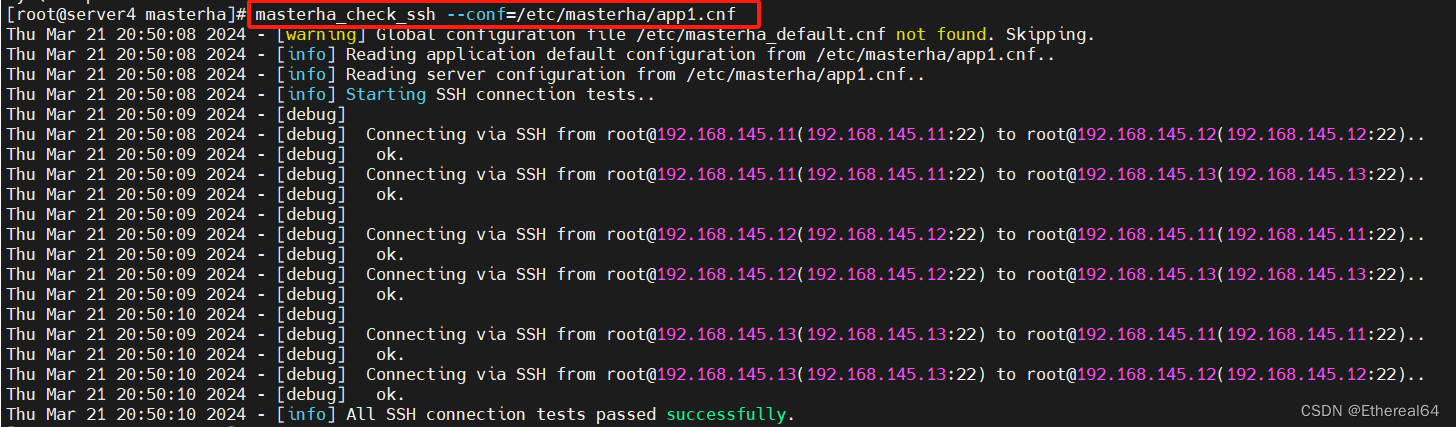
masterha_check_ssh --conf=/etc/masterha/app1.cnf
#检测各节点ssh免密连接
masterha_check_repl --conf=/etc/masterha/app1.cnf
#检测主从复制集群状态
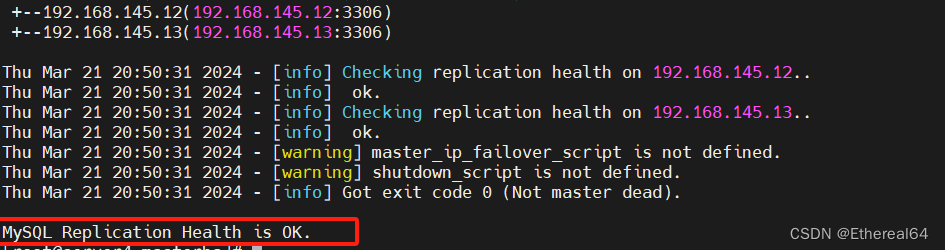
3.故障切换
手动切换(master正常)
masterha_master_switch --conf=/etc/masterha/app1.cnf --master_state=alive --new_master_host=192.168.145.12 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000

masterha_check_repl --conf=/etc/masterha/app1.cnf
#检测主从集群状态

手动切换(master故障)
/etc/init.d/mysqld stop
#手动停止server2节点上的服务
masterha_master_switch --master_state=dead --conf=/etc/masterha/app1.cnf --dead_master_host=192.168.145.12 --dead_master_port=3306 --new_master_host=192.168.145.11 --new_master_port=3306 --ignore_last_failover

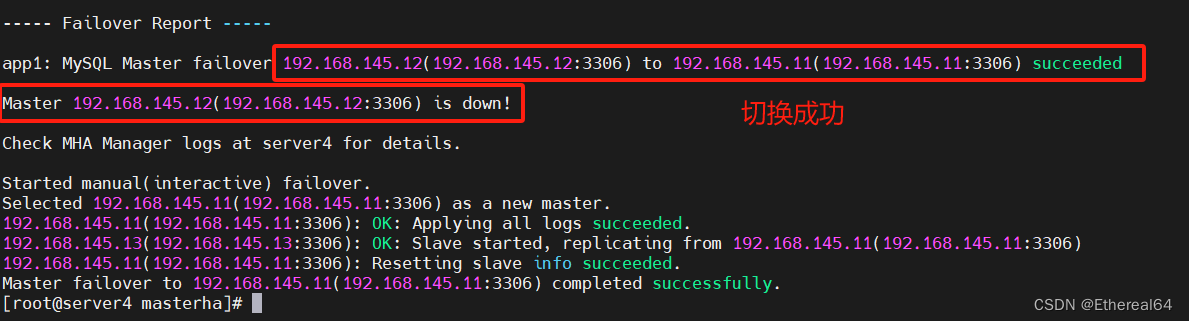
切换成功
手动修复故障节点
server2:
/etc/init.d/mysqld start
#重新启动服务
mysql> change master to master_host='192.168.145.11', master_user='repl', master_password='westos', master_auto_position=1;
#指定master
mysql> start slave;
#启动slave
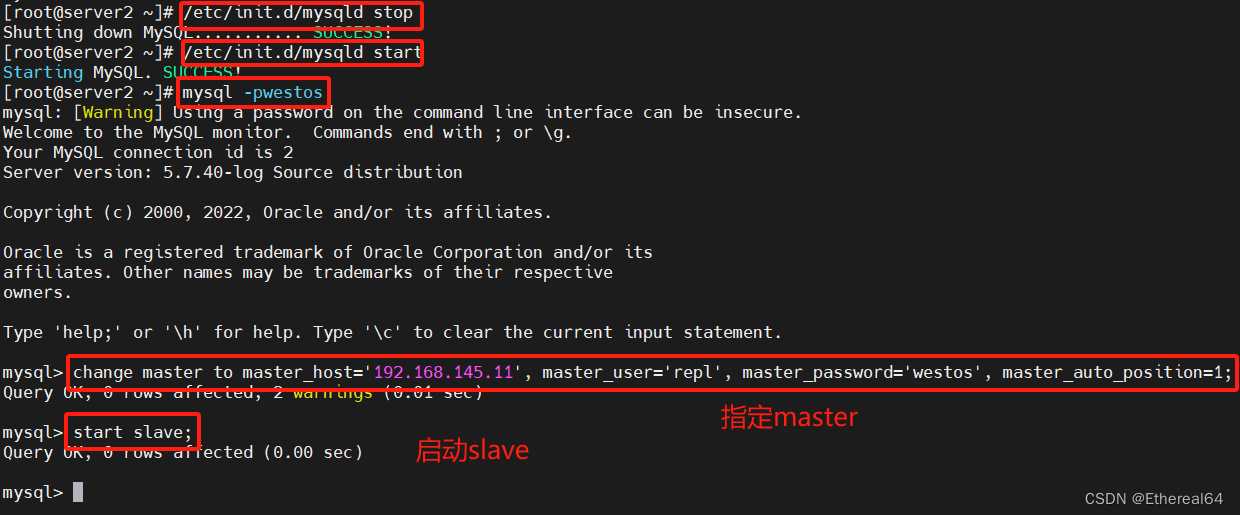
检测状态
server4:

无论是server1还是server2出现故障,切换另一台服务器为master后,手动恢复时都要指定此时的master,将故障节点设置为slave
自动切换
rm -f app1.failover.complete
#故障切换后会生成锁定文件,需要手动删除,否则会影响自动切换
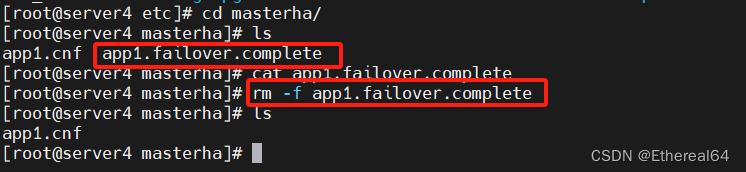
masterha_manager --conf=/etc/masterha/app1.cnf &
#启动manager程序,并打入后台运行,完成切换任务后进程会自动退出
server1:
/etc/init.d/mysqld stop
#关闭master
cat /etc/masterha/manager.log
#查看日志
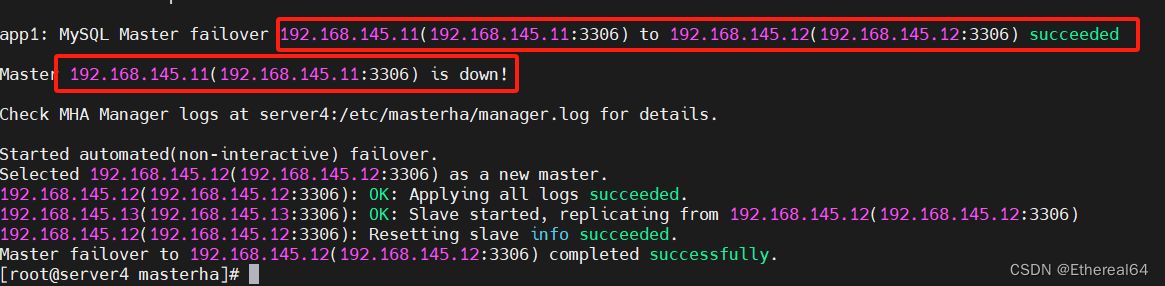
切换成功
手动恢复server1为slave

server4:

masterha_manager --conf=/etc/masterha/app1.cnf &
#再次启动manager进程打入后台

加入故障切换脚本

master_ip_failover
#ip故障切换脚本
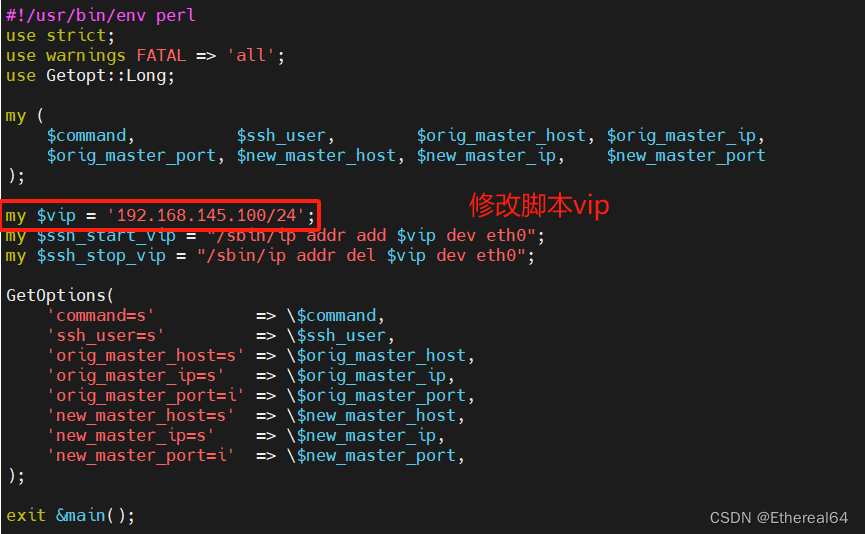
master_ip_online_change
#ip在线切换脚本
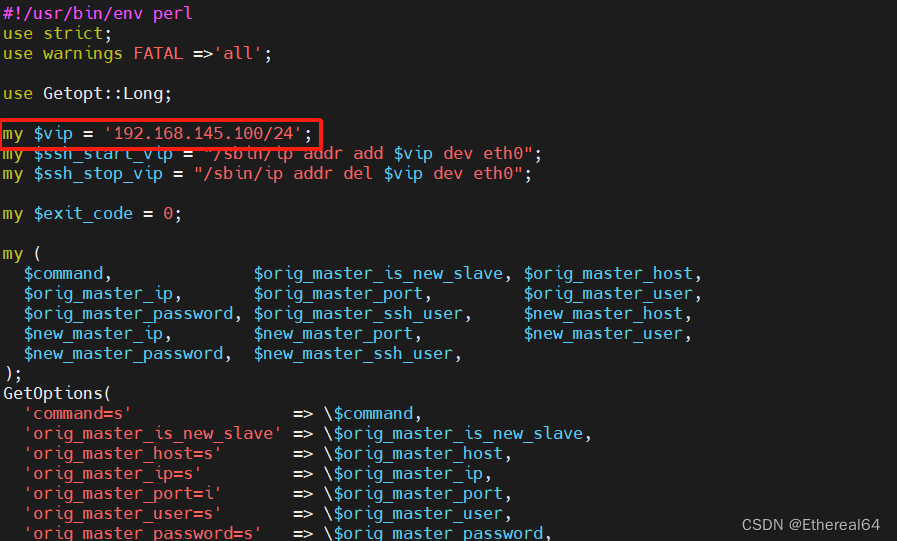
在server2(master)手动添加vip
ip a a 192.168.145.100/24 dev eth0
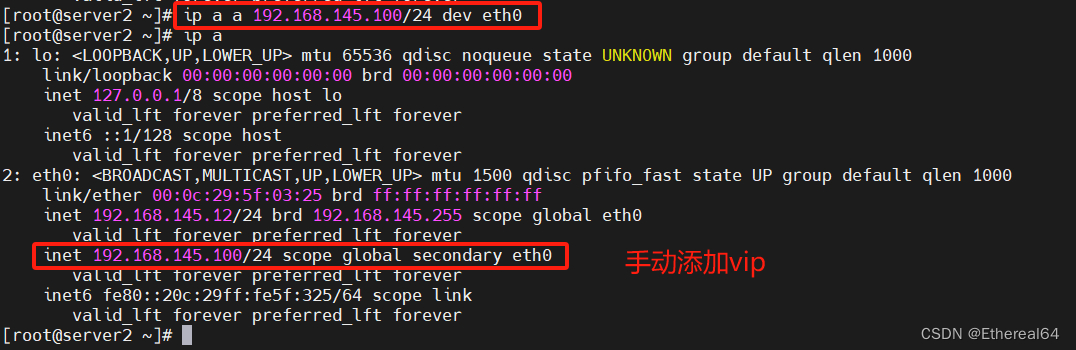
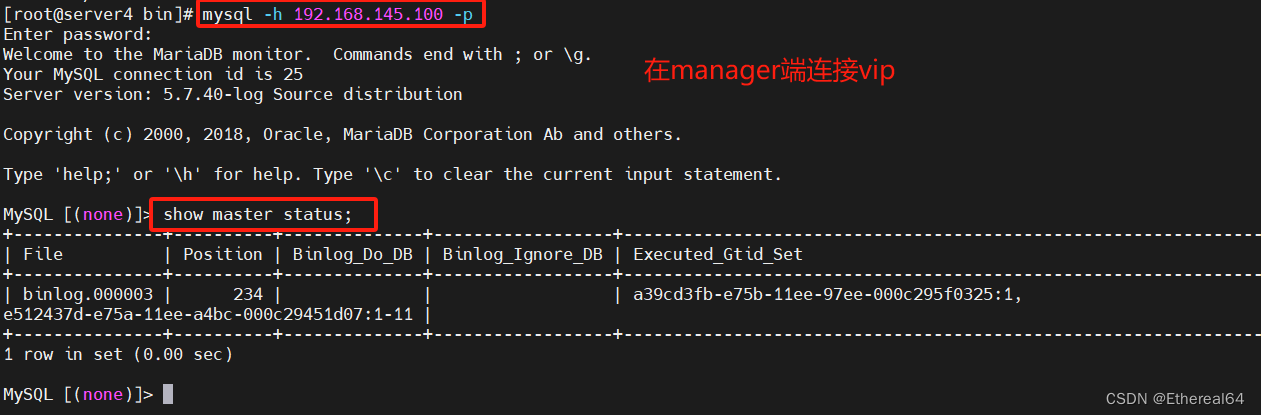
此时连接的是server2
/etc/init.d/mysql stop
#停止server2服务
在manager端查看日志

cat /etc/masterha/manager.log

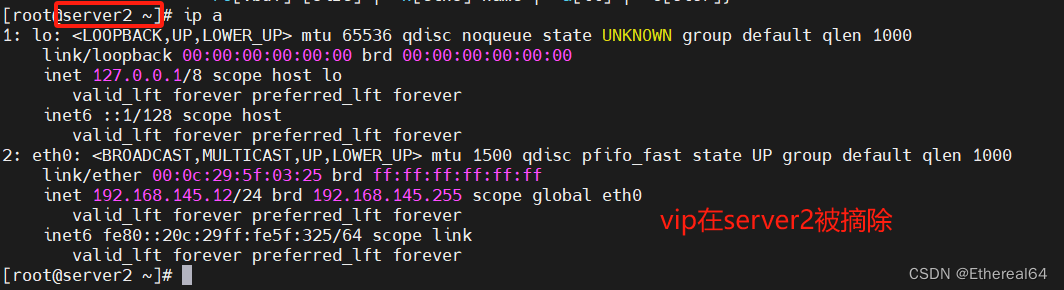


使用的是master_ip_failover故障切换脚本
手动恢复server2

删除manager端生成的锁定文件和日志

手动在线切换master
masterha_master_switch --conf=/etc/masterha/app1.cnf --master_state=alive --new_master_host=192.168.145.12 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000
#切换到server2
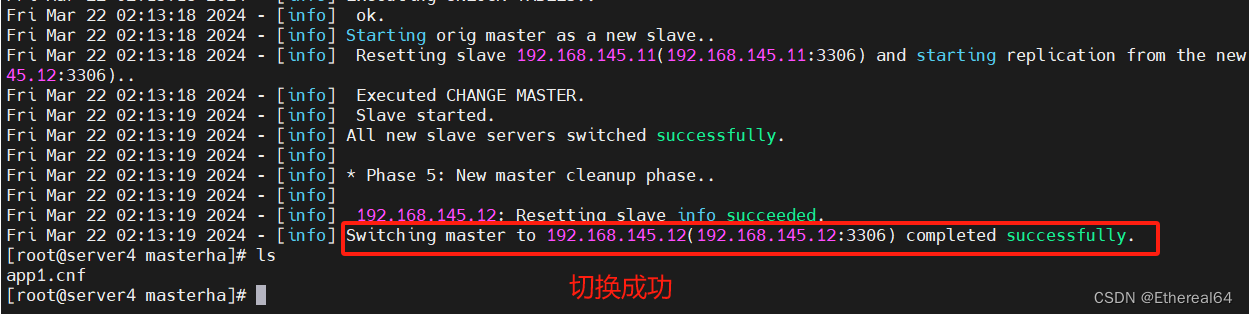

此时使用的是master_ip_online_change在线切换脚本
redis数据库
1.redis部署
NoSQL是一种非关系型数据库,它提供了灵活的数据存储和处理方式,不局限于传统的关系型数据库模型。NoSQL数据库通常适用于需要处理大量、高速度、分布式数据的场景,如大数据、实时数据处理、Web应用程序等。常见的NoSQL数据库包括MongoDB、Cassandra、Redis、HBase等
Redis是一种开源的内存键值存储数据库,它支持多种数据结构(如字符串、哈希、列表、集合等)并提供了丰富的功能和灵活的用途。Redis被广泛应用于缓存、会话存储、消息队列等场景,因为它具有快速的读写能力和丰富的功能特性。
除了数据持久化以外,Redis还支持主从复制、发布订阅等特性,可以用于构建高可用性的系统。由于其高性能和灵活性,Redis在Web开发、实时数据处理、分布式系统等领域得到了广泛的应用。
除了作为缓存存储之外,Redis还可以用作轻量级的数据库、消息中间件等,是一个功能强大的工具,为各种场景下的数据存储和处理提供了便利的解决方案
首先关闭mysql
/etc/init.d/mysqld stop
redis最新版本可以从官网 https://redis.io 下载

tar zxf redis-6.2.4.tar.gz
#解压
make
#编译
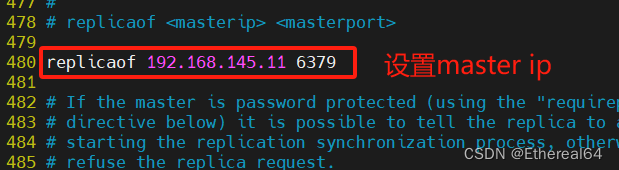
make install
#安装
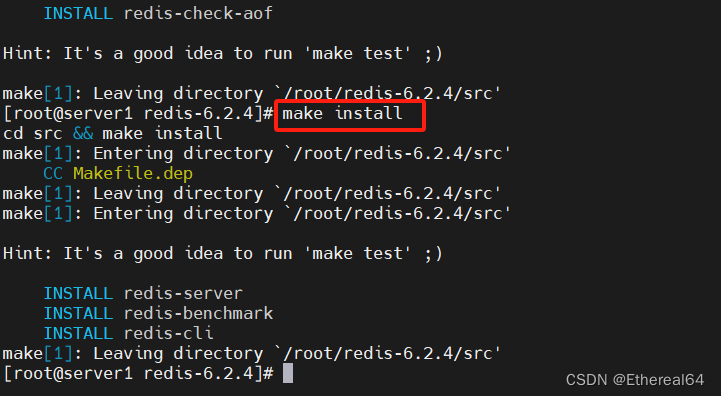
cd utils/
vim install_server.sh
#编辑安装脚本
./install_server.sh
#运行安装脚本

netstat -antlp |grep :6379

vim /etc/redis/6379.conf
#编辑配置文件


2.redis常用指令

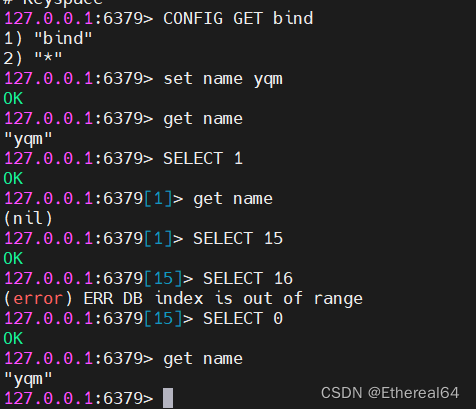





详细命令可以在中文官网https://redis.net.cn查看
3.redis主从复制

给要配置服务的节点都安装rsync
yum install -y rsync
rsync -a redis-* server2:/usr/local/bin/
rsync -a redis-6.2.4 server2:
#拷贝程序

server2上完成redis部署

cd ~/redis-6.2.4/
cd utils/
./install_server.sh
#执行安装脚本

vim /etc/redis/6379.conf
#编辑配置文件

/etc/init.d/redis_6379 restart
#重启服务

server操作同理
测试:
在master:
redis-cli
127.0.0.1:6379> info
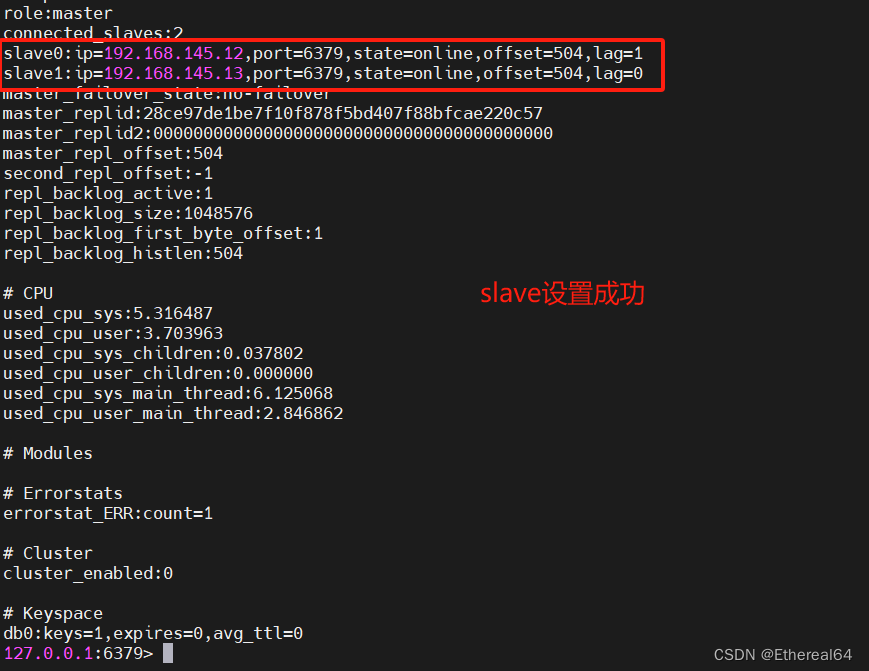
server2:

server3:

slave:


4.redis主从切换
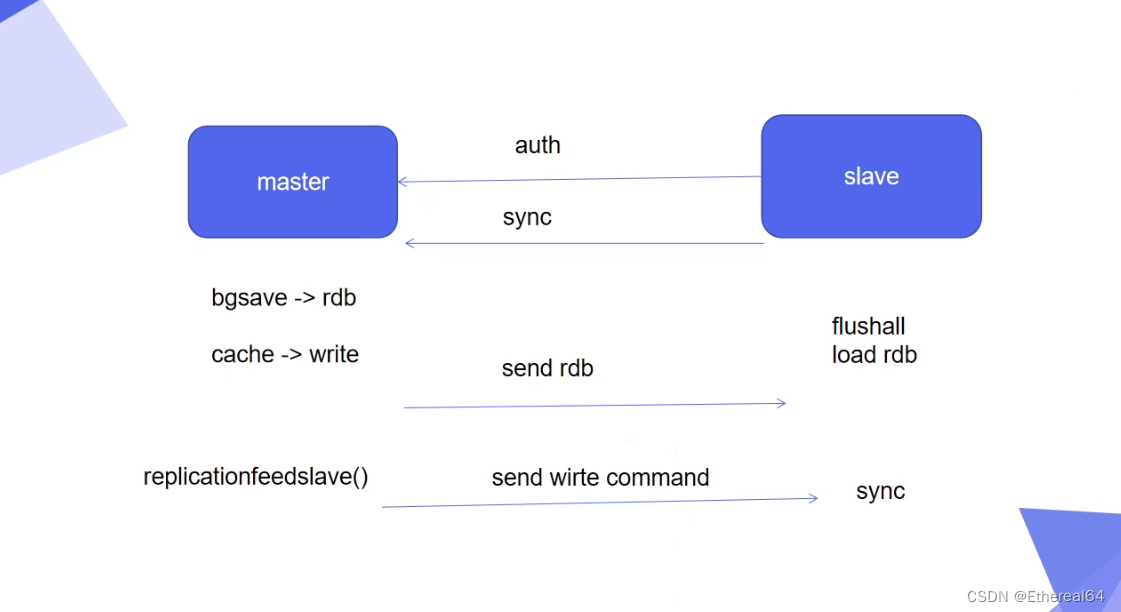

server1:
cp sentinel.conf /etc/redis/
#复制配置文件
cd /etc/redis/
vim sentinel.conf
#编辑,修改两行内容
sentinel monitor mymaster 192.168.145.11 6379 2
#指定监控主服务器组名称mymaster,IP地址192.168.145.11,端口6379,执行故障切换最小投票数为2,至少需要两个哨兵节点统一进行故障转移

sentinel down-after-milliseconds mymaster 10000
#在主服务器在10秒内未响应时(即认为不可达),将该主服务器标记为主服务器下线,触发后续的故障转移流程

sentinel parallel-syncs mymaster 1
#在进行故障转移时最多允许1个从服务器同时进行同步操作,这有助于控制并发同步操作的数量,避免对主服务器和网络造成过大负担
daemonize no
#在前台运行
scp sentinel.conf server2:/etc/redis/
scp sentinel.conf server3:/etc/redis/
#拷贝到另外两台服务器,要在启动服务之前拷贝,启动后会将当前集群状态写入文件

redis-sentinel /etc/redis/sentinel.conf
#启动服务

server2,server3直接启动服务,不用修改配置文件
redis-sentinel /etc/redis/sentinel.conf
#启动服务
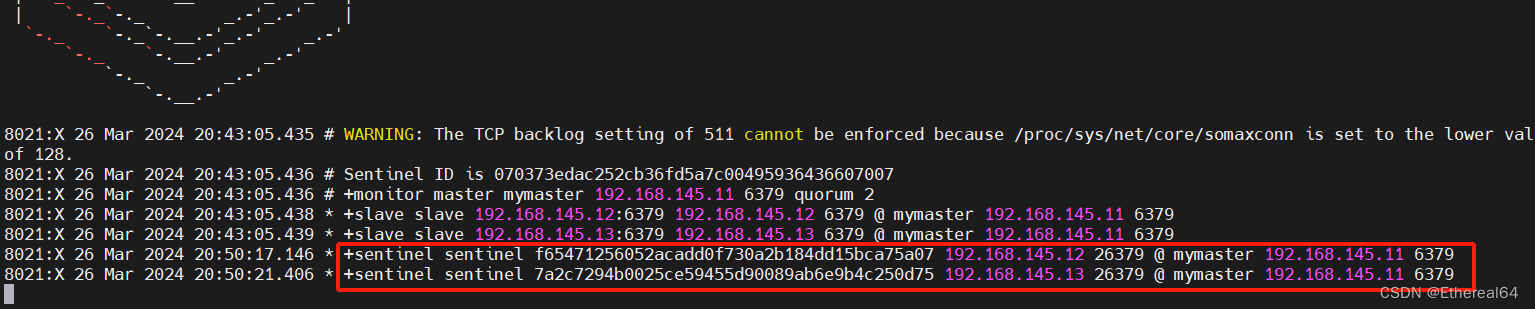
重新开启一个终端连接server1
127.0.0.1:6379> shutdown
#关闭redis服务

10秒后server2发起投票

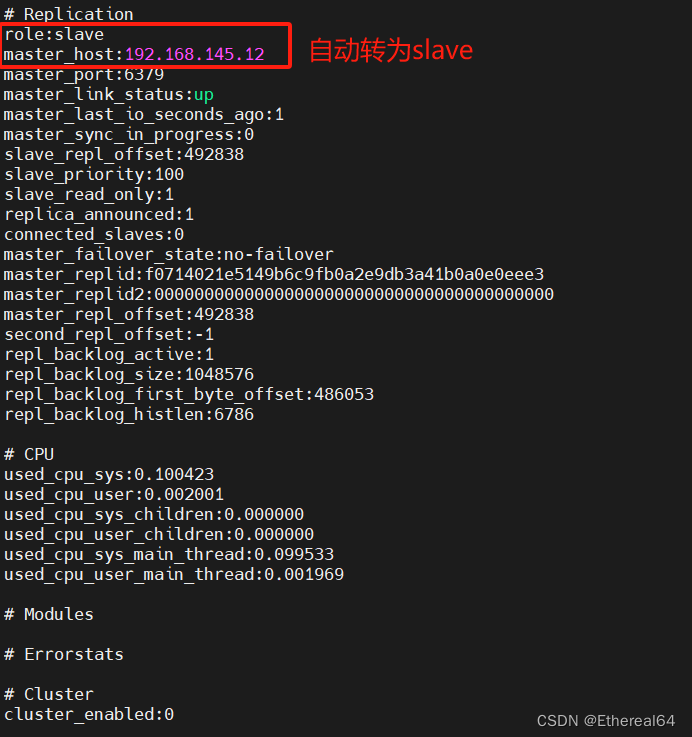
#完成投票后server1主观下线,选举server2为新的master,修改从节点配置文件,切换后标记server1为下线状态
再次启动server1

redis-cli
127.0.0.1:6379> info
#查看信息
![]()

配置文件自动修改
问题:
master重启后,切换到slave的网络出现了故障,此时客户还在往master中写数据,那么当master切换到slave后,由于slave会自动flushall,那么这部分数据就丢失了
解决办法:
在配置主从之前在配置文件中加入选项min-slaves-to-write=2,表示master在执行写操作前需要至少有两个从节点处于可用状态,可避免主从切换过程中的数据丢失
5.redis集群
Redis Cluster 是 Redis 提供的分布式解决方案,它允许将多个 Redis 节点组合成一个集群,用于存储大规模的数据并提供高可用性和横向扩展能力。Redis Cluster 自动将数据分片存储在不同的节点上,并提供了节点间的数据复制和故障转移机制,以保证数据的安全性和可靠性。
Redis Cluster 的特点包括:
- 分布式数据存储:数据被分片存储在多个节点上,可以存储超出单个 Redis 实例内存限制的数据量。
- 高可用性:当某个节点发生故障时,Redis Cluster 会自动进行故障转移,保证数据的可用性。
- 横向扩展:通过增加节点,可以线性地扩展 Redis 集群的容量和吞吐量。
- 自动化管理:Redis Cluster 提供了自动化的故障检测、故障转移和重新平衡数据的功能,简化了集群的管理工作。
通过这些特点,Redis Cluster 成为了存储大规模数据并提供高性能、高可用性的理想选择。它被广泛应用于缓存、会话存储、实时数据分析等场景中。
虽然 Redis Cluster 在分布式系统中有许多优点,但也存在一些缺点,包括:
-
数据一致性:Redis Cluster 使用的是哈希槽(slot)分片机制,数据按照槽进行分片存储,但在节点动态增减或者故障恢复时,可能会导致数据迁移和重新分配槽,从而引起数据不一致或者部分数据丢失的情况。
-
节点故障处理:虽然 Redis Cluster 提供了自动化的故障检测和转移功能,但在节点故障发生时,会引起数据迁移和重新分片操作,可能会影响系统性能和稳定性。
-
网络通信开销:在 Redis Cluster 中,节点之间需要频繁进行数据同步和通信,特别是在数据迁移、故障转移等操作时,会增加网络通信开销,影响系统性能。
-
复杂性:相对于单机 Redis 实例,Redis Cluster 的配置、部署和管理更为复杂,需要考虑节点之间的通信、数据分片、故障处理等方面的问题,对运维人员的要求较高。
-
跨槽事务支持:由于 Redis Cluster 的数据分片机制,无法支持涉及多个槽(slot)的事务操作,这限制了某些复杂场景下的数据操作能力。
综上所述,虽然 Redis Cluster 在大规模数据存储和高可用性方面表现优异,但也存在一些挑战和局限性,需要在实际应用中根据具体情况权衡利弊。
无中心化设计,任何节点都可读写
整合度高,二次开发成本高
Codis 是一个开源的分布式 Redis 解决方案,它在多个 Redis 服务器之上提供了代理层和管理工具,用于解决 Redis 单机容量有限、高可用性、扩展性等问题。Codis 通过在 Redis 服务器前部署代理,实现了数据的分片和负载均衡,从而有效地提升了 Redis 集群的性能和可扩展性。
Codis 提供了集群管理工具、监控工具和自动化故障转移等功能,使得 Redis 集群的部署和维护变得更加便捷和高效。同时,它也支持对 Redis 的扩展模块进行定制和集成,满足了不同场景下的需求。
总的来说,Codis 是一个为 Redis 集群提供代理和管理功能的工具,可以帮助用户轻松地构建和管理大规模的 Redis 集群,提供更高的性能和可用性。
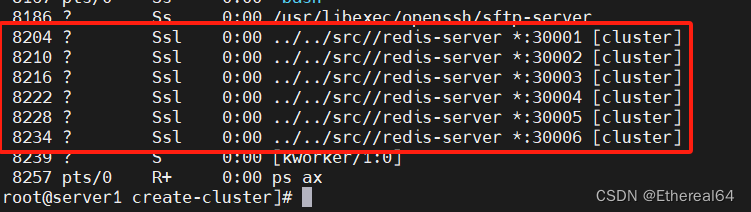
cd ~/redis-6.2.4/utils/create-cluster
./create-cluster start
#执行脚本


ps ax
#查看进程
./create-cluster create
#自动创建集群
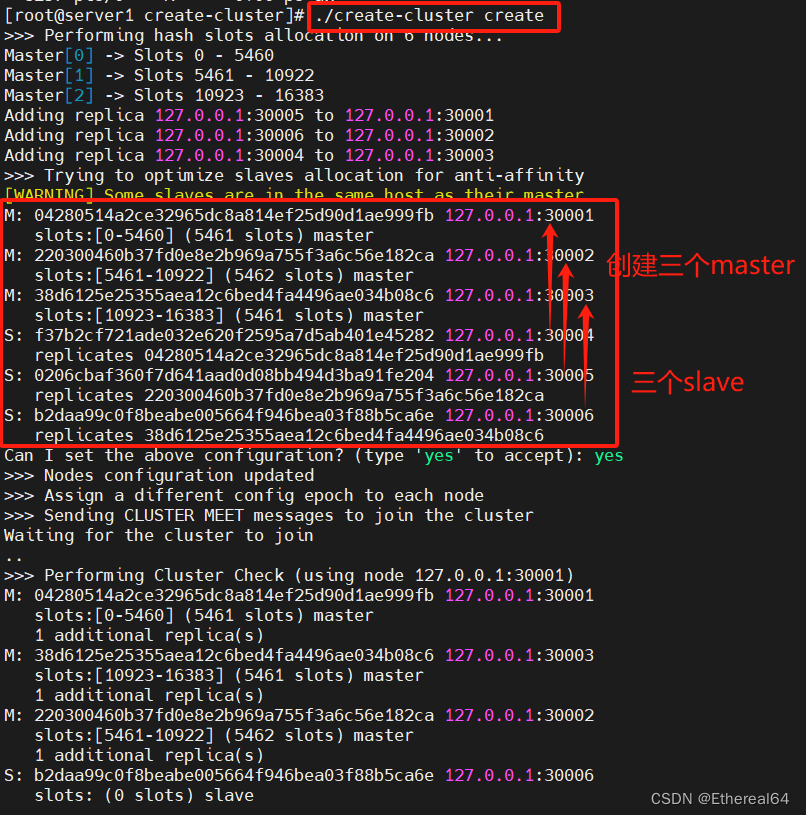
将16384个哈希槽平均分配给了3个master节点
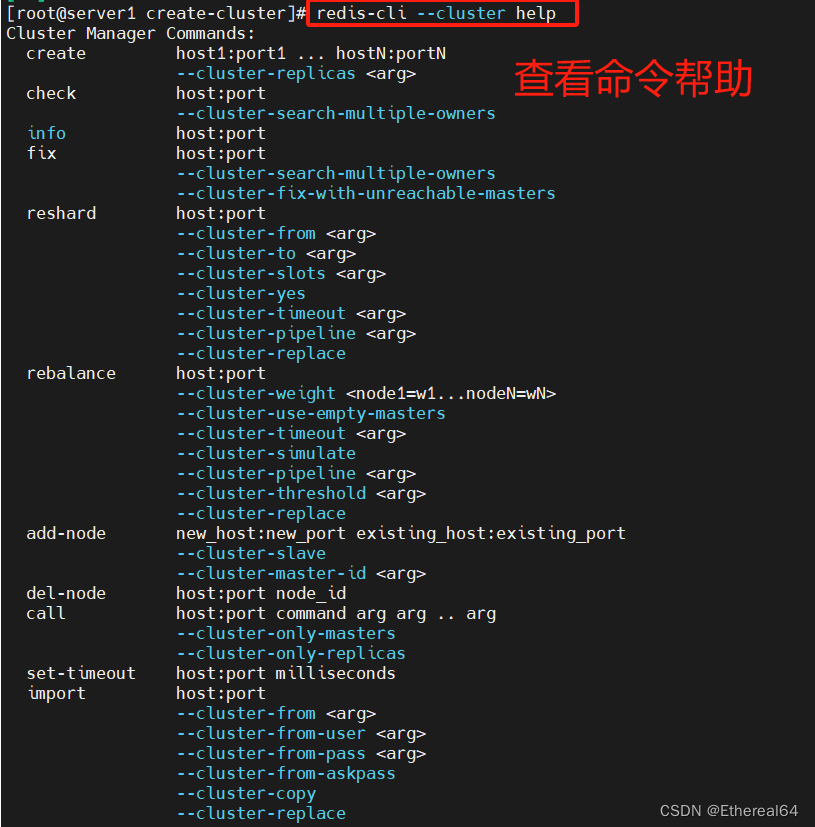
redis-cli --cluster help
#查看命令帮助
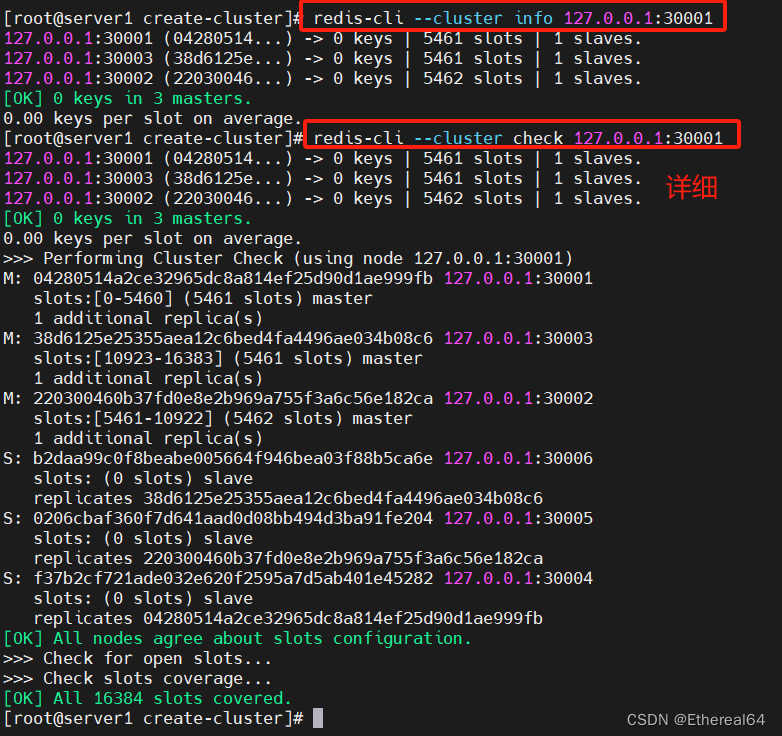
redis-cli --cluster info 127.0.0.1:30001
redis-cli --cluster check 127.0.0.1:30001
#查看集群信息
redis-cli -c -p 30001 info的节点信息
#查看30001端口





redis-cli -c -p 30002 shutdown
#关闭30002的服务,集群自动切换



数据存储在30005
./create-cluster start
#重新使用脚本创建集群
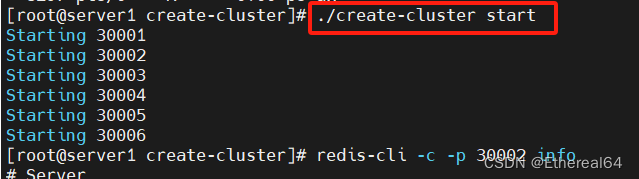
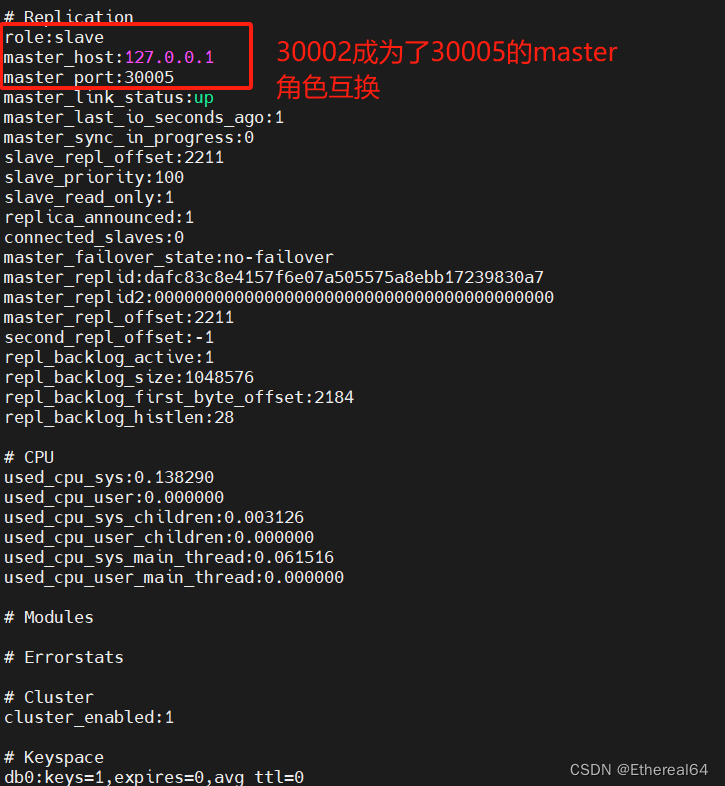
当部分节点同时故障时,可能导致哈希槽缺失,此时集群将不可用

./create-cluster start

vim create-cluster
#编辑脚本,再启动两个redis实例
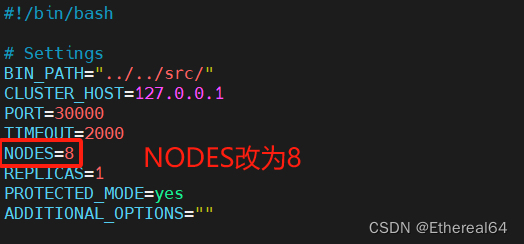


在线添加节点
redis-cli --cluster add-node 127.0.0.1:30007 127.0.0.1:30001
#添加30007为master

redis-cli --cluster add-node 127.0.0.1:30008 127.0.0.1:30001 --cluster-slave --cluster-master-id 3fd5360e705e8841d9fe9b933aa73c4a68dcbd8b
#在线添加30008节点



redis-cli --cluster reshard 127.0.0.1:30001
#重新分配槽位,随意指定节点即可,因为是无中心化
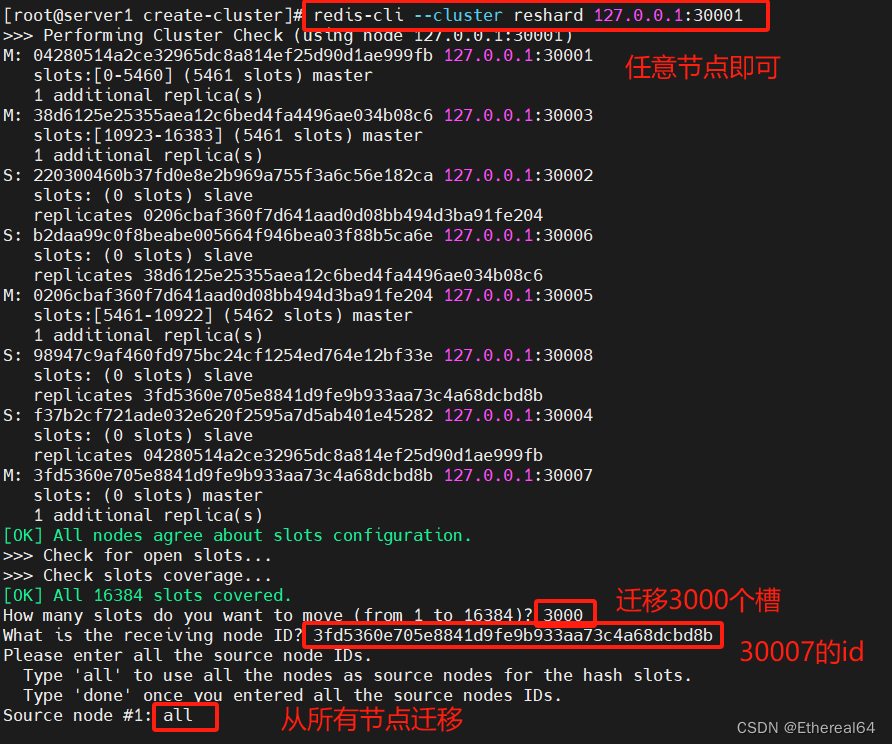

redis-cli --cluster check 127.0.0.1:30001
#查看集群信息
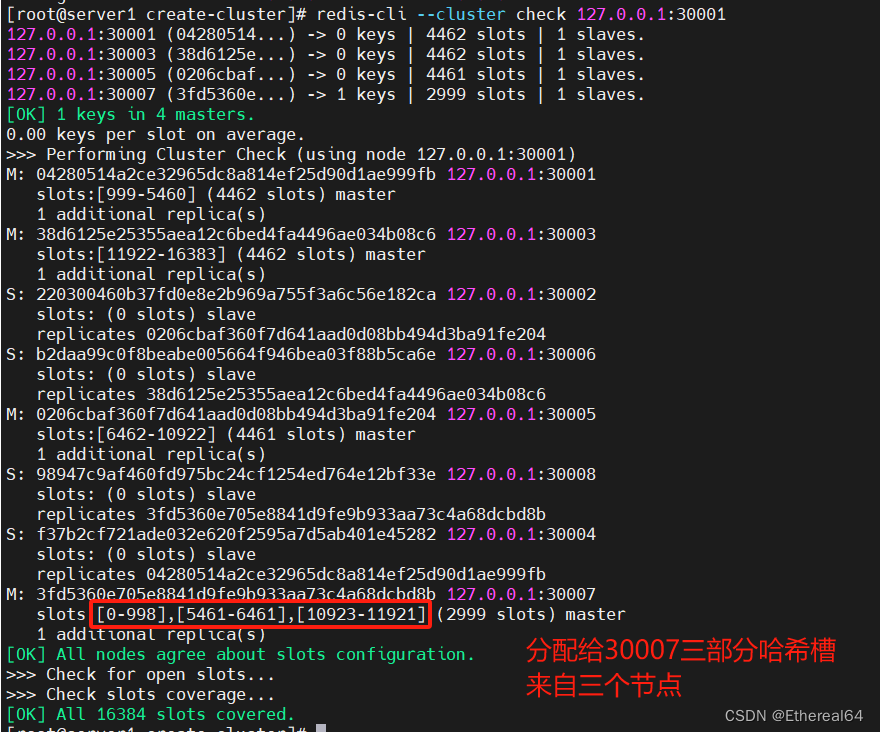

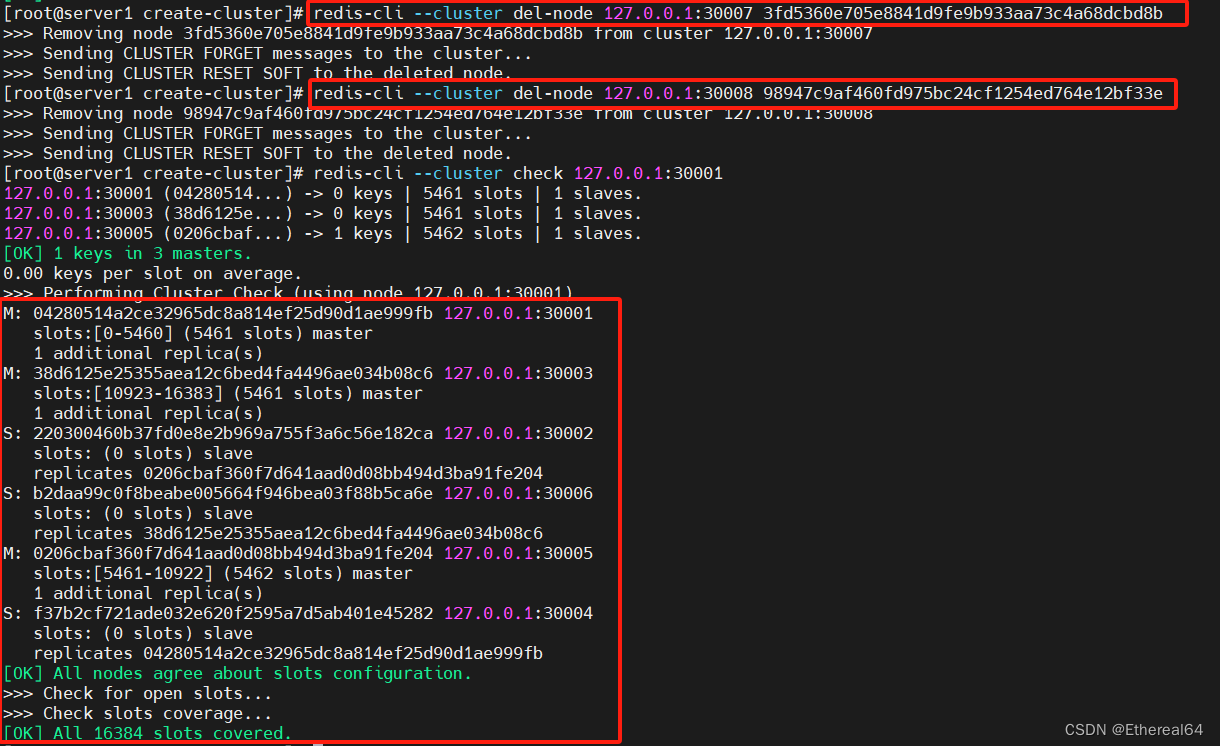
删除节点时,可先使用reshard进行重新分配槽位,将要删除结点的哈希槽迁移出来
再使用redis-cli --cluster del-node host:port node_id删除节点即可

以此类推将槽全部迁移出去,再删除节点即可






![P8649 [蓝桥杯 2017 省 B] k 倍区间:做题笔记](https://img-blog.csdnimg.cn/direct/d9ebb88b2eb84627b75faf965b328724.png)