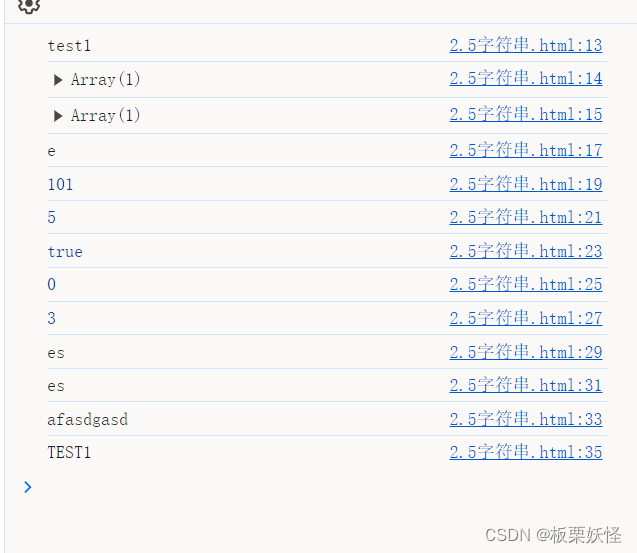
摘要
本文使用ECA-Net注意力机制加入到YoloV5中。我尝试了多种改进方法,并附上改进结果,方便大家了解改进后的效果,为论文改进提供思路。(更新中。。。。)
论文:《ECA-Net:用于深度卷积神经网络的高效通道注意力》
arxiv.org/pdf/1910.03151.pdf
最近,通道注意机制已被证明在改善深度卷积神经网络(CNN)的性能方面具有巨大潜力。然而,大多数现有方法致力于开发更复杂的注意模块以实现更好的性能,这不可避免地会增加模型的复杂性。 为了克服性能和复杂性折衷之间的矛盾,本文提出了一种有效的信道注意(ECA)模块,该模块仅包含少量参数,同时带来明显的性能提升。 通过剖析SENet中的通道注意模块,我们从经验上表明避免降维对于学习通道注意很重要,并且适当的跨通道交互可以在保持性能的同时显着降低模型的复杂性。因此,我们提出了一种无需降维的局部跨通道交互策略,该策略可以通过一维卷积有效地实现。 此外,我们提出了一种方法来自适应选择一维卷积的内核大小,确定局部跨通道交互的覆盖范围。提出的ECA模块既有效又有效,例如,针对ResNet50主干的模块参数和计算分别为80 vs. 24.37M和 4.7 e − 4 4.7e^{-4 } 4.7e−4 GFLOP与3.86 GFLOP,Top-1准确性而言提升超过2% 。 我们使用ResNets和MobileNetV2的骨干广泛评估了ECA模块的图像分类,对象检测和实例分割。 实验结果表明,我们的模块效率更高,同时性能优于同类模块。
1、简介
深卷积神经网络(CNN)已在计算机视觉社区中得到广泛使用,并且在图像分类,对象检测和语义分割等广泛的任务中取得了长足的进步。从开创性的AlexNet [17]开始,许多研究 不断研究以进一步改善深层CNN的性能。 近来,将通道注意力并入卷积块中引起了很多兴趣,显示出在性能改进方面的巨大潜力。 代表性的方法之一是挤压和激励网络(SENet)[14],它可以学习每个卷积块的通道注意,从而为各种深层CNN架构带来明显的性能提升。
在SENet [14]中设置了压缩(即特征聚合)和激励(即特征重新校准)之后,一些研究通过捕获更复杂的通道相关性或结合额外的空间关注来改善SE块。 尽管这些方法已经实现了更高的精度,但是它们通常带来更高的模型复杂度并承受更大的计算负担。 与前面提到的以更高的模型复杂度为代价实现更好的性能的方法不同,本文重点关注的问题是:是否可以以一种更有效的方式来学习有效的通道注意力机制?
为了回答这个问题,我们首先回顾一下SENet中的通道注意力模块。 具体而言,给定输入特征,SE块首先为每个通道独立采用全局平均池化,然后使用两个全连接(FC)层以及非线性Sigmoid函数来生成通道权重。 两个FC层旨在捕获非线性跨通道交互,其中涉及降低维度以控制模型的复杂性。 尽管此策略在后续的通道注意力模块中被广泛使用[33、13、9],但我们的经验研究表明,降维会给通道注意力预测带来副作用,并且捕获所有通道之间的依存关系效率不高且不必要。
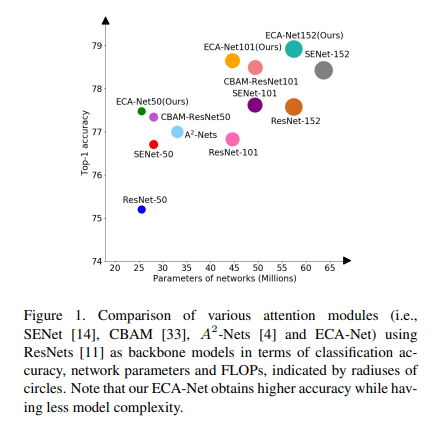
因此,本文提出了一种用于深层CNN的有效通道注意(ECA)模块,该模块避免了维度缩减,并有效捕获了跨通道交互。如图2所示,在不降低维度的情况下进行逐通道全局平均池化之后,我们的ECA通过考虑每个通道及其k个近邻来捕获本地跨通道交互 。实践证明,这种方法可以保证效率和有效性。请注意,我们的ECA可以通过大小为k的快速一维卷积有效实现,其中内核大小k代表本地跨通道交互的覆盖范围,即有多少个相近邻参与一个通道的注意力预测。我们提出了一种自适应确定k的方法,其中交互作用的覆盖范围(即内核大小k)与通道维成比例。如图1和表3所示,与骨干模型[11]相比,带有我们的ECA模块(称为ECA-Net)的深层CNN引入了很少的附加参数和可忽略的计算,同时带来了显着的性能提升。例如,对于具有24.37M参数和3.86 GFLOP的ResNet-50,ECA-Net50的附加参数和计算分别为80和 4.7 e − 4 4.7e^{-4} 4.7e−4 GFLOP;同时,在Top-1准确性方面,ECA-Net50优于ResNet-50 2.28%。
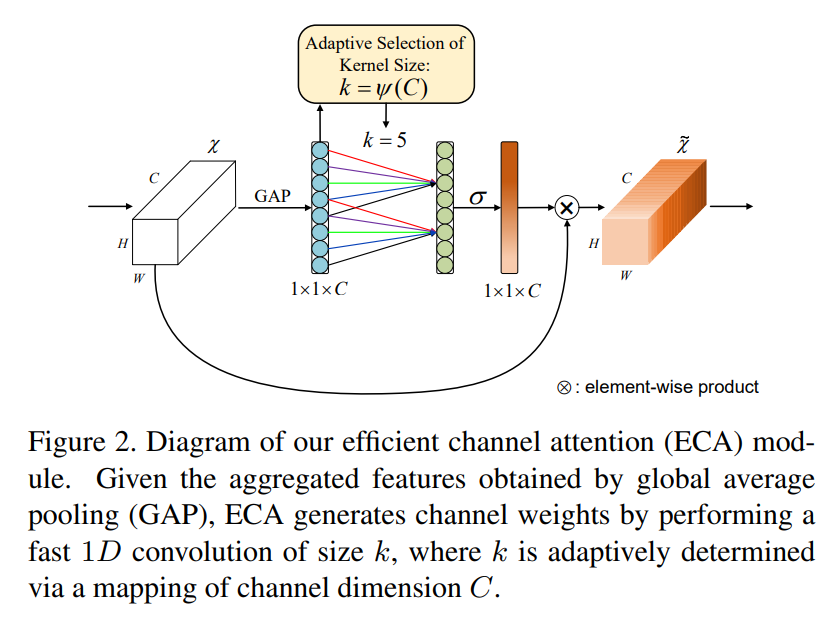
表1总结了现有的注意力模块,包括通道降维(DR),通道交互和轻量级模型方面,我们可以看到,我们的ECA模块通过避免通道降维,同时以极轻量的方式捕获了不同通道间的交互。 为了评估我们的方法,我们在ImageNet-1K [6]和MS COCO [23]上使用不同的深度CNN架构在各种任务中进行了实验。

本文的主要工作概括如下:(1)解析SE块,并通过经验证明避免降维对于学习有效,适当的不同通道交互对于通道注意力非常重要。(2)基于以上分析,我们尝试通过提出一种有效的通道注意(ECA)来用于深度CNN的极其轻量级的通道注意模块,该模块在增加明显改进的同时,增加了很少的模型复杂性。(3)在ImageNet-1K和MS COCO上的实验结果表明,该方法具有比最新技术更低的模型复杂 度,同时具有非常好的竞争性能。
2、相关工作
事实证明,注意力机制是增强深层CNN的潜在手段。 SE-Net [14]首次提出了一种有效的机制来学习通道关注度并实现并有不错的效果。随后,注意力模块的发展可以大致分为两个方向:(1)增强特征聚合; (2)通道和空间注意的结合。具体来说,CBAM [33]使用平均池和最大池来聚合特征。 GSoP [9]引入了二阶池,以实现更有效的特征聚合。 GE [13]探索了使用深度卷积[5]聚合特征的空间扩展。 CBAM [33]和scSE [27]使用内核大小为k x k的2D卷积计算空间注意力,然后将其与通道注意力结合起来。与非本地(NL)神经网络[32]共享相似的哲学,GCNet [2]开发了一个简化的NL网络并与SE块集成在一起,从而形成了一个用于建模远程依赖性的轻量级模块。 Double Attention Networks(A2-Nets)[4]为图像或视频识别的NL块引入了一种新颖的关联函数。双重注意网络(DAN)[7]同时考虑了基于NL的信道和空间注意,以进行语义分割。但是,由于它们的高模型复杂性,大多数以上基于NL的注意力模块只能在单个或几个卷积块中使用。显然,所有上述方法都集中于提出复杂的注意力模块以提高性能。与它们不同的是,我们的ECA旨在以较低的模型复杂性来学习有效的通道注意力。
我们的工作还涉及为轻量级CNN设计的高效卷积。 两种广泛使用的有效卷积是组卷积和深度方向可分离卷积。 如表2所示,尽管这些有效的卷积涉及较少的参数,但它们在注意力模块中的作用不大。我们的ECA模块旨在捕获局部跨通道交互,这与通道局部卷积[36]和通道级卷积具有相似之处 [8]; 与它们不同的是,我们的方法研究了具有自适应内核大小的一维卷积来替换通道注意力模块中的FC层。与分组和深度可分离卷积相比,我们的方法以较低的模型复杂度实现了更好的性能。
3、提出的方法
在本节中,我们首先回顾了SENet[14]中的通道注意力模块(即SE块)。然后,我们通过分析降维和跨通道交互的影响,对SE块进行了实证诊断。这促使我们提出ECA模块。此外,我们开发了一种自适应确定ECA参数的方法,并最后展示了如何将其应用于深度卷积神经网络。
3.1、重新审视SE块中的通道注意力
假设一个卷积块的输出为 X ∈ R W × H × C \mathcal{X} \in \mathbb{R}^{W \times H \times C} X∈RW×H×C,其中 W , H W, H W,H 和 C C C 分别是宽度、高度和通道维度(即滤波器的数量)。据此,SE块中通道的权重可以计算为
ω = σ ( f { W 1 , W 2 } ( g ( X ) ) ) , (1) \boldsymbol{\omega} = \sigma\left(f_{\left\{\mathbf{W}_{1}, \mathbf{W}_{2}\right\}}(g(\mathcal{X}))\right),\tag{1} ω=σ(f{W1,W2}(g(X))),(1)
其中 g ( X ) = 1 W H ∑ i = 1 , j = 1 W , H X i j g(\mathcal{X}) = \frac{1}{W H} \sum_{i=1, j=1}^{W, H} \mathcal{X}_{i j} g(X)=WH1∑i=1,j=1W,HXij 是通道级的全局平均池化(GAP), σ \sigma σ 是Sigmoid函数。令
y = g ( X ) \mathbf{y} = g(\mathcal{X}) y=g(X), f { w 1 , w 2 } f_{\left\{\mathbf{w}_{1}, \mathbf{w}_{2}\right\}} f{w1,w2} 的形式为
f { W 1 , W 2 } ( y ) = W 2 ReLU ( W 1 y ) , (2) f_{\left\{\mathbf{W}_{1}, \mathbf{W}_{2}\right\}}(\mathbf{y}) = \mathbf{W}_{2} \text{ReLU}\left(\mathbf{W}_{1} \mathbf{y}\right),\tag{2} f{W1,W2}(y)=W2ReLU(W1y),(2)
其中ReLU表示修正线性单元[25]。为了避免模型复杂度过高, W 1 \mathbf{W}_{1} W1 和 W 2 \mathbf{W}_{2} W2 的大小分别设置为 C × ( C r ) C \times \left(\frac{C}{r}\right) C×(rC) 和 ( C r ) × C \left(\frac{C}{r}\right) \times C (rC)×C。我们可以看到, f { W 1 , W 2 } f_{\left\{\mathbf{W}_{1}, \mathbf{W}_{2}\right\}} f{W1,W2} 包含了通道注意力块的所有参数。虽然式(2)中的降维可以减少模型复杂度,但它破坏了通道与其权重之间的直接对应关系。例如,单个全连接层使用所有通道的线性组合来预测每个通道的权重。但是式(2)首先将通道特征投影到低维空间,然后再映射回来,这使得通道与其权重之间的对应关系变得间接。
3.2、高效通道注意力(ECA)模块
在回顾了SE块之后,我们进行了实证比较,以分析通道降维和跨通道交互对通道注意力学习的影响。根据这些分析,我们提出了高效的通道注意力(ECA)模块。
3.2.1、避免降维
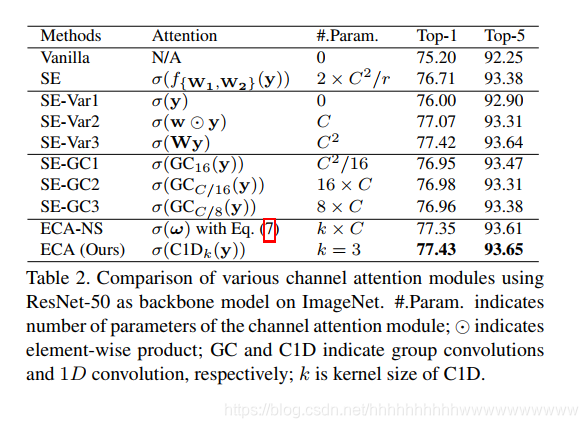
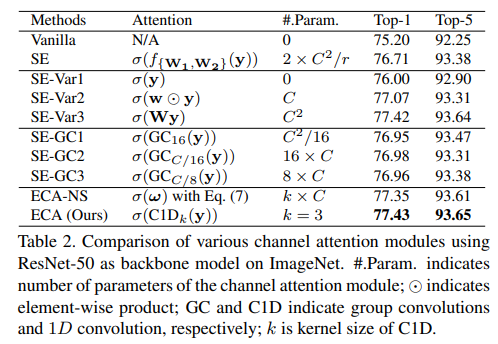
如上所述,式(2)中的降维使得通道与其权重之间的对应关系变得间接。为了验证其影响,我们将原始的SE块与其三个变体(即SE-Var1、SE-Var2和SE-Var3)进行了比较,它们都不进行降维。如表2所示,没有参数的SE-Var1仍然优于原始网络,这表明通道注意力有能力提高深度卷积神经网络的性能。同时,SE-Var2独立地学习每个通道的权重,这略优于SE块,同时涉及的参数更少。这可能表明,通道与其权重之间需要直接的对应关系,避免降维比考虑非线性的通道依赖性更为重要。此外,使用单个全连接层的SE-Var3的性能优于SE块中使用降维的两个全连接层。上述所有结果都清楚地表明,避免降维有助于学习有效的通道注意力。因此,我们开发了没有通道降维的ECA模块。
3.2.2、局部跨通道交互
对于没有降维的聚合特征 y ∈ R C \mathbf{y} \in \mathbb{R}^{C} y∈RC,通道注意力可以通过以下方式学习:
ω = σ ( W y ) (3) \boldsymbol{\omega} = \sigma(\mathbf{W} \mathbf{y}) \tag{3} ω=σ(Wy)(3)
其中 W \mathbf{W} W 是一个 C × C C \times C C×C 的参数矩阵。特别是,对于SE-Var2和SE-Var3,我们有
W = { W var 2 = [ w 1 , 1 … 0 ⋮ ⋱ ⋮ 0 … w C , C ] , W var 3 = [ w 1 , 1 ⋯ w 1 , C ⋮ ⋱ ⋮ w 1 , C … w C , C ] , (4) \mathbf{W} = \left\{ \begin{array}{c} \mathbf{W}_{\text {var } 2} = \left[ \begin{array}{ccc} w^{1,1} & \ldots & 0 \\ \vdots & \ddots & \vdots \\ 0 & \ldots & w^{C, C} \end{array} \right], \\ \mathbf{W}_{\text {var } 3} = \left[ \begin{array}{ccc} w^{1,1} & \cdots & w^{1, C} \\ \vdots & \ddots & \vdots \\ w^{1, C} & \ldots & w^{C, C} \end{array} \right], \end{array} \right.\tag{4} W=⎩ ⎨ ⎧Wvar 2= w1,1⋮0…⋱…0⋮wC,C ,Wvar 3= w1,1⋮w1,C⋯⋱…w1,C⋮wC,C ,(4)
其中,SE-Var2的 W var 2 \mathbf{W}_{\text {var } 2} Wvar 2 是一个对角矩阵,包含 C C C 个参数;SE-Var3的 W var 3 \mathbf{W}_{\text {var } 3} Wvar 3 是一个全矩阵,包含 C × C C \times C C×C 个参数。如式(4)所示,关键区别在于SE-Var3考虑了跨通道交互,而SE-Var2没有,因此SE-Var3实现了更好的性能。这一结果表明,跨通道交互有助于学习通道注意力。然而,SE-Var3需要大量的参数,导致模型复杂度较高,尤其是对于通道数量较大的情况。
在SE-Var2和SE-Var3之间,一个可能的折衷方案是将 W var 2 \mathbf{W}_{\text {var } 2} Wvar 2扩展为块对角矩阵,即:
W G = [ W G 1 ⋯ 0 ⋮ ⋱ ⋮ 0 ⋯ W G G ] (5) \mathbf{W}_{G} = \left[ \begin{array}{ccc} \mathbf{W}_{G}^{1} & \cdots & \mathbf{0} \\ \vdots & \ddots & \vdots \\ \mathbf{0} & \cdots & \mathbf{W}_{G}^{G} \end{array} \right] \tag{5} WG= WG1⋮0⋯⋱⋯0⋮WGG (5)
在式(5)中,我们将通道分为 G G G组,每组包含 C / G C / G C/G个通道,并在每个组内独立地学习通道注意力,从而以局部的方式捕获跨通道交互。因此,它涉及 C 2 / G C^{2} / G C2/G个参数。从卷积的角度来看,SE-Var2、SE-Var3和式(5)可以分别视为深度可分离卷积、全连接层和组卷积。这里,带有组卷积的SE块(SE-GC)表示为 σ ( G C G ( y ) ) = σ ( W G y ) \sigma\left(\mathrm{GC}_{G}(\mathbf{y})\right) = \sigma\left(\mathbf{W}_{G} \mathbf{y}\right) σ(GCG(y))=σ(WGy)。
然而,正如[24]所示,过多的组卷积会增加内存访问成本,从而降低计算效率。此外,如表2所示,具有不同组数的SE-GC相比SE-Var2并没有带来性能提升,这表明它并不是一种有效的捕获局部跨通道交互的方案。原因可能是SE-GC完全忽略了不同组之间的依赖关系。
因此,我们需要寻找一种既能保持计算效率又能有效捕获局部跨通道交互的方法。这引导我们提出了高效通道注意力(ECA)模块,该模块通过一维卷积在相邻通道之间捕获局部跨通道交互,从而实现了在避免降维的同时学习有效的通道注意力。
在本文中,我们探索了另一种捕获局部跨通道交互的方法,旨在同时保证效率和有效性。具体来说,我们采用带状矩阵 W k \mathbf{W}_{k} Wk来学习通道注意力,其中 W k \mathbf{W}_{k} Wk具有如下形式:
[ w 1 , 1 ⋯ w 1 , k 0 0 ⋯ ⋯ 0 0 w 2 , 2 ⋯ w 2 , k + 1 0 ⋯ ⋯ 0 ⋮ ⋮ ⋮ ⋮ ⋱ ⋮ ⋮ ⋮ 0 ⋯ 0 0 ⋯ w C , C − k + 1 ⋯ w C , C ] (6) \left[ \begin{array}{cccccccc} w^{1,1} & \cdots & w^{1, k} & 0 & 0 & \cdots & \cdots & 0 \\ 0 & w^{2,2} & \cdots & w^{2, k+1} & 0 & \cdots & \cdots & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots & \vdots \\ 0 & \cdots & 0 & 0 & \cdots & w^{C, C-k+1} & \cdots & w^{C, C} \end{array} \right] \tag{6} w1,10⋮0⋯w2,2⋮⋯w1,k⋯⋮00w2,k+1⋮000⋱⋯⋯⋯⋮wC,C−k+1⋯⋯⋮⋯00⋮wC,C (6)
显然,式(6)中的 W k \mathbf{W}_{k} Wk涉及 k × C k \times C k×C个参数,这通常少于式(5)中的参数数量。此外,式(6)避免了式(5)中不同组之间的完全独立性。如表2所示,式(6)中的方法(即ECA-NS)优于式(5)中的SE-GC。对于式(6), y i y_{i} yi的权重仅通过考虑 y i y_{i} yi与其 k k k个邻居之间的交互来计算,即:
ω i = σ ( ∑ j = 1 k w i j y i j ) , y i j ∈ Ω i k , (7) \omega_{i} = \sigma\left(\sum_{j=1}^{k} w_{i}^{j} y_{i}^{j}\right), \quad y_{i}^{j} \in \Omega_{i}^{k}, \tag{7} ωi=σ(j=1∑kwijyij),yij∈Ωik,(7)
其中 Ω i k \Omega_{i}^{k} Ωik表示 y i y_{i} yi的 k k k个相邻通道的集合。
一种更有效的方法是让所有通道共享相同的学习参数,即:
ω i = σ ( ∑ j = 1 k w j y i j ) , y i j ∈ Ω i k . (8) \omega_{i} = \sigma\left(\sum_{j=1}^{k} w^{j} y_{i}^{j}\right), \quad y_{i}^{j} \in \Omega_{i}^{k}. \tag{8} ωi=σ(j=1∑kwjyij),yij∈Ωik.(8)
注意,这种策略可以通过一个具有大小为 k k k的卷积核的快速一维卷积轻松实现,即:
ω = σ ( C 1 D k ( y ) ) , (9) \boldsymbol{\omega} = \sigma\left(\mathrm{C}1\mathrm{D}_{k}(\mathbf{y})\right), \tag{9} ω=σ(C1Dk(y)),(9)
其中C1D表示一维卷积。这里,式(9)中的方法被称为高效通道注意力(ECA)模块,它仅涉及 k k k个参数。如表2所示,我们的ECA模块在 k = 3 k=3 k=3时与SE-var 3取得了相似的结果,但模型复杂度要低得多,这通过适当捕获局部跨通道交互保证了效率和有效性。
3.2.3、局部跨通道交互的覆盖范围
由于我们的ECA模块(9)旨在适当捕获局部跨通道交互,因此需要确定交互的覆盖范围(即一维卷积的核大小 k k k)。对于不同CNN架构中具有不同通道数的卷积块,交互的优化覆盖范围可以通过手动调整获得。然而,通过交叉验证进行手动调整将消耗大量计算资源。组卷积已成功应用于改进CNN架构中[37, 34, 16],在固定组数的情况下,高维(低维)通道涉及长距离(短距离)卷积。基于类似的原理,局部跨通道交互的覆盖范围(即一维卷积的核大小 k k k)与通道维度 C C C成正比是合理的。换句话说, k k k和 C C C之间可能存在一个映射 ϕ \phi ϕ:
C = ϕ ( k ) . (10) C = \phi(k).\tag{10} C=ϕ(k).(10)
最简单的映射是线性函数,即 ϕ ( k ) = γ ⋅ k − b \phi(k) = \gamma \cdot k - b ϕ(k)=γ⋅k−b。然而,线性函数所表征的关系过于局限。另一方面,众所周知,通道维度 C C C(即滤波器的数量)通常设置为2的幂。因此,我们将线性函数 ϕ ( k ) = γ ⋅ k − b \phi(k) = \gamma \cdot k - b ϕ(k)=γ⋅k−b扩展到非线性函数,即:
C = ϕ ( k ) = 2 ( γ ⋅ k − b ) . (11) C = \phi(k) = 2^{(\gamma \cdot k - b)}.\tag{11} C=ϕ(k)=2(γ⋅k−b).(11)
然后,给定通道维度 C C C,可以通过以下方式自适应地确定核大小 k k k:
k = ψ ( C ) = ∣ log 2 ( C ) γ + b γ ∣ odd , (12) k = \psi(C) = \left|\frac{\log_{2}(C)}{\gamma} + \frac{b}{\gamma}\right|_{\text{odd}},\tag{12} k=ψ(C)= γlog2(C)+γb odd,(12)
其中 ∣ t ∣ odd |t|_{\text{odd}} ∣t∣odd表示 t t t的最接近的奇数。在本文中,我们在所有实验中分别将 γ \gamma γ和 b b b设置为2和1。显然,通过映射 ψ \psi ψ,高维通道具有更长的交互范围,而低维通道则通过非线性映射进行较短范围的交互。
3.3、深度卷积神经网络中的ECA模块
图2展示了我们的ECA模块的概述。在使用全局平均池化(GAP)聚合卷积特征而不进行降维之后,ECA模块首先自适应地确定核大小 k k k,然后执行一维卷积并跟随Sigmoid函数来学习通道注意力。为了将我们的ECA应用于深度卷积神经网络(CNNs),我们按照[14]中的相同配置,用ECA模块替换SE块。得到的网络被命名为ECA-Net。图3提供了我们ECA模块的PyTorch代码。

4、实验
在本节中,我们使用所提出的方法在ImageNet [6]和MS COCO [23]数据集上的大规模图像分类,目标检测和实例分割任务进行评估。 具体来说,我们首先评估内核大小对ECA模块的影响,然后与ImageNet上的最新技术进行比较。 然后,我们使用Faster R-CNN [26],Mask R-CNN [10]和RetinaNet [22]验证了ECA-Net在MS COCO上的有效性。
4.1、实现细节
为了评估我们的ECA-Net在ImageNet分类任务上的性能,我们采用了四种广泛使用的卷积神经网络作为骨干模型,包括ResNet-50 [11]、ResNet-101 [11]、ResNet-512 [11]和MobileNetV2 [28]。对于使用ECA的ResNet训练,我们完全采用[11, 14]中的相同数据增强和超参数设置。具体来说,输入图像被随机裁剪为 224 × 224 224 \times 224 224×224大小,并随机进行水平翻转。网络参数通过带有权重衰减1e-4、动量0.9和小批量大小为256的随机梯度下降(SGD)进行优化。所有模型均在100个周期内进行训练,初始学习率设置为0.1,每30个周期减少10倍。对于使用ECA的MobileNetV2训练,我们遵循[28]中的设置,其中网络在400个周期内使用SGD进行训练,权重衰减为4e-5,动量为0.9,小批量大小为96。初始学习率设置为0.045,并以0.98的线性衰减率进行降低。在验证集上进行测试时,首先将输入图像的较短边调整到256,然后使用中心裁剪的 224 × 224 224 \times 224 224×224区域进行评估。所有模型均使用PyTorch工具包实现。
我们进一步在MS COCO数据集上使用Faster R-CNN [26]、Mask R-CNN [10]和RetinaNet [22]评估我们的方法,其中ResNet-50和ResNet-101与FPN [21]一起用作骨干模型。我们使用MMDetection工具包[3]实现所有检测器,并采用默认设置。具体来说,输入图像的较短边被调整为800,然后使用带有权重衰减1e-4、动量0.9和小批量大小为8(在4个GPU上,每个GPU上2张图像)的SGD进行优化。学习率初始化为0.01,并在第8个和第11个周期后分别降低10倍。我们在COCO的train2017数据集上对所有检测器进行12个周期的训练,并在val2017上报告结果进行比较。所有程序都在配备四个RTX 2080Ti GPU和Intel® Xeon Silver 4112 CPU@2.60GHz的PC上运行。
4.2、ImageNet-1K上的图像分类
在这里,我们首先评估核大小对我们ECA模块的影响,并验证我们方法自适应确定核大小的有效性。然后,我们使用ResNet-50、ResNet-101、ResNet-152和MobileNetV2,将我们的方法与最先进的同类方法和CNN模型进行比较。
4.2.1、ECA模块中核大小(k)的影响
如公式(9)所示,我们的ECA模块包含一个参数k,即一维卷积的核大小。在这一部分,我们评估核大小对我们ECA模块的影响,并验证我们方法自适应选择核大小的有效性。为此,我们采用ResNet-50和ResNet-101作为骨干模型,并通过设置k值从3到9来训练带有ECA模块的模型。结果如图4所示,我们得到以下观察结果。
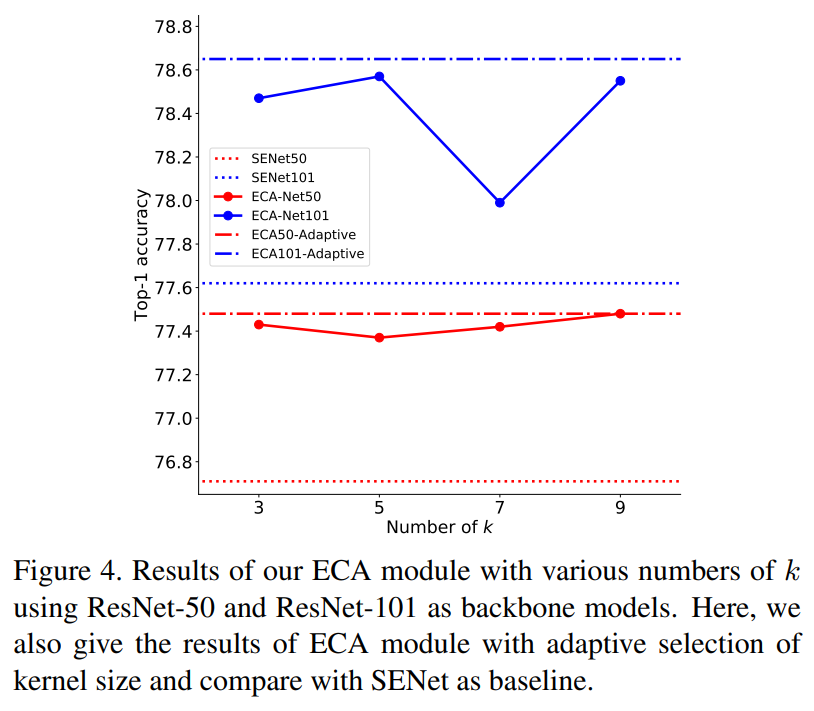
首先,当在所有卷积块中固定k时,ECA模块在k=9和k=5时分别对于ResNet-50和ResNet-101获得最佳结果。由于ResNet-101具有更多主导性能的中间层,它可能更倾向于较小的核大小。此外,这些结果表明不同的深度卷积神经网络具有不同的最优k值,且k对ECA-Net的性能有明显影响。此外,ResNet-101的准确率波动(约0.5%)大于ResNet-50的波动(约0.15%),我们推测原因是较深的网络对固定核大小的敏感性高于较浅的网络。另外,通过公式(12)自适应确定的核大小通常优于固定核大小,同时可以避免通过交叉验证手动调整参数k。上述结果证明了我们的自适应核大小选择方法在获得更好且稳定结果方面的有效性。最后,具有不同k值的ECA模块始终优于SE块,这验证了避免降维和局部跨通道交互对学习通道注意力有积极影响。
4.2.2、使用不同深度CNN的比较
ResNet-50 我们使用ResNet-50在ImageNet上将我们的ECA模块与几种最先进的注意力方法进行比较,包括SENet [14]、CBAM [33]、 A 2 − N e t s [ 4 ] A^{2}-Nets [4] A2−Nets[4]、AA-Net [1]、GSoP-Net1 [9]和GCNet [2]。评价指标包括效率(即网络参数、每秒浮点运算次数(FLOPs)以及训练/推理速度)和有效性(即Top-1/Top-5准确率)。为了进行比较,我们复制了[14]中ResNet和SENet的结果,并在原始论文中报告了其他比较方法的结果。为了测试各种模型的训练/推理速度,我们使用了公开可用的比较CNN模型,并在相同的计算平台上运行它们。结果如表3所示,我们可以看到我们的ECA-Net与原始ResNet-50具有几乎相同的模型复杂度(即网络参数、FLOPs和速度),同时在Top-1准确率上获得了2.28%的提升。与最先进的同类方法(即SENet、CBAM、 A 2 − N e t s A^{2}-Nets A2−Nets、AA-Net、GSoP-Net1和GCNet)相比,ECA-Net在具有更低模型复杂度的同时获得了更好或具有竞争力的结果。
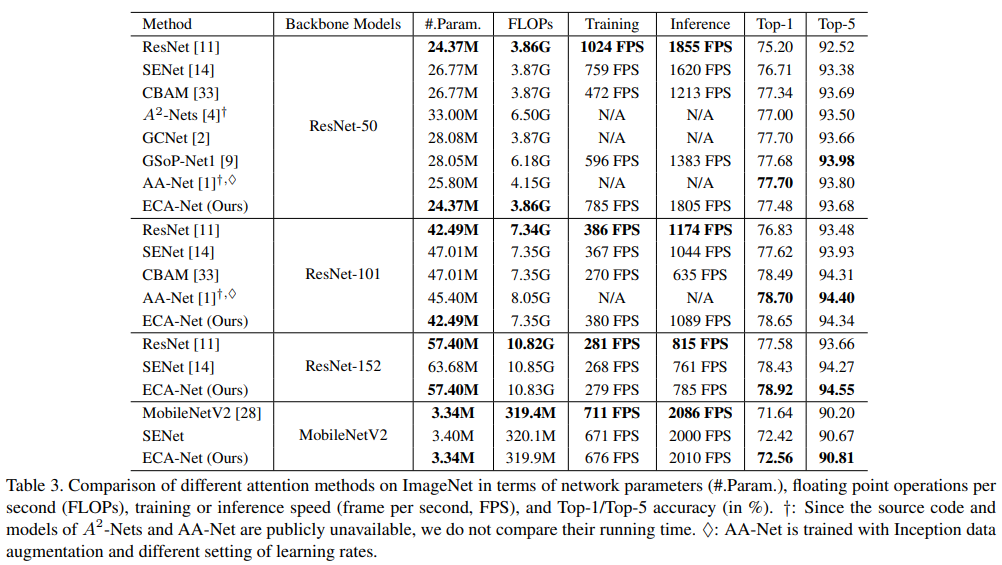
ResNet-101 使用ResNet-101作为骨干模型,我们将我们的ECA-Net与SENet [14]、CBAM [33]和AA-Net [1]进行比较。从表3中我们可以看到,ECA-Net以几乎相同的模型复杂度比原始ResNet-101高出1.8%的准确率。与在ResNet-50上表现出相同趋势的ECA-Net相比,它优于SENet和CBAM,同时与具有更低模型复杂度的AA-Net相比非常具有竞争力。需要注意的是,AA-Net使用Inception数据增强和不同的学习率设置进行训练。
ResNet-152 我们以ResNet-152为骨干模型,将我们的ECA-Net与SENet [14]进行比较。从表3中我们可以看到,ECA-Net在几乎相同的模型复杂度下,将原始ResNet-152的Top-1准确率提高了约1.3%。与SENet相比,ECA-Net在具有更低模型复杂度的同时,Top-1准确率提高了0.5%。关于ResNet-50、ResNet-101和ResNet-152的结果证明了我们的ECA模块在广泛使用的ResNet架构上的有效性。
MobileNetV2 除了ResNet架构外,我们还验证了我们的ECA模块在轻量级CNN架构上的有效性。为此,我们采用MobileNetV2 [28]作为骨干模型,并将我们的ECA模块与SE块进行比较。特别地,我们在MobileNetV2每个“瓶颈”中的残差连接之前的卷积层中集成了SE块和ECA模块,并将SE块的参数 r r r设置为8。所有模型都使用完全相同的设置进行训练。表3中的结果显示,我们的ECA-Net将原始MobileNetV2和SENet的Top-1准确率分别提高了约0.9%和0.14%。此外,我们的ECA-Net的模型大小比SENet更小,训练/推理速度也更快。上述结果再次验证了我们的ECA模块的有效性和效率。
4.2.3、与其他CNN模型的比较
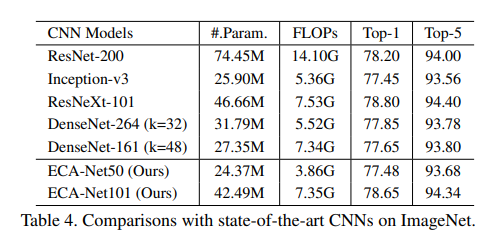
在本部分的最后,我们将我们的ECA-Net50和ECA-Net101与其他最先进的CNN模型进行比较,包括ResNet-200 [12]、Inception-v3 [31]、ResNeXt [34]、DenseNet [15]。这些CNN模型具有更深和更宽的架构,并且它们的结果都是从原始论文中复制的。如表4所示,ECA-Net101的性能优于ResNet-200,这表明我们的ECA-Net可以以更低的计算成本提高深度CNN的性能。同时,我们的ECA-Net101与ResNeXt-101相比也具有很强的竞争力,而后者使用了更多的卷积滤波器和昂贵的分组卷积。此外,ECA-Net50与DenseNet-264(k=32)、DenseNet-161(k=48)和Inception-v3相当,但其模型复杂度更低。上述所有结果都表明,我们的ECA-Net在与最先进的CNN相比时表现优异,同时受益于更低的模型复杂度。请注意,我们的ECA也有很大的潜力进一步提高所比较的CNN模型的性能。
4.3、在MS COCO上的目标检测
在本小节中,我们使用Faster R-CNN [26]、Mask R-CNN [10]和RetinaNet [22]在目标检测任务上评估我们的ECA-Net。我们主要将ECA-Net与ResNet和SENet进行比较。所有CNN模型都在ImageNet上进行预训练,然后通过微调转移到MS COCO上。
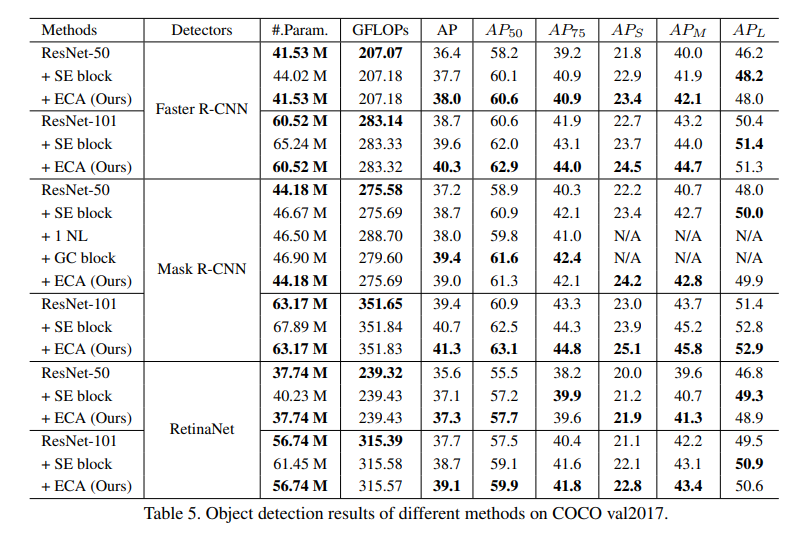
4.3.1、使用Faster R-CNN的比较
以Faster R-CNN作为基本检测器,我们采用50层和101层的ResNet以及FPN [21]作为骨干模型。如表5所示,无论是SE块还是我们的ECA模块,集成后都能显著提高目标检测的性能。同时,使用ResNet-50和ResNet-101时,我们的ECA在AP方面分别比SE块高出0.3%和0.7%。
4.3.2、使用Mask R-CNN的比较
我们进一步使用Mask R-CNN来验证我们的ECA-Net在目标检测任务上的有效性。如表5所示,在50层和101层设置下,我们的ECA模块在AP方面分别比原始ResNet高出1.8%和1.9%。同时,使用ResNet-50和ResNet-101作为骨干模型时,ECA模块分别比SE块高出0.3%和0.6%。使用ResNet-50时,ECA优于NL [32],并且在较低模型复杂度下与GC块 [2]相当。
4.3.3、使用RetinaNet的比较
此外,我们还使用一阶段检测器RetinaNet验证了ECA-Net在目标检测上的有效性。如表5所示,我们的ECA-Net在50层和101层网络上的AP方面分别比原始ResNet高出1.8%和1.4%。同时,对于ResNet-50和ResNet-101,ECA-Net分别比SE-Net提高了0.2%和0.4%。总的来说,表5中的结果表明,我们的ECA-Net可以很好地推广到目标检测任务上。具体来说,ECA模块在原始ResNet的基础上带来了明显的改进,同时在使用更低模型复杂度的情况下优于SE块。特别地,我们的ECA模块在检测小物体方面取得了更多的增益,而这些小物体通常更难被检测到。
4.4、MS COCO上的实例分割
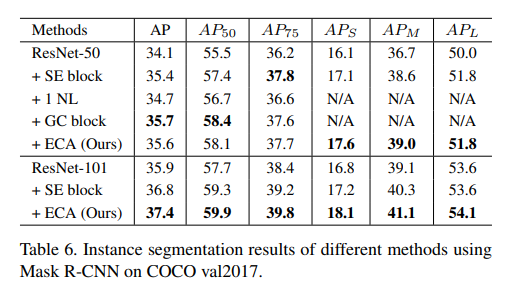
接着,我们使用Mask R-CNN在MS COCO上给出了我们的ECA模块的实例分割结果。如表6所示,ECA模块在原始ResNet的基础上取得了显著的增益,同时以较低的模型复杂度优于SE块。对于以ResNet-50为骨干模型的情况,ECA在较低模型复杂度下优于NL [32],并与GC块 [2]相当。这些结果验证了我们的ECA模块对于各种任务具有良好的泛化能力。
5、结论
在本文中,我们专注于为模型复杂度较低的深层CNN学习有效的渠道关注度。 为此,我们提出了一种有效的通道注意力(ECA)模块,该模块通过快速的1D卷积生成通道注意力,其内核大小可以通过通道尺寸的非线性映射来自适应确定。 实验结果表明,我们的ECA是一种极其轻巧的即插即用模块,可提高各种深度CNN架构的性能,包括广泛使用的ResNets和轻巧的MobileNetV2。 此外,我们的ECA-Net在对象检测和实例分割任务中表现出良好的概括能力。 将来,我们会将ECA模块应用于更多的CNN架构(例如ResNeXt和Inception [31]),并进一步研究将ECA与空间关注模块的结合。
YoloV5官方结果
YOLOv5l summary: 267 layers, 46275213 parameters, 0 gradients, 108.2 GFLOPsClass Images Instances P R mAP50 mAP50-95: 100%|██████████| 15/15 [00:02<00:00, 5.16it/s]all 230 1412 0.971 0.93 0.986 0.729c17 230 131 0.992 0.992 0.995 0.797c5 230 68 0.953 1 0.994 0.81helicopter 230 43 0.974 0.907 0.948 0.57c130 230 85 1 0.981 0.994 0.66f16 230 57 0.999 0.93 0.975 0.677b2 230 2 0.971 1 0.995 0.746other 230 86 0.987 0.915 0.974 0.545b52 230 70 0.983 0.957 0.981 0.803kc10 230 62 1 0.977 0.985 0.819command 230 40 0.971 1 0.986 0.782f15 230 123 0.992 0.976 0.994 0.655kc135 230 91 0.988 0.989 0.986 0.699a10 230 27 1 0.526 0.912 0.391b1 230 20 0.949 1 0.995 0.719aew 230 25 0.952 1 0.993 0.781f22 230 17 0.901 1 0.995 0.763p3 230 105 0.997 0.99 0.995 0.789p8 230 1 0.885 1 0.995 0.697f35 230 32 0.969 0.984 0.985 0.569f18 230 125 0.974 0.992 0.99 0.806v22 230 41 0.994 1 0.995 0.641su-27 230 31 0.987 1 0.995 0.842il-38 230 27 0.994 1 0.995 0.785tu-134 230 1 0.879 1 0.995 0.796su-33 230 2 1 0 0.995 0.846an-70 230 2 0.943 1 0.995 0.895tu-22 230 98 0.983 1 0.995 0.788