图片信息丰富多彩,许多网站上都有大量精美的图片资源。有时候我们可能需要批量下载这些图片,而手动一个个下载显然效率太低。因此,编写一个简单的网站图片爬取程序可以帮助我们高效地获取所需的图片资源。
目标网站:

如果出现模块报错
进入控制台输入:建议使用国内镜像源
pip install 模块名称 -i https://mirrors.aliyun.com/pypi/simple
我大致罗列了以下几种国内镜像源:
清华大学
https://pypi.tuna.tsinghua.edu.cn/simple阿里云
https://mirrors.aliyun.com/pypi/simple/豆瓣
https://pypi.douban.com/simple/ 百度云
https://mirror.baidu.com/pypi/simple/中科大
https://pypi.mirrors.ustc.edu.cn/simple/华为云
https://mirrors.huaweicloud.com/repository/pypi/simple/腾讯云
https://mirrors.cloud.tencent.com/pypi/simple/效果图:
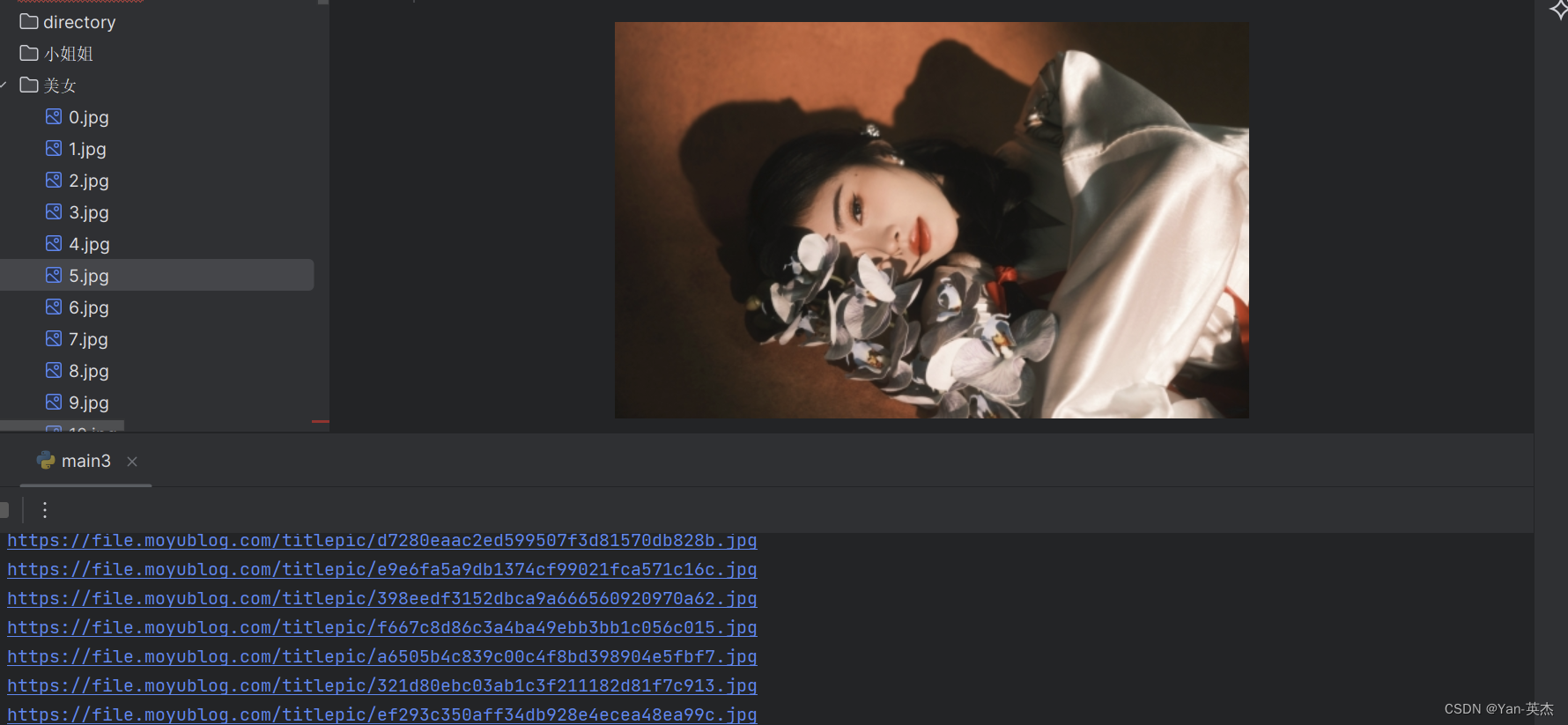
代码详解:
-
get_imgurl_list(url, imgurl_list)函数用来获取指定页面中的图片链接,并将这些链接存储在imgurl_list列表中。- 使用
requests.get(url=url, headers=headers)发起请求获取页面内容。 - 使用
etree.HTML(html_str)将页面内容转换为 etree 对象,方便后续使用 XPath 进行解析。 - 通过 XPath 定位到图片链接,并添加到
imgurl_list中。
- 使用
-
get_down_img(imgurl_list)函数用来下载图片到本地存储。- 创建名为 "美女" 的文件夹用于存储下载的图片。
- 遍历
imgurl_list中的图片链接,逐个下载图片并保存到本地文件夹中。
-
在
if __name__ == '__main__':部分:- 设置需要爬取的页数
page_number = 10。 - 循环构建每一页的链接,如
https://www.moyublog.com/95-2-2-{i}.html。 - 调用
get_imgurl_list()函数获取图片链接。 - 调用
get_down_img()函数下载图片到本地。
- 设置需要爬取的页数
代码流程:
- 导入必要的库和模块:
import requests # 用于发送HTTP请求
from lxml import etree # 用于解析HTML页面
import time # 用于控制爬取速度
import os # 用于文件操作
- 定义函数
get_imgurl_list(url, imgurl_list)用于获取图片链接:
def get_imgurl_list(url, imgurl_list):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}response = requests.get(url=url, headers=headers)html_str = response.texthtml_data = etree.HTML(html_str)li_list = html_data.xpath("//ul[@class='clearfix']/li")for li in li_list:imgurl = li.xpath(".//a/img/@data-original")[0]imgurl_list.append(imgurl)
- 发送GET请求获取网页内容。
- 将网页内容转换为etree对象以便后续使用xpath进行解析。
- 使用xpath定位所有的li标签,并遍历每个li标签获取图片链接,将链接添加到
imgurl_list列表中。
- 定义函数
get_down_img(imgurl_list)用于下载图片:
def get_down_img(imgurl_list):os.mkdir("美女")n = 0for img_url in imgurl_list:headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}img_data = requests.get(url=img_url, headers=headers).contentimg_path = './美女/' + str(n) + '.jpg'with open(img_path, 'wb') as f:f.write(img_data)n += 1
- 创建名为"美女"的目录用于存放下载的图片。
- 遍历图片链接列表,逐个发送GET请求下载图片数据,并将图片写入本地文件。每张图片以数字编号命名。
- 主程序部分:
if __name__ == '__main__':page_number = 10 # 爬取页数imgurl_list = [] # 存放图片链接for i in range(0, page_number + 1):url = f'https://www.moyublog.com/95-2-2-{i}.html'print(url)get_imgurl_list(url, imgurl_list)get_down_img(imgurl_list)
- 设定要爬取的页数
page_number为10。- 初始化存放图片链接的列表
imgurl_list。- 循环构建每一页的链接并调用
get_imgurl_list()函数获取图片链接。- 最后调用
get_down_img()函数下载图片到本地"美女"文件夹。
为什么我们在获取数据的过程中需要用到IP池
应对反爬虫策略:许多网站会采取反爬虫措施,限制单个IP的访问频率或次数。通过使用数据获取服务,可以轮换多IP来模仿多个用户访问,降低被封禁的风险。
保证稳定性:有些数据获取服务可能存在不稳定的情况,包括IP连接速度慢、IP被找到等问题。通过建立数据获取服务,可以预先准备多个可用的IP地址,确保程序在某个IP不可用时可以快速切换到其他可用IP,提高爬虫程序的稳定性。
提高访问速度:IP池中的多个IP地址可以并发使用,实现多线程或异步请求,从而加快数据获取速度。通过在数据获取服务中保持一定数量的可用IP地址,可以实现更快速的数据抓取。
应对封禁风险:有些网站会根据某些特定的IP地址或IP段进行封禁,如果整个IP池中的IP都被封禁,可以及时更新IP池中的IP地址,避免影响爬虫程序的正常运行。
降低被识别的风险:当爬虫程序使用固定的IP地址进行访问时,容易被网站识别出是爬虫行为。

完整代码:
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为Elements对象
import time # 防止爬取过快可以睡眠一秒
import os
def get_imgurl_list(url, imgurl_list):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}# 发送请求response = requests.get(url=url, headers=headers)# 获取网页源码html_str = response.text# 将html字符串转换为etree对象方便后面使用xpath进行解析html_data = etree.HTML(html_str)# 利用xpath取到所有的li标签li_list = html_data.xpath("//ul[@class='clearfix']/li")# 打印一下li标签个数看是否和一页的电影个数对得上print(len(li_list)) # 输出20,没有问题for li in li_list:imgurl = li.xpath(".//a/img/@data-original")[0]print(imgurl)# 写入列表imgurl_list.append(imgurl)
def get_down_img(imgurl_list):os.mkdir("美女")n = 0for img_url in imgurl_list:headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}img_data = requests.get(url=img_url, headers=headers).content ## 拼接图片存放地址和名字img_path = './美女/' + str(n) + '.jpg'# 将图片写入指定位置with open(img_path, 'wb') as f:f.write(img_data)# 图片编号递增n = n + 1if __name__ == '__main__':page_number = 10 # 爬取页数imgurl_list = [] # 存放图片链接# 1. 循环构建每页的链接for i in range(0, page_number + 1):# 页数拼接url = f'https://www.moyublog.com/95-2-2-{i}.html'print(url)# 2. 获取图片链接get_imgurl_list(url, imgurl_list)# 3. 下载图片get_down_img(imgurl_list)

)

的简介、使用方法、案例应用之详细攻略)








:sources 篇)


)


